
În lumea actuală bazată pe date, metoda tradițională de colectare manuală a datelor este depășită. Un computer cu o conexiune la internet pe fiecare birou a făcut din web o sursă uriașă de date. Astfel, metoda modernă mai eficientă și care economisește timp pentru colectarea datelor este web scraping. Și când vine vorba de web scraping, Python are un instrument numit Beautiful Soup. În această postare, vă voi ghida prin pașii de instalare a Beautiful Soup pentru a începe cu web scraping.
Înainte de a instala și de a lucra cu Beautiful Soup, să aflăm de ce ar trebui să o alegeți.
Cuprins
Ce este o supă frumoasă?
Să presupunem că cercetați „impactul COVID asupra sănătății oamenilor” și că ați găsit câteva pagini web care conțin date relevante. Dar dacă nu vă oferă o opțiune de descărcare cu un singur clic pentru a le împrumuta datele? Aici intră în joc Supa Frumoasă.
Beautiful Soup este printre indexul bibliotecilor Python pentru a extrage datele de pe site-urile vizate. Este mai confortabil să preluați date din pagini HTML sau XML.
Leonard Richardson a scos la lumină ideea Beautiful Soup pentru a scoate web-ul la lumină în 2004. Dar contribuția sa la proiect continuă și astăzi. El actualizează cu mândrie fiecare noua lansare a Beautiful Soup pe contul său de Twitter.
Deși Beautiful Soup pentru web scraping a fost dezvoltat folosind Python 3.8, funcționează perfect atât cu Python 3, cât și cu Python 2.4.
Adesea, site-urile web folosesc protecție captcha pentru a-și salva datele din instrumentele AI. În acest caz, câteva modificări ale antetului „user-agent” din Beautiful Soup sau utilizarea API-urilor de rezolvare a Captcha pot imita un browser de încredere și pot păcăli instrumentul de detectare.
Cu toate acestea, dacă nu aveți timp să explorați Beautiful Soup sau doriți ca scrapingul să se facă eficient și cu ușurință, atunci nu ar trebui să ratați să verificați acest API de web scraping, unde puteți doar să furnizați o adresă URL și să obțineți datele în mainile tale.
Dacă sunteți deja programator, folosirea Beautiful Soup pentru scraping nu va fi descurajantă din cauza sintaxei sale simple în navigarea paginilor web și extragerea datelor dorite pe baza analizei condiționate. În același timp, este și prietenos pentru începători.
Deși Beautiful Soup nu este pentru scraping avansat, funcționează cel mai bine pentru a răzui datele din fișierele scrise în limbaje de marcare.
Documentația clară și detaliată este un alt punct brownie pe care Beautiful Soup l-a pus în pungă.
Să găsim o modalitate ușoară de a introduce o supă frumoasă în mașina ta.
Cum se instalează o supă frumoasă pentru web scraping?
Pip – Un manager de pachete Python dezvoltat în 2008 este acum un instrument standard în rândul dezvoltatorilor pentru a instala orice biblioteci sau dependențe Python.
Pip vine implicit odată cu instalarea versiunilor recente de Python. Astfel, dacă aveți versiuni recente Python instalate pe sistemul dvs., sunteți gata.
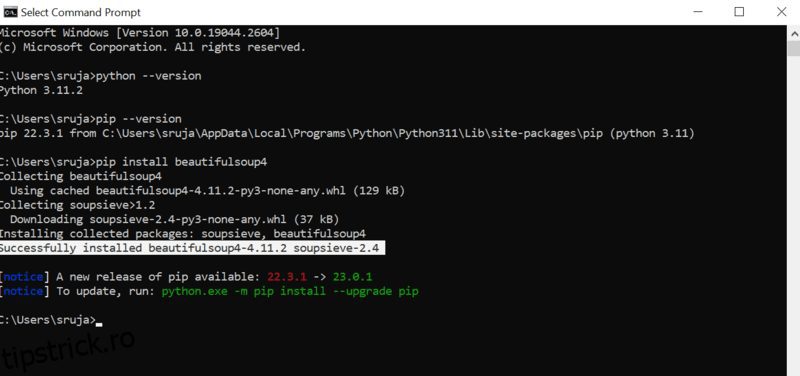
Deschideți promptul de comandă și introduceți următoarea comandă pip pentru a instala instantaneu frumoasa Supa.
pip install beautifulsoup4
Veți vedea ceva similar cu următoarea captură de ecran pe afișajul dvs.
Asigurați-vă că ați actualizat programul de instalare PIP la cea mai recentă versiune pentru a evita erorile comune.
Comanda de actualizare a programului de instalare pip la cea mai recentă versiune este:
pip install --upgrade pip
Am acoperit cu succes jumătate din teren în această postare.
Acum ați instalat Beautiful Soup pe aparat, așa că haideți să vedem cum să o folosiți pentru web scraping.
Cum să importați și să lucrați cu supă frumoasă pentru web scraping?
Introdu următoarea comandă în IDE-ul tău python pentru a importa supa frumoasă în scriptul python curent.
from bs4 import BeautifulSoup
Acum, Beautiful Soup se află în fișierul dvs. Python pentru a o utiliza pentru răzuire.
Să ne uităm la un exemplu de cod pentru a învăța cum să extragi datele dorite cu supa frumoasă.
Îi putem spune frumosului Supă să caute anumite etichete HTML pe site-ul sursă și să răzuie datele prezente în acele etichete.
În această piesă, voi folosi marketwatch.com, care actualizează prețurile acțiunilor în timp real ale diferitelor companii. Să extragem câteva date de pe acest site web pentru a vă familiariza cu biblioteca Beautiful Soup.
Importați pachetul „cereri” care ne va permite să primim și să răspundem la solicitări HTTP și „urllib” pentru a încărca pagina web de la adresa URL a acesteia.
from urllib.request import urlopen import requests
Salvați linkul paginii web într-o variabilă, astfel încât să îl puteți accesa cu ușurință mai târziu.
url="https://www.marketwatch.com/investing/stock/amzn"
Următorul ar fi să folosiți metoda „urlopen” din biblioteca „urllib” pentru a stoca pagina HTML într-o variabilă. Treceți adresa URL la funcția „urlopen” și salvați rezultatul într-o variabilă.
page = urlopen(url)
Creați un obiect Beautiful Soup și analizați pagina web dorită folosind „html.parser”.
soup_obj = BeautifulSoup(page, 'html.parser')
Acum, întregul script HTML al paginii web vizate este stocat în variabila „soup_obj”.
Înainte de a continua, să ne uităm la codul sursă al paginii vizate pentru a afla mai multe despre scriptul HTML și etichete.
Faceți clic dreapta oriunde pe pagina web cu mouse-ul. Apoi veți găsi o opțiune de inspectare, așa cum este afișată mai jos.
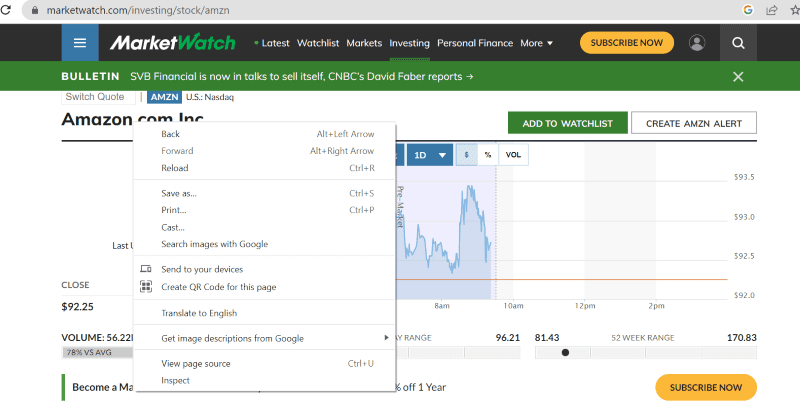
Faceți clic pe inspectare pentru a vedea codul sursă.
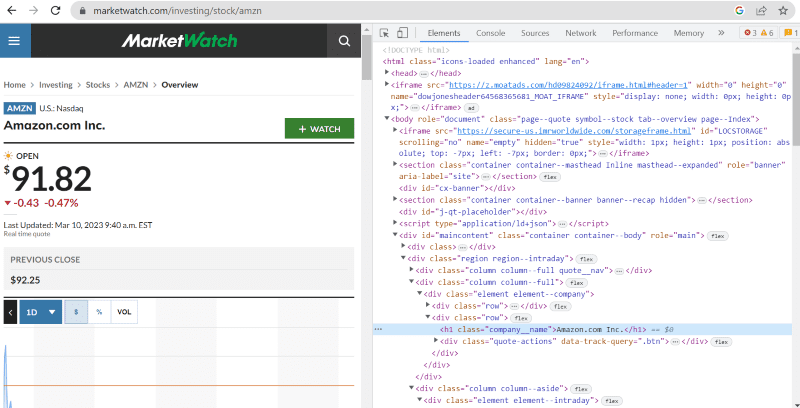
În codul sursă de mai sus, puteți găsi etichete, clase și informații mai specifice despre fiecare element vizibil pe interfața site-ului.
Metoda „găsește” în Beautiful Soup ne permite să căutăm etichetele HTML solicitate și să recuperăm datele. Pentru a face acest lucru, dăm numele clasei și etichetele metodei care extrage date specifice.
De exemplu, „Amazon.com Inc.” afișat pe pagina web are numele clasei: „company__name” etichetat sub „h1”. Putem introduce aceste informații în metoda „find” pentru a extrage fragmentul HTML relevant într-o variabilă.
name = soup_obj.find('h1', attrs={'class': 'company__name'})
Să redăm scriptul HTML stocat în variabila „nume” și textul necesar pe ecran.
print(name) print(name.text)

Puteți asista la datele extrase imprimate pe ecran.
Web Scrape site-ul IMDb
Mulți dintre noi căutăm evaluări ale filmelor pe site-ul IMBb înainte de a viziona un film. Această demonstrație vă va oferi o listă de filme de top și vă va ajuta să vă obișnuiți cu frumoasa Supă pentru web scraping.
Pasul 1: Importă frumoasa Supa și solicită biblioteci.
from bs4 import BeautifulSoup import requests
Pasul 2: Să atribuim adresa URL pe care vrem să o răzuim unei variabile numite „url” pentru acces ușor în cod.
Pachetul „cereri” este folosit pentru a obține pagina HTML de la adresa URL.
url = requests.get('https://www.imdb.com/search/title/?count=100&groups=top_1000&sort=user_rating')
Pasul 3: În următorul fragment de cod, vom analiza pagina HTML a adresei URL curente pentru a crea un obiect de supă frumoasă.
soup_obj = BeautifulSoup(url.text, 'html.parser')
Variabila „soup_obj” conține acum întregul script HTML al paginii web dorite, ca în imaginea următoare.
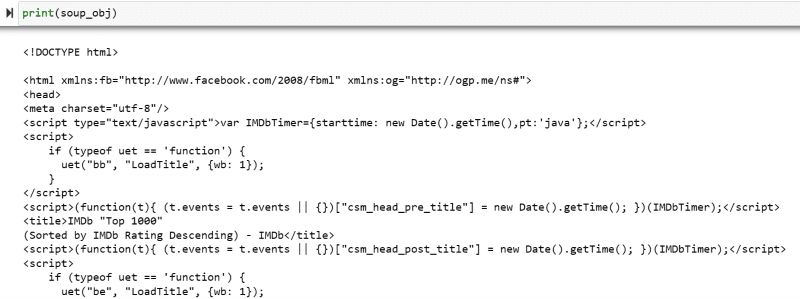
Să inspectăm codul sursă al paginii web pentru a găsi scriptul HTML al datelor pe care vrem să le răzuim.
Treceți cursorul peste elementul paginii web pe care doriți să îl extrageți. Apoi, faceți clic dreapta pe el și mergeți cu opțiunea de inspectare pentru a vedea codul sursă al acelui element specific. Următoarele imagini vă vor ghida mai bine.
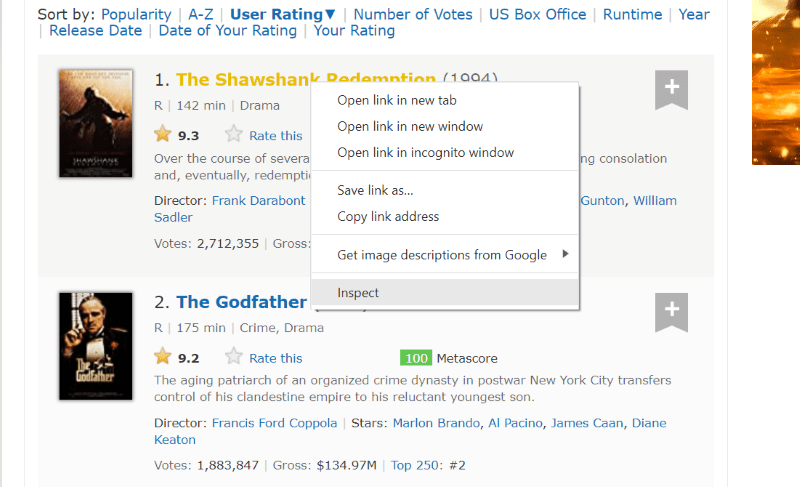
Lista „lister-list” de clasă conține toate datele legate de film cu cele mai bune cote ca subdiviziuni în etichete div succesive.
În scriptul HTML al fiecărei plăci de film, sub clasa „mod lista-element-avansat”, avem o etichetă „h3” care stochează numele filmului, rangul și anul lansării, așa cum este evidențiat în imaginea de mai jos.
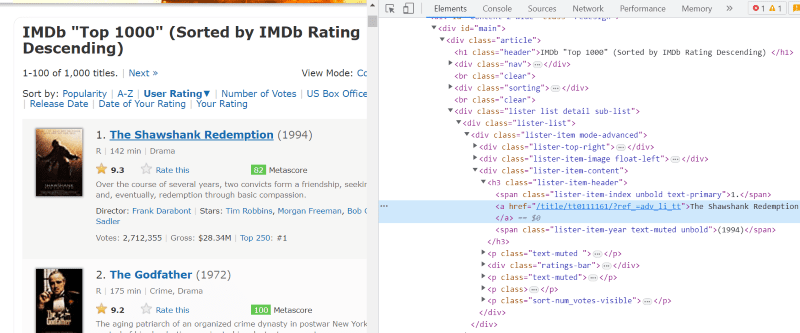
Notă: Metoda „găsește” în Beautiful Soup caută prima etichetă care se potrivește cu numele de intrare care i-a fost dat. Spre deosebire de „find”, metoda „find_all” caută toate etichetele care se potrivesc cu intrarea dată.
Pasul 4: Puteți folosi metodele „find” și „find_all” pentru a salva scriptul HTML al fiecărui film, rang și an într-o variabilă de listă.
top_movies = soup_obj.find('div',attrs={'class': 'lister-list'}).find_all('h3')
Pasul 5: Parcurgeți lista de filme stocate în variabila: „top_movies” și extrageți numele, rangul și anul fiecărui film în format text din scriptul HTML folosind codul de mai jos.
for movie in top_movies:
movi_name = movie.a.text
rank = movie.span.text.rstrip('.')
year = movie.find('span', attrs={'class': 'lister-item-year text-muted unbold'})
year = year.text.strip('()')
print(movi_name + " ", rank+ " ", year+ " ")
În captura de ecran de ieșire, puteți vedea lista de filme cu numele, rangul și anul lansării.
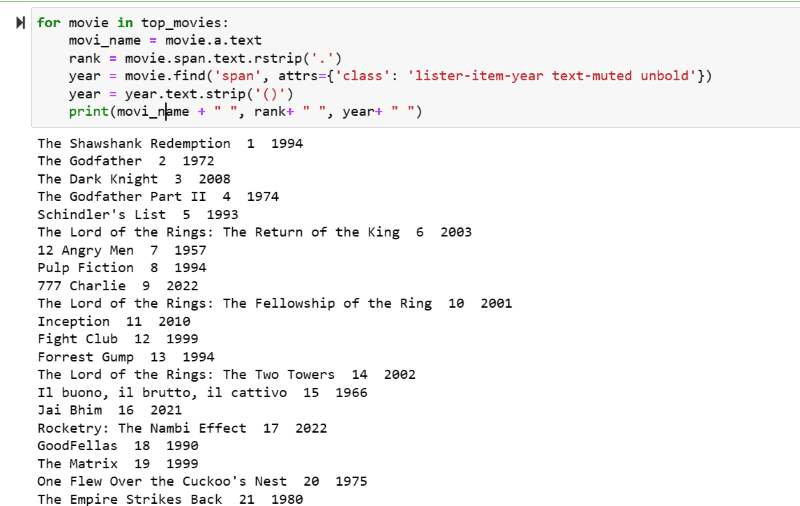
Puteți muta fără efort datele tipărite într-o foaie Excel cu un cod python și să le utilizați pentru analiză.
Cuvinte finale
Această postare vă îndrumă în instalarea unei supe frumoase pentru web scraping. De asemenea, exemplele de răzuire pe care le-am arătat ar trebui să vă ajute să începeți cu Beautiful Soup.
Deoarece sunteți interesat de cum să instalați Beautiful Soup pentru web scraping, vă recomand să consultați acest ghid ușor de înțeles pentru a afla mai multe despre web scraping folosind Python.