
Prometheus este un sistem de monitorizare open-source, bazat pe metrici. Acesta colectează date de la servicii și gazde prin trimiterea de solicitări HTTP pe punctele finale de metrice. Apoi stochează rezultatele într-o bază de date cu serii de timp și o pune la dispoziție pentru analiză și alertă.
Cuprins
De ce monitorizați?
- Activează alerte atunci când lucrurile merg prost, de preferință înainte de a merge prost. Pentru ca cineva să se uite la el.
- Oferă informații pentru a permite analiza, depanarea și rezolvarea problemei.
- Vă permite să vedeți tendințe/schimbări în timp. De exemplu, câte sesiuni active la un moment dat. Acest lucru ajută la deciziile de proiectare și la planificarea capacității.
Monitorizarea se referă de obicei la evenimente. Un eveniment poate include primirea unei solicitări HTTP, trimiterea unui răspuns, citirea de pe disc, autentificarea utilizatorului. Monitorizarea unui sistem ar putea include profilarea, înregistrarea în jurnal, urmărirea, valorile, alertele și vizualizarea.
Monitorizare Blackbox vs. Whitebox
Monitorizarea se încadrează în două categorii principale:
Monitorizare cutie neagră
În monitorizarea Blackbox, monitorizarea este la nivel de aplicație sau gazdă, așa cum sunt observate din exterior. Acest lucru poate fi destul de limitator.
Monitorizare Whitebox
Monitorizarea Whitebox înseamnă monitorizarea elementelor interne ale unui serviciu. Ar expune date despre starea și performanța componentelor interne.
Cele patru semnale de aur
Potrivit Googledacă puteți măsura doar patru valori ale sistemului dvs. orientat către utilizator, concentrați-vă pe următoarele patru, numite Patru semnale de aur:
#1. Latența
Timpul necesar pentru a servi o solicitare – cu succes sau eșuat. Este important să urmăriți nu doar cererile reușite, ci și pe cele eșuate.
#2. Trafic
O măsură a cererii impuse sistemului dvs. Pentru un serviciu web, acestea sunt de obicei solicitări HTTP pe secundă.
#3. Erori
Rata cererilor care eșuează.
#4. Saturare
Cât de plin este serviciul dvs. Creșterea latenței este adesea un indicator important al saturației. Multe sisteme se degradează în performanță mult înainte de a atinge utilizarea 100%.
Tipuri de metrici Prometheus
Valorile Prometheus sunt de patru tipuri principale:
#1. Tejghea
Valoarea unui contor va crește întotdeauna. Nu poate scădea niciodată, dar poate fi resetat la zero. Deci, dacă o răzuire eșuează, înseamnă doar un punct de date ratat. Creșterea cumulată va fi disponibilă la următoarea lectură. Exemple:
- Numărul total de solicitări HTTP primite
- Numărul de excepții.
#2. Ecartament
Un indicator este un instantaneu în orice moment dat. Poate să crească sau să scadă. Dacă preluarea datelor eșuează, pierdeți o probă; următoarea preluare ar putea afișa o valoare diferită: exemple de spațiu pe disc, utilizarea memoriei.
#3. Histogramă
O histogramă eșantionează observațiile și le numără în compartimente configurabile. Sunt folosite pentru lucruri precum durata cererii sau dimensiunile răspunsurilor. De exemplu, puteți măsura durata solicitării pentru o anumită solicitare HTTP. Histograma va avea un set de găleți, să zicem 1 ms, 10 ms și 25 ms. În loc să stocheze fiecare durată pentru fiecare cerere, Prometheus va stoca frecvența solicitărilor care se încadrează într-o anumită găleată.
#4. rezumat
Similar cu observațiile eșantioanelor de histogramă, de obicei solicită durate sau dimensiuni de răspuns. Acesta va oferi un număr total de observații și o sumă a tuturor valorilor observate, permițându-vă să calculați media valorilor observate. De exemplu, într-un minut, ai avut trei solicitări care au durat 2,3,4 secunde. Suma ar fi 9, iar numărul ar fi 3. Latența ar fi de 3 secunde.
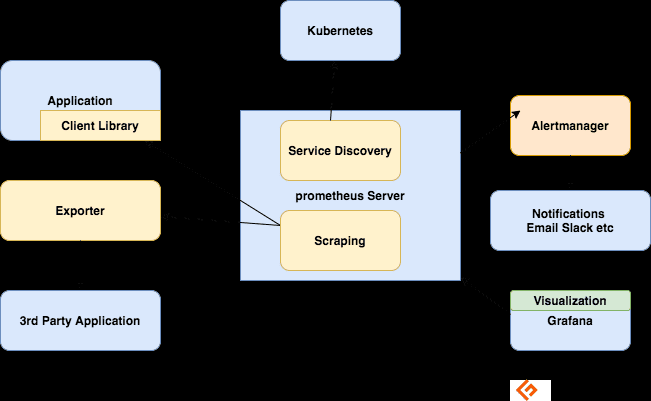
Componentele ecosistemului Prometheus
Serverul Prometheus
Colectează valori, le stochează și le pune la dispoziție pentru interogare, trimite alerte pe baza valorilor colectate.
Răzuire
Prometeu este un sistem bazat pe tragere. Pentru a prelua valori, Prometheus trimite o solicitare HTTP numită scrape. Trimite scrape către ținte pe baza configurației sale.
Fiecare țintă (definită static sau descoperită dinamic) este răzuită la un interval regulat (interval de răzuire). Fiecare scrape citește punctul final HTTP /metrics pentru a obține starea curentă a valorilor clientului și păstrează valorile în baza de date a seriei temporale Prometheus.
Există mai multe baze de date cu serii de timp pentru soluții de monitorizare pe care poate doriți să le explorați.
Biblioteci client
Pentru a monitoriza un serviciu, trebuie să adăugați instrumente la cod. Există biblioteci client disponibile pentru toate limbile și timpii de execuție populare. Folosind aceste biblioteci, odată ce adăugați câteva linii de cod, codul dvs. poate începe să emită valori. Aceasta se numește instrumentare directă. Aceste biblioteci vă permit să definiți valori interne și, de asemenea, să le expuneți printr-un punct final HTTP. Când Prometheus analizează punctul final HTTP pentru metrici, biblioteca client trimite valorile către server.
Bibliotecile client oficiale sunt oferite de Prometheus pentru Go, Java, Python și Ruby. Prometeu are un ecosistem deschis. Există, de asemenea, biblioteci client construite în comunitate disponibile pentru C, PHP, Node.js, C#/.NET și multe altele.
Exportatori
Multe aplicații expun valori în format non-Prometheus. Pentru acestea și pentru aplicațiile pe care nu le dețineți sau pentru care nu aveți acces la cod, nu puteți adăuga direct instrumentație. De exemplu, serverul MySQL, Kafka, JMX, HAProxy și NGINX. În aceste scenarii, utilizați exportatori.
Un exportator este un instrument pe care îl implementați împreună cu aplicația de la care doriți valori. Un exportator acționează ca un proxy între aplicație și Prometheus. Acesta va primi solicitări de la serverul Prometheus, va colecta date din jurnalele de acces, jurnalele de erori ale aplicației, o va transforma în formatul corect și, în final, va reveni la serverul Prometheus.
Unii dintre exportatorii populari sunt:
- Windows – pentru valorile serverului Windows
- Nodul – pentru valorile serverului Linux
- Cutie neagră – pentru valorile de performanță DNS și site-uri web
- JMX – pentru valorile aplicațiilor bazate pe Java
Odată ce aplicațiile au fost instrumentate sau exportatorii sunt la locul lor, trebuie să îi spuneți lui Prometheus unde se află. Acest lucru se poate face folosind configurația statică. În cazul mediilor dinamice, acest lucru nu se poate face; prin urmare, se utilizează descoperirea serviciului.
Alertarea
Alertarea cu Prometheus constă din două părți –
Regulile de alertă trimit alerte către Alertmanager.
Apoi Alertmanager gestionează acele alerte. Trimite notificări utilizând multe integrări de tip e-mail, Slack, Hipchat și PagerDuty. Alertmanager poate efectua, de asemenea, tăcere sau agregare pentru a reduce numărul de notificări.
Iată ghidul pentru monitorizarea serverului Linux folosind Prometheus și Dashboard.
Vizualizarea cu tablouri de bord
Prometheus are o serie de API-uri prin care interogările PromQL pot produce date brute pentru vizualizări.
Deși Prometheus include un browser de expresii care poate fi utilizat pentru interogări ad-hoc, cel mai bun instrument disponibil este Grafana. Grafana se integrează pe deplin cu Prometheus și poate produce o mare varietate de tablouri de bord.
Va trebui să configurați Prometheus ca sursă de date pentru Grafana.
Puteți adăuga tablouri de bord prin:
- Import de tablouri de bord construite de comunitate
- Construiește-ți propriul tău
- Folosind un tablou de bord predefinit.
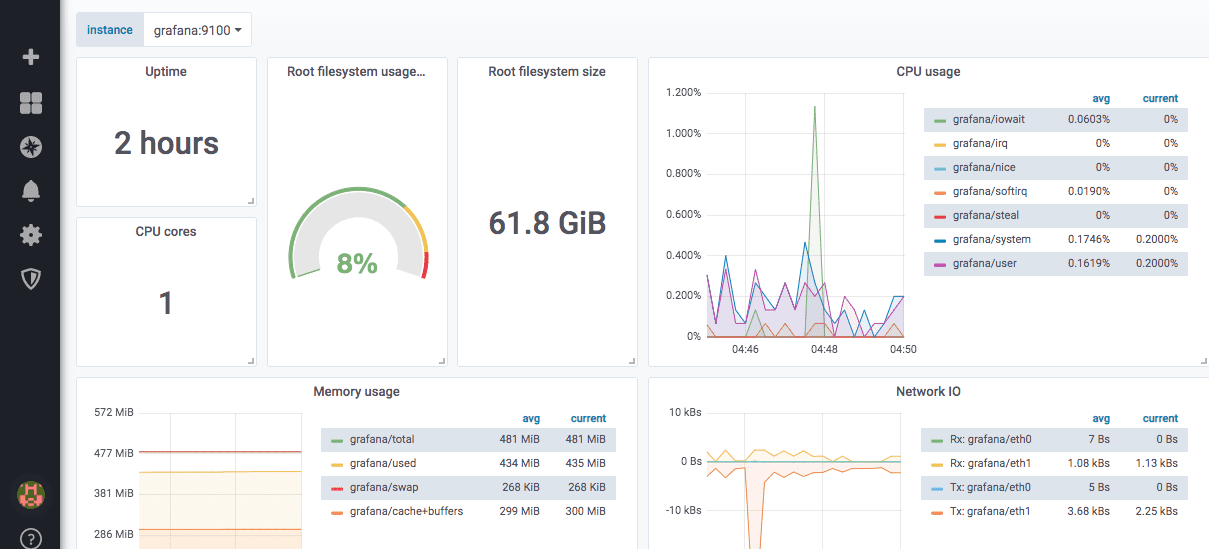
Iată cum arată un tablou de bord pentru exportator de noduri predefinite:
Grafana are un modul worldPing care vă permite să monitorizați valorile de performanță ale site-ului și DNS la nivel mondial.
rezumat
Prometheus are foarte puține cerințe. Poate fi destul de simplu de rulat, deoarece este un singur binar cu un fișier de configurare. Poate gestiona mii de ținte și poate ingera milioane de mostre pe secundă. Prometheus este conceput pentru a urmări sistemul general, starea de sănătate, comportamentul sistemului.
Grafana este cel mai bun instrument disponibil pentru vizualizarea valorilor și se integrează perfect cu Prometeu.