În ultimii ani, utilizarea limbajului Python în domeniul științei datelor a cunoscut o creștere exponențială, tendința continuând și astăzi.
Știința datelor este un domeniu vast, cu numeroase ramificații. Analiza datelor este, fără îndoială, una dintre cele mai importante subdiscipline, iar înțelegerea sa, chiar și la un nivel elementar, a devenit esențială, indiferent de nivelul de experiență în știința datelor.
Ce presupune analiza datelor?
Analiza datelor implică procesul de curățare și transformare a unor volume mari de date nestructurate sau dezorganizate. Scopul final este generarea de perspective și informații cruciale, care vor facilita luarea unor decizii bine fundamentate.
Pentru analiza datelor, există o varietate de instrumente, precum Python, Microsoft Excel, Tableau și SaS. Totuși, în acest articol ne vom concentra pe modul în care se realizează analiza datelor folosind Python, în special prin intermediul bibliotecii Pandas.
Ce este Pandas?
Pandas este o bibliotecă Python open-source utilizată pentru manipularea și prelucrarea datelor. Este renumită pentru viteza și eficiența sa, oferind instrumente care permit încărcarea rapidă a diverselor tipuri de date în memorie. Pandas poate fi utilizat pentru restructurarea, felierea, indexarea și gruparea diferitelor formate de date.
Structurile de date în Pandas
În Pandas, există trei structuri de date de bază:
O modalitate eficientă de a înțelege relația dintre aceste structuri este să le vizualizăm ca stive. Un DataFrame este format dintr-o stivă de serii, iar un Panel reprezintă o stivă de DataFrames.
- O serie este o matrice unidimensională.
- Un set de serii formează un DataFrame bidimensional.
- O stivă de DataFrames creează un Panel tridimensional.
Cel mai frecvent, vom lucra cu DataFrame-ul bidimensional, care este și modalitatea implicită de reprezentare a multora dintre seturile de date pe care le putem întâlni.
Analiza datelor folosind Pandas
Pentru scopul acestui articol, nu este necesară nicio instalare suplimentară. Vom utiliza un instrument numit Colab, creat de Google. Acesta este un mediu online pentru analiza datelor, învățare automată și inteligență artificială, bazat pe Jupyter Notebook și preinstalat cu majoritatea pachetelor Python necesare unui cercetător de date.
Accesați https://colab.research.google.com/notebooks/intro.ipynb. Ar trebui să vedeți o pagină similară celei de mai jos.
Navigând în partea din stânga sus, dați click pe opțiunea „Fișier”, apoi pe „Notebook nou”. O nouă pagină Jupyter Notebook se va încărca în browser. Primul pas este importarea bibliotecii Pandas în mediul nostru de lucru. Acest lucru se realizează prin executarea codului următor:
import pandas as pd
Pentru exemplul de analiză a datelor din acest articol, vom utiliza un set de date referitor la prețurile locuințelor. Acest set de date este disponibil aici. Primul pas este încărcarea setului de date în mediul nostru de lucru.
Acest lucru se poate realiza cu următorul cod într-o celulă nouă:
df = pd.read_csv('https://firebasestorage.googleapis.com/v0/b/ai6-portfolio-abeokuta.appspot.com/o/kc_house_data.csv?alt=media &token=6a5ab32c-3cac-42b3-b534-4dbd0e4bdbc0', sep=',')
Funcția .read_csv este utilizată pentru citirea fișierelor CSV. Am specificat proprietatea sep pentru a indica faptul că fișierul CSV este delimitat prin virgulă.
De asemenea, rețineți că fișierul CSV încărcat este stocat în variabila df.
În Jupyter Notebook, nu este nevoie să folosim funcția print(). Este suficient să introducem numele unei variabile într-o celulă, iar Jupyter Notebook o va afișa.
Încercați acest lucru introducând df într-o celulă nouă și executând-o. Veți observa că toate datele din setul nostru de date vor fi afișate ca DataFrame.
Însă, uneori nu dorim să afișăm toate datele. Este posibil să dorim doar să vedem primele sau ultimele câteva date și numele coloanelor acestora. Pentru aceasta, putem folosi funcția df.head() pentru a afișa primele cinci coloane și df.tail() pentru ultimele cinci. Rezultatul oricăreia dintre aceste funcții va arăta similar cu următorul:
Pentru a analiza relațiile dintre câteva rânduri și coloane de date, putem folosi funcția .describe(). Aceasta ne oferă statistici descriptive despre date.
Executând df.describe(), obținem următorul rezultat:
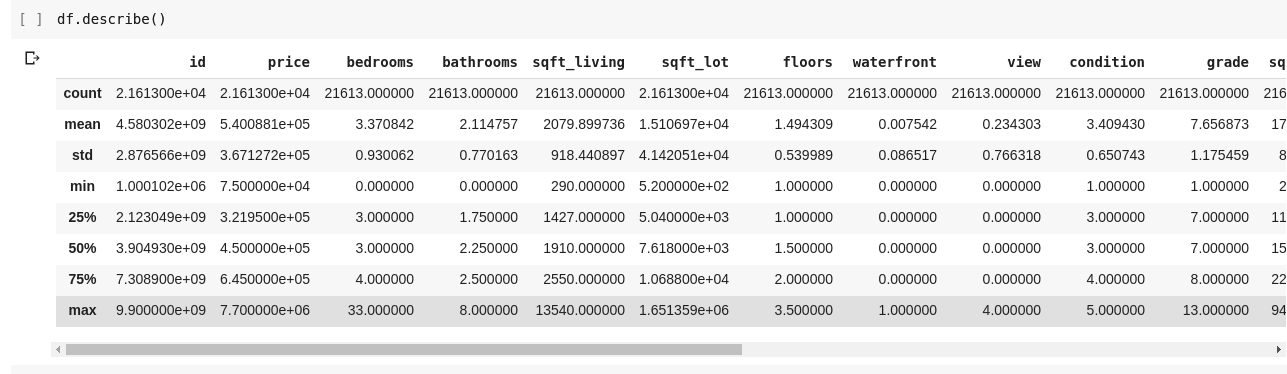
Observăm că funcția .describe() ne furnizează media, abaterea standard, valorile minime și maxime, precum și percentilele fiecărei coloane din DataFrame. Acest lucru este deosebit de util în analiza datelor.
Pentru a afla câte rânduri și coloane are DataFrame-ul nostru, putem verifica forma acestuia folosind df.shape. Această funcție returnează un tuplu în formatul (rânduri, coloane).
De asemenea, putem verifica numele tuturor coloanelor din DataFrame folosind df.columns.
Cum am putea selecta doar o singură coloană și să afișăm toate datele din ea? Acest lucru se realizează similar cu accesarea elementelor unui dicționar. Introduceți următorul cod într-o celulă nouă și executați-l:
df['price ']
Codul de mai sus afișează coloana ‘price’. Putem stoca această coloană într-o variabilă nouă, după cum urmează:
price = df['price']
Acum, putem efectua orice altă acțiune specifică DataFrame pe variabila price, deoarece aceasta reprezintă un subset al unui DataFrame. Putem folosi funcții precum df.head(), df.shape etc.
De asemenea, putem selecta mai multe coloane trecând o listă de nume de coloane în df, astfel:
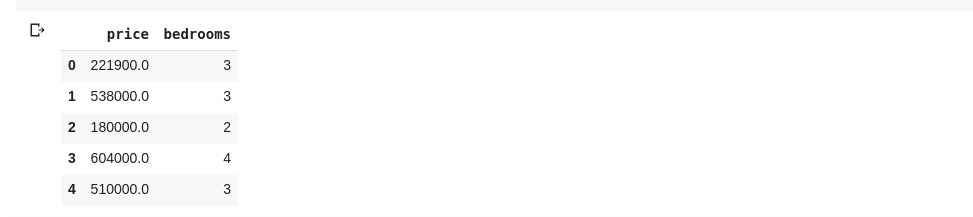
data = df[['price ', 'bedrooms']]
Codul de mai sus selectează coloanele denumite ‘price’ și ‘bedrooms’. Dacă introducem data.head() într-o celulă nouă, vom obține rezultatul următor:
Modul descris anterior de feliere a coloanelor returnează toate elementele rând din acea coloană. Ce se întâmplă dacă dorim să afișăm doar un subset de rânduri și un subset de coloane din setul nostru de date? Acest lucru poate fi realizat folosind .iloc, care funcționează similar cu indexarea listelor în Python. De exemplu, putem executa următorul cod:
df.iloc[50: , 3]
Acesta va returna a treia coloană începând cu rândul 50 până la final. Funcționează la fel ca felierea listelor în Python.
Acum, să facem ceva cu adevărat interesant. Setul nostru de date despre prețul locuințelor include o coloană cu prețul unei case și o altă coloană cu numărul de dormitoare. Prețul locuinței este o valoare continuă, deci este puțin probabil ca două case să aibă același preț. Însă numărul de dormitoare este o valoare discretă. Prin urmare, putem avea mai multe case cu două, trei sau patru dormitoare etc.
Cum am putea obține toate casele cu același număr de dormitoare și să aflăm prețul mediu pentru fiecare număr discret de dormitoare? Acest lucru este relativ ușor de realizat în Pandas. Se poate face astfel:
df.groupby('bedrooms ')['price '].mean()
Mai întâi, grupăm DataFrame-ul după seturile de date cu numărul identic de dormitoare, folosind funcția df.groupby(). Apoi, specificăm ca funcția să ne ofere doar coloana ‘bedrooms’ și utilizăm funcția .mean() pentru a găsi media fiecărei case din setul de date.
Dacă dorim să vizualizăm rezultatul obținut mai sus? Dacă vrem să observăm cum variază prețul mediu pentru fiecare număr distinct de dormitoare? Atunci putem conecta codul anterior la funcția .plot(), astfel:
df.groupby('bedrooms ')['price '].mean().plot()
Rezultatul obținut va arăta similar cu următorul:
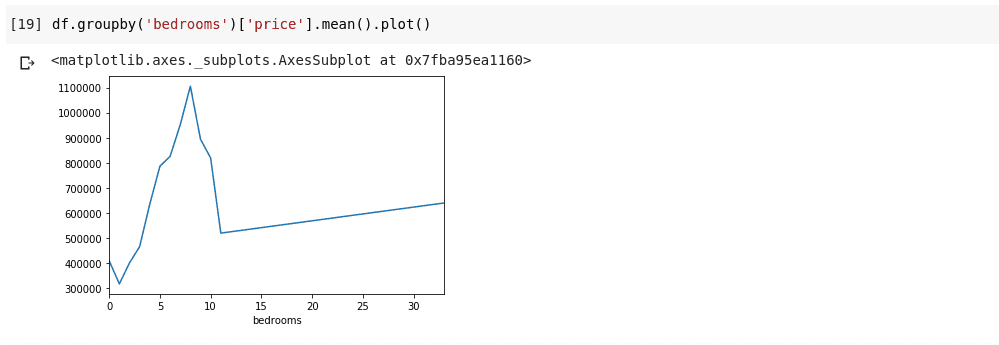
Graficul de mai sus ne prezintă câteva tendințe în cadrul datelor. Pe axa orizontală avem numărul distinct de dormitoare (reamintim că mai multe case pot avea același număr de dormitoare), iar pe axa verticală avem media prețurilor în funcție de numărul corespunzător de dormitoare de pe axa orizontală. Observăm că locuințele care au între 5 și 10 dormitoare sunt semnificativ mai scumpe decât cele cu 3 dormitoare. De asemenea, este evident că locuințele cu aproximativ 7 sau 8 dormitoare au prețuri considerabil mai mari decât cele cu 15, 20 sau chiar 30 de camere.
Aceste informații evidențiază importanța analizei datelor. Putem extrage informații utile din date care nu sunt evidente imediat și care ar fi chiar imposibil de observat fără analiză.
Date lipsă
Să presupunem că efectuăm un sondaj care constă dintr-o serie de întrebări. Distribuiți un link către sondaj unui număr mare de persoane pentru a obține feedback-ul lor. Obiectivul final este de a realiza o analiză a datelor colectate pentru a obține informații cheie.
În cadrul acestui proces, pot apărea diverse probleme. Unii respondenți se pot simți inconfortabil să răspundă la anumite întrebări și le pot lăsa necompletate. Mulți alții pot face același lucru pentru diferite părți ale chestionarului. Deși acest lucru poate părea nesemnificativ, imaginați-vă că ați colecta date numerice în sondaj și o parte a analizei necesită calculul sumei, mediei sau alte operații aritmetice. Prezența mai multor valori lipsă ar duce la o serie de inexactități în analiza datelor. Prin urmare, este necesară o modalitate de a identifica și înlocui aceste valori lipsă cu unele valori care ar putea reprezenta o aproximație a valorilor reale.
Pandas ne oferă funcția isnull() pentru a identifica valorile lipsă într-un DataFrame.
Funcția isnull() poate fi folosită astfel:
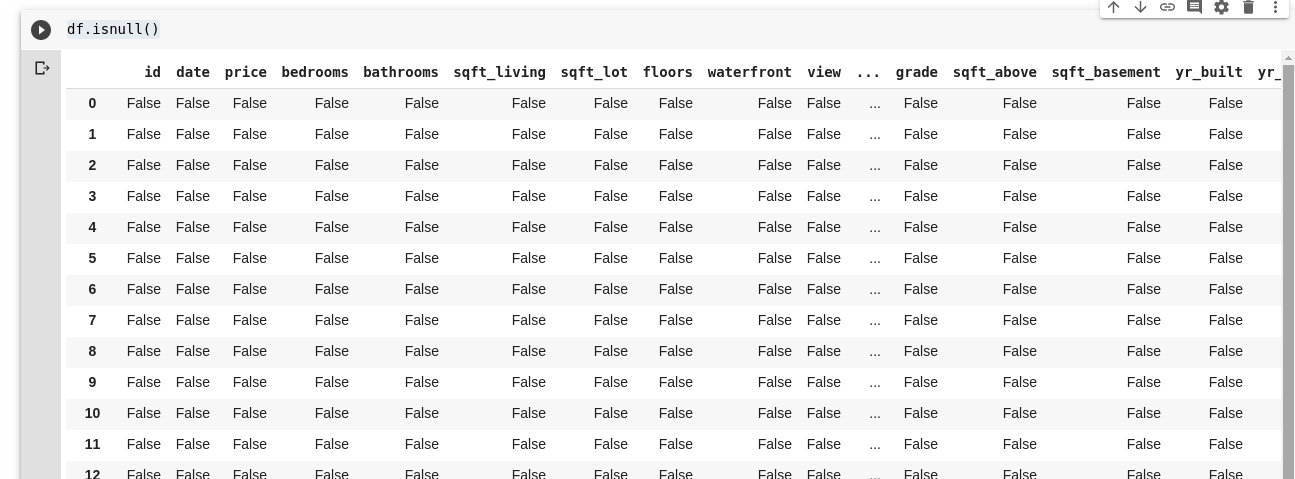
df.isnull()
Aceasta returnează un DataFrame cu valori boolean, indicând dacă datele prezente inițial au fost într-adevăr lipsă sau nu. Rezultatul ar arăta astfel:
Pentru a înlocui toate aceste valori lipsă, de obicei se alege valoarea zero. Uneori, valoarea lipsă poate fi înlocuită cu media tuturor celorlalte date sau cu media valorilor învecinate, în funcție de cercetătorul de date și de utilizarea datelor analizate.
Pentru a completa toate valorile lipsă dintr-un DataFrame, folosim funcția .fillna(), astfel:
df.fillna(0)
În codul de mai sus, am înlocuit toate valorile goale cu valoarea zero. Putem utiliza orice alt număr dorit.
Importanța datelor este evidentă. Ele ne ajută să obținem răspunsuri relevante din informațiile pe care le avem. Analiza datelor, așa cum se spune, este noul petrol al economiilor digitale.
Toate exemplele din acest articol pot fi găsite aici.
Pentru a aprofunda subiectul, consultați cursul online de analiză a datelor cu Python și Pandas.