

Învățarea prin ansamblu vă poate ajuta să luați decizii mai bune și să rezolvați multe provocări din viața reală prin combinarea deciziilor din mai multe modele.
Învățarea automată (ML) continuă să își extindă aripile în mai multe sectoare și industrii, fie că este vorba de finanțe, medicină, dezvoltare de aplicații sau securitate.
Antrenarea corectă a modelelor ML vă va ajuta să obțineți un succes mai mare în afacerea dvs. sau în rolul dvs. de muncă și există diverse metode pentru a obține acest lucru.
În acest articol, voi discuta despre învățarea prin ansamblu, importanța acesteia, cazurile de utilizare și tehnicile.
Rămâneţi aproape!
Cuprins
Ce este învățarea prin ansamblu?
În învățarea automată și statistică, „ansamblu” se referă la metode care generează diverse ipoteze în timp ce se utilizează un cursant de bază comun.
Și învățarea prin ansamblu este o abordare de învățare automată în care modele multiple (cum ar fi experții sau clasificatorii) sunt create strategic și combinate cu scopul de a rezolva o problemă de calcul sau de a face predicții mai bune.
Această abordare urmărește să îmbunătățească predicția, aproximarea funcției, clasificarea etc., performanța unui model dat. De asemenea, este folosit pentru a elimina posibilitatea ca tu să alegi un model sărac sau mai puțin valoros dintre multe. Pentru a obține o performanță predictivă îmbunătățită, sunt utilizați mai mulți algoritmi de învățare.
Importanța învățării ansamblului în ML
În modelele de învățare automată, există unele surse, cum ar fi părtinirea, varianța și zgomotul, care pot cauza erori. Învățarea prin ansamblu poate ajuta la reducerea acestor surse care cauzează erori și poate asigura stabilitatea și acuratețea algoritmilor dvs. ML.
Iată de ce învățarea prin ansamblu este utilizată în diferite scenarii:
Alegerea clasificatorului potrivit
Învățarea ansamblului vă ajută să alegeți un model sau un clasificator mai bun, reducând în același timp riscul care poate rezulta din cauza selecției slabe a modelului.

Există diferite tipuri de clasificatoare utilizate pentru diferite probleme, cum ar fi mașini de vectori suport (SVM), perceptron multistrat (MLP), clasificatori Bayes naivi, arbori de decizie etc. În plus, există diferite realizări ale algoritmilor de clasificare pe care trebuie să le alegeți. . Performanța diferitelor date de antrenament poate fi, de asemenea, diferită.
Dar, în loc să selectați un singur model, dacă utilizați un ansamblu de toate aceste modele și combinați rezultatele lor individuale, puteți evita să selectați modele mai slabe.
Volumul datelor
Multe metode și modele ML nu sunt atât de eficiente în ceea ce privește rezultatele lor dacă le furnizați date inadecvate sau un volum mare de date.
Pe de altă parte, învățarea ansamblului poate funcționa în ambele scenarii, chiar dacă volumul de date este prea mic sau prea mare.
- Dacă există date inadecvate, puteți utiliza bootstrapping pentru a antrena diferiți clasificatori cu ajutorul diferitelor mostre de date bootstrap.
- Dacă există un volum mare de date care poate face dificilă antrenamentul unui singur clasificator, atunci poate partiționa strategic datele în subseturi mai mici.
Complexitate

Este posibil ca un singur clasificator să nu poată rezolva unele probleme extrem de complexe. Limitele lor de decizie care separă datele diferitelor clase ar putea fi foarte complexe. Deci, dacă aplicați un clasificator liniar la o graniță complexă neliniară, acesta nu va putea să-l învețe.
Cu toate acestea, la combinarea corectă a unui ansamblu de clasificatori liniari adecvați, îl puteți face să învețe o limită neliniară dată. Clasificatorul va împărți datele în mai multe partiții ușor de învățat și mai mici, iar fiecare clasificator va învăța doar o partiție mai simplă. În continuare, diferiți clasificatori vor fi combinați pentru a produce o aprox. hotar de decizie.
Estimarea încrederii
În învățarea prin ansamblu, un vot de încredere este atribuit unei decizii pe care a luat-o un sistem. Să presupunem că aveți un ansamblu de diferiți clasificatori instruiți pentru o anumită problemă. Dacă majoritatea clasificatorilor sunt de acord cu decizia luată, rezultatul acesteia poate fi considerat ca un ansamblu cu o decizie de mare încredere.
Pe de altă parte, dacă jumătate dintre clasificatori nu sunt de acord cu decizia luată, se spune că este un ansamblu cu o decizie cu încredere scăzută.
Cu toate acestea, încrederea scăzută sau ridicată nu este întotdeauna decizia corectă. Dar există șanse mari ca o decizie cu mare încredere să fie corectă dacă ansamblul este pregătit corespunzător.
Acuratețe cu Data Fusion
Datele colectate din mai multe surse, atunci când sunt combinate strategic, pot îmbunătăți acuratețea deciziilor de clasificare. Această acuratețe este mai mare decât cea realizată cu ajutorul unei singure surse de date.
Cum funcționează învățarea prin ansamblu?
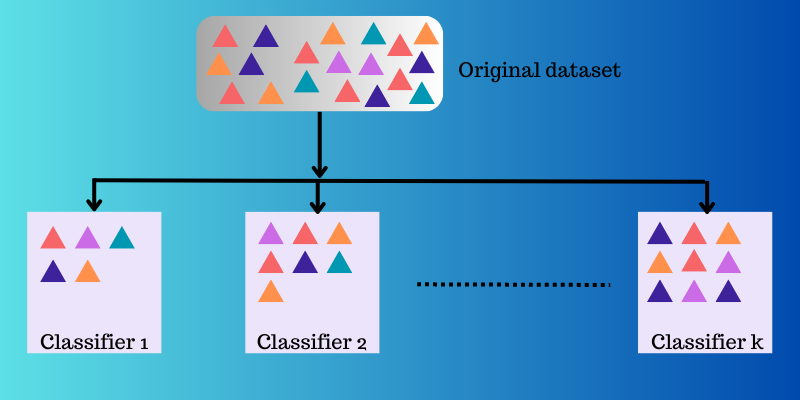
Învățarea ansamblului ia mai multe funcții de mapare pe care diferiți clasificatori le-au învățat și apoi le combină pentru a crea o singură funcție de mapare.
Iată un exemplu despre cum funcționează învățarea prin ansamblu.
Exemplu: creați o aplicație bazată pe produse alimentare pentru utilizatorii finali. Pentru a oferi utilizatorilor o experiență de înaltă calitate, doriți să colectați feedback-ul lor cu privire la problemele cu care se confruntă, lacune importante, erori, bug-uri etc.
Pentru aceasta, puteți cere părerile familiei, prietenilor, colegilor și altor persoane cu care comunicați frecvent cu privire la alegerile lor alimentare și experiența lor de a comanda mâncare online. De asemenea, puteți lansa aplicația în versiune beta pentru a colecta feedback în timp real, fără părtinire sau zgomot.
Deci, ceea ce faceți de fapt aici este să luați în considerare mai multe idei și opinii de la diferiți oameni pentru a ajuta la îmbunătățirea experienței utilizatorului.
Învățarea prin ansamblu și modelele sale funcționează într-un mod similar. Utilizează un set de modele și le combină pentru a produce o ieșire finală pentru a îmbunătăți acuratețea și performanța predicțiilor.
Tehnici de bază de învățare prin ansamblu
#1. Modul
Un „mod” este o valoare care apare într-un set de date. În învățarea prin ansamblu, profesioniștii ML folosesc mai multe modele pentru a crea predicții despre fiecare punct de date. Aceste predicții sunt considerate voturi individuale și predicția pe care majoritatea modelelor au făcut-o este considerată predicția finală. Este folosit mai ales în probleme de clasificare.
Exemplu: Patru persoane au evaluat cererea dvs. cu 4, în timp ce unul dintre ei a evaluat-o cu 3, atunci modul ar fi 4, deoarece majoritatea a votat 4.
#2. Medie/Medie
Folosind această tehnică, profesioniștii iau în considerare toate predicțiile modelului și își calculează media pentru a veni cu predicția finală. Este folosit mai ales pentru a face predicții pentru probleme de regresie, pentru a calcula probabilități în probleme de clasificare și multe altele.
Exemplu: în exemplul de mai sus, în care patru persoane au evaluat aplicația dvs. 4, în timp ce o persoană a evaluat-o cu 3, media ar fi (4+4+4+4+3)/5=3,8
#3. Medie ponderată
În această metodă de învățare prin ansamblu, profesioniștii alocă diferite ponderi diferitelor modele pentru a face o predicție. Aici, greutatea alocată descrie relevanța fiecărui model.
Exemplu: Să presupunem că 5 persoane au oferit feedback cu privire la cererea dvs. Dintre ei, 3 sunt dezvoltatori de aplicații, în timp ce 2 nu au experiență în dezvoltarea de aplicații. Deci, feedback-ul acelor 3 persoane va primi mai multă pondere decât restul 2.
Tehnici avansate de învățare prin ansamblu
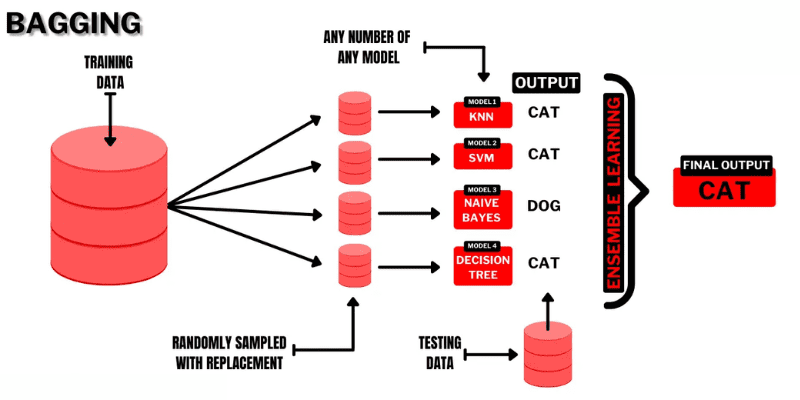
#1. Bagare
Bagging (Bootstrap AGGregatING) este o tehnică de învățare prin ansamblu extrem de intuitivă și simplă, cu o performanță bună. După cum sugerează și numele, este realizat prin combinarea a doi termeni „Bootstrap” și „agregare”.
Bootstrapping-ul este o altă metodă de eșantionare în care va trebui să creați subseturi de mai multe observații luate dintr-un set de date original cu înlocuire. Aici, dimensiunea subsetului va fi aceeași cu cea a setului de date original.
 Sursa: programator Buggy
Sursa: programator Buggy
Deci, în ambalaj, subseturile sau sacii sunt folosite pentru a înțelege distribuția setului complet. Cu toate acestea, subseturile ar putea fi mai mici decât setul de date original din ambalaj. Această metodă implică un singur algoritm ML. Scopul combinării rezultatelor diferitelor modele este obținerea unui rezultat generalizat.
Iată cum funcționează ambalarea:
- Mai multe subseturi sunt generate din setul original și observațiile sunt selectate cu înlocuiri. Subseturile sunt utilizate în formarea modelelor sau arborilor de decizie.
- Se creează un model slab sau de bază pentru fiecare subset. Modelele vor fi independente unele de altele și vor rula în paralel.
- Predicția finală va fi realizată prin combinarea fiecărei predicții din fiecare model folosind statistici precum media, votul etc.
Algoritmii populari utilizați în această tehnică de ansamblu sunt:
- pădure întâmplătoare
- Arbori de decizie împovărați
Avantajul acestei metode este că ajută la menținerea erorilor de varianță la minim în arborii de decizie.
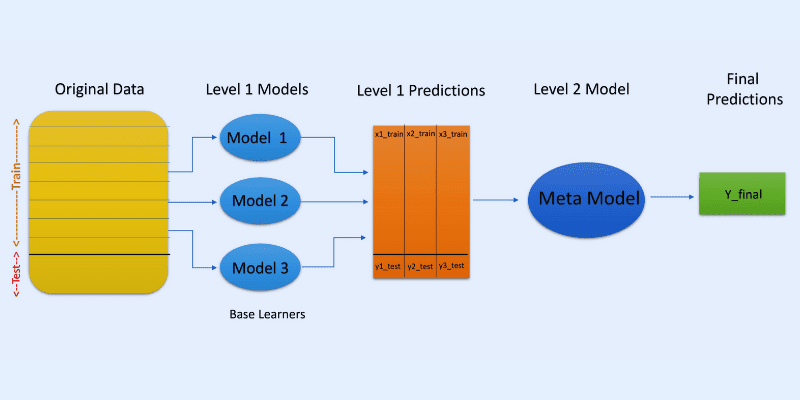
#2. Stivuire
 Sursa imagine: OpenGenus IQ
Sursa imagine: OpenGenus IQ
În generalizarea stivuită sau stivuită, predicțiile din diferite modele, cum ar fi un arbore de decizie, sunt utilizate pentru a crea un model nou pentru a face predicții pe acest set de testare.
Stivuirea implică crearea de subseturi de date bootstrapped pentru modele de antrenament, similar cu bagajul. Dar aici, ieșirea modelelor este luată ca o intrare pentru a fi transmisă unui alt clasificator, cunoscut sub numele de meta-clasificator pentru predicția finală a eșantioanelor.
Motivul pentru care sunt utilizate două straturi de clasificare este pentru a determina dacă seturile de date de antrenament sunt învățate corespunzător. Deși abordarea în două straturi este comună, pot fi utilizate și mai multe straturi.
De exemplu, puteți utiliza 3-5 modele în primul strat sau nivel-1 și un singur model în stratul 2 sau nivelul 2. Acesta din urmă va combina predicțiile obținute la nivelul 1 pentru a face predicția finală.
În plus, puteți utiliza orice model de învățare ML pentru agregarea predicțiilor; un model liniar cum ar fi regresia liniară, regresia logistică etc., este comun.
Algoritmii ML populari utilizați în stivuire sunt:
- Amestecare
- Super ansamblu
- Modele stivuite
Notă: Blending folosește un set de validare sau de așteptare din setul de date de antrenament pentru a face predicții. Spre deosebire de stivuire, amestecarea implică previziuni care trebuie făcute numai din holdout.
#3. Amplificare
Boosting-ul este o metodă iterativă de învățare prin ansamblu care ajustează ponderea unei anumite observații în funcție de ultima sau anterioară clasificare a acesteia. Aceasta înseamnă că fiecare model ulterior urmărește corectarea erorilor găsite în modelul anterior.
Dacă observația nu este clasificată corect, atunci amplificarea crește ponderea observației.
În boosting, profesioniștii antrenează primul algoritm pentru amplificare pe un set de date complet. În continuare, ei construiesc algoritmii ML următori folosind reziduurile extrase din algoritmul de amplificare anterior. Astfel, se acordă mai multă pondere observațiilor incorecte prezise de modelul anterior.
Iată cum funcționează treptat:
- Un subset va fi generat din setul de date original. Fiecare punct de date va avea inițial aceleași ponderi.
- Crearea unui model de bază are loc pe submult.
- Predicția se va face pe setul de date complet.
- Folosind valorile reale și prezise, erorile vor fi calculate.
- Observațiile prezise incorect vor primi mai multe ponderi
- Se va crea un nou model și se va face predicția finală pe acest set de date, în timp ce modelul încearcă să corecteze erorile făcute anterior. Mai multe modele vor fi create într-un mod similar, fiecare corectând erorile anterioare
- Predicția finală se va face din modelul final, care este media ponderată a tuturor modelelor.
Algoritmii populari de amplificare sunt:
- CatBoost
- GBM ușor
- AdaBoost
Avantajul boosting-ului este că generează predicții superioare și reduce erorile datorate părtinirii.
Alte tehnici de ansamblu

Un amestec de experți: este folosit pentru a antrena mai mulți clasificatori, iar rezultatele lor sunt ansamblu cu o regulă liniară generală. Aici, ponderile date combinațiilor sunt determinate de un model antrenabil.
Votul majoritar: implică alegerea unui clasificator impar, iar predicțiile sunt calculate pentru fiecare eșantion. Clasa care primește clasa maximă dintr-un grup de clasificatori va fi clasa prevăzută a ansamblului. Este folosit pentru rezolvarea unor probleme precum clasificarea binară.
Regula maximă: folosește distribuțiile de probabilitate ale fiecărui clasificator și folosește încrederea în a face predicții. Este folosit pentru probleme de clasificare cu mai multe clase.
Cazuri de utilizare în viața reală ale învățării prin ansamblu
#1. Detectarea feței și a emoțiilor
Învățarea ansamblului utilizează tehnici precum analiza independentă a componentelor (ICA) pentru a realiza detectarea feței.
Mai mult, învățarea în ansamblu este folosită în detectarea emoției unei persoane prin detectarea vorbirii. În plus, capacitățile sale ajută utilizatorii să realizeze detectarea emoțiilor faciale.
#2. Securitate
Detectarea fraudelor: Învățarea ansamblului ajută la creșterea puterii modelării comportamentului normal. Acesta este motivul pentru care este considerat a fi eficient în detectarea activităților frauduloase, de exemplu, în sistemele de carduri de credit și bancare, fraude de telecomunicații, spălare de bani etc.

DDoS: Distributed denial of service (DDoS) este un atac mortal asupra unui ISP. Clasificatoarele de ansamblu pot reduce detectarea erorilor și, de asemenea, pot discrimina atacurile de traficul real.
Detectarea intruziunilor: Învățarea ansamblului poate fi utilizată în sistemele de monitorizare, cum ar fi instrumentele de detectare a intruziunilor, pentru a detecta codurile de intruziune prin monitorizarea rețelelor sau sistemelor, găsirea anomaliilor și așa mai departe.
Detectarea programelor malware: Învățarea ansamblului este destul de eficientă în detectarea și clasificarea codului malware, cum ar fi viruși și viermi de computer, ransomware, cai troieni, spyware etc., folosind tehnici de învățare automată.
#3. Învățare incrementală
În învățarea incrementală, un algoritm ML învață dintr-un nou set de date, păstrând în același timp învățările anterioare, dar fără a accesa datele anterioare pe care le-a văzut. Sistemele de ansamblu sunt utilizate în învățarea incrementală, făcându-l să învețe un clasificator adăugat pentru fiecare set de date pe măsură ce acesta devine disponibil.
#4. Medicament
Clasificatoarele de ansamblu sunt utile în domeniul diagnosticului medical, cum ar fi detectarea tulburărilor neuro-cognitive (cum ar fi Alzheimer). Efectuează detectarea luând seturi de date RMN ca intrări și clasificând citologia cervicală. În afară de asta, se aplică în proteomică (studiul proteinelor), neuroștiință și în alte domenii.
#5. Teledetecție
Detectarea modificărilor: clasificatorii de ansamblu sunt utilizați pentru a efectua detectarea schimbărilor prin metode precum votul mediu bayesian și majoritar.
Cartografierea acoperirii terenului: Metodele de învățare în ansamblu, cum ar fi stimularea, arborii de decizie, analiza componentelor principale ale nucleului (KPCA), etc. sunt utilizate pentru a detecta și a mapa în mod eficient acoperirea terenului.
#6. Finanţa
Precizia este un aspect critic al finanțelor, fie că este vorba de calcul sau de predicție. Ea influențează foarte mult rezultatul deciziilor pe care le luați. Acestea pot, de asemenea, să analizeze schimbările în datele pieței de valori, să detecteze manipularea prețurilor acțiunilor și multe altele.
Resurse suplimentare de învățare

#1. Metode de ansamblu pentru învățare automată
Această carte vă va ajuta să învățați și să implementați metode importante de învățare prin ansamblu de la zero.
#2. Metode de ansamblu: Fundamente și algoritmi
Această carte conține elementele de bază ale învățării ansamblului și algoritmii săi. De asemenea, prezintă modul în care este folosit în lumea reală.
#3. Învățare prin ansamblu
Oferă o introducere într-o metodă de ansamblu unificat, provocări, aplicații etc.
#4. Învățare automată prin ansamblu: metode și aplicații:
Oferă o acoperire largă a tehnicilor avansate de învățare prin ansamblu.
Concluzie
Sper că acum aveți o idee despre învățarea prin ansamblu, metodele sale, cazurile de utilizare și de ce utilizarea acesteia poate fi benefică pentru cazul dvs. de utilizare. Are potențialul de a rezolva multe provocări din viața reală, de la domeniul securității și al dezvoltării de aplicații până la finanțe, medicină și multe altele. Utilizările sale se extind, așa că este probabil să existe mai multe îmbunătățiri în acest concept în viitorul apropiat.
De asemenea, puteți explora câteva instrumente pentru generarea de date sintetice pentru a antrena modele de învățare automată