

Conducta de agregare este modalitatea recomandată de a rula interogări complexe în MongoDB. Dacă ați folosit MapReduce de la MongoDB, mai bine treceți la conducta de agregare pentru calcule mai eficiente.
Cuprins
Ce este agregarea în MongoDB și cum funcționează?
Conducta de agregare este un proces în mai multe etape pentru rularea de interogări avansate în MongoDB. Procesează datele prin diferite etape numite conductă. Puteți utiliza rezultatele generate de la un nivel ca șablon de operație în altul.
De exemplu, puteți trece rezultatul unei operațiuni de potrivire într-o altă etapă pentru sortare în acea ordine până când obțineți rezultatul dorit.
Fiecare etapă a unei conducte de agregare prezintă un operator MongoDB și generează unul sau mai multe documente transformate. În funcție de interogarea dvs., un nivel poate apărea de mai multe ori în conductă. De exemplu, ar putea fi necesar să utilizați etapele operatorului $count sau $sort de mai multe ori în conducta de agregare.
Etapele conductei de agregare
Conducta de agregare trece datele prin mai multe etape într-o singură interogare. Există mai multe etape și puteți găsi detaliile acestora în Documentația MongoDB.
Să definim mai jos câteva dintre cele mai frecvent utilizate.
Etapa $match
Această etapă vă ajută să definiți condiții specifice de filtrare înainte de a începe celelalte etape de agregare. Îl puteți folosi pentru a selecta datele potrivite pe care doriți să le includeți în conducta de agregare.
Faza de grupe $
Etapa de grupă separă datele în diferite grupuri pe baza unor criterii specifice, folosind perechi cheie-valoare. Fiecare grup reprezintă o cheie în documentul de ieșire.
De exemplu, luați în considerare următoarele date mostre de vânzări:
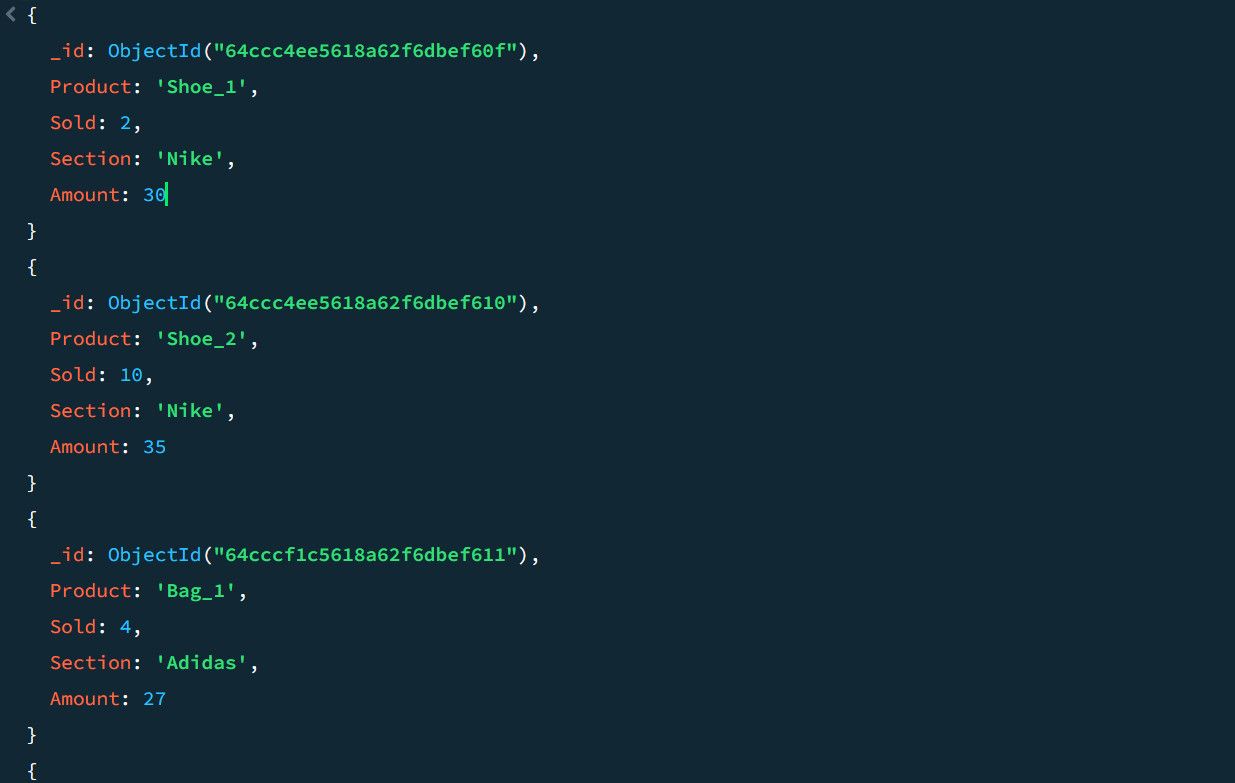
Folosind canalul de agregare, puteți calcula numărul total de vânzări și vânzările de top pentru fiecare secțiune de produs:
{
$group: {
_id: $Section,
total_sales_count: {$sum : $Sold},
top_sales: {$max: $Amount},
}
}
Perechea _id: $Section grupează documentul de ieșire pe baza secțiunilor. Prin specificarea câmpurilor top_sales_count și top_sales, MongoDB creează chei noi pe baza operațiunii definite de agregator; acesta poate fi $sum, $min, $max sau $avg.
Etapa $skip
Puteți utiliza etapa $skip pentru a omite un număr specificat de documente în ieșire. De obicei vine după faza grupelor. De exemplu, dacă vă așteptați la două documente de ieșire, dar omiteți unul, agregarea va scoate doar al doilea document.
Pentru a adăuga o etapă de ignorare, inserați operația $skip în conducta de agregare:
...,
{
$skip: 1
},
Etapa $sort
Etapa de sortare vă permite să aranjați datele în ordine descrescătoare sau crescătoare. De exemplu, putem sorta în continuare datele din exemplul de interogare anterior în ordine descrescătoare pentru a determina care secțiune are cele mai mari vânzări.
Adăugați operatorul $sort la interogarea anterioară:
...,
{
$sort: {top_sales: -1}
},
Etapa $limit
Operațiunea de limită ajută la reducerea numărului de documente de ieșire pe care doriți să le afișeze conducta de agregare. De exemplu, utilizați operatorul $limit pentru a obține secțiunea cu cele mai mari vânzări returnate de etapa anterioară:
...,
{
$sort: {top_sales: -1}
},{"$limit": 1}
Cele de mai sus returnează doar primul document; aceasta este secțiunea cu cele mai mari vânzări, așa cum apare în partea de sus a rezultatelor sortate.
Etapa $proiectului
Etapa $project vă permite să modelați documentul de ieșire după cum doriți. Folosind operatorul $project, puteți specifica ce câmp să includeți în rezultat și personalizați numele cheii acestuia.
De exemplu, un exemplu de ieșire fără etapa $project arată astfel:
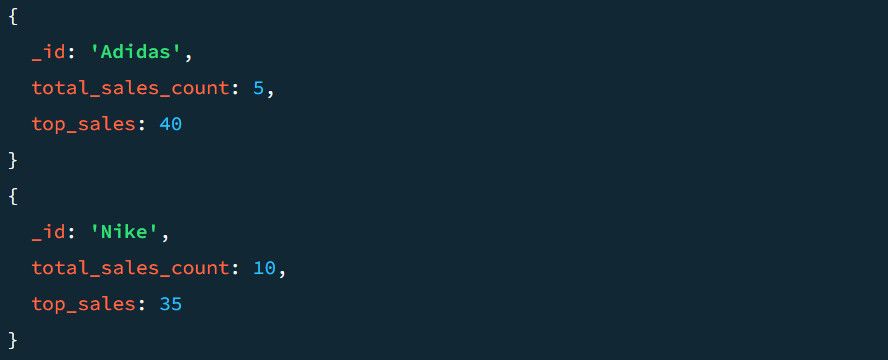
Să vedem cum arată cu etapa $project. Pentru a adăuga $project la conductă:
...,{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",}
}
Deoarece am grupat anterior datele pe baza secțiunilor de produse, cele de mai sus includ fiecare secțiune de produs în documentul de ieșire. De asemenea, se asigură că numărul total de vânzări și vânzările de top apar în rezultat ca TotalSold și TopSale.
Ieșirea finală este mult mai curată în comparație cu cea anterioară:

Etapa $unwind
Etapa $unwind descompune o matrice dintr-un document în documente individuale. Luați următoarele date Comenzi, de exemplu:
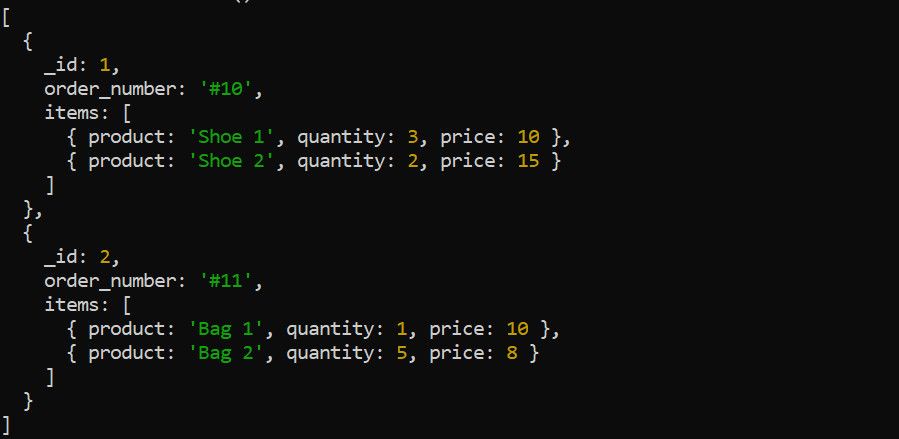
Utilizați etapa $unwind pentru a deconstrui matricea de articole înainte de a aplica alte etape de agregare. De exemplu, derularea matricei de articole are sens dacă doriți să calculați venitul total pentru fiecare produs:
db.Orders.aggregate(
[
{
"$unwind": "$items"
},
{
"$group": {
"_id": "$items.product",
"total_revenue": { "$sum": { "$multiply": ["$items.quantity", "$items.price"] } }
}
},
{
"$sort": { "total_revenue": -1 }
},{
"$project": {
"_id": 0,
"Product": "$_id",
"TotalRevenue": "$total_revenue",}
}
])
Iată rezultatul interogării de agregare de mai sus:

Cum se creează o conductă de agregare în MongoDB
În timp ce pipeline de agregare include mai multe operațiuni, etapele prezentate anterior vă oferă o idee despre cum să le aplicați în pipeline, inclusiv interogarea de bază pentru fiecare.
Folosind eșantionul anterior de date de vânzări, să avem câteva dintre etapele discutate mai sus într-o singură bucată pentru o vedere mai largă a conductei de agregare:
db.sales.aggregate([{
"$match": {
"Sold": { "$gte": 5 }
}
},{
"$group": {
"_id": "$Section",
"total_sales_count": { "$sum": "$Sold" },
"top_sales": { "$max": "$Amount" },
}},
{
"$sort": { "top_sales": -1 }
},{"$skip": 0},
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",}
}
])
Rezultatul final arată ca ceva pe care l-ați văzut anterior:
Conducta de agregare vs. MapReduce
Până la deprecierea sa începând de la MongoDB 5.0, modalitatea convențională de a agrega date în MongoDB a fost prin MapReduce. Deși MapReduce are aplicații mai largi dincolo de MongoDB, este mai puțin eficient decât conducta de agregare, necesitând scripturi terțe pentru a scrie harta și a reduce funcțiile separat.
Pe de altă parte, conducta de agregare este specifică numai pentru MongoDB. Dar oferă o modalitate mai curată și mai eficientă de a executa interogări complexe. Pe lângă simplitate și scalabilitate a interogărilor, etapele pipeline prezentate fac rezultatul mai personalizabil.
Există mult mai multe diferențe între conducta de agregare și MapReduce. Le veți vedea pe măsură ce treceți de la MapReduce la conducta de agregare.
Faceți interogări de date mari eficiente în MongoDB
Interogarea dvs. trebuie să fie cât mai eficientă dacă doriți să efectuați calcule aprofundate pe date complexe în MongoDB. Conducta de agregare este ideală pentru interogări avansate. În loc să manipulați datele în operațiuni separate, ceea ce reduce adesea performanța, agregarea vă permite să le împachetați pe toate într-o singură conductă performantă și să le executați o dată.
Deși canalul de agregare este mai eficient decât MapReduce, puteți face agregarea mai rapidă și mai eficientă prin indexarea datelor. Acest lucru limitează cantitatea de date pe care MongoDB trebuie să le scaneze în timpul fiecărei etape de agregare.