
Fiecare serviciu AWS își înregistrează procesarea în fișiere organizate în grupuri de jurnal CloudWatch. Grupurile de jurnal sunt de obicei denumite după serviciul în sine pentru o identificare mai ușoară. Mesajele de sistem ale serviciului sau informațiile comune de stare sunt scrise implicit în acele fișiere jurnal.
Cu toate acestea, puteți adăuga informații despre mesajele de jurnal personalizate peste cele implicite. Dacă astfel de jurnale sunt create cu înțelepciune, ele pot servi pentru a crea tablouri de bord utile CloudWatch.
Cu metrici și informații structurate care oferă detalii suplimentare despre procesarea locurilor de muncă. Nu numai că pot conține widget-uri standard cu informații de sistem despre serviciu. Puteți extinde acest lucru cu propriul dvs. conținut, agregat în widget-ul sau în metrica dvs. personalizată.
Cuprins
Interogați fișierele jurnal
Sursa: aws.amazon.com
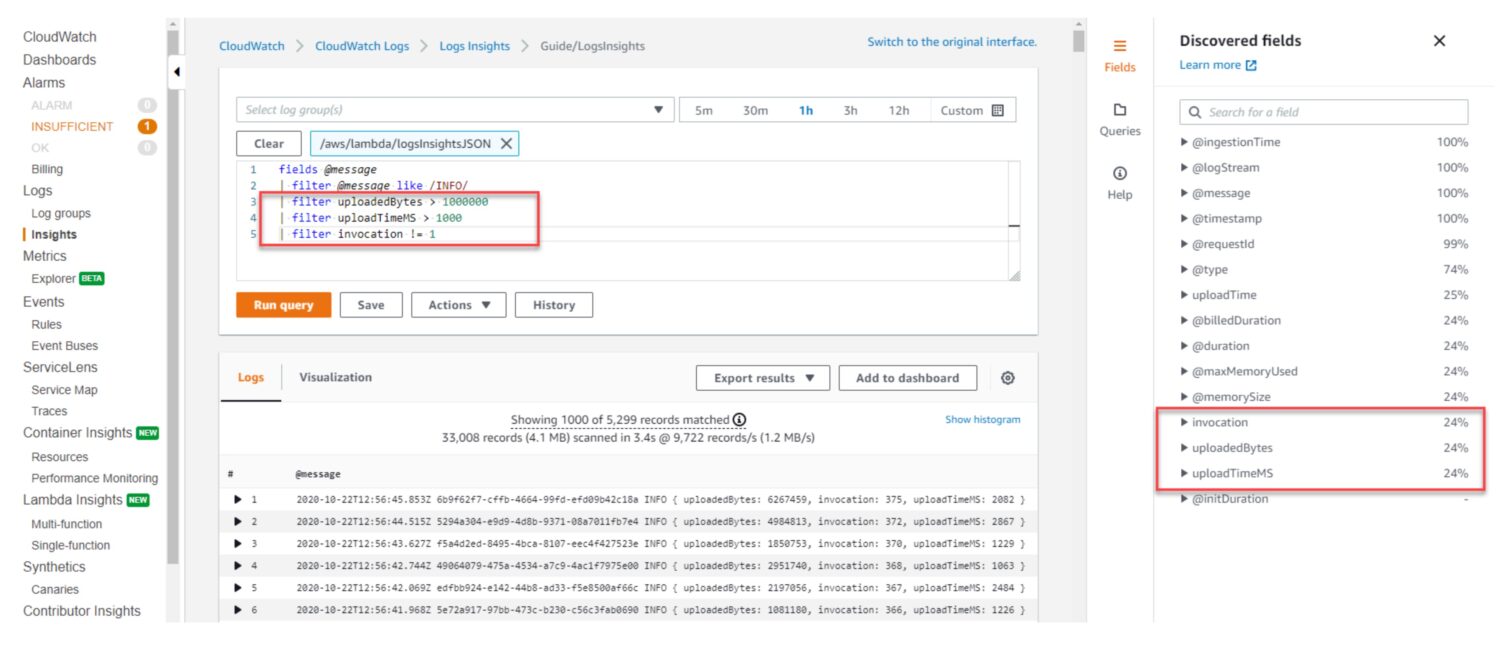
AWS CloudWatch Log Insights vă permite să căutați și să analizați datele din jurnal din resursele dvs. AWS în timp real. Îl puteți privi ca pe o vizualizare a bazei de date. Definiți interogarea pe tabloul de bord, iar tabloul de bord o va selecta atunci când îl vizitați sau în fereastra de timp specificată în trecut, așa cum o definiți în vizualizarea tabloului de bord.
Folosește un limbaj de interogare numit CloudWatch Logs Insights pentru a căuta și analiza datele din jurnal. Limbajul de interogare se bazează pe un subset al limbajului SQL. Vă permite să căutați și să filtrați datele din jurnal. Puteți căuta anumite evenimente din jurnal, text personalizat sau cuvinte cheie și puteți filtra datele din jurnal pe baza anumitor câmpuri. Și cel mai important, agregați datele de jurnal în unul sau mai multe fișiere de jurnal pentru a genera valori și vizualizări rezumate.
Când executați o interogare, CloudWatch Log Insights caută prin datele de jurnal din grupul de jurnal. Apoi returnează textele rezultate din fișierele care corespund criteriilor dvs. de interogare.
Exemplu de interogare a fișierului jurnal
Să aruncăm o privire la câteva întrebări de bază pentru a înțelege conceptul.
Fiecare serviciu, implicit, înregistrează câteva erori cruciale de serviciu. Chiar dacă nu creați un jurnal personalizat dedicat pentru astfel de evenimente de eroare. Apoi, cu o simplă interogare, puteți număra numărul de erori din jurnalele aplicației dvs. în ultima oră:
fields @timestamp, @message | filter @message like /ERROR/ | stats count() by bin(1h)
Sau iată cum puteți monitoriza timpul mediu de răspuns al API-ului dvs. în ultima zi:
fields @timestamp, @message | filter @message like /API response time/ | stats avg(response_time) by bin(1d)
Deoarece, în mod implicit, utilizarea CPU este informațiile înregistrate de serviciu în CloudWatch, puteți aduna și acest tip de măsură:
fields @timestamp, @message | filter @message like /CPUUtilization/ | stats avg(value) by bin(1h)
Aceste interogări pot fi personalizate pentru a se potrivi cu cazul dvs. de utilizare specific și pot fi folosite pentru a crea valori și vizualizări personalizate în tablourile de bord CloudWatch. Modul de a face acest lucru este să plasați widget-ul pe tabloul de bord și să plasați codul în interiorul widget-ului pentru a defini ce să selectați.
Iată câteva dintre widget-urile care pot fi folosite în tablourile de bord CloudWatch și completate cu conținutul din Log Insights:
- Widgeturi text – Afișează informații bazate pe text, cum ar fi rezultatul unei interogări CloudWatch Insights.
- Widgeturi de interogare în jurnal – Afișează rezultatele unei interogări de jurnal CloudWatch Insights, cum ar fi numărul de erori din jurnalele aplicației.
Cum să creați informații utile de jurnal pentru tabloul de bord
 Sursa: aws.amazon.com
Sursa: aws.amazon.com
Pentru a utiliza în mod eficient interogările CloudWatch Insights în tablourile de bord CloudWatch, este bine să urmați câteva bune practici atunci când creați jurnalele CloudWatch pentru fiecare dintre serviciile pe care le utilizați în sistemul dvs. Iată câteva sfaturi:
#1. Utilizați înregistrarea structurată
Trebuie să respectați un format de înregistrare care utilizează o schemă predefinită pentru a înregistra datele într-un format structurat. Acest lucru facilitează căutarea și filtrarea datelor din jurnal folosind interogări CloudWatch Insights.
Acest lucru înseamnă practic standardizarea jurnalelor dvs. în diferite servicii din platforma dvs. de arhitectură. Definirea acestuia în standardele de dezvoltare ajută enorm.
De exemplu, puteți defini că fiecare problemă legată de un anumit tabel al bazei de date va fi înregistrată cu un mesaj de pornire precum: „[TABLE_NAME] Avertisment / Eroare:
Sau puteți separa joburile de date complete de joburile de date delta prin prefixe precum „[FULL/DELTA]” să selecteze doar mesaje legate de procesele de date concrete.
Puteți defini că, în timpul procesării datelor dintr-un anumit sistem sursă, numele sistemului va fi un prefix al fiecărei intrări de jurnal aferente. După aceea, este mult mai ușor să filtrați astfel de mesaje din fișierele jurnal și să construiți valori asupra lor.
 Sursa: aws.amazon.com
Sursa: aws.amazon.com
#2. Utilizați formate de jurnal consistente
Utilizați formate de jurnal coerente în toate resursele dvs. AWS pentru a facilita căutarea și filtrarea datelor din jurnal folosind interogări CloudWatch Insights.
Acest lucru este destul de legat de punctul anterior, dar adevărul este că, cu cât formatul de jurnal este mai standardizat, cu atât este mai ușor să utilizați datele de jurnal. Dezvoltatorii se pot baza apoi pe acest format și îl pot folosi chiar și intuitiv.
Faptul crud este că majoritatea proiectelor nu se deranjează cu niciun standard în ceea ce privește exploatarea forestieră. În plus, multe proiecte nu creează nici măcar jurnalele personalizate. Este șocant, dar și atât de comun în același timp.
Nici nu pot spune de câte ori m-am trezit întrebându-mă cum pot locui oamenii aici fără nicio abordare a erorilor. Și dacă cineva a făcut un efort să facă un fel de tratare a erorilor ca excepție, a făcut-o greșit.
Deci, un format de jurnal consistent este un avantaj puternic. Nu mulți le au.
#3. Includeți metadate relevante
Includeți metadate în datele de jurnal, cum ar fi marcajele de timp, ID-urile resurselor și codurile de eroare, pentru a facilita căutarea și filtrarea datelor din jurnal folosind interogările CloudWatch Insights.
#4. Activați Rotația jurnalului
Activați rotația jurnalului pentru a preveni ca datele dvs. de jurnal să devină prea mari și pentru a facilita căutarea și filtrarea datelor din jurnal folosind interogările CloudWatch Insights.
A nu avea date de jurnal este un lucru, dar a avea prea multe dintre ele fără structură este la fel de disperat. Dacă nu vă puteți folosi datele, este ca și cum nu ați avea deloc date.
#5. Utilizați agenții CloudWatch Logs
Dacă nu vă puteți ajuta și refuzați să vă construiți sistemul de jurnal personalizat, atunci cel puțin utilizați agenți CloudWatch Logs. Ei trimit automat date de jurnal din resursele dvs. AWS către CloudWatch Logs. Acest lucru facilitează căutarea și filtrarea datelor din jurnal folosind interogări CloudWatch Insights.
Exemple de interogări cu statistici mai complexe
Interogarea CloudWatch Insights poate fi mai complicată decât declarația pe două rânduri.
fields @timestamp, @message | filter @message like /ERROR/ | filter @message not like /404/ | parse @message /.*[(?<timestamp>[^]]+)].*"(?<method>[^s]+)s+(?<path>[^s]+).*" (?<status>d+) (?<response_time>d+)/ | stats avg(response_time) as avg_response_time, count() as count by bin(1h), method, path, status | sort count desc | limit 20
Această interogare face următoarele:
Această interogare identifică cele mai frecvente erori din aplicația dvs. și urmărește timpul mediu de răspuns pentru fiecare combinație de metodă HTTP, cale și cod de stare. Puteți utiliza rezultatele pentru a crea valori și vizualizări personalizate în tablourile de bord CloudWatch pentru a monitoriza performanța aplicației dvs. web și a depana problemele.
Un alt exemplu de interogare a mesajelor serviciului Amazon S3:
fields @timestamp, @message | filter @message like /REST.API.REQUEST/ | parse @message /.*"(?<method>[^s]+)s+(?<path>[^s]+).*" (?<status>d+) (?<response_time>d+)/ | stats avg(response_time) as avg_response_time, count() as count by bin(1h), method, path, status | sort count desc | limit 20
- Interogarea selectează evenimentele din jurnal care conțin șirul „REST.API.REQUEST”.
- Apoi analizează mesajul de jurnal pentru a extrage metoda HTTP, calea, codul de stare și timpul de răspuns.
- Acesta calculează timpul mediu de răspuns și numărul de evenimente din jurnal pentru fiecare combinație de metodă HTTP, cale și cod de stare și sortează rezultatele după număr în ordine descrescătoare.
- Limitează rezultatul la primele 20 de rezultate.
Puteți utiliza rezultatul acestei interogări pentru a crea un grafic cu linii într-un tablou de bord CloudWatch care arată timpul mediu de răspuns pentru fiecare combinație de metodă HTTP, cale și cod de stare de-a lungul timpului.
Construirea tabloului de bord
Pentru a completa valorile și vizualizările din tablourile de bord CloudWatch din rezultatul interogărilor din jurnalul CloudWatch Insights, puteți naviga la consola CloudWatch și urmați vrăjitorul Dashboard pentru a vă crea conținut.
După aceea, așa arată codul unui tablou de bord CloudWatch și conține valori completate de datele de interogare CloudWatch Insights:
{
"widgets": [
{
"type": "metric",
"x": 0,
"y": 0,
"width": 12,
"height": 6,
"properties": {
"metrics": [
[
"AWS/EC2",
"CPUUtilization",
"InstanceId",
"i-0123456789abcdef0",
{
"label": "CPU Utilization",
"stat": "Average",
"period": 300
}
]
],
"view": "timeSeries",
"stacked": false,
"region": "us-east-1",
"title": "EC2 CPU Utilization"
}
},
{
"type": "log",
"x": 0,
"y": 6,
"width": 12,
"height": 6,
"properties": {
"query": "fields @timestamp, @message
| filter @message like /ERROR/
| stats count() by bin(1h)
",
"region": "us-east-1",
"title": "Application Errors"
}
}
]
}
Acest tablou de bord CloudWatch conține două widget-uri:
Este un fișier în format JSON cu o definiție a tabloului de bord și a valorilor în interior. Conține (ca proprietate) și interogarea insight în sine.
Puteți lua codul și îl puteți implementa în orice cont AWS de care aveți nevoie. Presupunând că serviciile și mesajele de jurnal sunt consecvente în toate conturile și etapele dvs. AWS, tabloul de bord va funcționa pe toate conturile fără a fi nevoie să schimbați codul sursă al tabloului de bord.
Cuvinte finale
Construirea unei structuri solide de logare a fost întotdeauna o investiție bună în viitorul fiabilității sistemului. Acum poate servi unui scop și mai mare. Puteți avea tablouri de bord utile cu valori și vizualizări doar ca efect secundar al acestui lucru.
Având necesitatea de a fi făcut o singură dată, cu doar puțină muncă suplimentară, echipa de dezvoltare, echipa de testare și utilizatorii de producție pot beneficia cu toții de aceeași soluție.
Apoi, consultați cele mai bune instrumente de monitorizare AWS.