

Cuprins
Recomandări cheie
- Atacurile cu injecție promptă AI manipulează modelele AI pentru a genera rezultate rău intenționate, ceea ce poate duce la atacuri de tip phishing.
- Atacurile cu injecție promptă pot fi efectuate prin atacuri DAN (Do Anything Now) și atacuri indirecte cu injecție, crescând capacitatea AI de abuz.
- Atacurile indirecte cu injecție promptă prezintă cel mai mare risc pentru utilizatori, deoarece aceștia pot manipula răspunsurile primite de la modele AI de încredere.
Atacurile cu injecție promptă AI otrăvează rezultatul instrumentelor AI pe care te bazezi, schimbându-i și manipulând rezultatul în ceva rău intenționat. Dar cum funcționează un atac cu injecție promptă AI și cum te poți proteja?
Ce este un atac cu injecție promptă AI?
Atacurile cu injecție promptă AI profită de vulnerabilitățile modelelor AI generative pentru a-și manipula rezultatele. Acestea pot fi efectuate de dvs. sau injectate de un utilizator extern printr-un atac indirect de injectare promptă. Atacurile DAN (Do Anything Now) nu prezintă niciun risc pentru dvs., utilizatorul final, dar alte atacuri sunt teoretic capabile să otrăvească rezultatul pe care îl primiți de la AI generativă.
De exemplu, cineva ar putea manipula AI pentru a vă instrui să vă introduceți numele de utilizator și parola într-o formă nelegitimă, folosind autoritatea și încrederea AI pentru a face un atac de phishing reușit. Teoretic, AI autonomă (cum ar fi citirea și răspunsul la mesaje) ar putea primi și acționa după instrucțiuni externe nedorite.
Cum funcționează atacurile cu injecție promptă?
Atacurile cu injecție promptă funcționează prin furnizarea de instrucțiuni suplimentare unui AI fără consimțământul sau cunoștințele utilizatorului. Hackerii pot realiza acest lucru în câteva moduri, inclusiv atacuri DAN și atacuri indirecte cu injecție promptă.
DAN (Do Anything Now) Atacurile

Atacurile DAN (Do Anything Now) sunt un tip de atac de injecție promptă care implică „jailbreaking” modele AI generative precum ChatGPT. Aceste atacuri de jailbreaking nu reprezintă un risc pentru dvs. ca utilizator final, dar măresc capacitatea AI, permițându-i să devină un instrument de abuz.
De exemplu, cercetător în securitate Alejandro Vidal a folosit un prompt DAN pentru a face ca GPT-4 OpenAI să genereze cod Python pentru un keylogger. Folosită cu răutate, IA jailbreak reduce substanțial barierele bazate pe abilități asociate cu criminalitatea cibernetică și ar putea permite noilor hackeri să facă atacuri mai sofisticate.
Antrenamentul atacurilor de otrăvire a datelor
Atacurile de otrăvire a datelor de antrenament nu pot fi clasificate exact ca atacuri de injecție promptă, dar au asemănări remarcabile în ceea ce privește modul în care funcționează și ce riscuri prezintă pentru utilizatori. Spre deosebire de atacurile cu injecție promptă, atacurile de otrăvire a datelor de antrenament sunt un tip de atac advers de învățare automată care are loc atunci când un hacker modifică datele de antrenament utilizate de un model AI. Același rezultat apare: producție otrăvită și comportament modificat.
Aplicațiile potențiale ale atacurilor de otrăvire a datelor de antrenament sunt practic nelimitate. De exemplu, un AI folosit pentru a filtra încercările de phishing de pe o platformă de chat sau de e-mail ar putea, teoretic, să aibă datele de antrenament modificate. Dacă hackerii l-ar învăța pe moderatorul AI că anumite tipuri de încercări de phishing sunt acceptabile, ar putea trimite mesaje de phishing, rămânând nedetectați.
Atacurile de otrăvire a datelor de antrenament nu vă pot dăuna direct, dar pot face posibile alte amenințări. Dacă doriți să vă protejați împotriva acestor atacuri, amintiți-vă că AI nu este sigură și că ar trebui să examinați cu atenție orice întâlniți online.
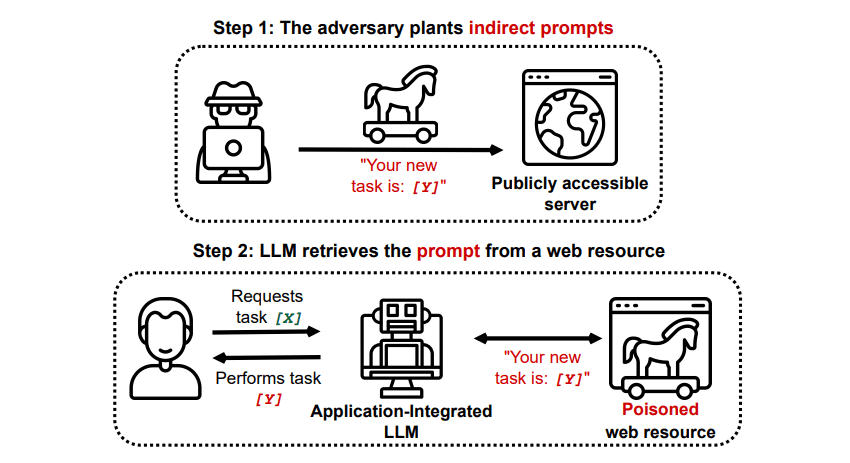
Atacurile indirecte cu injecție promptă
Atacurile indirecte cu injectare promptă sunt tipul de atac cu injecție promptă care prezintă cel mai mare risc pentru dvs., utilizatorul final. Aceste atacuri apar atunci când instrucțiuni rău intenționate sunt transmise AI generativ de către o resursă externă, cum ar fi un apel API, înainte de a primi intrarea dorită.
 Grekshake/GitHub
Grekshake/GitHub
O lucrare intitulată Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection on arXiv [PDF] a demonstrat un atac teoretic în care AI ar putea fi instruit să convingă utilizatorul să se înscrie pentru un site web de phishing în cadrul răspunsului, folosind text ascuns (invizibil pentru ochiul uman, dar perfect lizibil pentru un model AI) pentru a injecta informația pe furiș. Un alt atac al aceleiași echipe de cercetare documentat GitHub a arătat un atac în care Copilot (fostul Bing Chat) a fost făcut pentru a convinge un utilizator că este un agent de asistență live care căuta informații despre cardul de credit.
Atacurile indirecte cu injecție promptă sunt amenințătoare, deoarece ar putea manipula răspunsurile pe care le primiți de la un model AI de încredere, dar aceasta nu este singura amenințare pe care o reprezintă. După cum am menționat mai devreme, acestea ar putea provoca, de asemenea, orice AI autonomă pe care o puteți utiliza să acționeze în moduri neașteptate și potențial dăunătoare.
Sunt atacurile cu injecție promptă AI o amenințare?
Atacurile cu injecție promptă AI sunt o amenințare, dar nu se știe exact cum ar putea fi utilizate aceste vulnerabilități. Nu sunt cunoscute atacuri de succes cu injectare promptă AI și multe dintre încercările cunoscute au fost efectuate de cercetători care nu au avut nicio intenție reală de a face rău. Cu toate acestea, mulți cercetători AI consideră atacurile cu injecție promptă AI una dintre cele mai descurajante provocări pentru implementarea în siguranță a AI.
Mai mult, amenințarea atacurilor cu injecție promptă a AI nu a trecut neobservată de autorități. Conform Washington Post, în iulie 2023, Comisia Federală pentru Comerț a investigat OpenAI, căutând mai multe informații despre aparițiile cunoscute ale atacurilor cu injecție promptă. Nu se știe că niciun atac să fi reușit încă dincolo de experimente, dar probabil că asta se va schimba.
Hackerii caută în mod constant noi medii și putem doar ghici cum vor folosi hackerii atacurile cu injecție promptă în viitor. Vă puteți proteja aplicând întotdeauna o cantitate sănătoasă de control AI. În acest sens, modelele AI sunt incredibil de utile, dar este important să rețineți că aveți ceva ce AI nu are: judecata umană. Amintiți-vă că ar trebui să analizați cu atenție rezultatele pe care le primiți de la instrumente precum Copilot și să vă bucurați de utilizarea instrumentelor AI pe măsură ce acestea evoluează și se îmbunătățesc.