Înțelegerea Procesului de Web Scraping
Web scraping, cunoscut și ca extragere web, este o tehnică ce facilitează colectarea eficientă a unor cantități mari de date de pe internet. Acest proces automatizat este deosebit de util când site-urile web nu oferă acces structurat la date prin API-uri (Interfețe de Programare a Aplicațiilor).
De exemplu, presupunem că dorești să dezvolți o aplicație care compară prețurile produselor de pe diverse platforme de comerț electronic. O abordare ar fi verificarea manuală a prețurilor pe fiecare site și notarea acestora. Această metodă este însă ineficientă, având în vedere multitudinea de produse și site-uri, ceea ce ar necesita un timp considerabil.
O soluție mult mai practică este utilizarea web scraping-ului. Acesta presupune utilizarea unui software specializat pentru a extrage automat informații din pagini și site-uri web.
Aceste scripturi software, numite „web scrapers”, accesează paginile web și extrag datele relevante. Deși datele sunt preluate inițial într-un format nestructurat, acestea pot fi apoi organizate și stocate într-o manieră inteligibilă pentru utilizatori, facilitând analiza și interpretarea.
Valoarea web scraping-ului constă în capacitatea de a accesa volume mari de date și de a automatiza procesul, permițând programarea scripturilor pentru a rula la intervale specifice sau ca răspuns la anumite evenimente. Web scraping-ul oferă actualizări în timp real și simplifică cercetările de piață.

Numeroase companii din diverse sectoare utilizează web scraping pentru a colecta date pentru analiză. De la resurse umane și comerț electronic, până la finanțe, imobiliare, călătorii, rețele sociale și cercetare, web scraping-ul este un instrument vital pentru obținerea informațiilor relevante de pe web.
Chiar și Google folosește tehnici de web scraping pentru a indexa site-urile web de pe internet, oferind astfel rezultate relevante pentru căutările utilizatorilor.
Este crucial să abordăm web scraping-ul cu precauție. Deși extragerea datelor publice nu este ilegală în sine, unele site-uri web interzic această practică, fie pentru că dețin informații sensibile despre utilizatori, fie pentru că termenii și condițiile lor interzic explicit extragerea web, sau pentru a proteja proprietatea intelectuală.
Unele site-uri web pot restricționa web scraping-ul deoarece acesta poate supraîncărca serverul lor și duce la costuri suplimentare de lățime de bandă, în special dacă este realizat la scară mare.
Pentru a verifica dacă un site web permite extragerea datelor, adaugă „/robots.txt” la adresa URL a site-ului. Fișierul „robots.txt” indică roboților care secțiuni ale site-ului pot fi accesate. De exemplu, pentru a verifica politica Google, vizitează google.com/robots.txt.
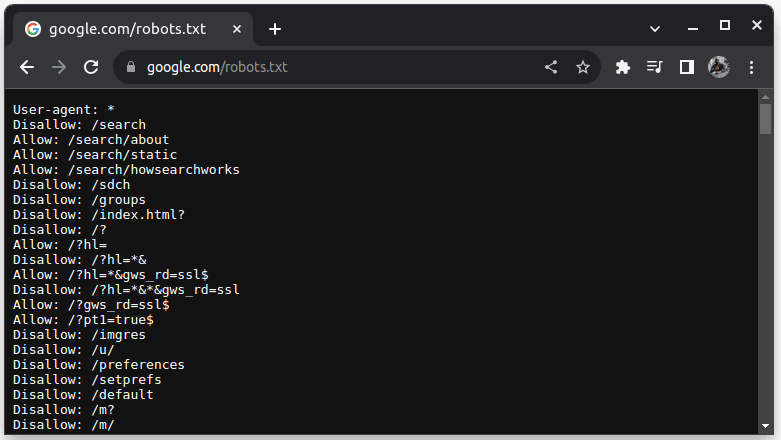
„User-agent: *” se referă la toți roboții, scripturile software și crawlerele. „Disallow” este utilizat pentru a indica ce directoare nu pot fi accesate de roboți (de exemplu, /search), iar „Allow” indică directoarele accesibile.
Un exemplu de site care nu permite scraping este LinkedIn. Pentru a verifica politica LinkedIn, vizitează linkedin.com/robots.txt.
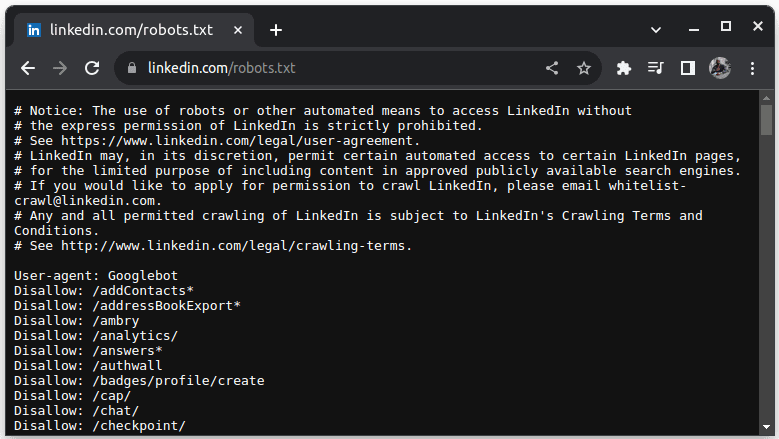
După cum se poate observa, scraping-ul LinkedIn nu este permis fără acordul lor. Este esențial să verificăm politicile fiecărui site web înainte de a începe extragerea, pentru a evita eventuale probleme legale.
De Ce Java Este Un Limbaj Potrivit Pentru Web Scraping?
Deși web scraperele pot fi dezvoltate folosind o varietate de limbaje de programare, Java se distinge ca o opțiune ideală din mai multe motive. În primul rând, Java oferă un ecosistem bogat, o comunitate extinsă și numeroase biblioteci specializate pentru web scraping, cum ar fi JSoup, WebMagic și HTMLUnit, care simplifică semnificativ procesul de dezvoltare.

Java oferă, de asemenea, biblioteci de analiză HTML, care simplifică extragerea datelor din documentele HTML, și biblioteci de rețea, cum ar fi HttpURLConnection, pentru a gestiona cererile către diverse adrese web.
Suportul robust al Java pentru concurență și multithreading este un avantaj major în web scraping, permițând procesarea paralelă și gestionarea eficientă a solicitărilor multiple, ceea ce permite extragerea datelor de pe mai multe pagini simultan. Datorită scalabilității Java, se pot realiza operațiuni de scraping de amploare fără probleme.
Compatibilitatea multiplatformă a Java este, de asemenea, un avantaj, permițând scrierea unui web scraper care poate fi rulat pe orice sistem compatibil cu o mașină virtuală Java. Acest lucru oferă flexibilitate în dezvoltare și implementare, fără a fi necesare modificări ale codului în funcție de sistemul de operare.
Java poate fi utilizat cu browsere fără interfață grafică, cum ar fi Headless Chrome, HTML Unit, Headless Firefox și PhantomJs. Aceste browsere sunt ideale pentru a simula interacțiunile utilizatorului și pentru a extrage date de pe site-uri care necesită astfel de interacțiuni.
În plus, Java este un limbaj popular, susținut de o gamă largă de instrumente, baze de date și cadre de procesare a datelor, ceea ce asigură că infrastructura necesară pentru colectarea, procesarea și stocarea datelor este compatibilă cu Java.
Acum, vom analiza modul în care Java poate fi folosit pentru web scraping.
Pregătirea Pentru Web Scraping Cu Java
Pentru a utiliza Java în web scraping, sunt necesare câteva pregătiri:
1. Java – Trebuie să ai Java instalat, de preferat ultima versiune LTS (Long-Term Support). Dacă nu ai Java instalat, consultă documentația oficială pentru a afla cum să instalezi Java pe sistemul tău.
2. Mediu de Dezvoltare Integrat (IDE) – Ar trebui să ai un IDE instalat. Vom folosi IntelliJ IDEA în acest ghid, dar poți utiliza orice IDE cu care ești familiarizat.
3. Maven – Acesta va fi utilizat pentru gestionarea dependențelor și pentru a instala o bibliotecă web scraping.
Dacă nu ai Maven instalat, poți face acest lucru prin intermediul terminalului folosind comanda:
sudo apt install maven
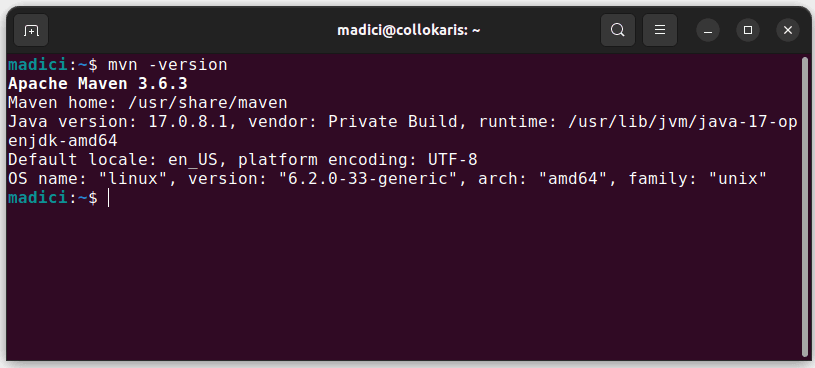
Această comandă instalează Maven din depozitul oficial. Poți confirma instalarea cu succes folosind comanda:
mvn -version
Dacă instalarea a reușit, vei obține un output similar cu cel de mai jos:
Configurarea Mediului de Dezvoltare
Pentru a configura mediul de dezvoltare, urmează pașii de mai jos:
1. Deschide IntelliJ IDEA. În bara de meniu din stânga, dă clic pe „Proiecte”, apoi selectează „Proiect nou”.
2. În fereastra „Proiect nou”, completează câmpurile după cum urmează: asigură-te că limbajul este setat la Java și sistemul de compilare la Maven. Poți da proiectului orice nume dorești și alege locația unde vrei să fie creat proiectul. După ce ai terminat, dă clic pe „Creare”.
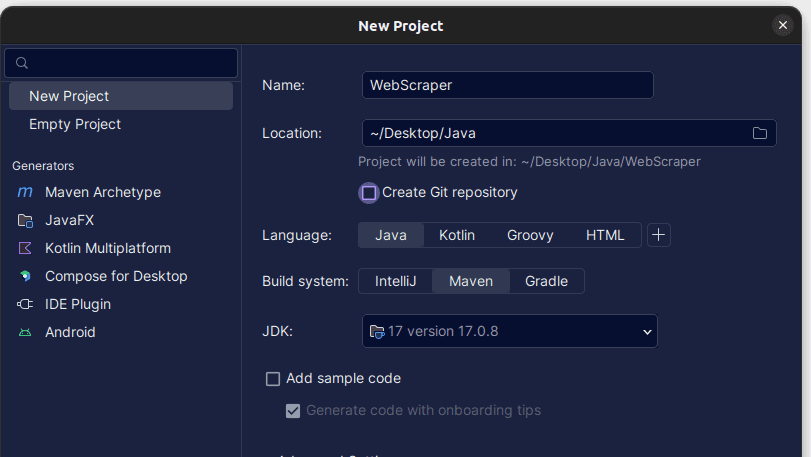
3. Odată ce proiectul a fost creat, ar trebui să ai un fișier „pom.xml”, așa cum se arată mai jos.
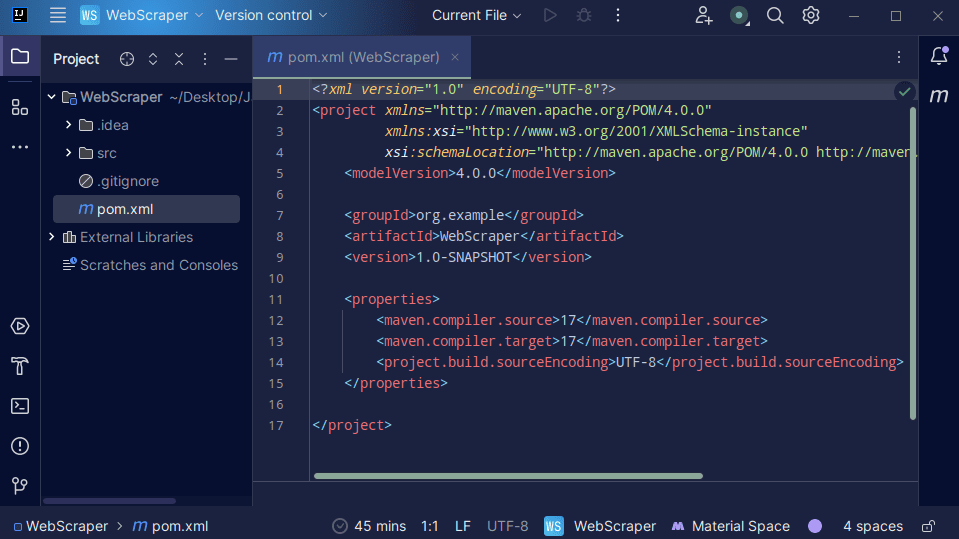
Fișierul „pom.xml” este creat de Maven și conține informații despre proiect și detalii de configurare utilizate de Maven pentru a construi proiectul. Acesta este fișierul în care vom specifica că folosim biblioteci externe.
Pentru web scraping, vom utiliza biblioteca jsoup. Prin urmare, trebuie să o adăugăm ca dependență în fișierul „pom.xml”, pentru ca Maven să o facă disponibilă în proiectul nostru.
4. Adaugă dependența jsoup în fișierul „pom.xml” prin copierea codului de mai jos și adăugarea sa în fișierul „pom.xml”.
<dependencies>
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.16.1</version>
</dependency>
</dependencies>
Rezultatul ar trebui să arate similar cu:
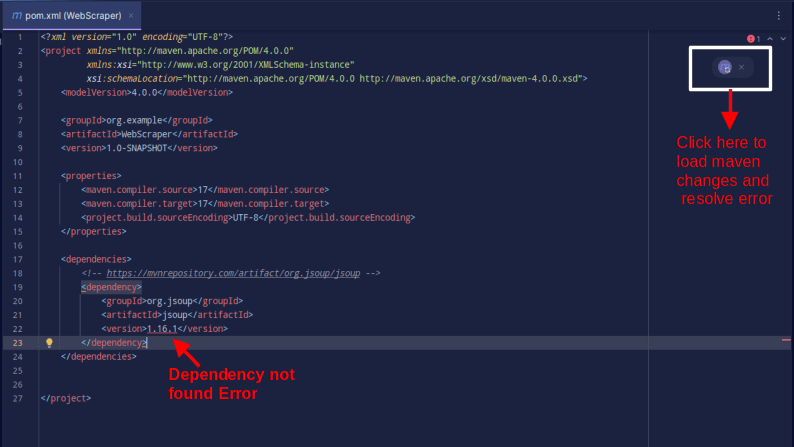
Dacă întâmpini o eroare care semnalează că dependența nu poate fi găsită, fă clic pe pictograma specifică pentru ca Maven să încarce modificările și să rezolve eroarea.
Cu acești pași, mediul tău este complet configurat.
Web Scraping Cu Java – Exemplu Practic
Pentru a ilustra procesul de web scraping cu Java, vom extrage date de pe site-ul ScrapeThisSite, un sandbox unde dezvoltatorii pot testa tehnici de web scraping fără probleme legale.
Pentru a face scraping unui site web folosind Java:
1. În bara de meniu din stânga a IntelliJ, deschide directorul „src”, apoi directorul „main”, care se află în „src”. În interiorul directorului „main” se află un director numit „java”; dă clic dreapta pe el și selectează „Nou”, apoi „Clasă Java”.
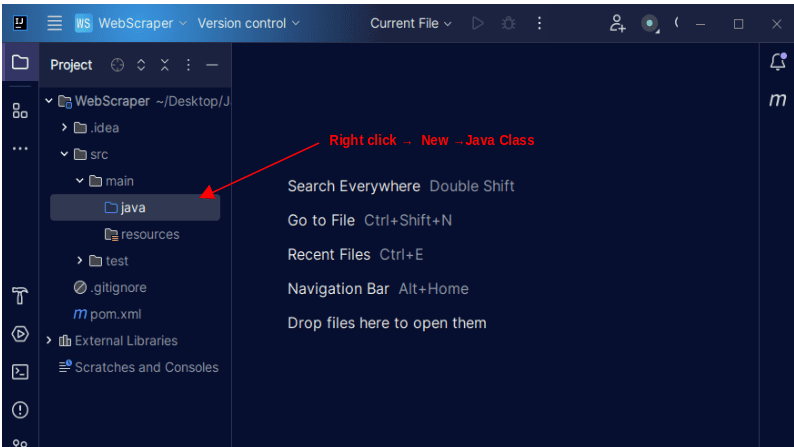
Denumește clasa cum dorești, de exemplu „WebScraper”, apoi apasă „Enter” pentru a crea noua clasă Java.
Deschide fișierul nou creat care conține clasa Java.
2. Web scraping presupune preluarea de date de pe site-uri web. Așadar, trebuie să specificăm adresa URL de unde dorim să extragem datele. Odată ce adresa URL este specificată, trebuie să ne conectăm la ea și să facem o cerere GET pentru a prelua conținutul HTML al paginii.
Codul care realizează acest lucru este prezentat mai jos:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
System.out.println(doc);
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
Rezultatul va fi similar cu:
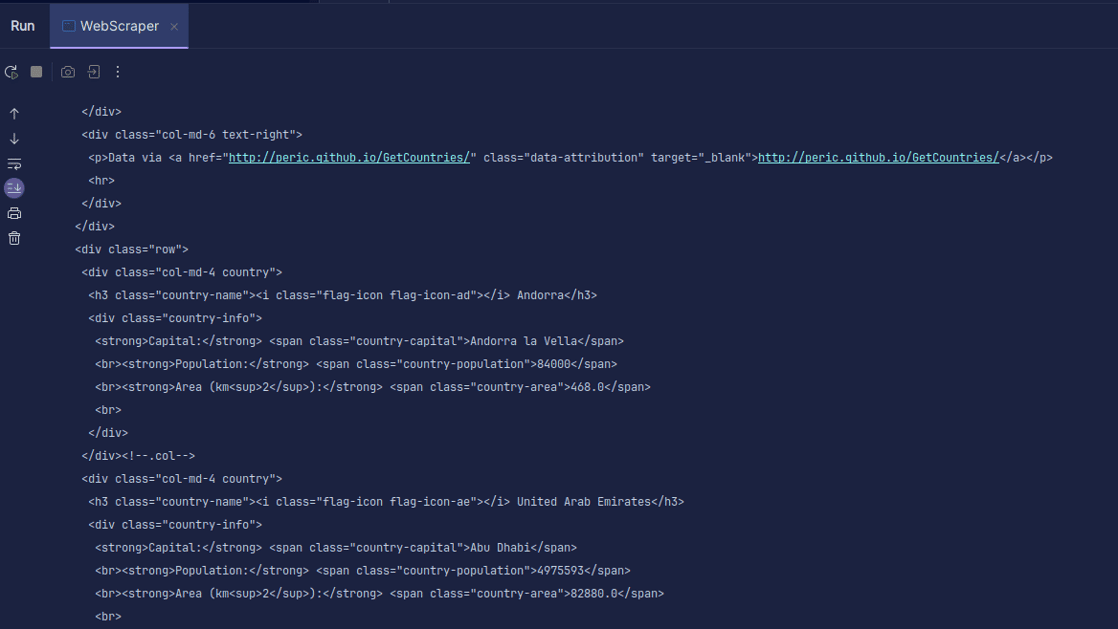
După cum se poate observa, codul HTML al paginii este returnat. În timpul procesului de scraping, pot apărea erori (de exemplu, adresa URL specificată să fie incorectă, sau resursa să nu mai existe). De aceea, este esențial să includem codul într-un bloc try-catch, pentru a gestiona eventualele excepții.
Linia de cod:
Document doc = Jsoup.connect(url).get();
este utilizată pentru a realiza conexiunea la adresa URL specificată. Metoda `get()` realizează o cerere GET și preia codul HTML al paginii, pe care îl stochează într-un obiect `Document` JSOUP, numit `doc`. Utilizarea unui obiect `Document` JSOUP permite manipularea codului HTML folosind API-ul JSOUP.
3. Vizitează ScrapeThisSite și inspectează pagina. În codul HTML, vei observa structura prezentată mai jos:
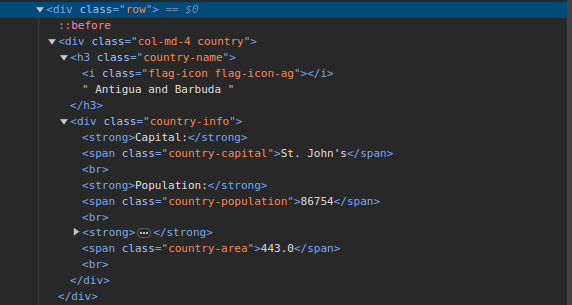
Se poate observa că toate țările de pe pagină sunt stocate într-o structură similară. Există un div cu clasa „country”, care conține un element `h3` cu clasa „country-name”, unde se află numele fiecărei țări de pe pagină.
În interiorul div-ului principal, există un alt div cu clasa „country-info”, care conține informații precum capitala, populația și zona țării. Putem utiliza aceste clase pentru a selecta elementele HTML și a extrage datele relevante.
4. Extrage conținutul specific din HTML-ul paginii folosind următoarele linii:
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " Population - " + population);
}
Folosim metoda `select()` pentru a selecta elementele HTML care se potrivesc cu selectorul CSS specificat. În exemplul nostru, folosim numele claselor. Din inspectarea codului paginii, am observat că toate informațiile despre țări sunt stocate într-un div cu clasa „country”.
Fiecare țară are propriul div cu clasa „country”, care conține informații precum numele țării, capitala și populația.
Așadar, selectăm mai întâi toate țările de pe pagină folosind clasa „.country”. Aceste elemente sunt stocate într-o variabilă numită „countries” de tipul `Elements`, care este similară cu o listă. Apoi, folosim un ciclu for pentru a itera prin țările extrase, pentru a extrage numele, capitala și populația fiecărei țări și a le afișa.
Codul complet este prezentat mai jos:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " - Population - " + population);
}
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
Rezultatul va fi:
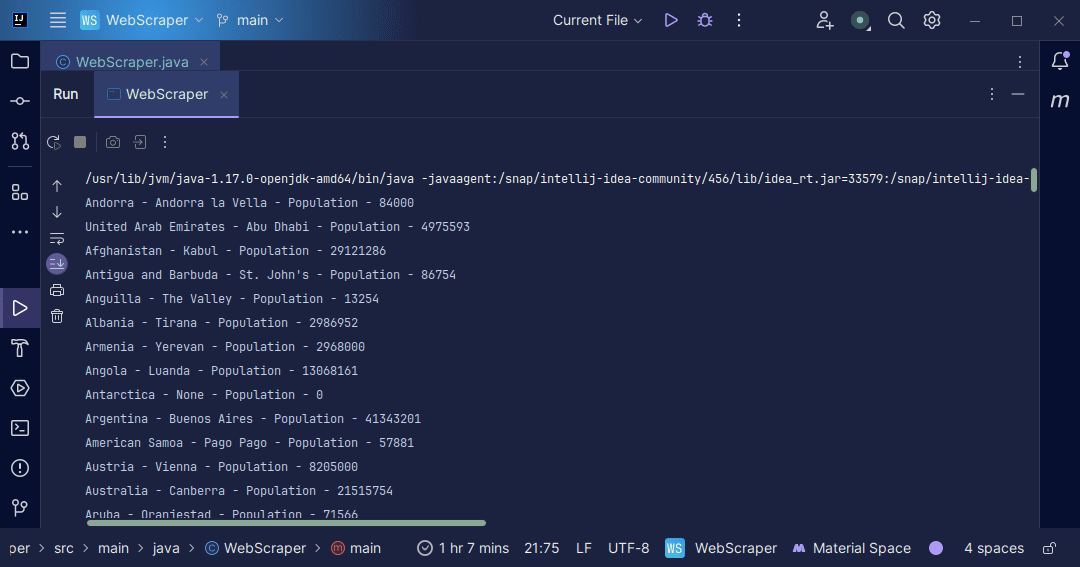
Cu informațiile extrase de pe pagină, se pot realiza diverse operațiuni, cum ar fi afișarea lor în consolă, sau stocarea într-un fișier pentru prelucrare ulterioară.
Concluzie
Web scraping este o tehnică excelentă pentru a extrage date nestructurate de pe site-uri web, a organiza aceste date într-un mod structurat și a le prelucra pentru a obține informații valoroase. Cu toate acestea, este important să abordăm web scraping-ul cu precauție, având în vedere că anumite site-uri web nu permit această practică.
Pentru a evita probleme, este recomandabil să folosim site-uri web care oferă medii de testare pentru web scraping. Alternativ, este esențial să verificăm fișierul „robots.txt” al fiecărui site web înainte de a începe extragerea datelor.
Java este un limbaj excelent pentru scrierea de web scrapere, datorită bibliotecilor sale care simplifică și eficientizează procesul de scraping. Pentru un dezvoltator Java, crearea unui web scraper reprezintă o oportunitate de a-și dezvolta abilitățile de programare. Te încurajăm să dezvolți propriul tău web scraper sau să modifici exemplul prezentat, pentru a extrage diverse tipuri de informații. Programare plăcută!
De asemenea, poți explora diverse soluții populare de web scraping bazate pe cloud.