

Web scraping vă permite să culegeți eficient cantități mari de date de pe internet într-o manieră foarte rapidă și este deosebit de utilă în cazurile în care site-urile web nu își expun datele într-un mod structurat prin utilizarea Interfețelor de programare a aplicațiilor (API).
De exemplu, imaginați-vă că creați o aplicație care compară prețurile articolelor de pe site-urile de comerț electronic. Cum ai proceda cu asta? O modalitate este să verificați manual prețul articolelor pe toate site-urile și să vă înregistrați constatările. Cu toate acestea, aceasta nu este o modalitate inteligentă, deoarece există mii de produse pe platformele de comerț electronic și îți va lua o veșnicie să extragi date relevante.
O modalitate mai bună de a face acest lucru este prin eliminarea web. Web scraping este procesul de extragere automată a datelor din pagini web și site-uri web prin utilizarea unui software.
Scripturile software, denumite web scrapers, sunt folosite pentru a accesa site-uri web și pentru a prelua date de pe site-uri web. Datele preluate, de obicei într-o formă nestructurată, pot fi apoi analizate și stocate într-un mod structurat, care este semnificativ pentru utilizatori.
Web scraping este foarte valoros în extragerea datelor, deoarece oferă acces la o mulțime de date și permite automatizarea, astfel încât să puteți programa scriptul de web scraping să ruleze la anumite momente sau ca răspuns la anumite declanșatoare. Web scraping vă permite, de asemenea, să obțineți actualizări în timp real și ușurează efectuarea de cercetări de piață.

Multe companii și companii se bazează pe web scraping pentru a extrage date pentru analiză. Companiile specializate în resurse umane, comerț electronic, finanțe, imobiliare, călătorii, rețele sociale și cercetare folosesc web scraping pentru a extrage date relevante de pe site-uri web.
Google însuși folosește web scraping pentru a indexa site-urile web de pe internet, astfel încât să poată oferi utilizatorilor rezultate relevante de căutare.
Cu toate acestea, este important să fiți precauți atunci când dezafectați web. Deși eliminarea datelor accesibile publicului nu este ilegală, unele site-uri web nu permit eliminarea. Acest lucru s-ar putea datora faptului că dețin informații sensibile despre utilizator, termenii și condițiile lor interzic în mod explicit casarea web sau protejează proprietatea intelectuală.
În plus, unele site-uri web nu permit web scraping, deoarece poate supraîncărca serverul site-ului web și poate duce la creșterea costurilor lățimii de bandă, mai ales atunci când web scraping se face la scară.
Pentru a verifica dacă un site web poate fi abandonat, adăugați robots.txt la adresa URL a site-ului. robots.txt este folosit pentru a indica roboților care părți ale site-ului pot fi răzuite. De exemplu, pentru a verifica dacă puteți analiza Google, accesați google.com/robots.txt
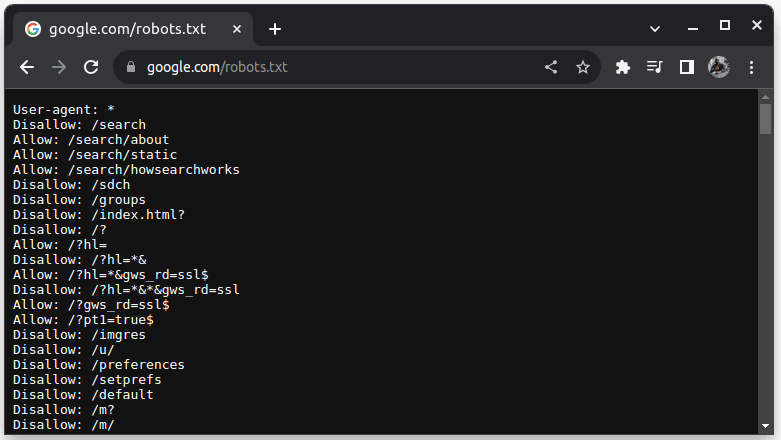
User-agent: * se referă la toți roboții sau scripturile software și crawlerele. Disallow este folosit pentru a spune roboților că nu pot accesa nicio adresă URL dintr-un director, de exemplu /search. Allow indică directoarele de unde pot accesa adresele URL.
Un exemplu de site care nu permite scraping este LinkedIn. Pentru a verifica dacă puteți analiza LinkedIn, accesați linkedin.com/robots.txt
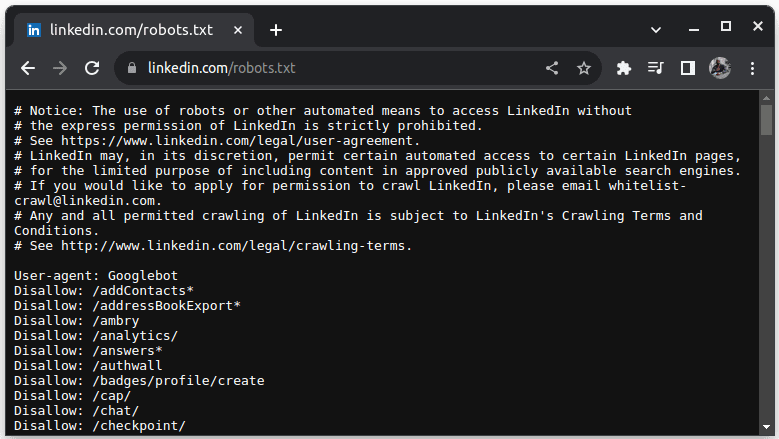
După cum puteți vedea, nu aveți voie să răzuiți LinkedIn fără permisiunea lor. Verificați întotdeauna dacă un site web permite scraping pentru a evita orice probleme juridice.
Cuprins
De ce Java este un limbaj potrivit pentru Web Scraping
În timp ce puteți crea un web scraper cu o varietate de limbaje de programare, Java este deosebit de ideal pentru job din mai multe motive. În primul rând, Java are un ecosistem bogat și o comunitate mare și oferă o varietate de biblioteci de web scraping, cum ar fi JSoup, WebMagic și HTMLUnit, care facilitează scrierea de web scrapers.

De asemenea, oferă biblioteci de analiză HTML pentru a simplifica procesul de extragere a datelor din documente HTML și biblioteci de rețea, cum ar fi HttpURLConnection, pentru a face solicitări către diferite adrese URL de site-uri web.
Suportul puternic al Java pentru concurență și multithreading este, de asemenea, benefic în scraping-ul web, deoarece permite procesarea paralelă și gestionarea sarcinilor web scraping cu mai multe solicitări, permițându-vă să scraping mai multe pagini simultan. Având în vedere că scalabilitatea este un punct forte cheie al Java, puteți răzui confortabil site-uri web la o scară masivă folosind un scraper web scris în Java.
Suportul multiplatformă Java este, de asemenea, util, deoarece vă permite să scrieți un web scraper și să îl rulați în orice sistem care are o mașină virtuală Java compatibilă. Prin urmare, puteți scrie un web scraper într-un sistem de operare sau dispozitiv și îl puteți rula într-un alt sistem de operare fără a fi nevoie să modificați web scraper.
Java poate fi folosit și cu browsere fără headless, cum ar fi Headless Chrome, HTML Unit, Headless Firefox și PhantomJs, printre altele. Un browser fără cap este un browser fără interfață grafică de utilizator. Browserele fără cap pot simula interacțiunile utilizatorului și sunt foarte utile atunci când răzuiesc site-uri web care necesită interacțiuni ale utilizatorului.
Pentru a acoperi totul, Java este un limbaj foarte popular și utilizat pe scară largă, care este acceptat și poate fi integrat cu ușurință cu o varietate de instrumente, cum ar fi baze de date și cadre de procesare a datelor. Acest lucru este benefic, deoarece asigură că, pe măsură ce răzuiți datele, toate instrumentele de care veți avea nevoie pentru răzuire, procesare și stocare a datelor vor suporta probabil Java.
Să vedem cum putem folosi Java pentru casarea web.
Java pentru Web Scraping: Cerințe preliminare
Pentru a utiliza Java în web scraping, trebuie îndeplinite următoarele cerințe preliminare:
1. Java – ar trebui să aveți instalat Java, de preferință cea mai recentă versiune de asistență pe termen lung. În cazul în care nu aveți Java instalat, accesați instalarea Java pentru a afla cum să instalați Java în mașina dvs
2. Mediu de dezvoltare integrat (IDE) – Ar trebui să aveți un IDE instalat pe computer. În acest tutorial, vom folosi IntelliJ IDEA, dar puteți folosi orice IDE cu care sunteți familiarizat.
3. Maven – acesta va fi folosit pentru gestionarea dependențelor și pentru a instala o bibliotecă web scraping.
În cazul în care nu aveți Maven instalat, îl puteți instala deschizând terminalul și executând:
sudo apt install maven
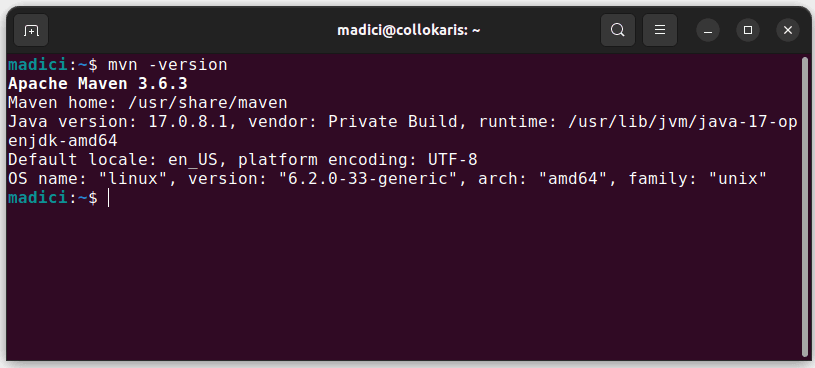
Aceasta instalează Maven din depozitul oficial. Puteți confirma că Maven a fost instalat cu succes executând:
mvn -version
În cazul în care instalarea a avut succes, ar trebui să obțineți o astfel de ieșire:
Configurarea mediului
Pentru a vă configura mediul:
1. Deschideți IntelliJ IDEA. În bara de meniu din stânga, faceți clic pe Proiecte, apoi selectați Proiect nou.
2. În fereastra Proiect nou care se deschide, completați-o așa cum se arată mai jos. Asigurați-vă că limbajul este setat la Java și sistemul de compilare la Maven. Puteți da proiectului orice nume doriți, apoi utilizați Locație pentru a specifica folderul în care doriți să fie creat proiectul. După ce ați terminat, faceți clic pe Creare.
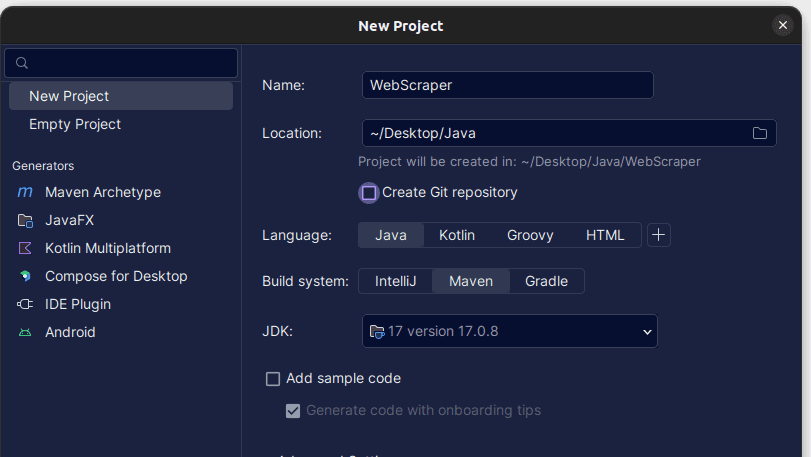
3. Odată ce proiectul dvs. este creat, ar trebui să aveți un pom.xml în proiect, așa cum se arată mai jos.
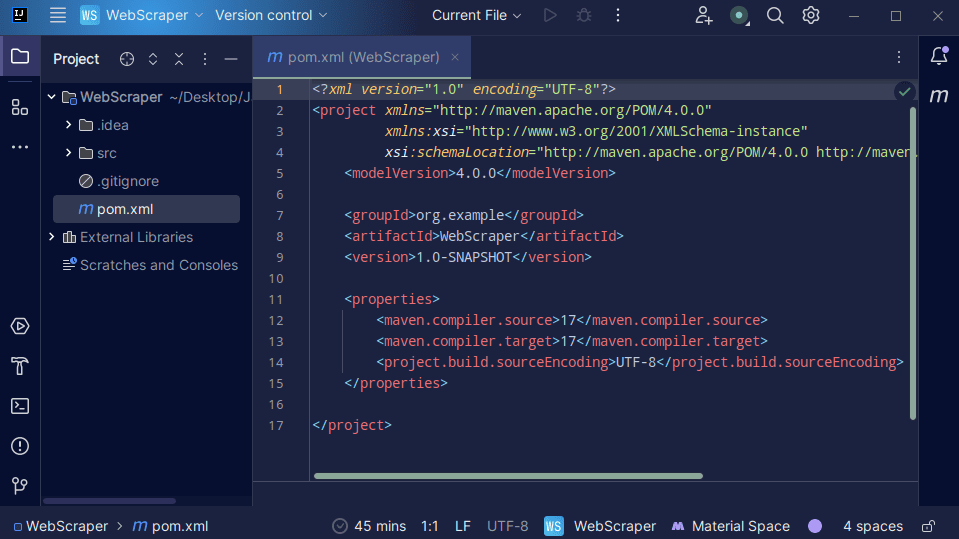
Fișierul pom.xml este creat de Maven și conține informații despre proiect și detalii de configurare utilizate de Maven pentru a construi proiectul. Acesta este fișierul pe care îl folosim și pentru a indica faptul că vom folosi biblioteci externe.
În construirea unui web scraper, vom folosi biblioteca jsoup. Prin urmare, trebuie să-l adăugăm ca dependență în fișierul pom.xml, astfel încât Maven să îl poată face disponibil în proiectul nostru.
4. Adăugați dependența jsoup în fișierul pom.xml prin copierea codului de mai jos și adăugându-l în fișierul pom.xml
<dependencies>
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.16.1</version>
</dependency>
</dependencies>
Rezultatul ar trebui să fie așa cum se arată mai jos:
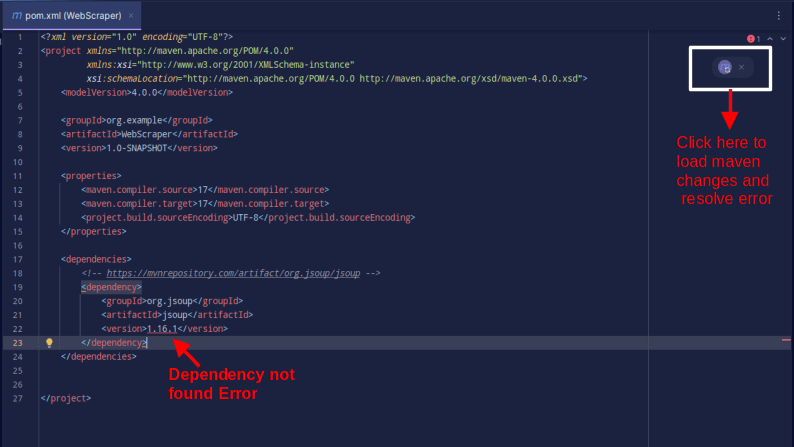
În cazul în care întâmpinați o eroare care spune că dependența nu poate fi găsită, faceți clic pe pictograma indicată pentru ca Maven să încarce modificările efectuate, să încarce dependența și să elimine eroarea.
Cu asta, mediul tău este complet configurat.
Web Scraping cu Java
Pentru web scraping, vom elimina datele din ScrapeThisSitecare oferă un sandbox în care dezvoltatorii pot practica web scraping fără a avea probleme legale.
Pentru a răzui un site web folosind Java
1. În bara de meniu din stânga a IntelliJ, deschideți directorul src, apoi directorul principal, care se află în directorul src. Directorul principal conține un director numit java; faceți clic dreapta pe el și selectați Nou, apoi Clasă Java
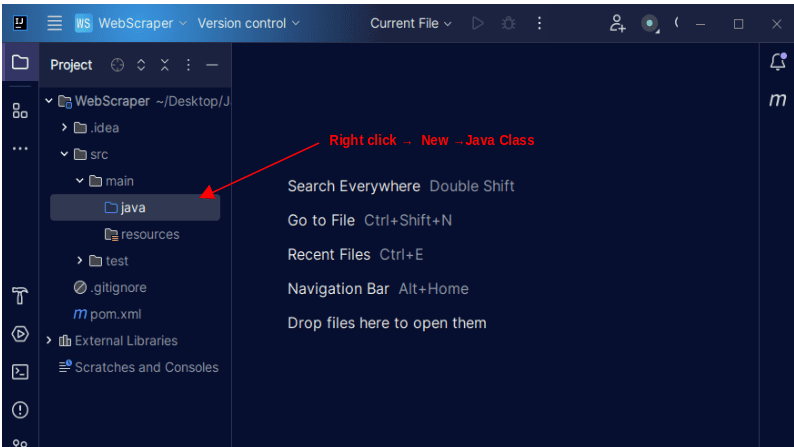
Dați clasei orice nume doriți, cum ar fi WebScraper, apoi apăsați Enter pentru a crea o nouă clasă Java.
Deschideți fișierul nou creat care conține clasele Java pe care tocmai le-ați creat.
2. Web scraping implică obținerea de date de pe site-uri web. Prin urmare, trebuie să specificăm adresa URL de la care dorim să extragem datele. Odată ce specificăm adresa URL, trebuie să ne conectăm la adresa URL și să facem o solicitare GET pentru a prelua conținutul HTML al paginii.
Codul care face acest lucru este prezentat mai jos:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
System.out.println(doc);
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
Ieșire:
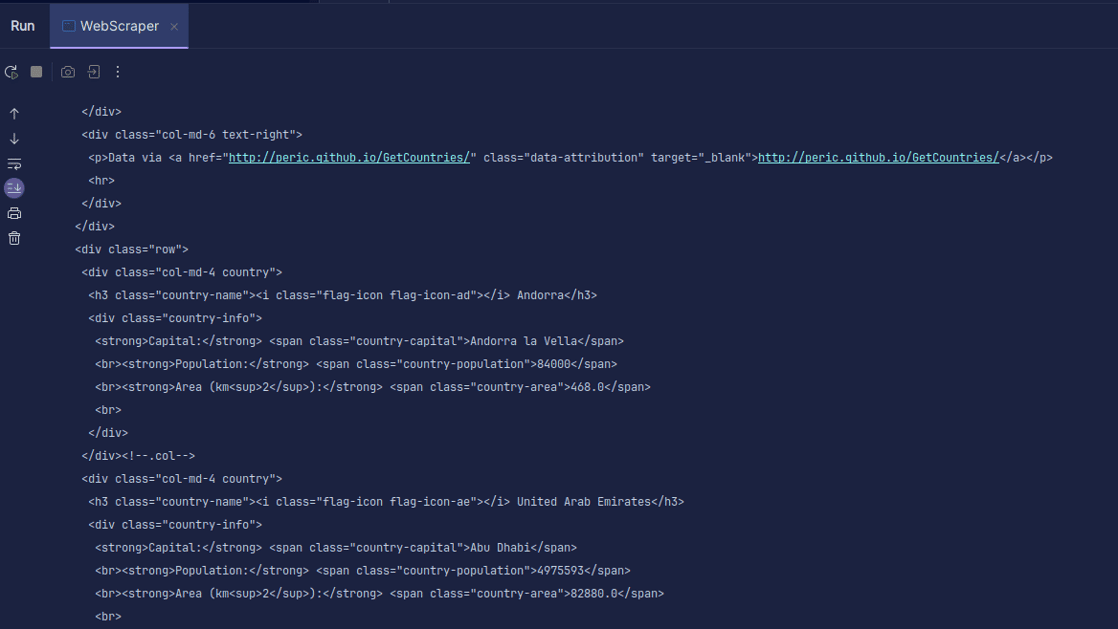
După cum puteți vedea, HTML-ul paginii este returnat și este ceea ce imprimăm. Când răzuiți, adresa URL pe care o specificați poate avea o eroare, iar resursa pe care încercați să o eliminați poate să nu existe deloc. De aceea este important să ne înfășurăm codul într-o declarație try-catch.
Linia:
Document doc = Jsoup.connect(url).get();
Este folosit pentru a vă conecta pentru a vă conecta la adresa URL pe care doriți să o răzuiți. Metoda get() este folosită pentru a face o cerere GET și pentru a prelua codul HTML de pe pagină. Rezultatul returnat este apoi stocat într-un obiect Document JSOUP, numit doc. Stocarea rezultatului într-un document JSOUP vă permite să utilizați API-ul JSOUP pentru a manipula HTML-ul returnat.
3. Accesați ScrapeThisSite și inspectați pagina. În HTML, ar trebui să vedeți structura prezentată mai jos:
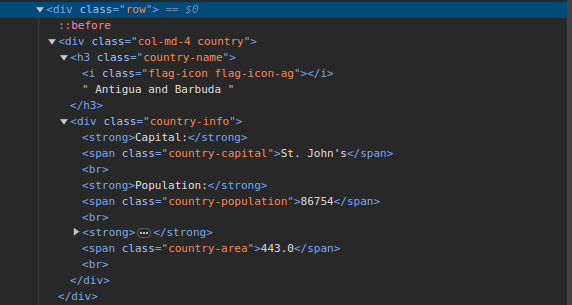
Observați că toate țările de pe pagină sunt stocate într-o structură similară. Există un div cu o clasă numită țară cu un element h3 cu o clasă de nume-țară care conține numele fiecărei țări de pe pagină.
În interiorul div-ului principal, există un alt div cu o clasă de informații despre țară și conține informații precum capitala, populația și zona țării. Putem folosi aceste nume de clasă pentru a selecta elementele HTML și a extrage informații din ele.
4. Extrageți conținut specific din HTML de pe pagină folosind următoarele rânduri:
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " Population - " + population);
}
Folosim metoda select() pentru a selecta elemente din HTML-ul paginii care se potrivesc cu selectorul CSS specific pe care îl trecem. În cazul nostru, trecem numele claselor. Din inspectarea paginii, am văzut că toate informațiile despre țară de pe pagină sunt stocate sub un div cu o clasă de țară.
Fiecare țară are propriul div cu o clasă de țară, iar div-ul conține informații precum numele țării, capitala și populația.
Prin urmare, selectăm mai întâi toate țările de pe pagină folosind clasa .country. Apoi stocăm acest lucru într-o variabilă numită țări de tip Elemente, care funcționează la fel ca o listă. Apoi folosim o buclă pentru a parcurge țări și a extrage numele țării, capitala și populația și tipărim ceea ce este găsit.
Întreaga noastră bază de cod este prezentată mai jos:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " - Population - " + population);
}
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
Ieșire:
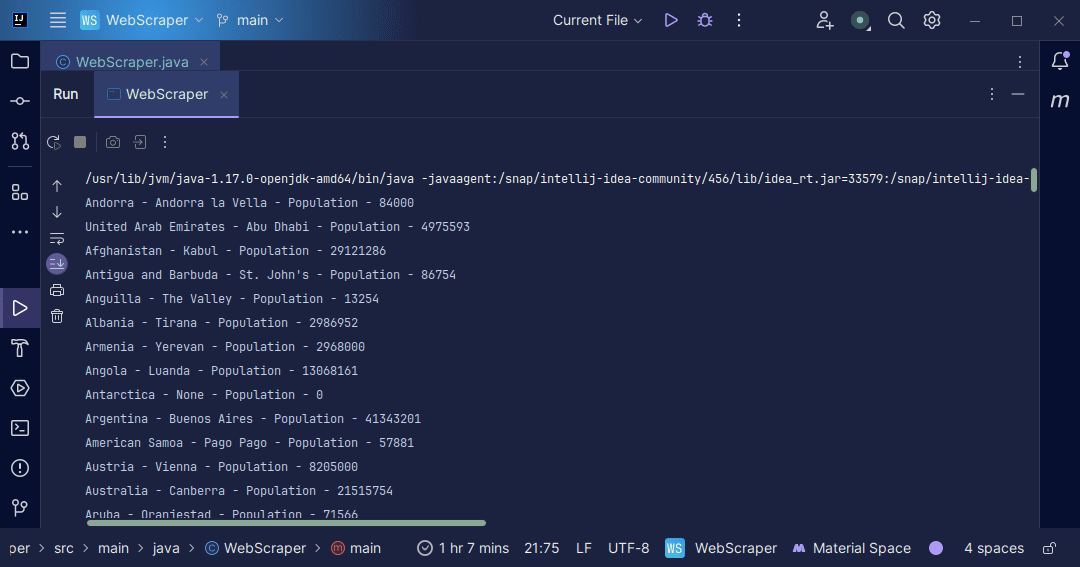
Cu informațiile pe care le primim de pe pagină, putem face o varietate de lucruri, cum ar fi să le imprimăm așa cum tocmai am făcut-o sau să le stocăm într-un fișier în cazul în care dorim să facem o prelucrare ulterioară a datelor.
Concluzie
Web scraping este o modalitate excelentă de a extrage date nestructurate de pe site-uri web, de a stoca datele într-un mod structurat și de a procesa datele pentru a extrage informații semnificative. Cu toate acestea, este important să fiți precauți atunci când faceți scraping pe web, deoarece anumite site-uri web nu permit scrapingul pe web.
Pentru a fi în siguranță, utilizați site-uri web care oferă casete cu nisip pentru a practica casarea. În caz contrar, inspectați întotdeauna fișierul robots.txt al fiecărui site web pe care doriți să îl răzuiți pentru a afla dacă site-ul web permite casarea.
când scrieți web scrapper, Java este un limbaj excelent, deoarece oferă biblioteci care fac scrapingul web mai ușor și mai eficient. În calitate de dezvoltator Java, construirea unui web scraper vă va ajuta să vă dezvoltați și mai mult abilitățile de programare. Așa că mergeți mai departe și scrieți propriul dvs. web scrapper sau modificați-l pe cel folosit în articol pentru a extrage diferite tipuri de informații. Codare fericită!
De asemenea, puteți explora câteva soluții populare de web scraping bazate pe cloud.