
Scikit-LLM este un pachet Python care ajută la integrarea modelelor de limbaj mari (LLM) în cadrul scikit-learn. Ajută la îndeplinirea sarcinilor de analiză a textului. Dacă sunteți familiarizat cu scikit-learn, vă va fi mai ușor să lucrați cu Scikit-LLM.
Este important de reținut că Scikit-LLM nu înlocuiește scikit-learn. scikit-learn este o bibliotecă de învățare automată de uz general, dar Scikit-LLM este conceput special pentru sarcini de analiză a textului.
Cuprins
Noțiuni introductive cu Scikit-LLM
Pentru a începe cu Scikit-LLM, va trebui să instalați biblioteca și să configurați cheia API. Pentru a instala biblioteca, deschideți IDE-ul și creați un nou mediu virtual. Acest lucru va ajuta la prevenirea eventualelor conflicte de versiuni ale bibliotecii. Apoi, executați următoarea comandă în terminal.
pip install scikit-llm
Această comandă va instala Scikit-LLM și dependențele necesare.
Pentru a vă configura cheia API, trebuie să achiziționați una de la furnizorul LLM. Pentru a obține cheia API OpenAI, urmați acești pași:
Continuați la Pagina API OpenAI. Apoi faceți clic pe profilul dvs. situat în colțul din dreapta sus al ferestrei. Selectați Vizualizați cheile API. Aceasta vă va duce la pagina cheilor API.
Pe pagina de chei API, faceți clic pe butonul Creare cheie secretă nouă.
Denumiți-vă cheia API și faceți clic pe butonul Creare cheie secretă pentru a genera cheia. După generare, trebuie să copiați cheia și să o păstrați într-un loc sigur, deoarece OpenAI nu va afișa cheia din nou. Dacă îl pierdeți, va trebui să generați unul nou.
Acum că aveți cheia API, deschideți IDE-ul și importați clasa SKLLMConfig din biblioteca Scikit-LLM. Această clasă vă permite să setați opțiuni de configurare legate de utilizarea modelelor de limbaj mari.
from skllm.config import SKLLMConfig
Această clasă se așteaptă să setați cheia API OpenAI și detaliile organizației.
SKLLMConfig.set_openai_key("Your API key")
SKLLMConfig.set_openai_org("Your organization ID")
ID-ul organizației și numele nu sunt același. ID-ul organizației este un identificator unic al organizației dvs. Pentru a obține ID-ul organizației dvs., treceți la Organizația OpenAI pagina de setări și copiați-o. Acum ați stabilit o conexiune între Scikit-LLM și modelul de limbaj mare.
Scikit-LLM vă solicită să aveți un plan cu plata pe măsură. Acest lucru se datorează faptului că contul de încercare gratuită OpenAI are o limită de rată de trei solicitări pe minut, ceea ce nu este suficient pentru Scikit-LLM.
Încercarea de a utiliza contul de probă gratuită va duce la o eroare similară cu cea de mai jos în timpul analizei textului.

Pentru a afla mai multe despre limitele ratelor. Continuați la Pagina cu limitele ratei OpenAI.
Furnizorul LLM nu se limitează doar la OpenAI. Puteți folosi și alți furnizori LLM.
Importarea bibliotecilor necesare și încărcarea setului de date
Importați panda pe care le veți folosi pentru a încărca setul de date. De asemenea, din Scikit-LLM și scikit-learn, importați clasele necesare.
import pandas as pd
from skllm import ZeroShotGPTClassifier, MultiLabelZeroShotGPTClassifier
from skllm.preprocessing import GPTSummarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import MultiLabelBinarizer
Apoi, încărcați setul de date pe care doriți să efectuați analiza textului. Acest cod folosește setul de date pentru filme IMDB. Cu toate acestea, îl puteți modifica pentru a utiliza propriul set de date.
data = pd.read_csv("imdb_movies_dataset.csv")
data = data.head(100)
Utilizarea numai a primelor 100 de rânduri ale setului de date nu este obligatorie. Puteți utiliza întregul set de date.
Apoi, extrageți caracteristicile și etichetați coloanele. Apoi împărțiți setul de date în seturi de tren și de testare.
X = data['Description']y = data['Genre']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Coloana Gen conține etichetele pe care doriți să le preziceți.
Clasificarea textului Zero-Shot cu Scikit-LLM
Clasificarea textului zero-shot este o caracteristică oferită de modelele mari de limbă. Clasifică textul în categorii predefinite fără a fi nevoie de instruire explicită asupra datelor etichetate. Această capacitate este foarte utilă atunci când aveți de-a face cu sarcini în care trebuie să clasificați textul în categorii pe care nu le-ați anticipat în timpul antrenamentului de model.
Pentru a efectua clasificarea textului zero-shot folosind Scikit-LLM, utilizați clasa ZeroShotGPTClassifier.
zero_shot_clf = ZeroShotGPTClassifier(openai_model="gpt-3.5-turbo")
zero_shot_clf.fit(X_train, y_train)
zero_shot_predictions = zero_shot_clf.predict(X_test)
print("Zero-Shot Text Classification Report:")
print(classification_report(y_test, zero_shot_predictions))
Ieșirea este după cum urmează:
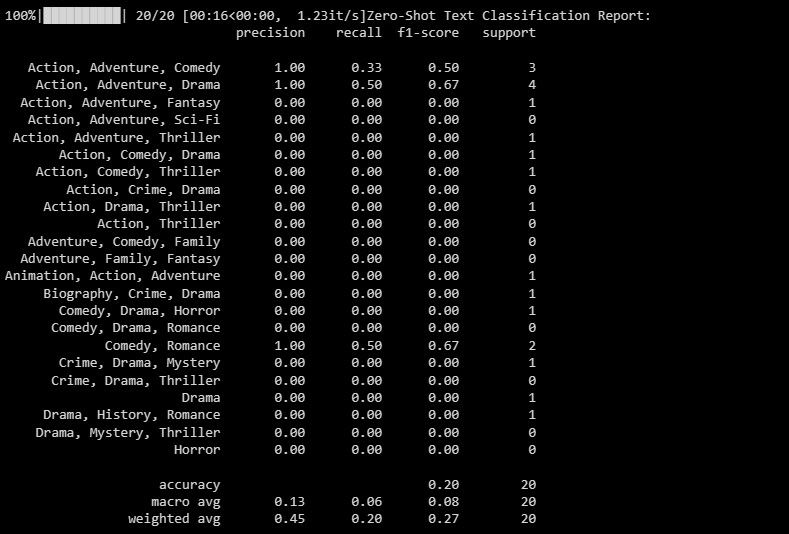
Raportul de clasificare oferă valori pentru fiecare etichetă pe care modelul încearcă să o prezică.
Clasificare text Zero-Shot cu mai multe etichete cu Scikit-LLM
În unele scenarii, un singur text poate aparține mai multor categorii simultan. Modelele tradiționale de clasificare se luptă cu acest lucru. Scikit-LLM, pe de altă parte, face posibilă această clasificare. Clasificarea textului zero-shot cu mai multe etichete este crucială în atribuirea mai multor etichete descriptive unui singur eșantion de text.
Utilizați MultiLabelZeroShotGPTClassifier pentru a estima ce etichete sunt adecvate pentru fiecare eșantion de text.
candidate_labels = ["Action", "Comedy", "Drama", "Horror", "Sci-Fi"]
multi_label_zero_shot_clf = MultiLabelZeroShotGPTClassifier(max_labels=2)
multi_label_zero_shot_clf.fit(X_train, candidate_labels)
multi_label_zero_shot_predictions = multi_label_zero_shot_clf.predict(X_test)
mlb = MultiLabelBinarizer()
y_test_binary = mlb.fit_transform(y_test)
multi_label_zero_shot_predictions_binary = mlb.transform(multi_label_zero_shot_predictions)
print("Multi-Label Zero-Shot Text Classification Report:")
print(classification_report(y_test_binary, multi_label_zero_shot_predictions_binary))
În codul de mai sus, definiți etichetele candidate cărora le-ar putea aparține textul dvs.
Ieșirea este așa cum se arată mai jos:
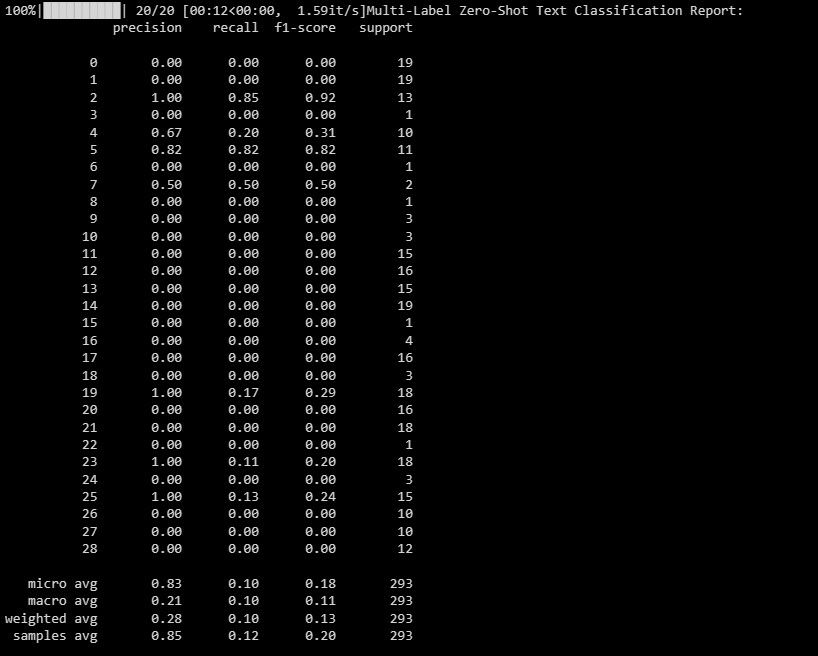
Acest raport vă ajută să înțelegeți cât de bine funcționează modelul dvs. pentru fiecare etichetă din clasificarea cu mai multe etichete.
Vectorizarea textului cu Scikit-LLM
În vectorizarea textului, datele textuale sunt convertite într-un format numeric pe care modelele de învățare automată îl pot înțelege. Scikit-LLM oferă GPTVectorizer pentru aceasta. Vă permite să transformați textul în vectori cu dimensiuni fixe folosind modele GPT.
Puteți realiza acest lucru utilizând Frecvența Termenului-Frecvența Documentului invers.
tfidf_vectorizer = TfidfVectorizer(max_features=1000)
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train)
X_test_tfidf = tfidf_vectorizer.transform(X_test)
print("TF-IDF Vectorized Features (First 5 samples):")
print(X_train_tfidf[:5])
Iată rezultatul:
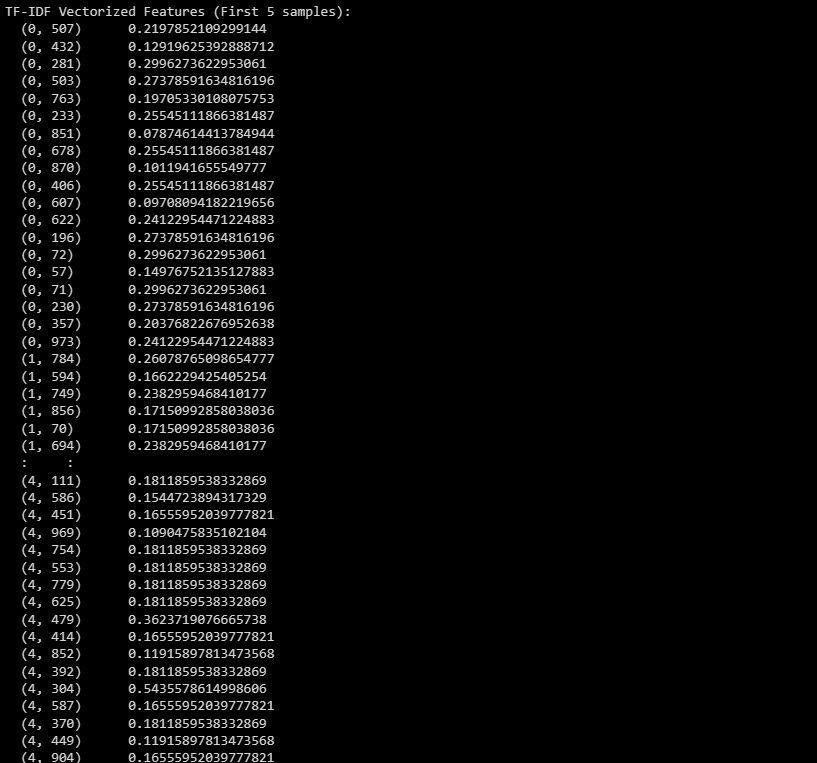
Ieșirea reprezintă caracteristicile vectorizate TF-IDF pentru primele 5 eșantioane din setul de date.
Rezumat text cu Scikit-LLM
Rezumarea textului ajută la condensarea unei porțiuni de text, păstrând în același timp informațiile cele mai importante. Scikit-LLM oferă GPTSummarizer, care utilizează modelele GPT pentru a genera rezumate concise ale textului.
summarizer = GPTSummarizer(openai_model="gpt-3.5-turbo", max_words=15)
summaries = summarizer.fit_transform(X_test)
print(summaries)
Ieșirea este după cum urmează:
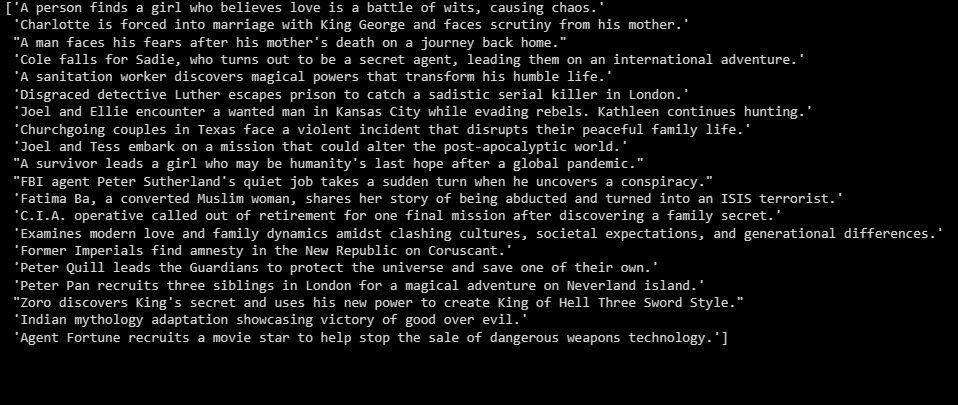
Cele de mai sus sunt un rezumat al datelor de testare.
Creați aplicații pe partea de sus a LLM-urilor
Scikit-LLM deschide o lume de posibilități pentru analiza textului cu modele mari de limbaj. Înțelegerea tehnologiei din spatele modelelor de limbaj mari este crucială. Vă va ajuta să înțelegeți punctele lor tari și punctele slabe care vă pot ajuta să construiți aplicații eficiente pe deasupra acestei tehnologii de ultimă oră.