Colectarea datelor de pe pagini web, cunoscută și ca extragere de date, implică recuperarea informațiilor specifice pe care le dorești. Aceste informații pot include text, imagini, materiale video, evaluări ale utilizatorilor, descrieri de produse și multe altele. Scopurile pentru care se colectează date sunt diverse, de la studiul pieței, analiza sentimentelor consumatorilor, până la analiza comparativă a concurenței și agregarea datelor.
Dacă volumul de date necesare este redus, procesul de extragere poate fi realizat manual, prin simpla copiere și lipire a informațiilor direct într-o foaie de calcul sau alt format de document. Un exemplu în acest sens este cazul unui cumpărător online care caută evaluări ale altor clienți pentru a lua o decizie informată de cumpărare.
Însă, când avem de-a face cu cantități mari de date, este necesară automatizarea procesului de extragere. În acest scop, se pot dezvolta soluții interne de extragere sau se pot utiliza API-uri specializate pentru aceasta, precum API-ul Proxy sau API-ul Scraping.
Cu toate acestea, aceste metode pot întâmpina dificultăți, deoarece multe site-uri web sunt protejate cu captchas. De asemenea, este necesară gestionarea roboților și a proxy-urilor, operațiuni ce pot fi consumatoare de timp și pot limita tipul de conținut ce poate fi extras.
Scraping Browser: O soluție optimă
Browserul Scraping oferit de Bright Data elimină aceste obstacole. Acest browser versatil este proiectat pentru a colecta date de pe pagini web greu accesibile. Dotat cu o interfață grafică (GUI), browserul este controlat prin API-urile Puppeteer sau Playwright, făcându-l invizibil pentru sistemele de detecție a roboților.
Browserul Scraping include funcții de deblocare care gestionează automat orice blocaje întâmpinate. Fiind găzduit pe serverele Bright Data, nu mai este nevoie de o infrastructură locală costisitoare pentru a executa proiecte de extragere de date la scară largă.
Caracteristici ale Browserului Bright Data Scraping
- Deblocare automată a site-urilor: Nu mai este necesară reîmprospătarea manuală a paginii, deoarece browserul se ajustează singur pentru a depăși CAPTCHA-urile, blocările, amprentele digitale și reluările. Browserul Scraping imită comportamentul unui utilizator real.
- Rețea extinsă de proxy-uri: Poți viza orice locație dorești, având la dispoziție o rețea de peste 72 de milioane de IP-uri. Această rețea permite vizarea unor orașe specifice sau chiar furnizori de internet, beneficiind de cea mai performantă tehnologie existentă.
- Scalabilitate: Se pot deschide simultan mii de sesiuni, datorită infrastructurii Bright Data ce susține toate cererile.
- Compatibilitate cu Puppeteer și Playwright: Acest browser permite apeluri API și gestionarea mai multor sesiuni de browser, utilizând fie Puppeteer (Python), fie Playwright (Node.js).
- Economie de timp și resurse: În loc să configurezi proxy-uri manual, Browserul Scraping se ocupă de toate aspectele tehnice. Nu mai este nevoie nici de o infrastructură internă, browserul fiind complet operațional.
Cum se configurează Browserul Scraping
- Accesează site-ul Bright Data și selectează Browserul Scraping din secțiunea „Soluții Scraping”.
- Creează un cont. Vei avea la dispoziție două opțiuni: „Începe perioada de încercare gratuită” și „Începe gratuit cu Google”. Vom alege opțiunea „Începe perioada de încercare gratuită” pentru acest exemplu. Poți crea un cont manual sau folosind contul tău Google.
- După crearea contului, tabloul de bord va afișa mai multe opțiuni. Alege „Proxies & Scraping Infrastructure”.
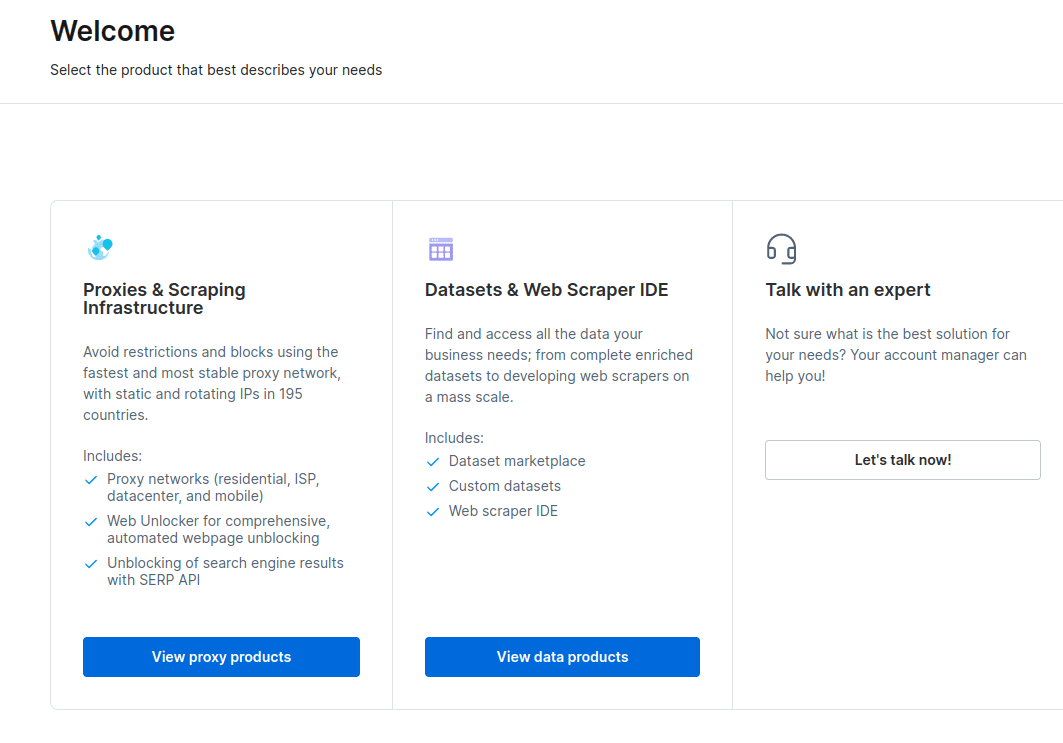
- În fereastra nou deschisă, selectează Browserul Scraping și apoi apasă butonul „Începeți”.
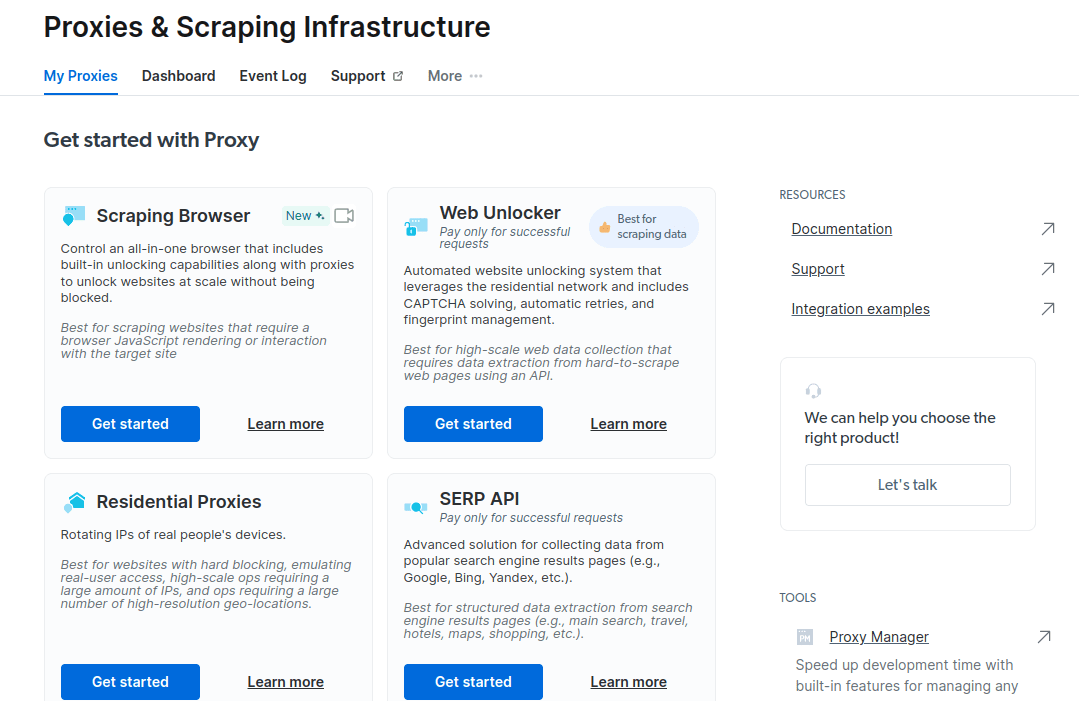
- Salvează și activează configurațiile tale.
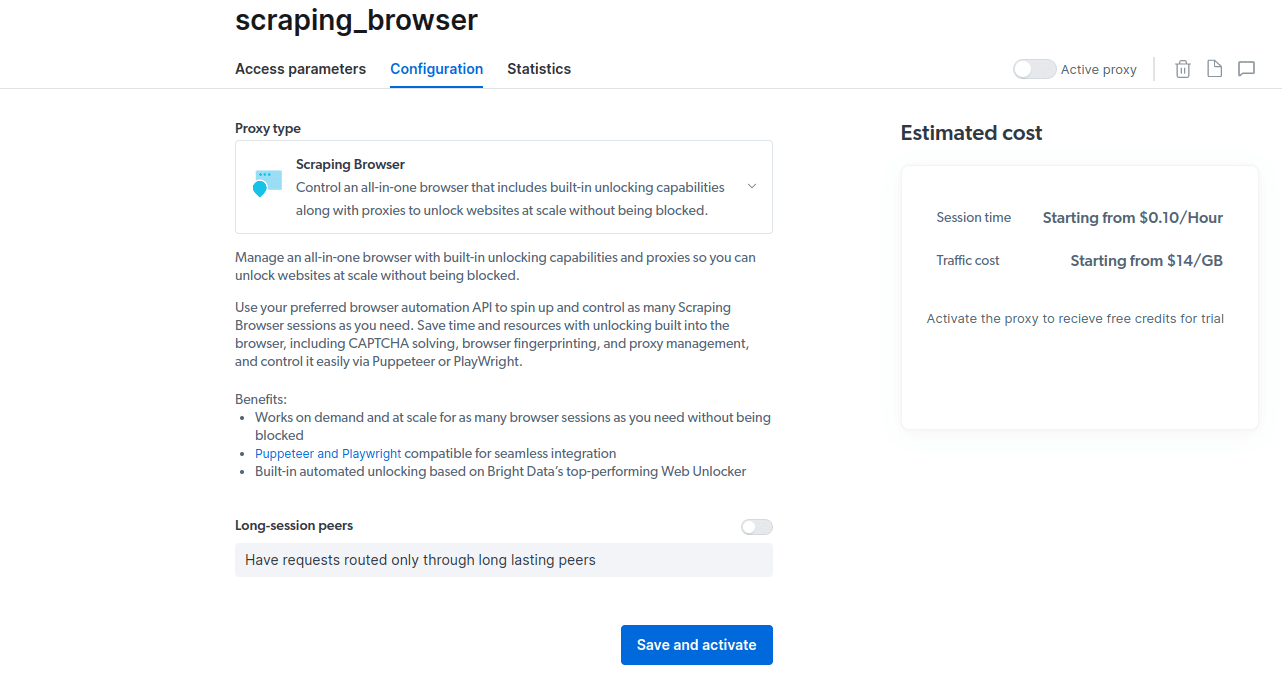
- Activează perioada de încercare gratuită. Prima opțiune îți oferă un credit de 5 USD pentru utilizarea proxy-urilor. Selectează această opțiune pentru a testa produsul. Dacă ești un utilizator frecvent, a doua opțiune îți oferă 50 USD gratuit, dacă îți încarci contul cu 50 USD sau mai mult.
- Introdu informațiile de facturare. Platforma nu va efectua nicio plată. Informațiile de facturare sunt folosite doar pentru a verifica dacă ești un utilizator nou și nu încerci să abuzezi de sistem prin crearea mai multor conturi.
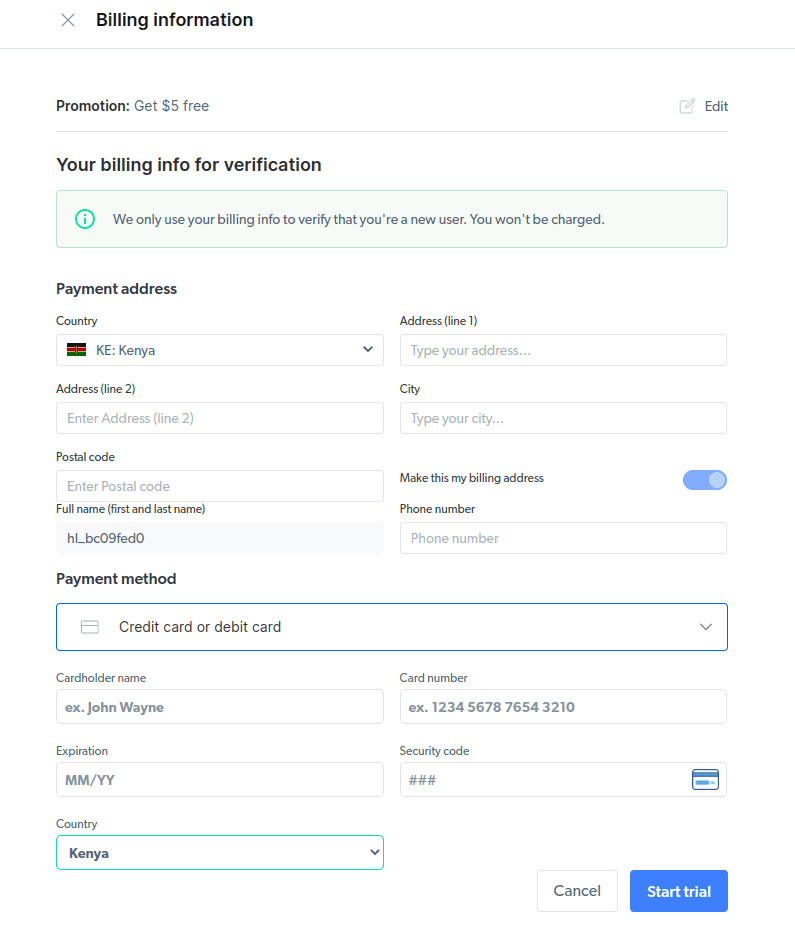
- Creează un nou proxy. După salvarea detaliilor de facturare, poți crea un nou proxy. Apasă pictograma „adăugați” și alege Browserul Scraping ca „Tipul de proxy”. Apasă „Adăugați proxy” și continuă cu următorul pas.
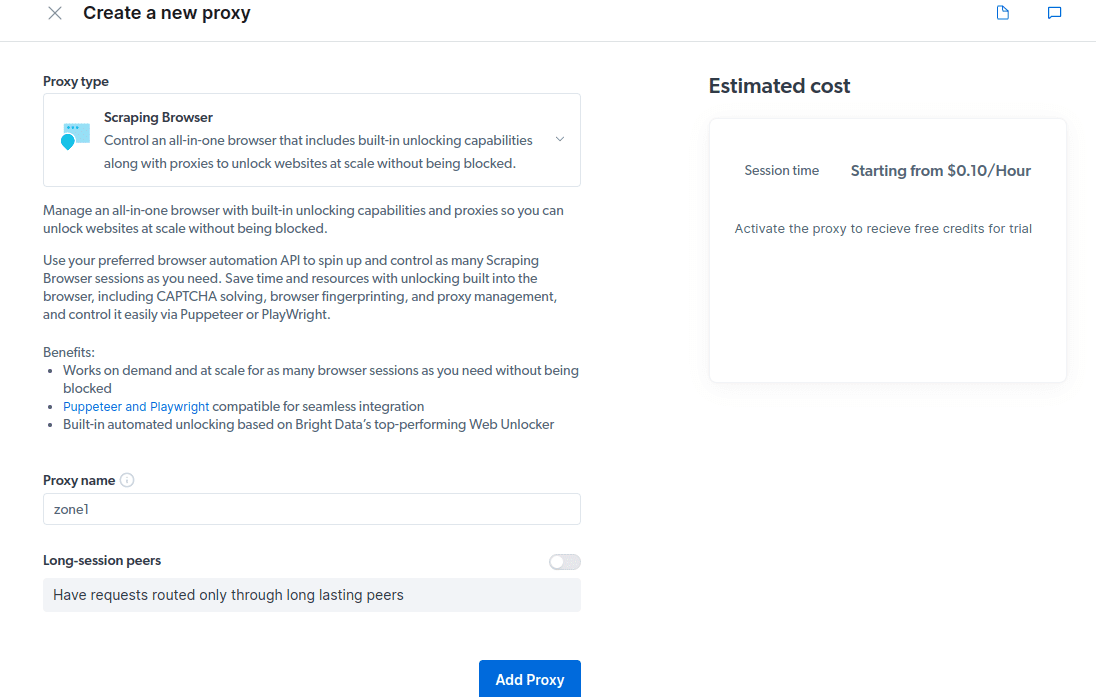
- Creează o nouă „zonă”. Va apărea o fereastră pop-up ce te va întreba dacă dorești crearea unei noi zone; apasă „Da” și continuă.
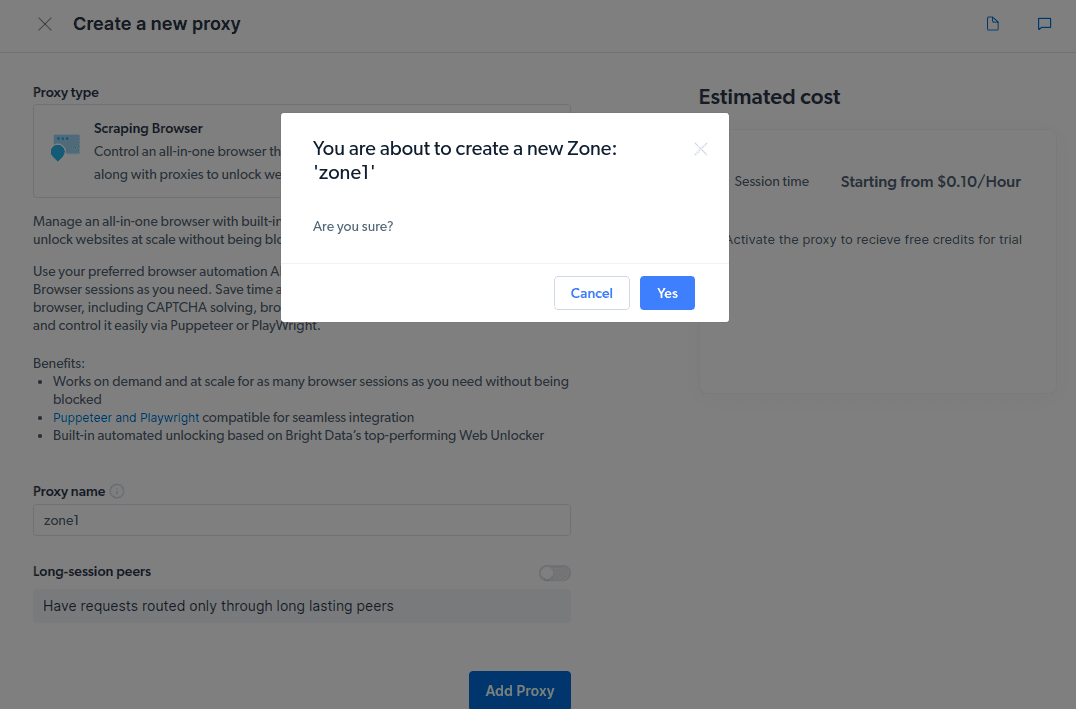
- Apasă pe „Verificați exemple de cod și integrare”. Vei obține exemple de integrare proxy pe care le poți utiliza pentru a extrage date de pe site-ul țintă. Poți utiliza Node.js sau Python pentru a extrage date de pe site-ul vizat.
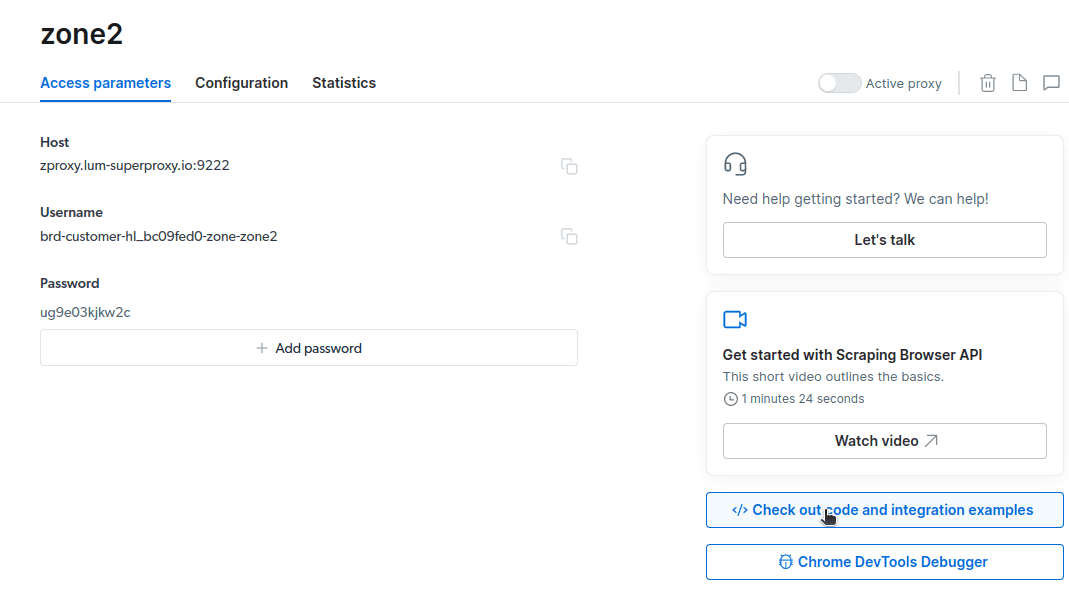
Acum ai tot ce îți trebuie pentru a extrage date de pe un site web. Vom folosi site-ul nostru, tipstrick.ro.com, pentru a demonstra cum funcționează Browserul Scraping. Vom folosi node.js pentru această demonstrație. Poți urmări pașii dacă ai node.js instalat.
Urmează acești pași:
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="USERNAME:PASSWORD";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://example.com');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
Voi modifica codul de la linia 10 astfel:
await page.goto(‘https://tipstrick.ro.com/authors/‘);
Codul meu final va arăta așa:
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://tipstrick.ro.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
node script.js
Vei obține un rezultat similar în terminal.
Cum se exportă datele
Există mai multe metode de export al datelor, în funcție de cum dorești să le utilizezi. În acest exemplu, vom exporta datele într-un fișier HTML, modificând scriptul pentru a crea un fișier nou, numit data.html, în loc să afișăm rezultatul în consolă.
Poți modifica codul după cum urmează:
const puppeteer = require('puppeteer-core');
const fs = require('fs');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run() {
let browser;
try {
browser = await puppeteer.connect({ browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222` });
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2 * 60 * 1000);
await page.goto('https://tipstrick.ro.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
// Write HTML content to a file
fs.writeFileSync('data.html', html);
console.log('Data export complete.');
} catch (e) {
console.error('run failed', e);
} finally {
await browser?.close();
}
}
if (require.main == module) {
run();
}
Acum poți rula codul folosind comanda:
node script.js
După cum poți vedea în captura de ecran de mai jos, terminalul afișează mesajul „export de date finalizat”.
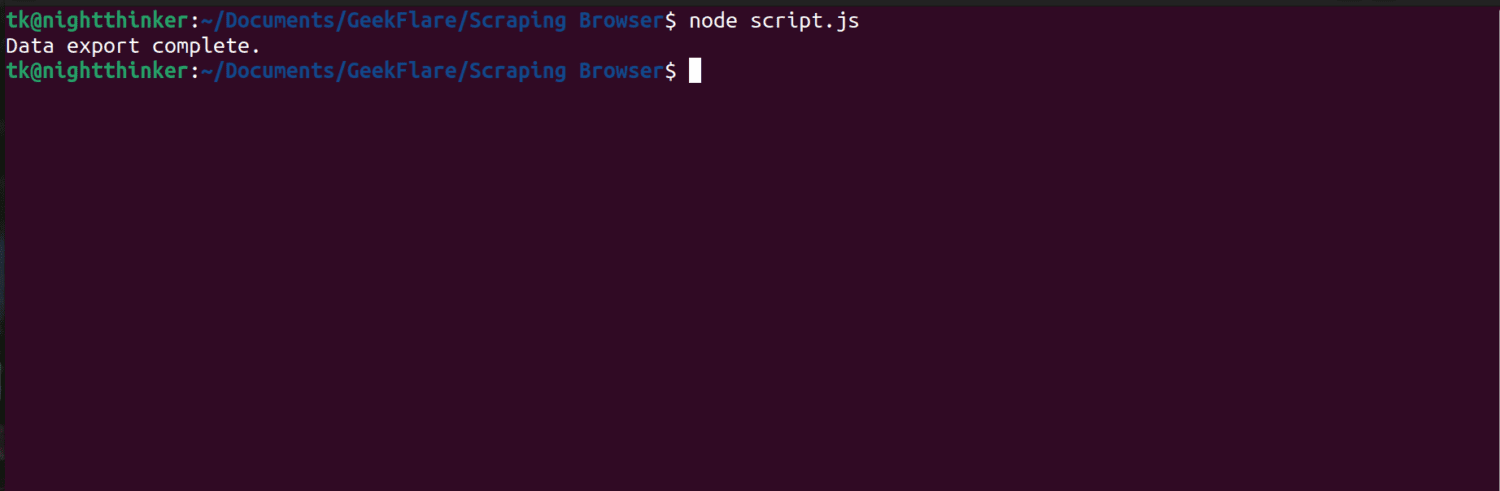
Dacă verifici folderul proiectului, vei observa un fișier numit data.html, care conține mii de linii de cod.
Abia am zgâriat suprafața modului în care datele pot fi extrase folosind browserul Scraping. Se pot extrage doar anumite elemente, ca de exemplu, doar numele autorilor și descrierile acestora.
Dacă dorești să utilizezi Browserul Scraping, identifică setul de date pe care vrei să îl extragi și modifică codul corespunzător. Poți extrage text, imagini, video, metadate și link-uri, în funcție de site-ul țintă și de structura fișierului HTML.
Întrebări frecvente
Este legală extragerea datelor și web scraping?
Web scraping este un subiect controversat, unii considerându-l imoral, în timp ce alții îl consideră acceptabil. Legalitatea web scraping-ului depinde de natura conținutului extras și de politicile site-ului vizat. În general, extragerea datelor cu caracter personal, precum adrese și detalii financiare, este considerată ilegală. Înainte de a extrage date, verifică politicile site-ului vizat. Asigură-te întotdeauna că nu extragi date care nu sunt disponibile public.
Browserul Scraping este un instrument gratuit?
Nu. Browserul Scraping este un serviciu contra cost. Dacă te înregistrezi pentru perioada de încercare gratuită, instrumentul îți oferă un credit de 5 USD. Pachetele plătite încep de la 15 USD/GB + 0,1 USD/h. Poți alege opțiunea Pay As You Go, care începe de la 20 USD/GB + 0,1 USD/h.
Care este diferența dintre browserele Scraping și browserele fără interfață grafică?
Browserul Scraping are o interfață grafică (GUI). Browserele fără interfață grafică (headless) nu au GUI. Browserele headless, cum ar fi Selenium, sunt utilizate pentru a automatiza procesul de web scraping, dar pot fi limitate de necesitatea de a gestiona CAPTCHA-uri și detectarea roboților.
Concluzie
După cum ai văzut, Browserul Scraping simplifică procesul de extragere a datelor de pe paginile web. Este mai ușor de utilizat în comparație cu alte instrumente, precum Selenium. Chiar și persoanele fără cunoștințe de programare pot utiliza acest browser, datorită interfeței intuitive și documentației detaliate. Instrumentul dispune de capacități de deblocare a site-urilor, care nu sunt disponibile în alte instrumente, făcându-l o soluție eficientă pentru automatizarea procesului de extragere de date.
Poți explora și cum să previi plugin-urile ChatGPT să extragă conținut de pe site-ul tău.