
Regresia și clasificarea sunt două dintre cele mai fundamentale și semnificative domenii ale învățării automate.
Poate fi dificil să faci distincția între algoritmii de regresie și clasificare atunci când abia te apuci de învățarea automată. Înțelegerea modului în care acești algoritmi funcționează și când să îi folosească poate fi crucială pentru a face predicții precise și a lua decizii eficiente.
În primul rând, să vedem despre învățarea automată.
Cuprins
Ce este învățarea automată?
Învățarea automată este o metodă de a preda computerele să învețe și să ia decizii fără a fi programate în mod explicit. Aceasta implică antrenarea unui model de computer pe un set de date, permițând modelului să facă predicții sau decizii bazate pe modele și relații din date.
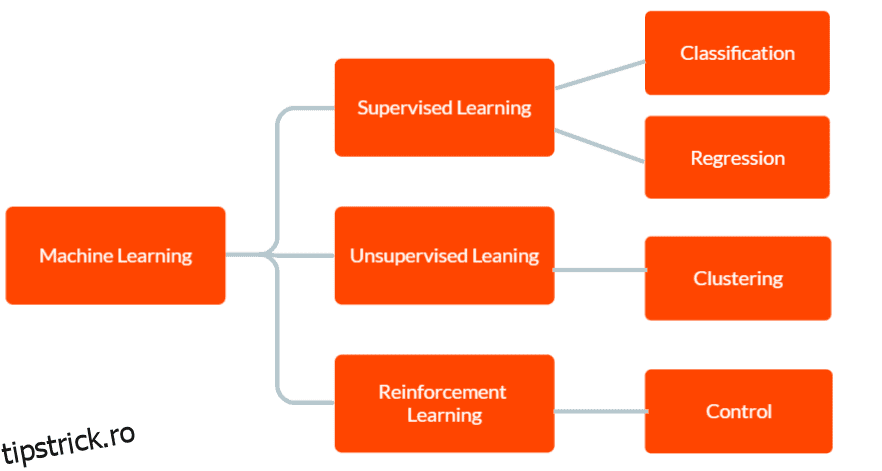
Există trei tipuri principale de învățare automată: învățare supravegheată, învățare nesupravegheată și învățare prin consolidare.
În învățarea supravegheată, modelul este furnizat cu date de antrenament etichetate, inclusiv date de intrare și ieșirea corectă corespunzătoare. Scopul este ca modelul să facă predicții despre rezultatul pentru date noi, nevăzute, pe baza modelelor pe care le-a învățat din datele de antrenament.
În învățarea nesupravegheată, modelului nu i se oferă date de antrenament etichetate. În schimb, este lăsat să descoperiți modele și relații în date în mod independent. Acesta poate fi folosit pentru a identifica grupuri sau clustere în date sau pentru a găsi anomalii sau modele neobișnuite.
Și în Reinforcement Learning, un agent învață să interacționeze cu mediul său pentru a maximiza o recompensă. Implică antrenarea unui model pentru a lua decizii pe baza feedback-ului pe care îl primește de la mediu.
Învățarea automată este utilizată în diverse aplicații, inclusiv recunoașterea imaginilor și a vorbirii, procesarea limbajului natural, detectarea fraudelor și mașini cu conducere autonomă. Are potențialul de a automatiza multe sarcini și de a îmbunătăți procesul decizional în diverse industrii.
Acest articol se concentrează în principal pe conceptele de clasificare și regresie, care fac parte din învățarea automată supravegheată. Să începem!
Clasificare în Machine Learning

Clasificarea este o tehnică de învățare automată care implică antrenarea unui model pentru a atribui o etichetă de clasă unei date date. Este o sarcină de învățare supravegheată, ceea ce înseamnă că modelul este antrenat pe un set de date etichetat care include exemple de date de intrare și etichetele de clasă corespunzătoare.
Modelul urmărește să învețe relația dintre datele de intrare și etichetele clasei pentru a prezice eticheta clasei pentru o intrare nouă, nevăzută.
Există mulți algoritmi diferiți care pot fi utilizați pentru clasificare, inclusiv regresia logistică, arbori de decizie și mașini vectori suport. Alegerea algoritmului va depinde de caracteristicile datelor și de performanța dorită a modelului.
Unele aplicații comune de clasificare includ detectarea spam-ului, analiza sentimentelor și detectarea fraudelor. În fiecare dintre aceste cazuri, datele de intrare pot include text, valori numerice sau o combinație a ambelor. Etichetele de clasă pot fi binare (de exemplu, spam sau nu spam) sau multiclase (de exemplu, sentiment pozitiv, neutru, negativ).
De exemplu, luați în considerare un set de date de recenzii ale clienților despre un produs. Datele de intrare pot fi textul recenziei, iar eticheta clasei poate fi o evaluare (de exemplu, pozitiv, neutru, negativ). Modelul ar fi instruit pe un set de date de recenzii etichetate și apoi ar putea prezice evaluarea unei noi recenzii pe care nu a văzut-o înainte.
Tipuri de algoritmi de clasificare ML
Există mai multe tipuri de algoritmi de clasificare în învățarea automată:
Regresie logistică
Acesta este un model liniar utilizat pentru clasificarea binară. Este folosit pentru a prezice probabilitatea ca un anumit eveniment să se producă. Scopul regresiei logistice este de a găsi cei mai buni coeficienți (greutăți) care minimizează eroarea dintre probabilitatea prezisă și rezultatul observat.
Acest lucru se face prin utilizarea unui algoritm de optimizare, cum ar fi coborârea gradientului, pentru a ajusta coeficienții până când modelul se potrivește cât mai bine cu datele de antrenament.
Arbori de decizie
Acestea sunt modele de tip arbore care iau decizii pe baza valorilor caracteristicilor. Ele pot fi utilizate atât pentru clasificarea binară, cât și pentru clasificarea multiclasă. Arborii de decizie au mai multe avantaje, inclusiv simplitatea și interoperabilitatea lor.
De asemenea, sunt rapid de antrenat și de a face predicții și pot gestiona atât date numerice, cât și date categoriale. Cu toate acestea, pot fi predispuse la supraadaptare, mai ales dacă copacul este adânc și are multe ramuri.
Clasificarea aleatorie a pădurilor
Clasificarea aleatorie a pădurilor este o metodă de ansamblu care combină predicțiile mai multor arbori de decizie pentru a face o predicție mai precisă și mai stabilă. Este mai puțin predispus la supraadaptare decât un singur arbore de decizie, deoarece predicțiile arborilor individuali sunt mediate, ceea ce reduce varianța în model.
AdaBoost
Acesta este un algoritm de stimulare care modifică adaptiv ponderea exemplelor clasificate greșit în setul de antrenament. Este adesea folosit pentru clasificarea binară.
Bayes naiv
Naïve Bayes se bazează pe teorema lui Bayes, care este o modalitate de a actualiza probabilitatea unui eveniment pe baza unor noi dovezi. Este un clasificator probabilistic folosit adesea pentru clasificarea textului și filtrarea spam-ului.
K-Cel mai apropiat vecin
K-Nearest Neighbours (KNN) este utilizat pentru sarcini de clasificare și regresie. Este o metodă neparametrică care clasifică un punct de date pe baza clasei vecinilor săi cei mai apropiați. KNN are mai multe avantaje, printre care simplitatea și faptul că este ușor de implementat. De asemenea, poate gestiona atât date numerice, cât și date categoriale și nu face ipoteze cu privire la distribuția datelor de bază.
Creșterea gradientului
Acestea sunt ansambluri de cursanți slabi care sunt instruiți secvențial, fiecare model încercând să corecteze greșelile modelului anterior. Ele pot fi utilizate atât pentru clasificare, cât și pentru regresie.
Regresia în învățarea automată
În învățarea automată, regresia este un tip de învățare supravegheată în care scopul este de a prezice variabile dependente de ac pe baza uneia sau mai multor caracteristici de intrare (numite și predictori sau variabile independente).
Algoritmii de regresie sunt utilizați pentru a modela relația dintre intrări și ieșiri și pentru a face predicții pe baza acelei relații. Regresia poate fi utilizată atât pentru variabile dependente continue, cât și pentru variabile categoriale.
În general, scopul regresiei este de a construi un model care poate prezice cu precizie rezultatul pe baza caracteristicilor de intrare și de a înțelege relația de bază dintre caracteristicile de intrare și ieșire.
Analiza regresiei este utilizată în diverse domenii, inclusiv economie, finanțe, marketing și psihologie, pentru a înțelege și a prezice relațiile dintre diferite variabile. Este un instrument fundamental în analiza datelor și învățarea automată și este folosit pentru a face predicții, a identifica tendințele și a înțelege mecanismele de bază care conduc datele.
De exemplu, într-un model de regresie liniară simplu, scopul ar putea fi acela de a prezice prețul unei case pe baza dimensiunii, locației și a altor caracteristici. Mărimea casei și locația acesteia ar fi variabilele independente, iar prețul casei ar fi variabila dependentă.
Modelul va fi instruit pe date de intrare care includ dimensiunea și locația mai multor case, împreună cu prețurile corespunzătoare. Odată antrenat modelul, acesta poate fi folosit pentru a face predicții despre prețul unei case, având în vedere dimensiunea și locația acesteia.
Tipuri de algoritmi de regresie ML
Algoritmii de regresie sunt disponibili în diferite forme, iar utilizarea fiecărui algoritm depinde de numărul de parametri, cum ar fi tipul de valoare a atributului, modelul liniei de tendință și numărul de variabile independente. Tehnicile de regresie care sunt adesea folosite includ:
Regresie liniara
Acest model liniar simplu este folosit pentru a prezice o valoare continuă pe baza unui set de caracteristici. Este folosit pentru a modela relația dintre caracteristici și variabila țintă prin potrivirea unei linii la date.
Regresia polinomială
Acesta este un model neliniar care este utilizat pentru a potrivi o curbă la date. Este folosit pentru a modela relațiile dintre caracteristici și variabila țintă atunci când relația nu este liniară. Se bazează pe ideea de a adăuga termeni de ordin superior la modelul liniar pentru a surprinde relații neliniare dintre variabilele dependente și independente.
Regresia crestei
Acesta este un model liniar care abordează supraadaptarea în regresia liniară. Este o versiune regularizată a regresiei liniare care adaugă un termen de penalizare la funcția de cost pentru a reduce complexitatea modelului.
Sprijină regresia vectorială
La fel ca SVM-urile, regresia vectorială de suport este un model liniar care încearcă să se potrivească cu datele prin găsirea hiperplanului care maximizează marja dintre variabilele dependente și independente.
Cu toate acestea, spre deosebire de SVM, care sunt utilizate pentru clasificare, SVR este utilizat pentru sarcini de regresie, unde scopul este de a prezice o valoare continuă, mai degrabă decât o etichetă de clasă.
Regresia Lasso
Acesta este un alt model liniar regularizat utilizat pentru a preveni supraadaptarea în regresia liniară. Se adaugă un termen de penalizare la funcția de cost pe baza valorii absolute a coeficienților.
Regresia liniară bayesiană
Regresia liniară bayesiană este o abordare probabilistică a regresiei liniare bazată pe teorema lui Bayes, care este o modalitate de a actualiza probabilitatea unui eveniment pe baza unor noi dovezi.
Acest model de regresie are ca scop estimarea distribuției posterioare a parametrilor modelului având în vedere datele. Acest lucru se face prin definirea unei distribuții anterioare peste parametri și apoi folosind teorema lui Bayes pentru a actualiza distribuția pe baza datelor observate.
Regresie vs. Clasificare
Regresia și clasificarea sunt două tipuri de învățare supravegheată, ceea ce înseamnă că sunt folosite pentru a prezice o ieșire pe baza unui set de caracteristici de intrare. Cu toate acestea, există câteva diferențe cheie între cele două:
RegressionClassificationDefinitionUn tip de învățare supravegheată care prezice o valoare continuă. Un tip de învățare supravegheată care prezice o valoare categoric. Arborele de decizie Regresie logistică, SVM, Naïve Bayes, KNN, Arborele de decizie Complexitatea modelului Modele mai puțin complexe Modele mai complexe IpotezeRelație liniară între caracteristici și țintăFără presupuneri specifice despre relația dintre caracteristici și țintăDezechilibru de clasăNu se aplicăPoate fi o problemă Valori aberePoate afecta performanța modeluluiNu este, de obicei, o problemă Caracteristică importanță Caracteristici importanță Caracteristici nu sunt clasificate în funcție de importanțăExemple de aplicațiiPredicția prețurilor, temperaturilor, cantitățilorPredicția dacă spam-ul prin e-mail, anticiparea abandonului clienților
Resurse de învățare
Ar putea fi o provocare să alegeți cele mai bune resurse online pentru înțelegerea conceptelor de învățare automată. Am examinat cursurile populare oferite de platforme de încredere pentru a vă prezenta recomandările noastre pentru cele mai bune cursuri ML despre regresie și clasificare.
#1. Bootcamp pentru clasificarea învățării automate în Python
Acesta este un curs oferit pe platforma Udemy. Acesta acoperă o varietate de algoritmi și tehnici de clasificare, inclusiv arbori de decizie și regresie logistică și acceptă mașini vectoriale.

Puteți, de asemenea, să aflați despre subiecte precum supraajustarea, compromisul de variație de părtinire și evaluarea modelului. Cursul folosește biblioteci Python, cum ar fi sci-kit-learn și panda, pentru a implementa și a evalua modele de învățare automată. Deci, sunt necesare cunoștințe de bază python pentru a începe cu acest curs.
#2. Masterclass de regresie în învățare automată în Python
În acest curs Udemy, Trainerul acoperă elementele de bază și teoria de bază a diverșilor algoritmi de regresie, inclusiv regresia liniară, regresia polinomială și tehnicile de regresie Lasso & Ridge.
Până la sfârșitul acestui curs, veți fi capabil să implementați algoritmi de regresie și să evaluați performanța modelelor de învățare automată antrenate folosind diverși indicatori cheie de performanță.
Încheierea
Algoritmii de învățare automată pot fi foarte utili în multe aplicații și pot ajuta la automatizarea și eficientizarea multor procese. Algoritmii ML folosesc tehnici statistice pentru a învăța modele în date și pentru a face predicții sau decizii pe baza acestor modele.
Aceștia pot fi instruiți pe cantități mari de date și pot fi utilizați pentru a îndeplini sarcini care ar fi dificile sau consumatoare de timp pentru ca oamenii să le facă manual.
Fiecare algoritm ML are punctele sale forte și punctele slabe, iar alegerea algoritmului depinde de natura datelor și de cerințele sarcinii. Este important să alegeți algoritmul adecvat sau combinația de algoritmi pentru problema specifică pe care încercați să o rezolvați.
Este important să alegeți tipul corect de algoritm pentru problema dvs., deoarece utilizarea unui tip greșit de algoritm poate duce la performanțe slabe și previziuni inexacte. Dacă nu sunteți sigur ce algoritm să utilizați, poate fi util să încercați atât algoritmii de regresie, cât și algoritmii de clasificare și să comparați performanța acestora pe setul dvs. de date.
Sper că ați găsit acest articol util în învățarea regresiei vs. clasificare în învățarea automată. De asemenea, ați putea fi interesat să aflați despre cele mai bune modele de învățare automată.