
Web scraping este o tehnică puternică pentru a extrage informații de pe site-uri web și a le analiza automat. Deși puteți face acest lucru manual, poate fi o sarcină obositoare și consumatoare de timp. Instrumentele web scraping fac procesul mai rapid și mai eficient, costând totodată mai puțin.
Interesant este că Google Sheets are potențialul de a fi instrumentul tău unic de eliminare a site-ului web, datorită funcției IMPORTXML. Cu IMPORTXML, puteți extrage cu ușurință datele din paginile web și le puteți utiliza pentru analiză, raportare sau orice alte sarcini bazate pe date.
Cuprins
Funcția IMPORTXML din Foi de calcul Google
Foi de calcul Google oferă o funcție încorporată numită IMPORTXML, care vă permite să importați date din formate web precum XML, HTML, RSS și CSV. Această funcție poate schimba jocul dacă doriți să colectați date de pe site-uri web fără a recurge la codare complexă.
Iată sintaxa de bază a IMPORTXML:
=IMPORTXML(url, xpath_query)
- url: adresa URL a paginii web din care doriți să extrageți datele.
- xpath_query: Interogarea XPath care definește datele pe care doriți să le extrageți.
XPath (XML Path Language) este un limbaj folosit pentru a naviga documente XML, inclusiv HTML, permițându-vă să specificați locația datelor într-o structură HTML. Înțelegerea interogărilor XPath este esențială pentru utilizarea corectă a IMPORTXML.
Înțelegerea XPath
XPath oferă diverse funcții și expresii pentru a naviga și filtra datele într-un document HTML. Un ghid cuprinzător pentru XML și XPath depășește domeniul de aplicare al acestui articol, așa că ne vom mulțumi cu câteva concepte XPath esențiale:
- Selectarea elementelor: Puteți selecta elemente folosind / și // pentru a indica trasee. De exemplu, /html/body/div selectează toate elementele div din corpul unui document.
- Selectarea atributelor: Pentru a selecta atribute, puteți folosi @. De exemplu, //@href selectează toate atributele href de pe pagină.
- Filtre de predicate: puteți filtra elemente folosind predicate incluse între paranteze drepte ([ ]). De exemplu, /div[@class=”container”] selectează toate elementele div cu containerul de clasă.
- Funcții: XPath oferă diverse funcții, cum ar fi contains(), starts-with() și text() pentru a efectua acțiuni specifice, cum ar fi verificarea conținutului textului sau a valorilor atributelor.
Până acum, cunoașteți sintaxa IMPORTXML, știți adresa URL a site-ului și știți ce element doriți să extrageți. Dar cum obții XPath-ul elementului?
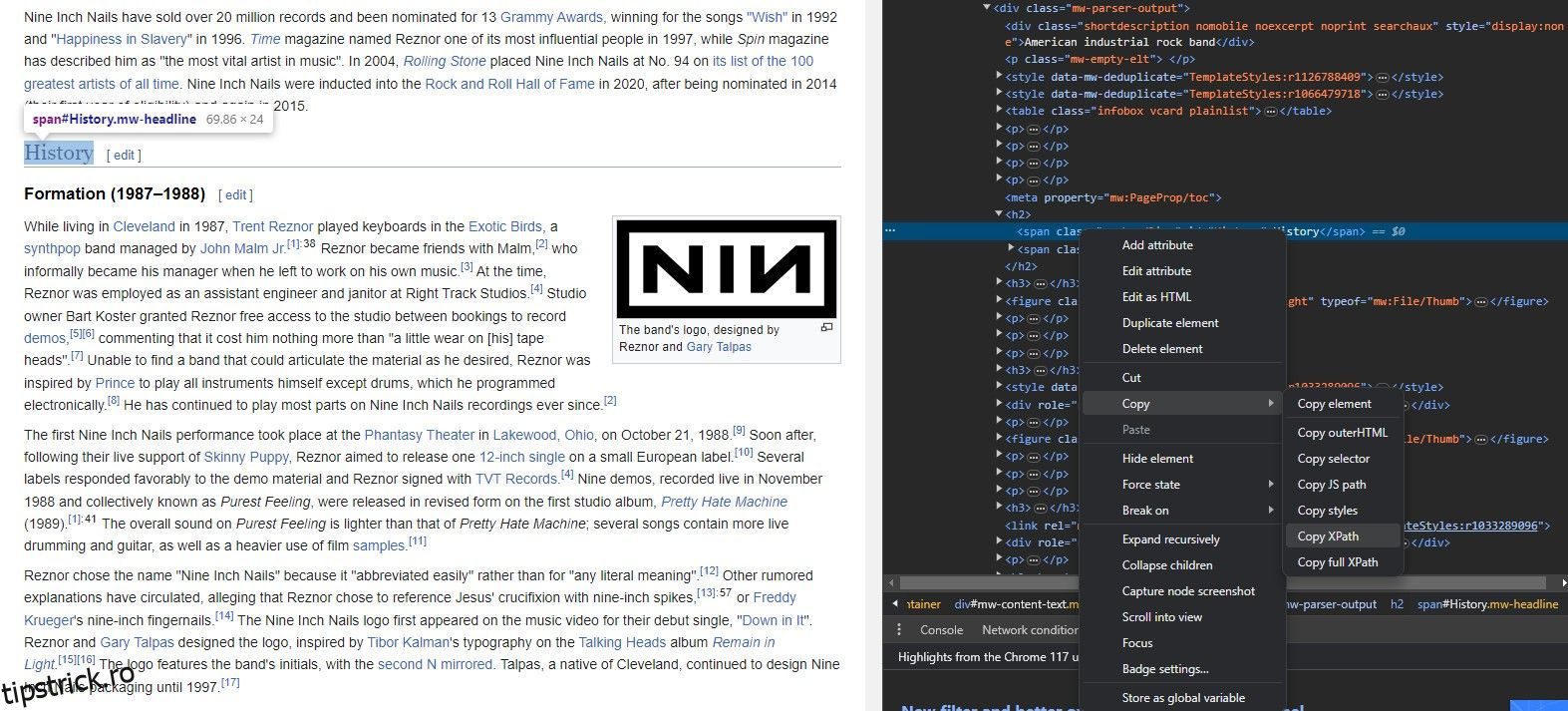
Nu trebuie să cunoașteți pe de rost structura unui site web pentru a-i extrage datele cu IMPORTXML. De fapt, fiecare browser are un instrument ingenios care vă permite să copiați instantaneu XPath-ul oricărui element.
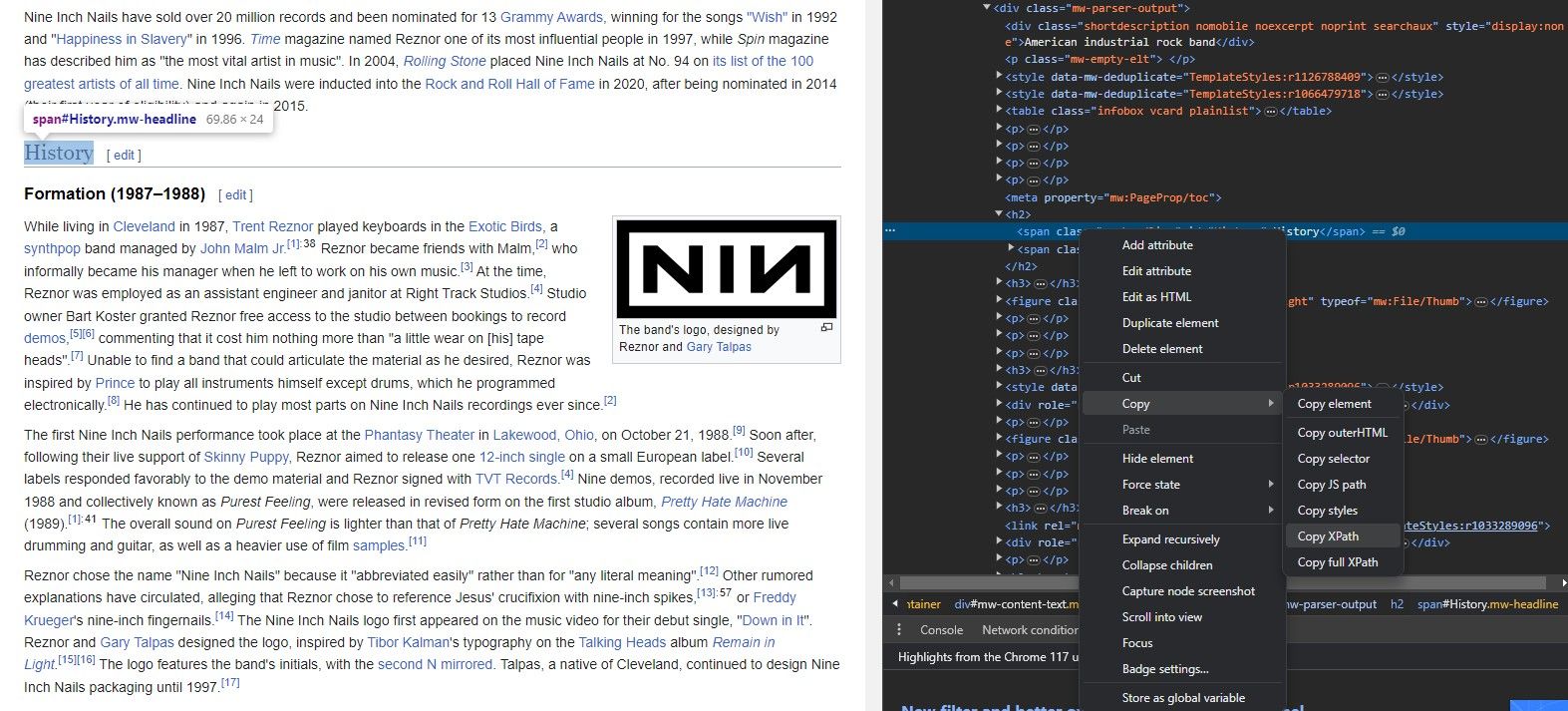
Instrumentul Inspectare element vă permite să extrageți XPath-ul din elementele site-ului web. Iată cum:
Acum că aveți tot ce aveți nevoie, este timpul să vedeți IMPORTXML în acțiune și să răzuiți câteva link-uri.
Cum să răzuiți linkurile de pe un site web cu IMPORTXML
Puteți folosi IMPORTXML pentru a elimina tot felul de date de pe site-uri web. Aceasta include link-uri, videoclipuri, imagini și aproape orice element al site-ului web. Legăturile sunt unul dintre elementele cele mai proeminente în analiza web și puteți afla multe despre un site web doar analizând paginile către care face legătura.
IMPORTXML vă permite să răzuiți rapid link-urile în Foi de calcul Google și apoi să le analizați în continuare folosind diferitele funcții oferite de Foi de calcul Google.
1. Scraping All Links
Pentru a elimina toate linkurile dintr-o pagină web, puteți utiliza următoarea formulă:
=IMPORTXML(url, "//a/@href")
Această interogare XPath selectează toate atributele href ale unui element, extragând efectiv toate linkurile de pe pagină.
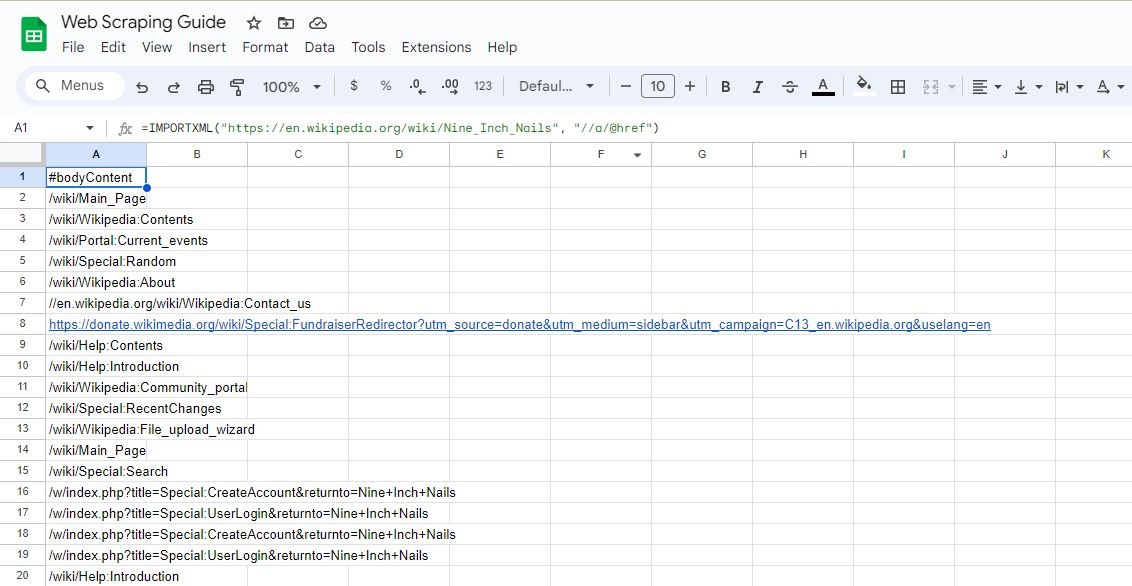
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a/@href")
Formula de mai sus elimină toate linkurile dintr-un articol Wikipedia.
Este o idee bună să introduceți adresa URL a paginii web într-o celulă separată și apoi să faceți referire la acea celulă. Acest lucru va împiedica formula ta să devină prea lungă și greoaie. Puteți face același lucru cu interogarea XPath.
2. Scraping All Link Textes
Pentru a extrage textul linkurilor împreună cu adresele URL ale acestora, puteți utiliza:
=IMPORTXML(url, "//a")
Această interogare selectează toate elementele și puteți extrage textul linkului și adresele URL din rezultate.
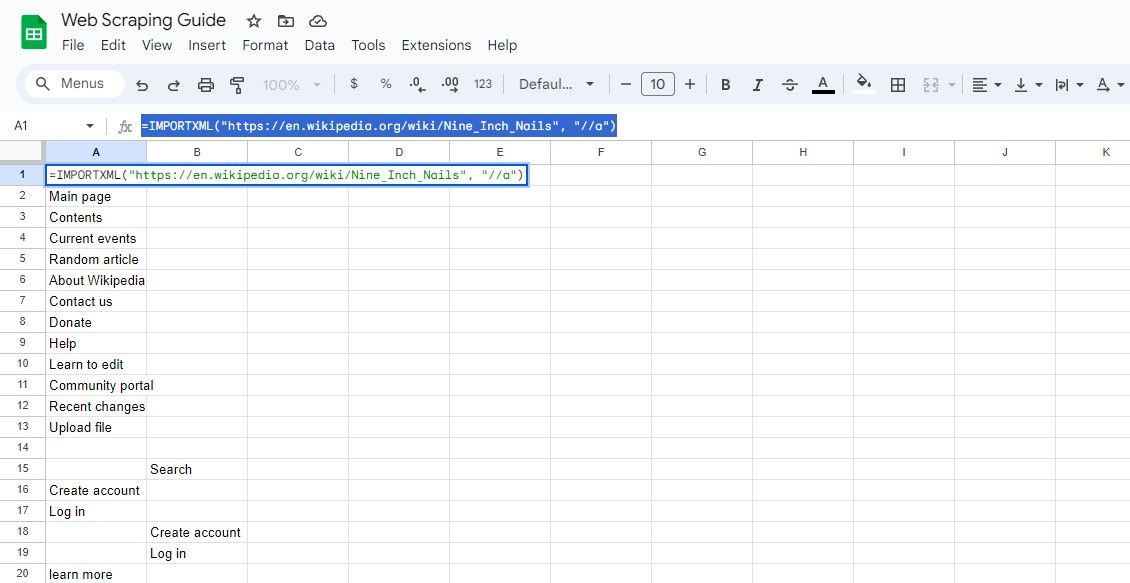
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a")
Formula de mai sus primește textele link-urilor în același articol Wikipedia.
Cum să răzuiți link-uri specifice de pe un site web cu IMPORTXML
Uneori, poate fi necesar să răzuiți anumite link-uri pe baza unor criterii. De exemplu, ați putea fi interesat să extrageți link-uri care conțin un anumit cuvânt cheie sau link-uri care se află într-o anumită secțiune a paginii.
Cu cunoștințe adecvate despre XPath, puteți identifica orice element pe care îl căutați.
1. Scraping Link-uri care conțin un cuvânt cheie
Pentru a răzui link-urile care conțin un anumit cuvânt cheie, puteți utiliza funcția contains() XPath:
=IMPORTXML(url, "//a[contains(@href, 'keyword')]/@href")
Această interogare selectează atributele href ale elementelor în care href conține cuvântul cheie specificat.
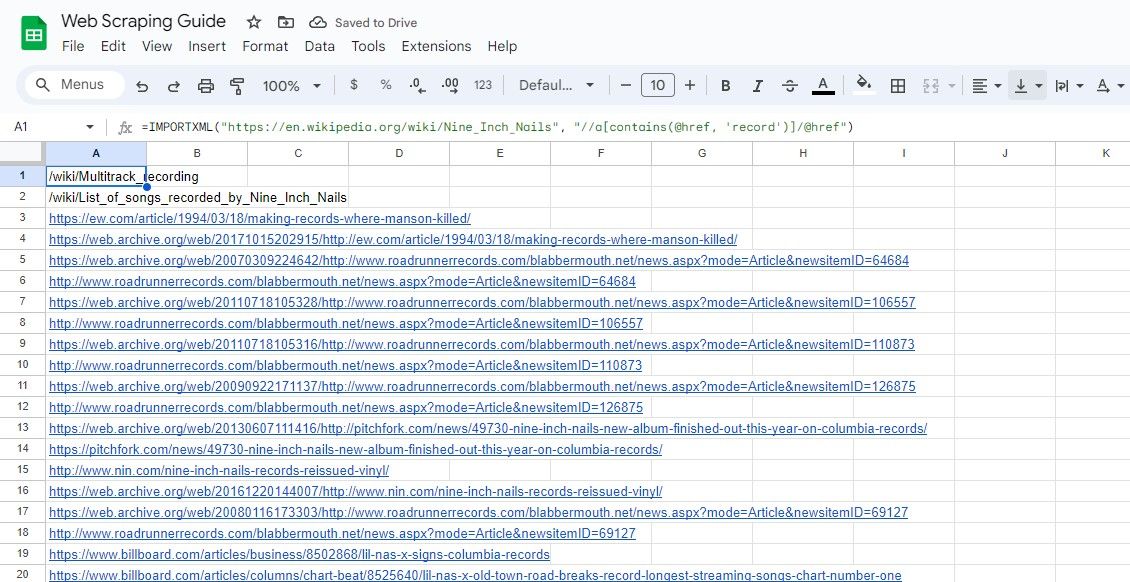
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a[contains(@href, 'record')]/@href")
Formula de mai sus răzuiește toate linkurile care conțin înregistrarea cuvântului în textul lor dintr-un exemplu de articol Wikipedia.
2. Razuirea legăturilor într-o secțiune
Pentru a răzui link-uri dintr-o anumită secțiune a unei pagini, puteți specifica XPath-ul secțiunii. De exemplu:
=IMPORTXML(url, "//div[@class="section"]//a/@href")
Această interogare selectează atributele href ale elementelor din elementele div cu clasa „secțiune”.
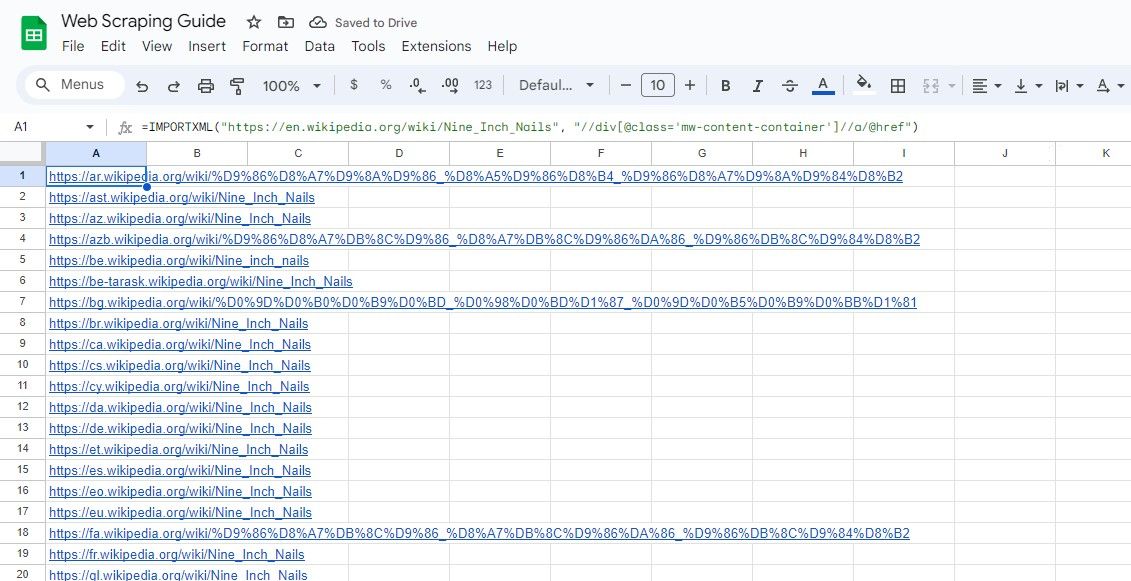
În mod similar, formula de mai jos selectează toate linkurile din clasa div care au clasa mw-content-container:
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//div[@class="mw-content-container"]//a/@href")
Este demn de remarcat faptul că puteți utiliza IMPORTXML pentru mai mult decât pentru web scraping. Puteți utiliza familia de funcții IMPORT pentru a importa tabele de date de pe site-uri web în Foi de calcul Google.
Deși Google Sheets și Excel împărtășesc majoritatea funcțiilor lor, familia de funcții IMPORT este unică pentru Google Sheets. Va trebui să luați în considerare alte metode de a importa date de pe site-uri web în Excel.
Simplificați Web Scraping cu Foi de calcul Google
Web scraping cu Foi de calcul Google și funcția IMPORTXML este o modalitate versatilă și accesibilă de a colecta date de pe site-uri web.
Prin stăpânirea XPath și înțelegerea modului de a crea interogări eficiente, puteți debloca întregul potențial al IMPORTXML și puteți obține informații valoroase din resursele web. Deci, începeți să răzuiți și duceți-vă analiza web la nivelul următor!