
Pandas este cea mai populară bibliotecă de analiză a datelor pentru Python. Este utilizat pe scară largă de analiștii de date, oamenii de știință de date și inginerii de învățare automată.
Alături de NumPy, este una dintre bibliotecile și instrumentele care trebuie cunoscute pentru oricine lucrează cu date și AI.
În acest articol, vom explora Pandas și caracteristicile care îl fac atât de popular în ecosistemul de date.
Cuprins
Ce este Pandas?
Pandas este o bibliotecă de analiză a datelor pentru Python. Aceasta înseamnă că este folosit pentru a lucra și a manipula date din codul tău Python. Cu Pandas, puteți citi, manipula, vizualiza, analiza și stoca datele în mod eficient.
Numele „Pandas” provine din alăturarea cuvintelor Panel Data, un termen de econometrie care se referă la datele obținute din observarea mai multor indivizi de-a lungul timpului. Pandas a fost lansat inițial în ianuarie 2008 de Wes Kinney și de atunci a devenit cea mai populară bibliotecă pentru cazul său de utilizare.
În centrul Pandas se află două structuri de date esențiale cu care ar trebui să fii familiarizat, Dataframes și Series. Când creați sau încărcați un set de date în Pandas, acesta este reprezentat ca oricare dintre aceste două structuri de date.
În secțiunea următoare, vom explora ce sunt, cum sunt diferite și când este ideal să folosiți oricare dintre ele.
Structuri cheie de date
După cum am menționat mai devreme, toate datele din Pandas sunt reprezentate folosind fie una dintre cele două structuri de date, un Dataframe sau o serie. Aceste două structuri de date sunt explicate în detaliu mai jos.
Cadrul de date
Acest exemplu de cadru de date a fost produs folosind fragmentul de cod din partea de jos a acestei secțiuni
Un Dataframe în Pandas este o structură de date bidimensională cu coloane și rânduri. Este similar cu o foaie de calcul din aplicația ta de calcul sau cu un tabel dintr-o bază de date relațională.
Este alcătuit din coloane, iar fiecare coloană reprezintă un atribut sau o caracteristică din setul dvs. de date. Aceste coloane sunt apoi formate din valori individuale. Această listă sau serie de valori individuale este reprezentată ca obiecte de serie. Vom discuta mai detaliat structura datelor din serie mai târziu în acest articol.
Coloanele dintr-un cadru de date pot avea nume descriptive, astfel încât să se distingă unele de altele. Aceste nume sunt atribuite atunci când cadrul de date este creat sau încărcat, dar pot fi redenumite cu ușurință în orice moment.
Valorile dintr-o coloană trebuie să fie de același tip de date, deși coloanele nu trebuie să conțină date de același tip. Aceasta înseamnă că o coloană de nume dintr-un set de date va stoca exclusiv șiruri. Dar același set de date poate avea alte coloane, cum ar fi vârsta, care stochează int.
Cadrele de date au, de asemenea, un index folosit pentru a face referire la rânduri. Valorile din coloane diferite, dar cu același index formează un rând. În mod implicit, indecșii sunt numerotați, dar pot fi reatribuiți pentru a se potrivi cu setul de date. În exemplul (figurat mai sus, codificat mai jos), setăm coloana index la coloana „luni”.
import pandas as pd
sales_df = pd.DataFrame({
'Month': ['January', 'February', 'March'],
'Jane Doe': [5000, 6000, 5500],
'John Doe': [4500, 6700, 6000]
})
sales_df.set_index(['Month'], inplace=True)
print(sales_df)
Serie
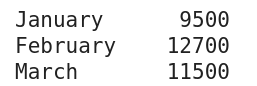 Acest exemplu de serie a fost produs folosind codul din partea de jos a acestei secțiuni
Acest exemplu de serie a fost produs folosind codul din partea de jos a acestei secțiuni
După cum sa discutat mai devreme, o serie este folosită pentru a reprezenta o coloană de date în Pandas. O serie este, prin urmare, o structură de date unidimensională. Acest lucru este în contrast cu un cadru de date care este bidimensional.
Deși o serie este folosită în mod obișnuit ca coloană într-un cadru de date, poate reprezenta, de asemenea, un set de date complet în sine, cu condiția ca setul de date să aibă un singur atribut înregistrat într-o singură coloană. Sau, mai degrabă, setul de date este pur și simplu o listă de valori.
Deoarece o serie este pur și simplu o coloană, nu trebuie să aibă un nume. Cu toate acestea, valorile din Seria sunt indexate. La fel ca indexul unui Dataframe, cadrul de date al unei Serii poate fi modificat de la numerotarea implicită.
În exemplul (figurat mai sus, codificat mai jos), indexul a fost setat la luni diferite folosind metoda set_axis a unui obiect din seria Pandas.
import pandas as pd total_sales = pd.Series([9500, 12700, 11500]) months = ['January', 'February', 'March'] total_sales = total_sales.set_axis(months) print(total_sales)
Caracteristicile Pandas
Acum că aveți o idee bună despre ce este Pandas și despre structurile cheie de date pe care le utilizează, putem începe să discutăm despre caracteristicile care fac din Pandas o bibliotecă de analiză a datelor atât de puternică și, ca rezultat, incredibil de populară în cadrul științei datelor și învățării automate. Ecosisteme.
#1. Manipulare de date
Obiectele Dataframe și Series sunt modificabile. Puteți adăuga sau elimina coloane după cum este necesar. În plus, Pandas vă permite să adăugați rânduri și chiar să îmbinați seturi de date.
Puteți efectua calcule numerice, cum ar fi normalizarea datelor și efectuarea de comparații logice la nivel de elemente. Pandas vă permite, de asemenea, să grupați date și să aplicați funcții agregate, cum ar fi medie, medie, max și min. Acest lucru face ca lucrul cu date în Pandas să fie o ușoară.
#2. Curățarea datelor
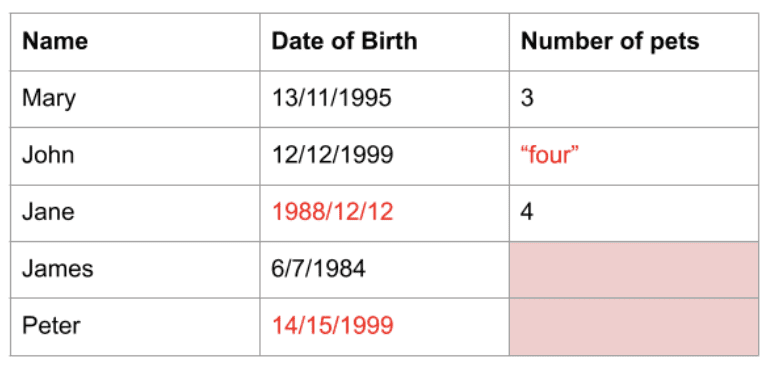
Datele obținute din lumea reală au adesea valori care fac dificilă lucrul cu sau nu ideal pentru analiză sau utilizare în modelele de învățare automată. Datele ar putea fi de tipul de date greșit, în format greșit sau ar putea lipsi complet. În orice caz, aceste date necesită o preprocesare, denumită curățare, înainte de a putea fi utilizate.
Pandas are funcții care vă ajută să vă curățați datele. De exemplu, în Pandas, puteți șterge rândurile duplicate, puteți elimina coloane sau rânduri cu date lipsă și puteți înlocui valorile fie cu valori implicite, fie cu alte valori, cum ar fi media coloanei. Există mai multe funcții și biblioteci care funcționează cu Pandas pentru a vă permite să faceți mai multă curățare a datelor.
#3. Vizualizarea datelor
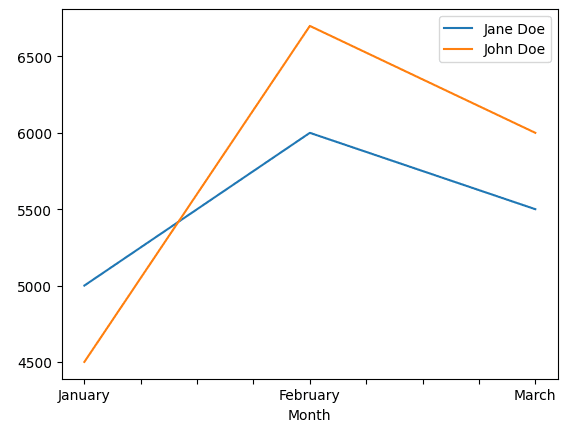 Acest grafic a fost generat cu codul de sub această secțiune
Acest grafic a fost generat cu codul de sub această secțiune
Deși nu este o bibliotecă de vizualizare precum Matplotlib, Pandas are funcții pentru a crea vizualizări de date de bază. Și, deși sunt de bază, totuși își fac treaba în majoritatea cazurilor.
Cu Pandas, puteți reprezenta cu ușurință grafice cu bare, histograme, matrici de împrăștiere și alte tipuri diferite de diagrame. Combinați asta cu unele manipulări de date pe care le puteți face în Python și puteți crea vizualizări și mai complicate pentru a vă înțelege mai bine datele.
import pandas as pd
sales_df = pd.DataFrame({
'Month': ['January', 'February', 'March'],
'Jane Doe': [5000, 6000, 5500],
'John Doe': [4500, 6700, 6000]
})
sales_df.set_index(['Month'], inplace=True)
sales_df.plot.line()
#4. Analiza serii temporale
Pandas acceptă, de asemenea, lucrul cu date marcate de timp. Când Pandas recunoaște o coloană ca având valori date și oră, puteți efectua multe operații pe aceeași coloană, care sunt utile atunci când lucrați cu date din seria temporală.
Acestea includ gruparea observațiilor în funcție de perioadă de timp și aplicarea de funcții agregate acestora, cum ar fi suma sau media sau obținerea celor mai vechi sau cele mai recente observații folosind min și max. Există, desigur, multe alte lucruri pe care le puteți face cu datele serii cronologice în Pandas.
#5. Intrare/ieșire în Pandas
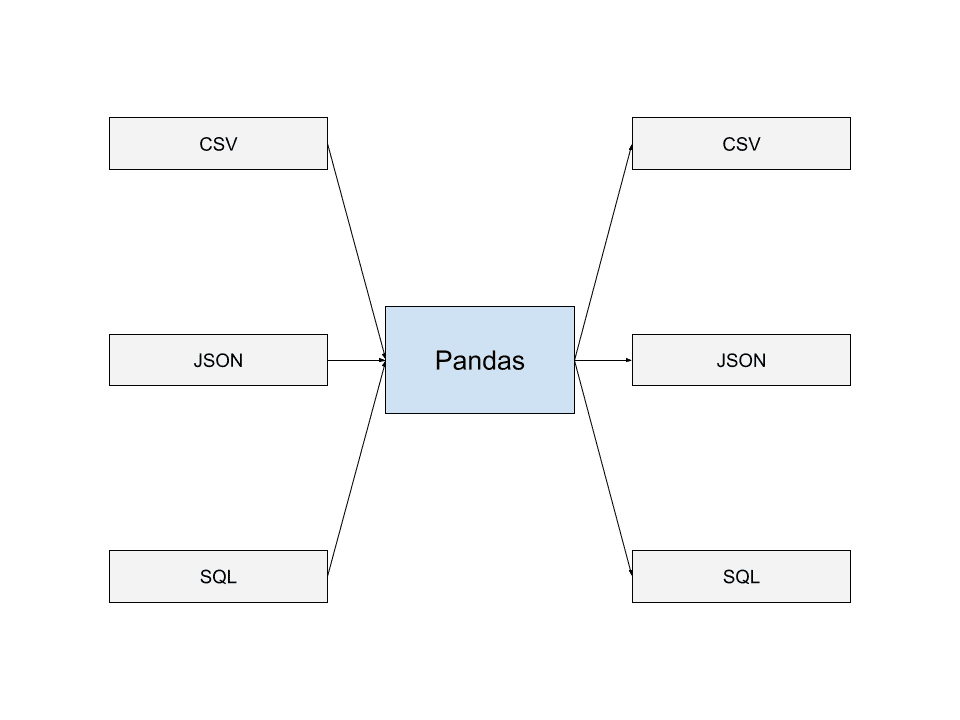
Pandas este capabil să citească date din cele mai comune formate de stocare a datelor. Acestea includ JSON, SQL Dumps și CSV-uri. De asemenea, puteți scrie date în fișiere în multe dintre aceste formate.
Această capacitate de a citi și de a scrie în diferite formate de fișiere de date îi permite lui Pandas să interacționeze fără probleme cu alte aplicații și să construiască conducte de date care se integrează bine cu Pandas. Acesta este unul dintre motivele pentru care Pandas este utilizat pe scară largă de mulți dezvoltatori.
#6. Integrare cu alte biblioteci
Pandas are, de asemenea, un ecosistem bogat de instrumente și biblioteci construite deasupra acestuia pentru a-și completa funcționalitatea. Acest lucru îl face o bibliotecă și mai puternică și mai utilă.
Instrumentele din ecosistemul Pandas își îmbunătățesc funcționalitatea în diferite domenii, inclusiv curățarea datelor, vizualizare, învățare automată, intrare/ieșire și paralelizare. Pandas menține un registru al acestor instrumente în documentația lor.
Considerații de performanță și eficiență în Pandas
În timp ce Pandas strălucește în majoritatea operațiunilor, poate fi notoriu de lent. Partea bună este că puteți optimiza codul și îmbunătăți viteza acestuia. Pentru a face acest lucru, trebuie să înțelegeți cum este construit Pandas.
Pandas este construit pe NumPy, o bibliotecă populară Python pentru calcul numeric și științific. Prin urmare, la fel ca NumPy, Pandas funcționează mai eficient atunci când operațiunile sunt vectorizate, spre deosebire de alegerea de celule sau rânduri individuale folosind bucle.
Vectorizarea este o formă de paralelizare în care aceeași operație este aplicată mai multor puncte de date simultan. Acesta este denumit SIMD – Instrucțiune unică, date multiple. Profitarea de operațiuni vectorizate va îmbunătăți dramatic viteza și performanța Pandas.
Deoarece folosesc matrice NumPy sub capotă, structurile de date DataFrame și Series sunt mai rapide decât dicționarele și listele lor alternative.
Implementarea implicită Pandas rulează pe un singur nucleu CPU. O altă modalitate de a vă accelera codul este să utilizați biblioteci care permit Pandas să utilizeze toate nucleele CPU disponibile. Acestea includ Dask, Vaex, Modin și IPython.
Comunitate și Resurse
Fiind o bibliotecă populară a celui mai popular limbaj de programare, Pandas are o comunitate mare de utilizatori și colaboratori. Ca rezultat, există o mulțime de resurse de folosit pentru a învăța cum să-l folosești. Acestea includ documentația oficială Pandas. Dar există și nenumărate cursuri, tutoriale și cărți din care să înveți.
Există, de asemenea, comunități online pe platforme precum Reddit în subreddit-urile r/Python și r/Data Science pentru a pune întrebări și a obține răspunsuri. Fiind o bibliotecă open-source, puteți raporta probleme pe GitHub și chiar puteți contribui cu cod.
Cuvinte finale
Pandas este incredibil de util și puternic ca bibliotecă de știință a datelor. În acest articol, am încercat să-i explic popularitatea explorând caracteristicile care îl fac instrumentul de bază pentru cercetătorii de date și programatori.
Apoi, vedeți cum să creați un Pandas DataFrame.