
Calculul este la apogeu în aceste zile și continuă să crească. În ultimele 3 decenii, mașinile au evoluat și s-au îmbunătățit foarte mult, în special în ceea ce privește puterea de procesare și multitasking.
Vă puteți imagina cât de nebunește ar putea fi creșterea performanței dacă sarcinile sunt împărțite între mai multe mașini și executate în paralel? Aceasta se numește calcul distribuit. Este ca munca în echipă pentru computere.
Cu toate acestea, s-ar putea să vă întrebați de ce discutăm despre acest lucru de calcul distribuit. Deoarece calculul distribuit și Amazon EMR (Elastic MapReduce) sunt foarte înrudite. Adică, EMR by AWS utilizează principii de calcul distribuit pentru a procesa și analiza cantități mari de date pe cloud.
Cu Amazon EMR, acum puteți analiza și procesa date mari folosind un cadru de procesare distribuită la alegere pe instanțe S3.
Cuprins
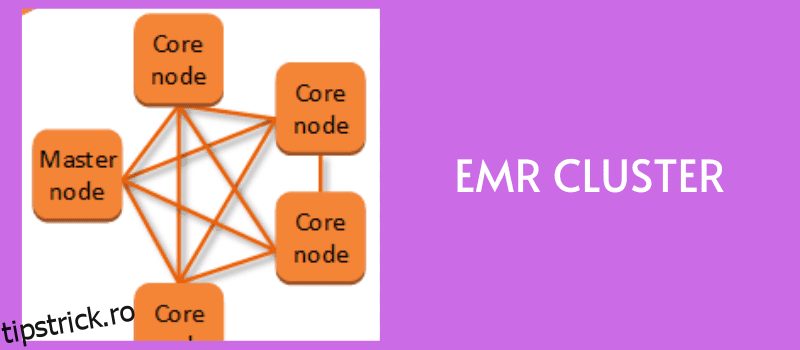
Cum funcționează Amazon EMR?
Sursă: aws.amazon.com
În primul rând, introduceți datele în orice magazin de date, cum ar fi Amazon S3, DynamoDB sau alte platforme de stocare AWS, deoarece toate se integrează bine cu EMR.
Acum, veți avea nevoie de un cadru de date mari pentru a procesa și analiza aceste date. Cu diverse cadre de date mari din care puteți alege, cum ar fi Apache Spark, Hadoop, Hive și Presto, îl puteți alege pe cel care se potrivește cerințelor dvs. și îl puteți încărca în depozitul de date ales.
Un cluster EMR de instanțe EC2 este creat pentru a procesa și analiza în paralel datele. Puteți configura numărul de noduri și alte detalii pentru a crea clusterul.
Stocarea dvs. principală distribuie datele și cadrele către aceste noduri, unde bucățile de date sunt procesate individual, iar rezultatele sunt combinate.
Odată ce rezultatele sunt disponibile, puteți închide clusterul pentru a elibera toate resursele alocate.
Beneficiile Amazon EMR
Întreprinderile, fie mici, fie mari, iau întotdeauna în considerare adoptarea de soluții rentabile. Atunci de ce nu un Amazon EMR accesibil? Când poate simplifica rularea diferitelor cadre de date mari pe AWS, oferind o modalitate convenabilă de a vă procesa și analiza datele, economisind în același timp niște bani.
✅ Elasticitate: îi puteți ghici natura prin intermediul termenului „Elastic MapReduce”. Termenul spune – Pe baza cerințelor, Amazon EMR vă permite să redimensionați cu ușurință clusterele manual sau automat. De exemplu, este posibil să aveți nevoie de 200 de instanțe pentru a vă procesa solicitările acum, iar aceasta poate ajunge la 600 de instanțe după o oră sau două. Deci, Amazon EMR este cel mai bun atunci când aveți nevoie doar de scalabilitate pentru a vă adapta la schimbările rapide ale cererii.
✅ Magazine de date: Fie că este vorba despre Amazon S3, sistemul de fișiere distribuit Hadoop, Amazon DynamoDB sau alte magazine de date AWS, Amazon EMR se integrează perfect cu acesta.
✅ Instrumente de procesare a datelor: Amazon EMR acceptă diverse cadre de date mari, inclusiv Apache Spark, Hive, Hadoop și Presto. În plus, puteți rula algoritmi și instrumente de învățare profundă și de învățare automată pe acest cadru.
✅ Eficient din punct de vedere al costurilor: Spre deosebire de alte produse comerciale, Amazon EMR vă permite să plătiți numai pentru resursele pe care le utilizați pe oră. În plus, puteți alege dintre diferite modele de prețuri care se aliniază bugetului dvs.
✅ Personalizare cluster: cadrul vă permite să personalizați fiecare instanță a clusterului dvs. De asemenea, puteți asocia un cadru de date mari cu un tip de cluster perfect. De exemplu, instanțele bazate pe Apache Spark și Graviton2 sunt o combinație mortală pentru performanță optimizată în EMR.
✅ Controale de acces: puteți utiliza instrumentele AWS Identity and Access Management (IAM) pentru a controla permisiunile în EMR. De exemplu, puteți permite anumitor utilizatori să editeze clusterul, în timp ce alții pot vedea doar clusterul.
✅ Integrare: Integrarea EMR cu toate celelalte servicii AWS este fără probleme. Cu aceasta, puteți obține puterea serverelor virtuale, securitate robustă, capacitate extensibilă și capabilități de analiză în EMR.
Cazuri de utilizare Amazon EMR
#1. Învățare automată

Analizați datele folosind învățarea automată și învățarea profundă în Amazon EMR. De exemplu, rularea diverșilor algoritmi pe date legate de sănătate pentru a urmări mai multe valori de sănătate, cum ar fi indicele de masă corporală, frecvența cardiacă, tensiunea arterială, procentul de grăsime etc., este crucială pentru dezvoltarea unui instrument de urmărire a fitness-ului. Toate acestea pot fi realizate pe instanțe EMR mai rapid și mai eficient.
#2. Efectuați transformări mari
Comercianții cu amănuntul extrag de obicei o cantitate mare de date digitale pentru a analiza comportamentul clienților și pentru a îmbunătăți afacerea. Pe aceeași linie, Amazon EMR va fi eficient în extragerea datelor mari și în efectuarea transformărilor mari folosind Spark.
#3. Exploatarea datelor

Doriți să abordați un set de date care necesită mult timp pentru a fi procesat? Amazon EMR este exclusiv pentru extragerea datelor și analiza predictivă a seturilor de date complexe, în special în cazurile de date nestructurate. Mai mult, arhitectura sa de cluster este excelentă pentru procesarea paralelă.
#4. Scopuri de cercetare
Finalizați-vă cercetarea cu acest cadru rentabil și eficient numit Amazon EMR. Datorită scalabilității sale, rareori vezi probleme de performanță în timp ce rulezi seturi mari de date pe EMR. Deci, acest cadru este foarte adaptat în laboratoarele de cercetare și analiză a datelor mari.
#5. Streaming în timp real
Un alt avantaj major Amazon EMR este suportul pentru streaming în timp real. Construiți conducte scalabile de date în flux în timp real pentru jocuri online, streaming video, monitorizare a traficului și tranzacționare cu acțiuni folosind Apache Kafka și Apache Flink pe Amazon EMR.
Cum este EMR diferit de Amazon Glue și Redshift?
AWS EMR vs. Glue
Cele două servicii AWS puternice – Amazon EMR și Amazon Glue au câștigat o remarcă loială în tratarea datelor dvs.
Extragerea datelor din diverse surse, transformarea și încărcarea acestora în depozitele de date este rapidă și eficientă cu Amazon Glue, în timp ce Amazon EMR vă ajută să procesați aplicațiile de date mari folosind Hadoop, Spark, Hive etc.,
Practic, AWS Glue vă permite să colectați și să pregătiți date pentru analiză, iar Amazon EMR vă permite să le procesați.
EMR vs Redshift
Imaginează-ți că navighezi în mod constant prin datele tale și le interoghezi cu ușurință. SQL este ceva pe care îl folosiți adesea pentru a face acest lucru. Pe aceeași linie, Redshift oferă servicii optimizate de procesare analitică online pentru a interoga cu ușurință volume mari de date folosind SQL.
Când stocați date, veți avea acces la foarte scalabil, sigur și disponibil Amazon EMR utilizează furnizori de stocare terți, cum ar fi S3 și DynamoDB. În schimb, Redshift are propriul strat de date, permițându-vă să stocați date în format coloane.
Abordări de optimizare a costurilor Amazon EMR

#1. Vin cu date formatate
Cu cât datele sunt mai mari, cu atât este nevoie de mai mult pentru procesare. În plus, furnizarea datelor brute direct către cluster face ca acesta să fie și mai complex, necesitând mai mult timp pentru a găsi piesa pe care intenționați să o procesați.
Deci, datele formatate vin cu metadate despre coloane, tipul de date, dimensiunea și multe altele, folosind care puteți economisi timp în căutări și agregări.
De asemenea, reduceți dimensiunea datelor prin utilizarea tehnicilor de comprimare a datelor, deoarece este relativ mai ușor să procesați seturi de date mai mici.
#2. Utilizați servicii de stocare la prețuri accesibile
Folosirea serviciilor de stocare primară rentabile reduce cheltuielile majore pentru EMR. Amazon s3 este un serviciu de stocare simplu și accesibil pentru salvarea datelor de intrare și de ieșire. Modelul său cu plata pe măsura utilizării taxă doar pentru spațiul de stocare real pe care l-ați folosit.
#3. Dimensiunea corectă a instanței
Utilizarea instanțelor adecvate cu dimensiunile potrivite poate reduce semnificativ bugetul cheltuit pentru EMR. Instanțele EC2 sunt de obicei taxate pe secundă, iar prețul crește în funcție de dimensiunea lor, dar indiferent dacă utilizați un cluster mare de .7x sau un cluster mare de .36x, costul gestionării lor este același. Deci, utilizarea eficientă a mașinilor mai mari este rentabilă în comparație cu utilizarea mai multor mașini mici.
#4. Instanțe spot
Instanțele spot sunt o opțiune excelentă pentru a cumpăra resurse EC2 neutilizate la reduceri. În comparație cu cazurile la cerere, acestea sunt mai ieftine, dar nu sunt permanente, deoarece pot fi revendicate atunci când cererea crește. Deci, acestea sunt flexibile pentru toleranța la erori, dar nu sunt potrivite pentru lucrări de lungă durată.
#5. Scalare automată
Funcția sa de scalare automată este tot ce aveți nevoie pentru a evita clusterele supradimensionate sau subdimensionate. Acest lucru vă permite să alegeți numărul și tipul corect de instanțe din cluster pe baza volumului de lucru, optimizând costurile.
Cuvinte finale
Nu există sfârșit pentru tehnologia cloud și big data, lăsându-vă instrumente și cadre nesfârșite de învățat și implementat. O astfel de platformă unică pentru a folosi atât big data, cât și cloud-ul este Amazon EMR, deoarece simplifică rularea cadrelor de date mari pentru a procesa și analiza date mari.
Pentru a vă ajuta să începeți cu EMR, acest articol vă arată ce este, cum beneficiază, funcționarea sa, cazurile de utilizare și abordările rentabile.
Apoi, consultați tot ce trebuie să știți despre AWS Athena.