

În acest articol, vom discuta despre vectorizare – o tehnică NLP și vom înțelege semnificația acesteia cu un ghid cuprinzător despre diferite tipuri de vectorizare.
Am discutat despre conceptele fundamentale ale preprocesării NLP și curățării textului. Am analizat elementele de bază ale NLP, diversele sale aplicații și tehnici precum tokenizarea, normalizarea, standardizarea și curățarea textului.

Înainte de a discuta despre vectorizare, să revizuim ce este tokenizarea și cum diferă ea de vectorizare.
Cuprins
Ce este tokenizarea?
Tokenizarea este procesul de împărțire a propozițiilor în unități mai mici numite jetoane. Tokenul ajută computerele să înțeleagă și să lucreze cu ușurință cu text.
EX. „Acest articol este bun”
Jetoane- [‘This’, ‘article’, ‘is’, ‘good’.]
Ce este Vectorizarea?
După cum știm, modelele și algoritmii de învățare automată înțeleg datele numerice. Vectorizarea este un proces de conversie a datelor textuale sau categorice în vectori numerici. Prin conversia datelor în date numerice, vă puteți antrena modelul mai precis.
De ce avem nevoie de vectorizare?
❇️ Tokenizarea și vectorizarea au o importanță diferită în procesarea limbajului natural (NPL). Tokenizarea împarte propozițiile în jetoane mici. Vectorizarea îl convertește într-un format numeric, astfel încât modelul computer/ML să îl poată înțelege.
❇️ Vectorizarea nu este utilă doar pentru a o converti în formă numerică, ci și în captarea sensului semantic.
❇️ Vectorizarea poate reduce dimensionalitatea datelor și le poate face mai eficiente. Acest lucru ar putea fi foarte util în timp ce lucrați la un set de date mare.
❇️ Mulți algoritmi de învățare automată necesită intrare numerică, cum ar fi rețelele neuronale, astfel încât vectorizarea ne poate ajuta.
Există diferite tipuri de tehnici de vectorizare, pe care le vom înțelege prin intermediul acestui articol.
Pungă de cuvinte
Dacă aveți o grămadă de documente sau propoziții și doriți să le analizați, un Bag of Words simplifică acest proces tratând documentul ca pe o pungă care este plină de cuvinte.
Abordarea pachetului de cuvinte poate fi utilă în clasificarea textului, analiza sentimentelor și regăsirea documentelor.
Să presupunem că lucrați la o mulțime de text. O pungă de cuvinte vă va ajuta să reprezentați datele text prin crearea unui vocabular de cuvinte unice în datele noastre text. După crearea vocabularului, acesta va codifica fiecare cuvânt ca un vector pe baza frecvenței (cât de des apare fiecare cuvânt în acel text) a acestor cuvinte.
Acești vectori constau din numere nenegative (0,1,2…..) care reprezintă numărul de frecvențe din acel document.
Punga de cuvinte presupune trei pași:
Pasul 1: Tokenizare
Acesta va sparge documentele în jetoane.
Ex – (Propoziție: „Îmi place pizza și iubesc burgerii”)
Pasul 2: Separarea unică a cuvintelor/crearea vocabularului
Creați o listă cu toate cuvintele unice care apar în propozițiile dvs.
[“I”, “love”, “Pizza”, “and”, “Burgers”]
Pasul 3: Numărarea apariției cuvântului/crearea vectorului
Acest pas va număra de câte ori se repetă fiecare cuvânt din vocabular și îl va stoca într-o matrice rară. În matricea rară, fiecare rând dintr-un vector de propoziție a cărui lungime (coloanele matricei) este egală cu dimensiunea vocabularului.
Import CountVectorizer
Vom importa CountVectorizer pentru a ne antrena modelul Bag of words
from sklearn.feature_extraction.text import CountVectorizer
Creați un vectorizator
În acest pas, vom crea modelul nostru folosind CountVectorizer și îl vom antrena folosind documentul nostru text exemplu.
# Sample text documents
documents = [
"This is the first document.",
"This document is the second document.",
"And this is the third one.",
"Is this the first document?",
]
# Create a CountVectorizer
cv = CountVectorizer()
# Fit and Transform X = cv.fit_transform(documents)
Convertiți într-o matrice densă
În acest pas, vom converti reprezentările noastre în matrice densă. De asemenea, vom primi nume de caracteristici sau cuvinte.
# Get the feature names/words feature_names = vectorizer.get_feature_names_out() # Convert to dense array X_dense = X.toarray()
Să tipărim matricea termenilor Documentului și cuvintele caracteristice
# Print the DTM and feature names
print("Document-Term Matrix (DTM):")
print(X_dense)
print("\nFeature Names:")
print(feature_names)
Document – Matrice de termeni (DTM):
 Matrice
Matrice
Nume caracteristici:
 Cuvinte caracteristice
Cuvinte caracteristice
După cum puteți vedea, vectorii sunt formați din numere nenegative (0,1,2……) care reprezintă frecvența cuvintelor din document.
Avem patru exemple de documente text și am identificat nouă cuvinte unice din aceste documente. Am stocat aceste cuvinte unice în vocabularul nostru, atribuindu-le „Nume caracteristici”.
Apoi, modelul nostru Bag of Words verifică dacă primul cuvânt unic este prezent în primul nostru document. Dacă este prezent, atribuie o valoare de 1, în caz contrar, atribuie 0.
Dacă cuvântul apare de mai multe ori (de exemplu, de 2 ori), acesta atribuie o valoare corespunzător.
De exemplu, în al doilea document, cuvântul „document” se repetă de două ori, astfel încât valoarea sa în matrice va fi 2.
Dacă vrem un singur cuvânt ca caracteristică în cheia de vocabular – reprezentare Unigram.
n – grame = Unigrame, bigrame…….etc.
Există multe biblioteci precum scikit-learn pentru a implementa pachetul de cuvinte: Keras, Gensim și altele. Acest lucru este simplu și poate fi util în diferite cazuri.
Dar, Bag of words este mai rapid, dar are unele limitări.
Pentru a rezolva această problemă putem alege abordări mai bune, una dintre ele este TF-IDF. Să înțelegem în detaliu.
TF-IDF
TF-IDF, sau Term Frequency – Inverse Document Frequency, este o reprezentare numerică pentru a determina importanța cuvintelor din document.
De ce avem nevoie de TF-IDF peste Bag of Words?
O pungă de cuvinte tratează toate cuvintele în mod egal și se preocupă doar de frecvența cuvintelor unice în propoziții. TF-IDF acordă importanță cuvintelor dintr-un document luând în considerare atât frecvența, cât și unicitatea.
Cuvintele care se repetă prea des nu învinge cuvintele mai puțin frecvente și mai importante.
TF: Frecvența termenului măsoară cât de important este un cuvânt într-o singură propoziție.
IDF: Frecvența inversă a documentelor măsoară cât de important este un cuvânt în întreaga colecție de documente.
TF = Frecvența cuvintelor dintr-un document / Numărul total de cuvinte din acel document
DF = Document care conține cuvântul cu / Numărul total de documente
IDF = jurnal (numărul total de documente / documente care conțin cuvântul w)
IDF este reciprocă cu DF. Motivul din spatele acestui lucru este cu cât cuvântul este mai comun în toate documentele, cu atât importanța sa în documentul curent este mai mică.
Scor final TF-IDF: TF-IDF = TF * IDF
Este o modalitate de a afla ce cuvinte sunt comune într-un singur document și unice în toate documentele. Aceste cuvinte pot fi utile în găsirea temei principale a documentului.
De exemplu,
Doc1 = „Îmi place învățarea automată”
Doc2 = „Îmi place tipstrick.ro”
Trebuie să găsim matricea TF-IDF pentru documentele noastre.
În primul rând, vom crea un vocabular de cuvinte unice.
Vocabular = [“I,” “love,” “machine,” “learning,” “Geekflare”]
Deci, avem 5 cinci cuvinte. Să găsim TF și IDF pentru aceste cuvinte.
TF = Frecvența cuvintelor dintr-un document / Numărul total de cuvinte din acel document
TF:
- Pentru „I” = TF pentru Doc1: 1/4 = 0,25 și pentru Doc2: 1/3 ≈ 0,33
- Pentru „dragoste”: TF pentru Doc1: 1/4 = 0,25 și pentru Doc2: 1/3 ≈ 0,33
- Pentru „Mașină”: TF pentru Doc1: 1/4 = 0,25 și pentru Doc2: 0/3 ≈ 0
- Pentru „Învățare”: TF pentru Doc1: 1/4 = 0,25 și pentru Doc2: 0/3 ≈ 0
- Pentru „tipstrick.ro”: TF pentru Doc1: 0/4 = 0 și pentru Doc2: 1/3 ≈ 0,33
Acum, să calculăm IDF.
IDF = jurnal (numărul total de documente / documente care conțin cuvântul w)
IDF:
- Pentru „I”: IDF este log(2/2) = 0
- Pentru „dragoste”: IDF este log(2/2) = 0
- Pentru „Mașină”: IDF este log(2/1) = log(2) ≈ 0,69
- Pentru „Învățare”: IDF este log(2/1) = log(2) ≈ 0,69
- Pentru „tipstrick.ro”: IDF este log(2/1) = log(2) ≈ 0,69
Acum, să calculăm scorul final al TF-IDF:
- Pentru „I”: TF-IDF pentru Doc1: 0,25 * 0 = 0 și TF-IDF pentru Doc2: 0,33 * 0 = 0
- Pentru „dragoste”: TF-IDF pentru Doc1: 0,25 * 0 = 0 și TF-IDF pentru Doc2: 0,33 * 0 = 0
- Pentru „Mașină”: TF-IDF pentru Doc1: 0,25 * 0,69 ≈ 0,17 și TF-IDF pentru Doc2: 0 * 0,69 = 0
- Pentru „Învățare”: TF-IDF pentru Doc1: 0,25 * 0,69 ≈ 0,17 și TF-IDF pentru Doc2: 0 * 0,69 = 0
- Pentru „tipstrick.ro”: TF-IDF pentru Doc1: 0 * 0,69 = 0 și TF-IDF pentru Doc2: 0,33 * 0,69 ≈ 0,23
Matricea TF-IDF arată astfel:
I love machine learning tipstrick.ro Doc1 0.0 0.0 0.17 0.17 0.0 Doc2 0.0 0.0 0.0 0.0 0.23
Valorile dintr-o matrice TF-IDF vă spun cât de important este fiecare termen în cadrul fiecărui document. Valorile ridicate indică faptul că un termen este important într-un anumit document, în timp ce valorile scăzute sugerează că termenul este mai puțin important sau comun în acel context.
TF-IDF este folosit mai ales în clasificarea textului, construirea de informații despre chatbot și rezumarea textului.
Importați TfidfVectorizer
Să importăm TfidfVectorizer din sklearn
from sklearn.feature_extraction.text import TfidfVectorizer
Creați un vectorizator
După cum vrei să vezi, vom crea modelul nostru Tf Idf folosind TfidfVectorizer.
# Sample text documents
text = [
"This is the first document.",
"This document is the second document.",
"And this is the third one.",
"Is this the first document?",
]
# Create a TfidfVectorizer
cv = TfidfVectorizer()
Creați matrice TF-IDF
Să ne antrenăm modelul furnizând text. După aceea, vom converti matricea reprezentativă într-o matrice densă.
# Fit and transform to create the TF-IDF matrix X = cv.fit_transform(text)
# Get the feature names/words feature_names = vectorizer.get_feature_names_out() # Convert the TF-IDF matrix to a dense array for easier manipulation (optional) X_dense = X.toarray()
Tipăriți matricea TF-IDF și cuvintele caracteristice
# Print the TF-IDF matrix and feature words
print("TF-IDF Matrix:")
print(X_dense)
print("\nFeature Names:")
print(feature_names)
Matricea TF-IDF:
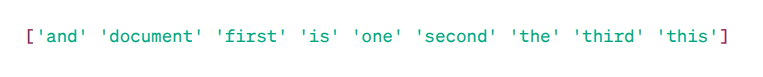 Cuvinte caracteristice
Cuvinte caracteristice
După cum puteți vedea, aceste numere întregi zecimale indică importanța cuvintelor în anumite documente.
De asemenea, puteți combina cuvinte în grupuri de 2,3,4 și așa mai departe folosind n-grame.
Există și alți parametri pe care îi putem include: min_df, max_feature, subliner_tf etc.
Până acum, am explorat tehnici de bază bazate pe frecvență.
Dar, TF-IDF nu poate oferi sens semantic și înțelegere contextuală a textului.
Să înțelegem tehnici mai avansate care au schimbat lumea înglobării cuvintelor și care sunt mai bune pentru semnificația semantică și înțelegerea contextuală.
Word2Vec
Word2vec este popular încorporarea cuvintelor (tip de vector de cuvânt și util pentru a surprinde similaritatea semantică și sintactică) tehnică în NLP. Acesta a fost dezvoltat de Tomas Mikolov și echipa sa de la Google în 2013. Word2vec reprezintă cuvintele ca vectori continui într-un spațiu multidimensional.
Word2vec își propune să reprezinte cuvintele într-un mod care să surprindă semnificația lor semantică. Vectorii de cuvinte generați de word2vec sunt poziționați într-un spațiu vectorial continuu.
Ex – Vectorii „Pisică” și „Câine” ar fi mai apropiați decât vectorii „pisica” și „fată”.
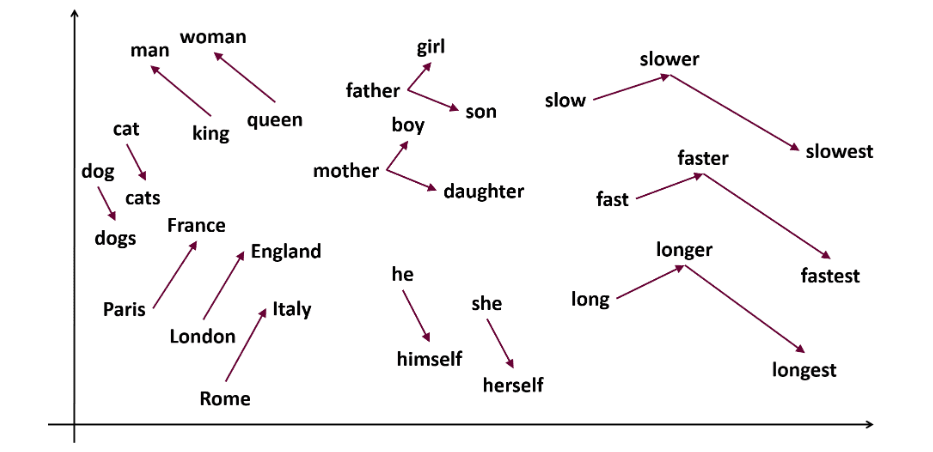 Sursă: usna.edu
Sursă: usna.edu
Două arhitecturi model pot fi folosite de word2vec pentru a crea încorporarea cuvintelor.
CBOW: sac continuu de cuvinte sau CBOW încearcă să prezică un cuvânt făcând o medie a semnificației cuvintelor din apropiere. Este nevoie de un număr fix sau de o fereastră de cuvinte în jurul cuvântului țintă, apoi îl convertește în formă numerică (Incorporare), apoi face media tuturor și folosește acea medie pentru a prezice cuvântul țintă cu rețeaua neuronală.
Ținta ex-Predict: „Vulpe”
Cuvinte de propoziție: „The”, „quick”, „maro”, „sări”, „peste”, „the”
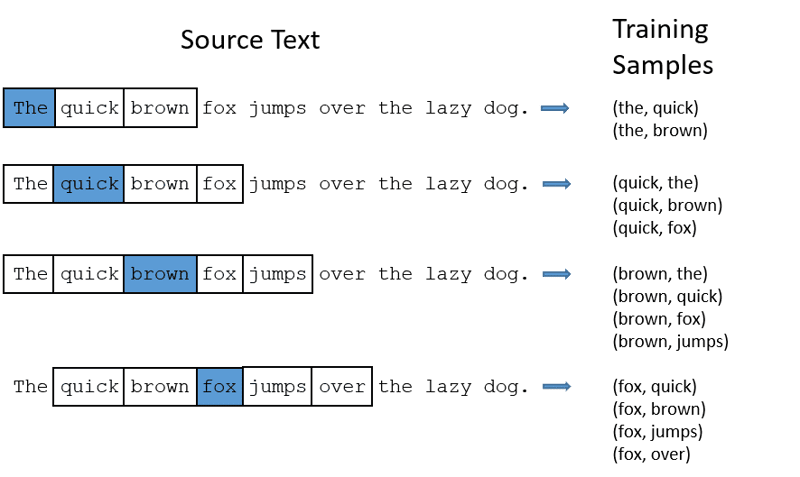 Word2Vec
Word2Vec
- CBOW preia o fereastră de dimensiune fixă (număr) de cuvinte precum 2 (2 la stânga și 2 la dreapta)
- Convertiți în încorporare de cuvinte.
- CBOW face o medie a cuvântului încorporare.
- CBOW face o medie a cuvântului încorporat în cuvintele contextului.
- Vectorul mediu încearcă să prezică un cuvânt țintă folosind o rețea neuronală.
Acum, să înțelegem cât de diferit este skip-gram de CBOW.
Skip-gram: Este un model de încorporare a cuvintelor, dar funcționează diferit. În loc să prezică cuvântul țintă, skip-gram prezice cuvintele de context date cuvinte țintă.
Skip-grams este mai bine la captarea relațiilor semantice dintre cuvinte.
Fostul „Rege – bărbați + femei = regină”
Dacă doriți să lucrați cu Word2Vec, aveți două opțiuni: fie vă puteți antrena propriul model, fie folosiți un model pre-antrenat. Vom trece printr-un model pre-antrenat.
Import gensim
Puteți instala gensim folosind pip install:
pip install gensim
Tokenizați propoziția folosind word_tokenize:
În primul rând, vom converti propozițiile în mai mici. După aceea, ne vom tokeniza propozițiile folosind word_tokenize.
# Import necessary libraries
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
# Sample sentences
sentences = [
"I love thor",
"Hulk is an important member of Avengers",
"Ironman helps Spiderman",
"Spiderman is one of the popular members of Avengers",
]
# Tokenize the sentences
tokenized_sentences = [word_tokenize(sentence.lower()) for sentence in sentences]
Să ne antrenăm modelul:
Ne vom antrena modelul furnizând propoziții tokenizate. Folosim 5 ferestre pentru acest model de antrenament, vă puteți adapta conform cerințelor dvs.
# Train a Word2Vec model
model = Word2Vec(sentences=tokenized_sentences, vector_size=100, window=5, min_count=1, sg=0)
# Find similar words
similar_words = model.wv.most_similar("avengers")
# Print similar words
print("Similar words to 'avengers':")
for word, score in similar_words:
print(f"{word}: {score}")
Cuvinte similare cu „răzbunătorii”:
 Asemănarea Word2Vec
Asemănarea Word2Vec
Acestea sunt câteva dintre cuvintele care sunt similare cu „răzbunătorii” bazate pe modelul Word2Vec, împreună cu scorurile lor de similaritate.
Modelul calculează un scor de similaritate (în mare parte asemănarea cosinusului) între vectorii de cuvinte ai „răzbunătorilor” și alte cuvinte din vocabularul său. Scorul de similaritate indică cât de strâns legate sunt două cuvinte în spațiul vectorial.
Ex –
Aici, cuvântul „ajută” cu asemănarea cosinusului -0,005911458611011982 cu cuvântul „răzbunători”. Valoarea negativă sugerează că ar putea fi diferite între ele.
Valorile asemănării cosinusului variază de la -1 la 1, unde:
- 1 indică faptul că cei doi vectori sunt identici și au similitudini pozitive.
- Valorile apropiate de 1 indică o asemănare pozitivă ridicată.
- Valorile apropiate de 0 indică faptul că vectorii nu sunt puternic legați.
- Valorile apropiate de -1 indică o mare diferență.
- -1 indică faptul că cei doi vectori sunt total opuși și au o asemănare negativă perfectă.
Vizitează asta legătură dacă doriți o mai bună înțelegere a modelelor word2vec și o reprezentare vizuală a modului în care funcționează. Este un instrument foarte grozav pentru a vedea CBOW și skip-gram în acțiune.
Similar cu Word2Vec, avem GloVe. GloVe poate produce încorporare care necesită mai puțină memorie în comparație cu Word2Vec. Să înțelegem mai multe despre GloVe.
Mănușă
Vectorii globali pentru reprezentarea cuvintelor (GloVe) este o tehnică ca word2vec. Este folosit pentru a reprezenta cuvinte ca vectori în spațiu continuu. Conceptul din spatele GloVe este același cu cel al Word2Vec: produce încorporare de cuvinte contextuale, luând în considerare performanța superioară a Word2Vec.
De ce avem nevoie de GloVe?
Word2vec este o metodă bazată pe ferestre și folosește cuvinte din apropiere pentru a înțelege cuvintele. Aceasta înseamnă că sensul semantic al cuvântului țintă este afectat doar de cuvintele din jur în propoziții, ceea ce este o utilizare ineficientă a statisticilor.
În timp ce GloVe captează atât statistici globale, cât și locale, care urmează să vină cu încorporarea cuvintelor.
Când să folosiți GloVe?
Folosiți GloVe atunci când doriți încorporare de cuvinte care să surprindă relații semantice mai largi și asocieri globale de cuvinte.
GloVe este mai bun decât alte modele cu privire la sarcinile de recunoaștere a entităților cu nume, analogia cuvintelor și similitudinea cuvintelor.
În primul rând, trebuie să instalăm Gensim:
pip install gensim
Pasul 1: Vom instala biblioteci importante
# Import the required libraries import numpy as np import matplotlib.pyplot as plt from sklearn.manifold import TSNE import gensim.downloader as api
Pasul 2: importați modelul Glove
import gensim.downloader as api
glove_model = api.load('glove-wiki-gigaword-300')
Pasul 3: Preluați reprezentarea cuvântului vectorial pentru cuvântul „drăguț”
glove_model["cute"]
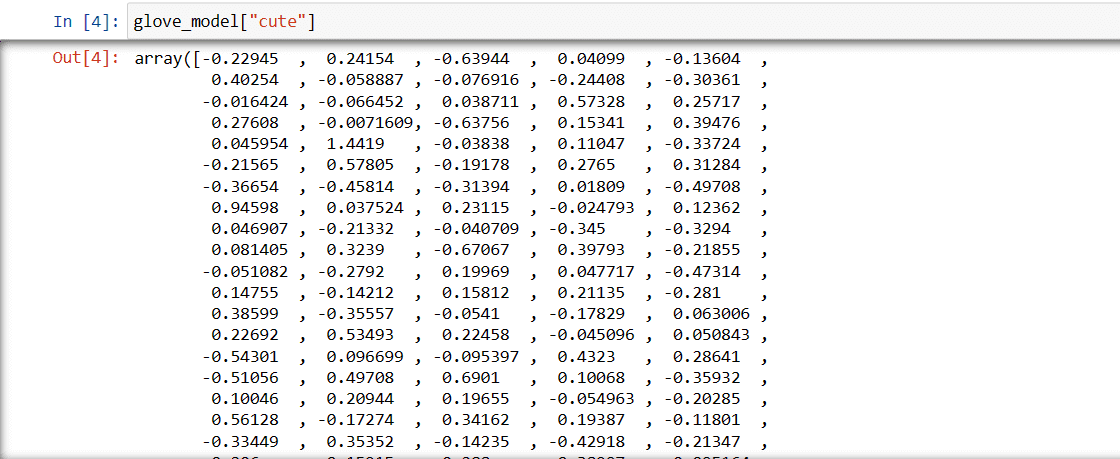 Vector pentru cuvântul „drăguț”
Vector pentru cuvântul „drăguț”
Aceste valori captează sensul cuvântului și relațiile cu alte cuvinte. Valorile pozitive indică asocieri pozitive cu anumite concepte, în timp ce valorile negative indică asocieri negative cu alte concepte.
Într-un model GloVe, fiecare dimensiune din vectorul cuvântului reprezintă un anumit aspect al sensului sau contextului cuvântului.
Valorile negative și pozitive din aceste dimensiuni contribuie la cât de „drăguț” este legat semantic de alte cuvinte din vocabularul modelului.
Valorile pot fi diferite pentru diferite modele. Să găsim câteva cuvinte similare cu cuvântul „băiat”
Top 10 cuvinte similare despre care modelul crede că sunt cele mai asemănătoare cu cuvântul „băiat”
# find similar word
glove_model.most_similar("boy")
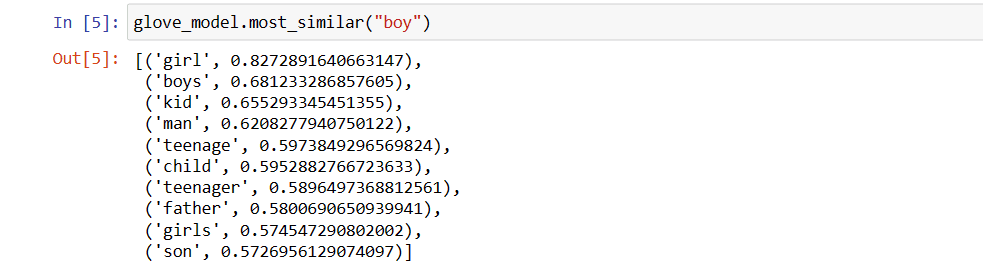 Top 10 cuvinte similare cu „băiat”
Top 10 cuvinte similare cu „băiat”
După cum puteți vedea, cel mai asemănător cuvânt cu „băiat” este „fată”.
Acum, vom încerca să găsim cât de exact va obține modelul sens semantic din cuvintele furnizate.
glove_model.most_similar(positive=['boy', 'queen'], negative=['girl'], topn=1)
 Cel mai relevant cuvânt pentru „regina”
Cel mai relevant cuvânt pentru „regina”
Modelul nostru este capabil să găsească relația perfectă între cuvinte.
Definiți lista de vocabular:
Acum, să încercăm să înțelegem sensul semantic sau relația dintre cuvinte folosind un complot. Definiți lista de cuvinte pe care doriți să o vizualizați.
# Define the list of words you want to visualize vocab = ["boy", "girl", "man", "woman", "king", "queen", "banana", "apple", "mango", "cow", "coconut", "orange", "cat", "dog"]
Creați matrice de încorporare:
Să scriem cod pentru crearea matricei de încorporare.
# Your code for creating the embedding matrix
EMBEDDING_DIM = glove_model.vectors.shape[1]
word_index = {word: index for index, word in enumerate(vocab)}
num_words = len(vocab)
embedding_matrix = np.zeros((num_words, EMBEDDING_DIM))
for word, i in word_index.items():
embedding_vector = glove_model[word]
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
Definiți o funcție pentru vizualizarea t-SNE:
Din acest cod, vom defini funcția pentru graficul nostru de vizualizare.
def tsne_plot(embedding_matrix, words):
tsne_model = TSNE(perplexity=3, n_components=2, init="pca", random_state=42)
coordinates = tsne_model.fit_transform(embedding_matrix)
x, y = coordinates[:, 0], coordinates[:, 1]
plt.figure(figsize=(14, 8))
for i, word in enumerate(words):
plt.scatter(x[i], y[i])
plt.annotate(word,
xy=(x[i], y[i]),
xytext=(2, 2),
textcoords="offset points",
ha="right",
va="bottom")
plt.show()
Să vedem cum arată complotul nostru:
# Call the tsne_plot function with your embedding matrix and list of words tsne_plot(embedding_matrix, vocab)
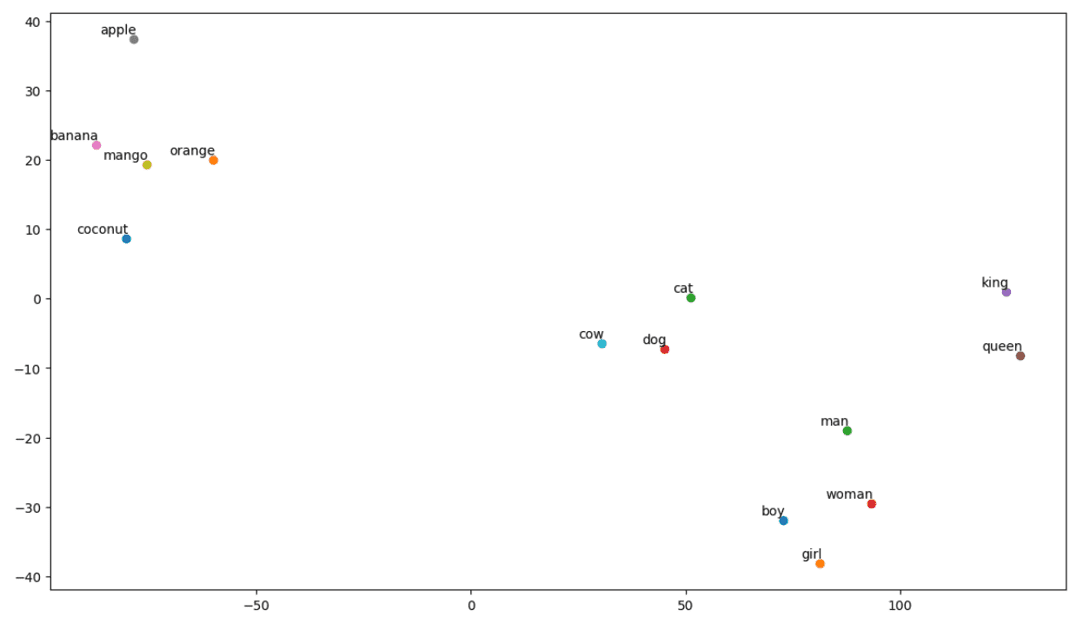 t-SNE complot
t-SNE complot
Deci, după cum putem vedea, există cuvinte precum „banana”, „mango”, „orange”, „nucă de cocos” și „măr” în partea stângă a parcelei noastre. În timp ce „vaca”, „câinele” și „pisica” sunt similare între ele, deoarece sunt animale.
Deci, modelul nostru poate găsi semnificația semantică și relațiile dintre cuvinte, de asemenea!
Schimbând vocabul sau creându-ți modelul de la zero, poți experimenta cu diferite cuvinte.
Puteți utiliza această matrice de încorporare așa cum doriți. Poate fi aplicat numai sarcinilor de similaritate a cuvintelor sau alimentat în stratul de încorporare al unei rețele neuronale.
GloVe se antrenează pe o matrice de co-ocurență pentru a obține semnificația semantică. Se bazează pe ideea că co-aparițiile cuvânt-cuvânt sunt o cunoaștere esențială și că utilizarea lor este o modalitate eficientă de a folosi statisticile pentru a produce înglobări de cuvinte. Acesta este modul în care GloVe realizează adăugarea de „statistici globale” la produsul final.
Și asta este GloVe; O altă metodă populară de vectorizare este FastText. Să discutăm mai multe despre asta.
FastText
FastText este o bibliotecă open-source introdusă de echipa Facebook AI Research pentru clasificarea textului și analiza sentimentelor. FastText oferă instrumente pentru formarea încorporarii cuvintelor, care reprezintă cuvinte dense vectoriale. Acest lucru este util pentru a surprinde semnificația semantică a documentului. FastText acceptă atât clasificarea cu mai multe etichete, cât și cu mai multe clase.
De ce FastText?
FastText este mai bun decât alte modele datorită capacității sale de a generaliza la cuvinte necunoscute, care lipseau în alte metode. FastText oferă vectori de cuvinte pre-antrenați pentru diferite limbi, care ar putea fi folositori în diferite sarcini în care avem nevoie de cunoștințe anterioare despre cuvinte și semnificația lor.
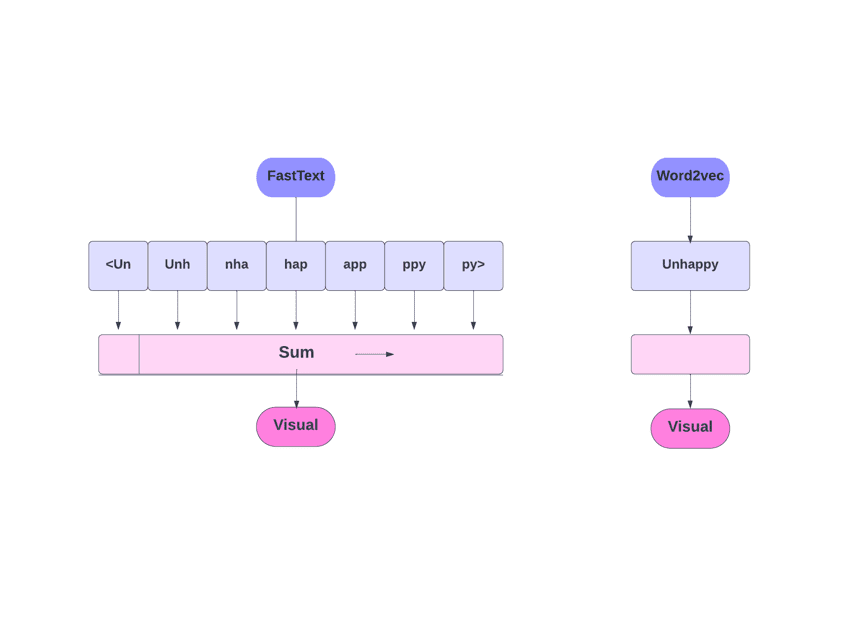 FastText vs Word2Vec
FastText vs Word2Vec
Cum functioneazã?
După cum am discutat, alte modele, cum ar fi Word2Vec și GloVe, folosesc cuvinte pentru încorporarea cuvintelor. Dar, blocul de bază al FastText este literele în loc de cuvinte. Ceea ce înseamnă că folosesc litere pentru încorporarea cuvintelor.
Folosirea caracterelor în loc de cuvinte are un alt avantaj. Sunt necesare mai puține date pentru antrenament. Pe măsură ce un cuvânt devine contextul său, din text pot fi extrase mai multe informații.
Word Embedding obținut prin FastText este o combinație de înglobări de nivel inferior.
Acum, să ne uităm la modul în care FastText utilizează informațiile sub-cuvinte.
Să presupunem că avem cuvântul „citire”. Pentru acest cuvânt, caracterul n-grame cu lungimea 3-6 ar fi generat după cum urmează:
- Începutul și sfârșitul sunt indicate prin paranteze unghiulare.
- Hashing este folosit deoarece ar putea exista un număr mare de n-grame; în loc să învățăm o încorporare pentru fiecare n-gramă distinctă, învățăm înglobările totale B, unde B reprezintă dimensiunea găleții. Dimensiunea de 2 milioane de găleți a fost folosită în hârtia originală.
- Fiecare caracter n-gram, cum ar fi „eadi”, este mapat la un număr întreg între 1 și B folosind această funcție de hashing, iar acel index are încorporarea corespunzătoare.
- Prin medierea acestor înglobări de n-grame constitutive, se obține apoi încorporarea completă a cuvântului.
- Chiar dacă această abordare hashing are ca rezultat coliziuni, ajută la gestionarea dimensiunii vocabularului într-o mare măsură.
- Rețeaua folosită în FastText este similară cu Word2Vec. La fel ca acolo, putem antrena FastText în două moduri – CBOW și skip-gram. Prin urmare, nu trebuie să repetăm acea parte aici.
Îți poți antrena propriul model sau poți folosi un model pre-antrenat. Vom folosi un model pre-antrenat.
Mai întâi, trebuie să instalați FastText.
pip install fasttext
Vom folosi un set de date care constă din text conversațional cu privire la câteva medicamente și trebuie să clasificăm acele texte în 3 tipuri. Ca și cu tipul de medicamente cu care sunt asociate.
 Setul de date
Setul de date
Acum, pentru a antrena un model FastText pe orice set de date, trebuie să pregătim datele de intrare într-un anumit format, care este:
__label__
Să facem asta și pentru setul nostru de date.
all_texts = train['text'].tolist()
all_labels = train['drug type'].tolist()
prep_datapoints=[]
for i in range(len(all_texts)):
sample="__label__"+ str(all_labels[i]) + ' '+ all_texts[i]
prep_datapoints.append(sample)
 prep_datapoints
prep_datapoints
Am omis o mulțime de preprocesare în acest pas. În caz contrar, articolul nostru va fi prea mare. În problemele din lumea reală, cel mai bine este să faceți preprocesare pentru a face datele potrivite pentru modelare.
Acum, scrieți punctele de date pregătite într-un fișier .txt.
with open('train_fasttext.txt','w') as f:
for datapoint in prep_datapoints:
f.write(datapoint)
f.write('n')
f.close()
Să ne antrenăm modelul.
model = fasttext.train_supervised('train_fasttext.txt')
Vom obține predicții din modelul nostru.

Modelul prezice eticheta și îi atribuie un scor de încredere.
Ca și în cazul oricărui alt model, performanța acestuia depinde de o varietate de variabile, dar dacă doriți să vă faceți o idee rapidă despre exactitatea așteptată, FastText ar putea fi o opțiune excelentă.
Concluzie
În concluzie, metodele de vectorizare a textului precum Bag of Words (BoW), TF-IDF, Word2Vec, GloVe și FastText oferă o varietate de capabilități pentru sarcini NLP.
În timp ce Word2Vec captează semantica cuvintelor și este adaptabil pentru o varietate de sarcini NLP, BoW și TF-IDF sunt simple și potrivite pentru clasificarea și recomandarea textului.
Pentru aplicații precum analiza sentimentelor, GloVe oferă înglobări pre-antrenate, iar FastText se descurcă bine la analiza la nivel de subcuvânt, făcându-l util pentru limbajele bogate din punct de vedere structural și recunoașterea entităților.
Alegerea tehnicii depinde de sarcină, date și resurse. Vom discuta mai profund complexitățile NLP pe măsură ce această serie progresează. Învățare fericită!
Apoi, consultați cele mai bune cursuri NLP pentru a învăța Procesarea limbajului natural.