Extragerea Informațiilor din Fișiere PDF cu Python: Text, Legături și Imagini
Python, un limbaj de programare extrem de adaptabil, solicită adesea dezvoltatorilor să gestioneze diverse tipuri de fișiere. O sarcină frecventă este procesarea fișierelor PDF (Portable Document Format) pentru a extrage informații esențiale.
Fișierele PDF pot conține o gamă largă de date, inclusiv text, imagini și link-uri. În cadrul unui program Python, extragerea acestor date poate fi necesară pentru diferite operații. Spre deosebire de structurile de date uzuale, cum ar fi tupluri, liste sau dicționare, recuperarea informațiilor dintr-un PDF poate ridica provocări.
Din fericire, există biblioteci Python specializate, concepute pentru a facilita interacțiunea cu fișierele PDF și pentru a extrage datele conținute. Pentru a ilustra acest lucru, vom explora metodele de extragere a textului, legăturilor și imaginilor din documentele PDF. Pentru a începe, descărcați un fișier PDF de test și salvați-l în același director cu codul dvs. Python.
Extragerea Textului din PDF-uri cu PyPDF2
Pentru a extrage textul din fișiere PDF, vom utiliza biblioteca PyPDF2. PyPDF2 este o bibliotecă gratuită, cu sursă deschisă, care permite manipularea paginilor PDF, cum ar fi îmbinarea, decuparea și transformarea. De asemenea, permite adăugarea de date personalizate, setări de vizualizare și parole la fișierele PDF. Cel mai important, PyPDF2 oferă capacitatea de a extrage text din PDF-uri.
Pentru a instala PyPDF2, vom folosi pip, un instrument de gestionare a pachetelor Python, care permite instalarea diverselor biblioteci. Iată pașii:
1. Verificați dacă pip este deja instalat, rulând comanda:
pip --version
Dacă nu primiți un număr de versiune, pip nu este instalat.
2. Pentru a instala pip, descărcați scriptul de instalare de aici.
Veți fi redirecționat către o pagină cu scriptul de instalare:
Salvați pagina ca `get-pip.py`.
Deschideți terminalul, navigați la directorul unde ați salvat fișierul și executați:
sudo python3 get-pip.py
Ar trebui să vedeți confirmarea instalării, similar cu exemplul de mai jos:
3. Verificați instalarea reușită a pip, executând:
pip --version
Ar trebui să primiți un număr de versiune, ceea ce confirmă instalarea cu succes:

Cu pip instalat, putem continua cu instalarea PyPDF2.
1. Instalați PyPDF2 prin terminal, utilizând comanda:
pip install PyPDF2
2. Creați un fișier Python și importați clasa `PdfReader` din PyPDF2:
from PyPDF2 import PdfReader
Clasa `PdfReader` ne permite să deschidem, să citim conținutul și să extragem text din fișiere PDF.
3. Pentru a începe lucrul cu un PDF, trebuie să-l deschidem, creând o instanță a clasei `PdfReader` și transmițând fișierul PDF:
reader = PdfReader('games.pdf')
Această linie creează o instanță `PdfReader` care va accesa conținutul fișierului PDF specificat, folosind variabila `reader` pentru a accesa metodele și proprietățile clasei.
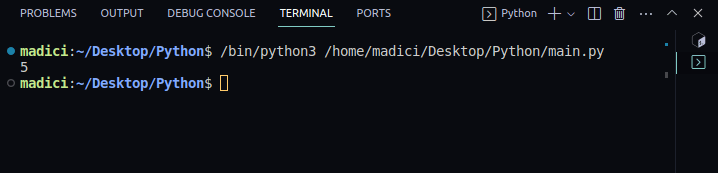
4. Pentru a verifica dacă totul funcționează, tipăriți numărul de pagini din PDF:
print(len(reader.pages))
Rezultatul va fi:
5
5. Având 5 pagini, putem accesa fiecare pagină. În Python, numerotarea începe de la 0. Pentru a accesa prima pagină, folosim:
page1 = reader.pages[0]
Astfel, variabila `page1` stochează prima pagină din PDF.
6. Pentru a extrage textul primei pagini, folosim:
textPage1 = page1.extract_text()
Textul extras este stocat în variabila `textPage1`.
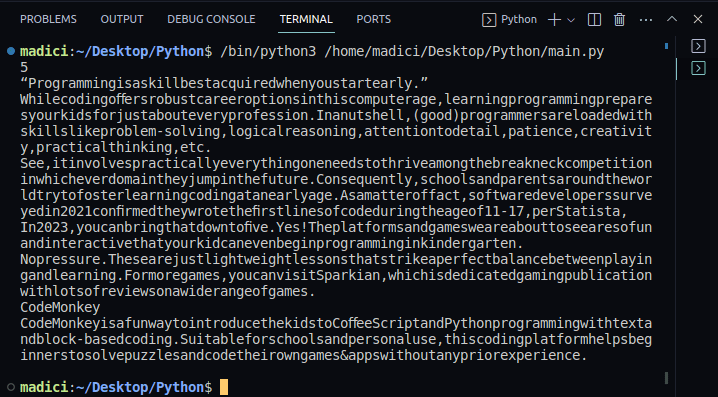
7. Pentru a confirma extragerea cu succes, putem tipări conținutul variabilei `textPage1`. Codul complet pentru extragerea și tipărirea textului primei pagini este:
# import the PdfReader class from PyPDF2
from PyPDF2 import PdfReader
# create an instance of the PdfReader class
reader = PdfReader('games.pdf')
# get the number of pages available in the pdf file
print(len(reader.pages))
# access the first page in the pdf
page1 = reader.pages[0]
# extract the text in page 1 of the pdf file
textPage1 = page1.extract_text()
# print out the extracted text
print(textPage1)
Rezultatul va afișa textul primei pagini:
Extragerea Legăturilor din PDF-uri cu PyMuPDF
Pentru a extrage link-uri din fișiere PDF, vom folosi biblioteca PyMuPDF, care oferă instrumente pentru extragerea, analizarea, conversia și manipularea datelor din documente PDF. PyMuPDF necesită Python 3.8 sau o versiune ulterioară. Pentru a începe:
1. Instalați PyMuPDF prin terminal, cu comanda:
pip install PyMuPDF
2. Importați PyMuPDF în fișierul Python:
import fitz
3. Pentru a accesa PDF-ul, trebuie mai întâi să îl deschidem folosind:
doc = fitz.open("games.pdf")
4. Tipăriți numărul de pagini din PDF:
print(doc.page_count)
Rezultatul este:
5
4. Pentru a extrage link-urile, încărcați pagina dorită cu ajutorul funcției `load_page()`, transmițând numărul paginii (începând de la 0). Pentru prima pagină, folosim:
page = doc.load_page(0)
5. Extrageți toate legăturile din pagină folosind:
links = page.get_links()
Variabila `links` va conține toate legăturile de pe pagina specificată.
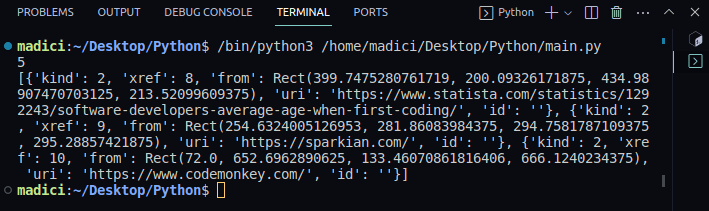
6. Pentru a vedea conținutul variabilei `links`, tipăriți-o:
print(links)
Veți observa o listă de dicționare, unde fiecare dicționar reprezintă o legătură, cu link-ul real stocat sub cheia „uri”:
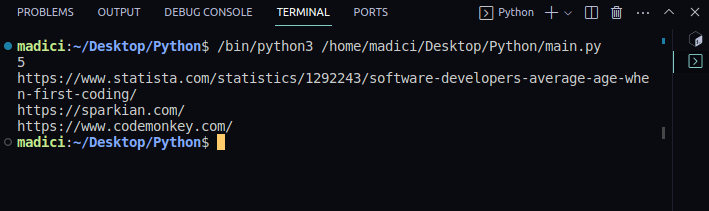
7. Pentru a obține efectiv legăturile, iterăm prin lista `links` și tipărim valorile corespunzătoare cheii „uri”. Iată codul complet:
import fitz
# Open the PDF file
doc = fitz.open("games.pdf")
# Print out the number of pages
print(doc.page_count)
# load the first page from the PDF
page = doc.load_page(0)
# extract all links from the page and store it under - links
links = page.get_links()
# print the links object
#print(links)
# print the actual links stored under the key "uri"
for obj in links:
print(obj["uri"])
Rezultatul va fi o listă cu toate link-urile din prima pagină:
8. Pentru a face codul reutilizabil, definim funcții pentru a extrage și a tipări toate link-urile dintr-un PDF. Astfel, vom putea apela aceste funcții cu orice PDF și vom primi link-urile extrase. Iată codul:
import fitz
# Extract all the links in a PDF document
def extract_link(path_to_pdf):
links = []
doc = fitz.open(path_to_pdf)
for page_num in range(doc.page_count):
page = doc.load_page(page_num)
page_links = page.get_links()
links.extend(page_links)
return links
# print out all the links returned from the PDF document
def print_all_links(links):
for link in links:
print(link["uri"])
# Call the function to extract all the links in a pdf
# all the return links are stored under all_links
all_links = extract_link("games.pdf")
# call the function to print all links in the PDF
print_all_links(all_links)
Rezultatul va fi o listă cu toate link-urile din întregul PDF:
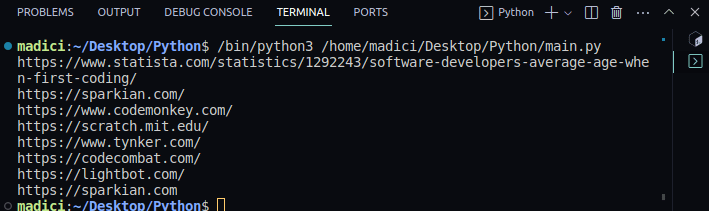
Funcția `extract_link()` primește un fișier PDF, iterează prin toate paginile, extrage legăturile și le returnează. Funcția `print_all_links()` tipărește link-urile din rezultatul `extract_link()`.
Extragerea Imaginilor din PDF-uri cu PyMuPDF
Pentru a extrage imagini, continuăm să folosim PyMuPDF. Iată pașii necesari:
1. Importăm bibliotecile necesare: PyMuPDF, `io` și PIL (Python Imaging Library):
import fitz from io import BytesIO from PIL import Image
`io` ne permite să manipulăm date binare, iar PIL ne ajută la crearea și salvarea imaginilor.
2. Deschidem fișierul PDF:
doc = fitz.open("games.pdf")
3. Încărcăm pagina de unde dorim să extragem imaginea:
page = doc.load_page(0)
4. PyMuPDF identifică imaginile printr-un număr de referință încrucișată (xref), care este un număr întreg unic pentru fiecare imagine. Pentru a obține xref-ul imaginilor de pe o pagină, folosim funcția `get_images()`:
image_xref = page.get_images() print(image_xref)
Rezultatul va fi:
[(7, 0, 699, 407, 8, 'DeviceRGB', '', 'X7', 'FlateDecode')]
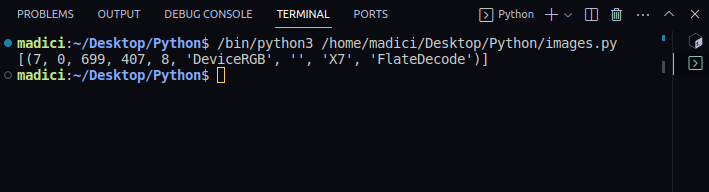
`get_images()` returnează o listă de tupluri cu informații despre imagine. Primul element din tuplu este xref-ul imaginii.
5. Pentru a extrage valoarea xref, folosim:
# get xref value of the image xref_value = image_xref[0][0] print(xref_value)
Rezultatul:
[(7, 0, 699, 407, 8, 'DeviceRGB', '', 'X7', 'FlateDecode')] 7
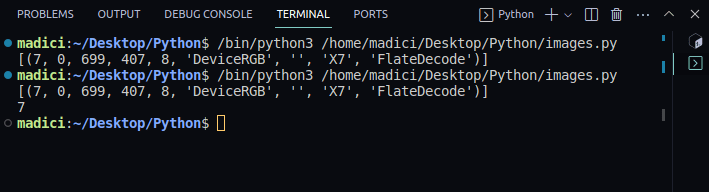
6. Acum putem extrage imaginea folosind funcția `extract_image()`:
img_dictionary = doc.extract_image(xref_value)
Funcția returnează un dicționar care conține datele binare ale imaginii și metadatele.
7. Verificăm extensia fișierului imaginii, care este stocată sub cheia „ext”:
# get file extenstion img_extension = img_dictionary["ext"] print(img_extension)
Rezultatul este:
png
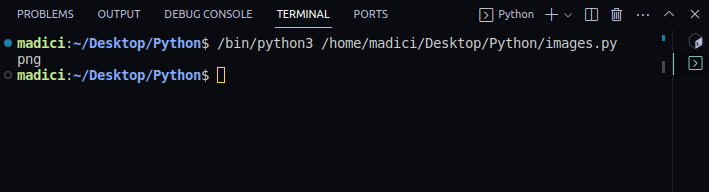
8. Extragem datele binare ale imaginii, stocate sub cheia „image”:
# get the actual image binary data img_binary = img_dictionary["image"]
9. Creăm un obiect `BytesIO` și îl inițializăm cu datele binare. Acest obiect permite bibliotecilor Python, cum ar fi PIL, să proceseze imaginea:
# create a BytesIO object to work with the image bytes image_io = BytesIO(img_binary)
10. Deschidem și analizăm datele imaginii din obiectul `BytesIO` cu PIL. Acest lucru permite bibliotecii să determine formatul imaginii (în acest caz, PNG) și să creeze un obiect imagine care poate fi manipulat cu metodele PIL:
# open the image using Pillow image = Image.open(image_io)
11. Specificăm calea unde dorim să salvăm imaginea:
output_path = "image_1.png"
Imaginea va fi salvată în același director cu fișierul Python, sub numele de `image_1.png`.
12. Salvăm imaginea și închidem obiectul `BytesIO`:
# save the image image.save(output_path) # Close the BytesIO object image_io.close()
Codul complet pentru extragerea unei imagini din PDF:
import fitz
from io import BytesIO
from PIL import Image
doc = fitz.open("games.pdf")
page = doc.load_page(0)
# get a cross reference(xref) to the image
image_xref = page.get_images()
# get the actual xref value of the image
xref_value = image_xref[0][0]
# extract the image
img_dictionary = doc.extract_image(xref_value)
# get file extenstion
img_extension = img_dictionary["ext"]
# get the actual image binary data
img_binary = img_dictionary["image"]
# create a BytesIO object to work with the image bytes
image_io = BytesIO(img_binary)
# open the image using PIL library
image = Image.open(image_io)
#specify the path where you want to save the image
output_path = "image_1.png"
# save the image
image.save(output_path)
# Close the BytesIO object
image_io.close()
După rularea codului, veți găsi imaginea `image_1.png` în directorul fișierului Python:
Concluzie
Pentru a îmbunătăți abilitățile de extragere a datelor, încercați să refactorizați codul, creând funcții reutilizabile, așa cum am demonstrat în cazul link-urilor. Astfel, veți putea extrage cu ușurință texte, imagini și link-uri din orice fișier PDF. Continuați să experimentați și să perfecționați codul. Explorați și API-uri PDF disponibile pentru a satisface cerințele specifice ale afacerii dvs.