
Llama 2 este un model de limbaj mare (LLM) open-source dezvoltat de Meta. Este un model de limbă mare cu sursă deschisă competent, probabil mai bun decât unele modele închise, cum ar fi GPT-3.5 și PaLM 2. Este format din trei dimensiuni de model de text generativ pre-antrenate și ajustate, inclusiv cele 7 miliarde, 13 miliarde și 70 de miliarde de modele cu parametri.
Veți explora capacitățile conversaționale ale Llama 2 prin construirea unui chatbot folosind Streamlit și Llama 2.
Cuprins
Înțelegerea Llama 2: caracteristici și beneficii
Cât de diferit este Llama 2 de modelul predecesor de limbă mare, Llama 1?
- Dimensiune mai mare a modelului: modelul este mai mare, cu până la 70 de miliarde de parametri. Acest lucru îi permite să învețe asocieri mai complexe între cuvinte și propoziții.
- Abilități de conversație îmbunătățite: Învățarea prin consolidare din feedbackul uman (RLHF) îmbunătățește abilitățile de aplicare a conversației. Acest lucru permite modelului să genereze conținut uman chiar și în interacțiuni complicate.
- Inferență mai rapidă: introduce o metodă nouă numită atenție la interogare grupată pentru a accelera inferența. Acest lucru are ca rezultat capacitatea sa de a construi aplicații mai utile, cum ar fi chatbot-uri și asistenți virtuali.
- Mai eficient: este mai eficient în memorie și resurse de calcul decât predecesorul său.
- Licență open-source și non-comercială: este open-source. Cercetătorii și dezvoltatorii pot folosi și modifica Llama 2 fără restricții.
Llama 2 depășește semnificativ predecesorul în toate privințele. Aceste caracteristici îl fac un instrument puternic pentru multe aplicații, cum ar fi chatbot, asistenți virtuali și înțelegerea limbajului natural.
Configurarea unui mediu Streamlit pentru dezvoltarea Chatbot
Pentru a începe să vă construiți aplicația, trebuie să configurați un mediu de dezvoltare. Aceasta este pentru a vă izola proiectul de proiectele existente pe mașina dvs.
Mai întâi, începeți prin a crea un mediu virtual folosind biblioteca Pipenv, după cum urmează:
pipenv shell
Apoi, instalați bibliotecile necesare pentru a construi chatbot-ul.
pipenv install streamlit replicate
Streamlit: este un cadru de aplicații web open-source care redă rapid aplicațiile de învățare automată și știința datelor.
Replicare: este o platformă cloud care oferă acces la modele mari de învățare automată open-source pentru implementare.
Obțineți tokenul dvs. API Llama 2 de la Replicate
Pentru a obține o cheie cu simbol Replicat, trebuie mai întâi să înregistrați un cont pe Replica folosind contul tău GitHub.
După ce ați accesat tabloul de bord, navigați la butonul Explore și căutați chat Llama 2 pentru a vedea modelul llama-2–70b-chat.
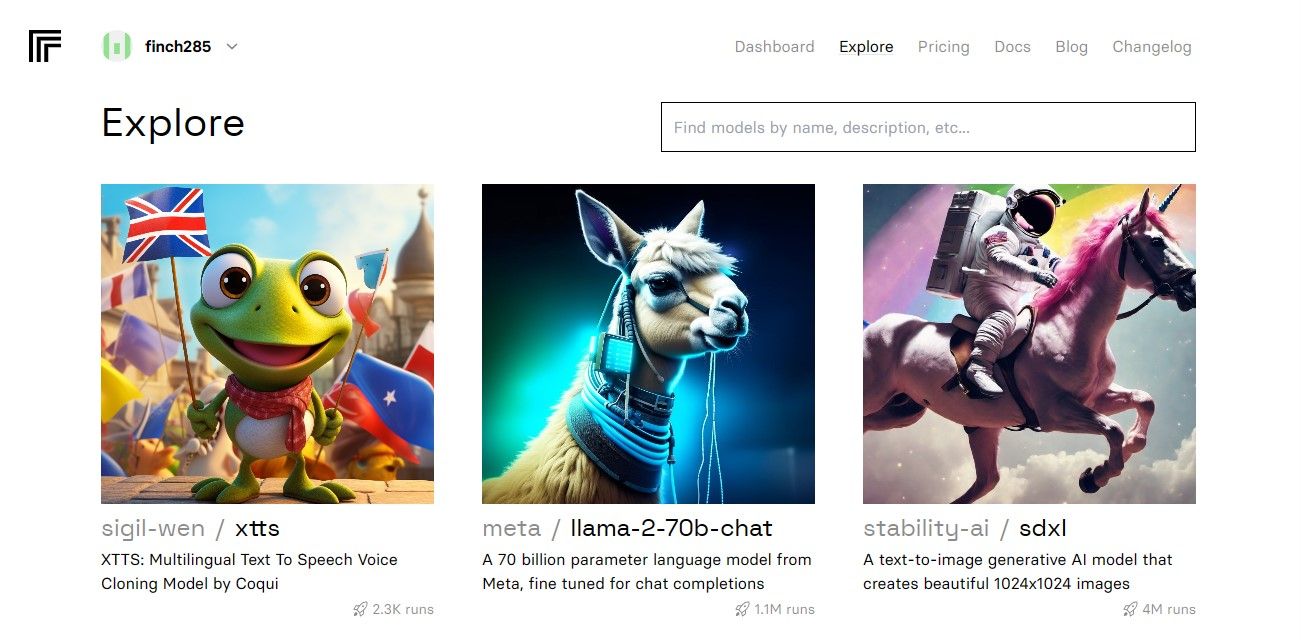
Faceți clic pe modelul llama-2–70b-chat pentru a vedea punctele finale API Llama 2. Faceți clic pe butonul API din bara de navigare a modelului llama-2–70b-chat. În partea dreaptă a paginii, faceți clic pe butonul Python. Acest lucru vă va oferi acces la simbolul API pentru aplicațiile Python.
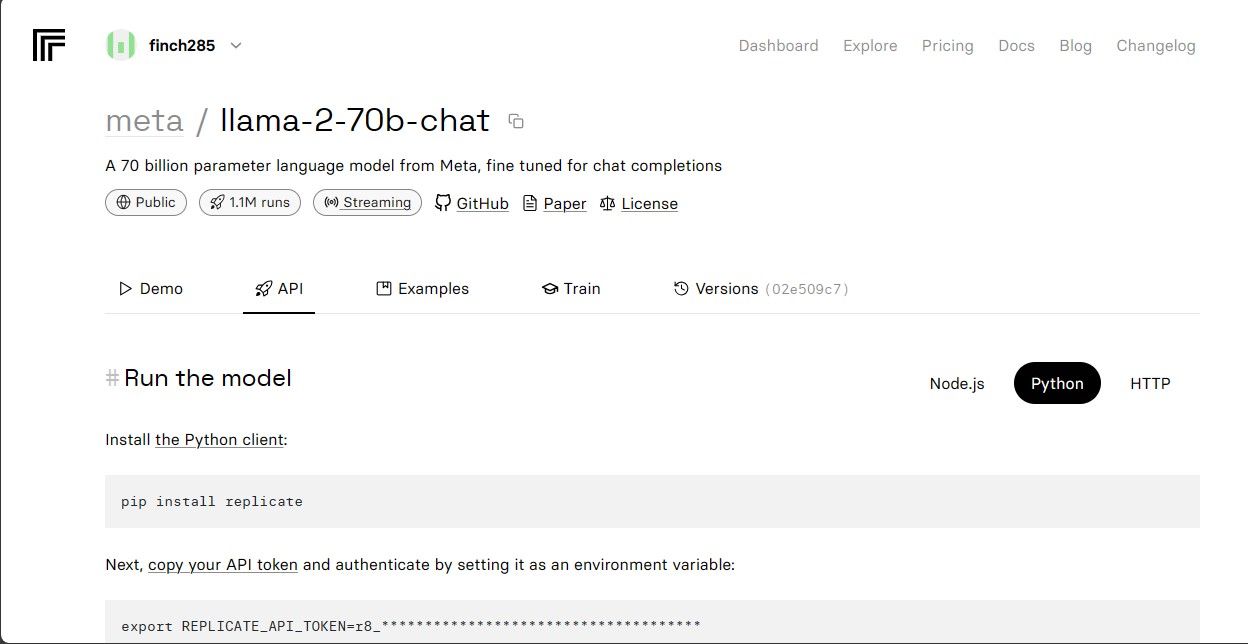
Copiați REPLICATE_API_TOKEN și păstrați-l în siguranță pentru utilizare ulterioară.
Construirea Chatbot-ului
Mai întâi, creați un fișier Python numit llama_chatbot.py și un fișier env (.env). Îți vei scrie codul în llama_chatbot.py și vei stoca cheile secrete și jetoanele API în fișierul .env.
În fișierul llama_chatbot.py, importați bibliotecile după cum urmează.
import streamlit as st
import os
import replicate
Apoi, setați variabilele globale ale modelului llama-2–70b-chat.
REPLICATE_API_TOKEN = os.environ.get('REPLICATE_API_TOKEN', default="")
LLaMA2_7B_ENDPOINT = os.environ.get('MODEL_ENDPOINT7B', default="")
LLaMA2_13B_ENDPOINT = os.environ.get('MODEL_ENDPOINT13B', default="")
LLaMA2_70B_ENDPOINT = os.environ.get('MODEL_ENDPOINT70B', default="")
În fișierul .env, adăugați jetonul Replicare și punctele finale ale modelului în următorul format:
REPLICATE_API_TOKEN='Paste_Your_Replicate_Token'
MODEL_ENDPOINT7B='a16z-infra/llama7b-v2-chat:4f0a4744c7295c024a1de15e1a63c880d3da035fa1f49bfd344fe076074c8eea'
MODEL_ENDPOINT13B='a16z-infra/llama13b-v2-chat:df7690f1994d94e96ad9d568eac121aecf50684a0b0963b25a41cc40061269e5'
MODEL_ENDPOINT70B='replicate/llama70b-v2-chat:e951f18578850b652510200860fc4ea62b3b16fac280f83ff32282f87bbd2e48'
Lipiți indicativul de replicare și salvați fișierul .env.
Proiectarea fluxului conversațional al chatbot-ului
Creați o solicitare prealabilă pentru a porni modelul Llama 2, în funcție de sarcina pe care doriți să o facă. În acest caz, doriți ca modelul să acționeze ca asistent.
PRE_PROMPT = "You are a helpful assistant. You do not respond as " \
"'User' or pretend to be 'User'." \
" You only respond once as Assistant."
Configurați configurația paginii pentru chatbot-ul dvs. după cum urmează:
st.set_page_config(
page_title="LLaMA2Chat",
page_icon=":volleyball:",
layout="wide"
)
Scrieți o funcție care inițializează și setează variabilele de stare a sesiunii.
LLaMA2_MODELS = {
'LLaMA2-7B': LLaMA2_7B_ENDPOINT,
'LLaMA2-13B': LLaMA2_13B_ENDPOINT,
'LLaMA2-70B': LLaMA2_70B_ENDPOINT,
}
DEFAULT_TEMPERATURE = 0.1
DEFAULT_TOP_P = 0.9
DEFAULT_MAX_SEQ_LEN = 512
DEFAULT_PRE_PROMPT = PRE_PROMPTdef setup_session_state():
st.session_state.setdefault('chat_dialogue', [])
selected_model = st.sidebar.selectbox(
'Choose a LLaMA2 model:', list(LLaMA2_MODELS.keys()), key='model')
st.session_state.setdefault(
'llm', LLaMA2_MODELS.get(selected_model, LLaMA2_70B_ENDPOINT))
st.session_state.setdefault('temperature', DEFAULT_TEMPERATURE)
st.session_state.setdefault('top_p', DEFAULT_TOP_P)
st.session_state.setdefault('max_seq_len', DEFAULT_MAX_SEQ_LEN)
st.session_state.setdefault('pre_prompt', DEFAULT_PRE_PROMPT)
Funcția setează variabilele esențiale precum chat_dialogue, pre_prompt, llm, top_p, max_seq_len și temperatura în starea sesiunii. De asemenea, se ocupă de selecția modelului Llama 2 în funcție de alegerea utilizatorului.
Scrieți o funcție pentru a reda conținutul barei laterale a aplicației Streamlit.
def render_sidebar():
st.sidebar.header("LLaMA2 Chatbot")
st.session_state['temperature'] = st.sidebar.slider('Temperature:',
min_value=0.01, max_value=5.0, value=DEFAULT_TEMPERATURE, step=0.01)
st.session_state['top_p'] = st.sidebar.slider('Top P:', min_value=0.01,
max_value=1.0, value=DEFAULT_TOP_P, step=0.01)
st.session_state['max_seq_len'] = st.sidebar.slider('Max Sequence Length:',
min_value=64, max_value=4096, value=DEFAULT_MAX_SEQ_LEN, step=8)
new_prompt = st.sidebar.text_area(
'Prompt before the chat starts. Edit here if desired:',
DEFAULT_PRE_PROMPT,height=60)
if new_prompt != DEFAULT_PRE_PROMPT and new_prompt != "" and
new_prompt is not None:
st.session_state['pre_prompt'] = new_prompt + "\n"
else:
st.session_state['pre_prompt'] = DEFAULT_PRE_PROMPT
Funcția afișează antetul și variabilele de setare ale chatbot-ului Llama 2 pentru ajustări.
Scrieți funcția care redă istoricul chatului în zona de conținut principal a aplicației Streamlit.
def render_chat_history():
response_container = st.container()
for message in st.session_state.chat_dialogue:
with st.chat_message(message["role"]):
st.markdown(message["content"])
Funcția iterează prin chat_dialogue salvat în starea de sesiune, afișând fiecare mesaj cu rolul corespunzător (utilizator sau asistent).
Gestionați intrarea utilizatorului utilizând funcția de mai jos.
def handle_user_input():
user_input = st.chat_input(
"Type your question here to talk to LLaMA2"
)
if user_input:
st.session_state.chat_dialogue.append(
{"role": "user", "content": user_input}
)
with st.chat_message("user"):
st.markdown(user_input)
Această funcție prezintă utilizatorului un câmp de introducere în care își poate introduce mesajele și întrebările. Mesajul este adăugat la chat_dialogue în starea de sesiune cu rolul de utilizator odată ce utilizatorul trimite mesajul.
Scrieți o funcție care generează răspunsuri din modelul Llama 2 și le afișează în zona de chat.
def generate_assistant_response():
message_placeholder = st.empty()
full_response = ""
string_dialogue = st.session_state['pre_prompt']
for dict_message in st.session_state.chat_dialogue:
speaker = "User" if dict_message["role"] == "user" else "Assistant"
string_dialogue += f"{speaker}: {dict_message['content']}\n"
output = debounce_replicate_run(
st.session_state['llm'],
string_dialogue + "Assistant: ",
st.session_state['max_seq_len'],
st.session_state['temperature'],
st.session_state['top_p'],
REPLICATE_API_TOKEN
)
for item in output:
full_response += item
message_placeholder.markdown(full_response + "▌")
message_placeholder.markdown(full_response)
st.session_state.chat_dialogue.append({"role": "assistant",
"content": full_response})
Funcția creează un șir de istoric de conversație care include atât mesajele utilizatorului, cât și cele ale asistentului înainte de a apela funcția debounce_replicate_run pentru a obține răspunsul asistentului. Modifică continuu răspunsul în interfața de utilizare pentru a oferi o experiență de chat în timp real.
Scrieți funcția principală responsabilă pentru redarea întregii aplicații Streamlit.
def render_app():
setup_session_state()
render_sidebar()
render_chat_history()
handle_user_input()
generate_assistant_response()
Apelează toate funcțiile definite pentru a configura starea sesiunii, a reda bara laterală, a istoricului de chat, a gestiona intrarea utilizatorului și a genera răspunsuri ale asistentului într-o ordine logică.
Scrieți o funcție pentru a invoca funcția render_app și porniți aplicația când scriptul este executat.
def main():
render_app()if __name__ == "__main__":
main()
Acum aplicația dvs. ar trebui să fie gata de execuție.
Gestionarea solicitărilor API
Creați un fișier utils.py în directorul proiectului și adăugați funcția de mai jos:
import replicate
import time
last_call_time = 0
debounce_interval = 2def debounce_replicate_run(llm, prompt, max_len, temperature, top_p,
API_TOKEN):
global last_call_time
print("last call time: ", last_call_time)current_time = time.time()
elapsed_time = current_time - last_call_timeif elapsed_time < debounce_interval:
print("Debouncing")
return "Hello! Your requests are too fast. Please wait a few" \
" seconds before sending another request."last_call_time = time.time()
output = replicate.run(llm, input={"prompt": prompt + "Assistant: ",
"max_length": max_len, "temperature":
temperature, "top_p": top_p,
"repetition_penalty": 1}, api_token=API_TOKEN)
return output
Funcția efectuează un mecanism de retragere pentru a preveni interogările API frecvente și excesive de la intrarea unui utilizator.
Apoi, importați funcția de răspuns la debounce în fișierul llama_chatbot.py, după cum urmează:
from utils import debounce_replicate_run
Acum rulați aplicația:
streamlit run llama_chatbot.py
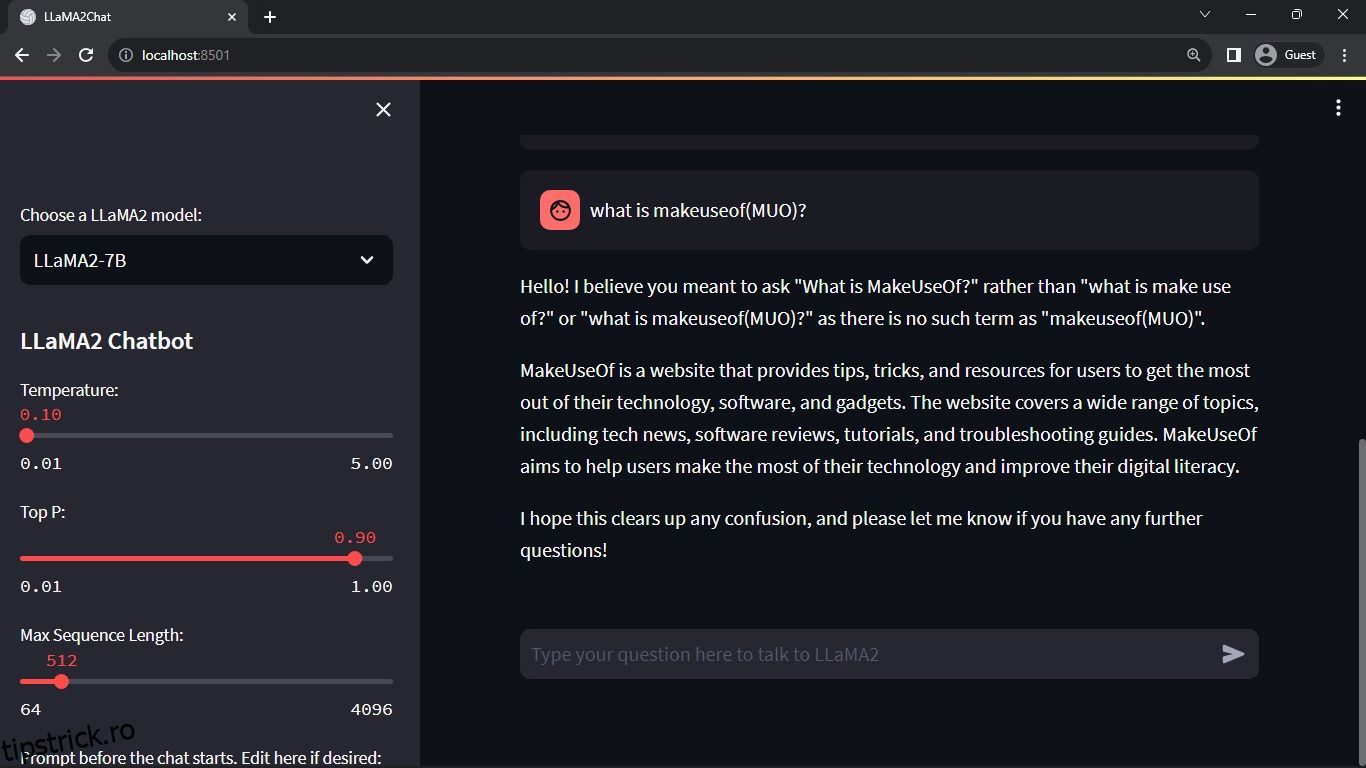
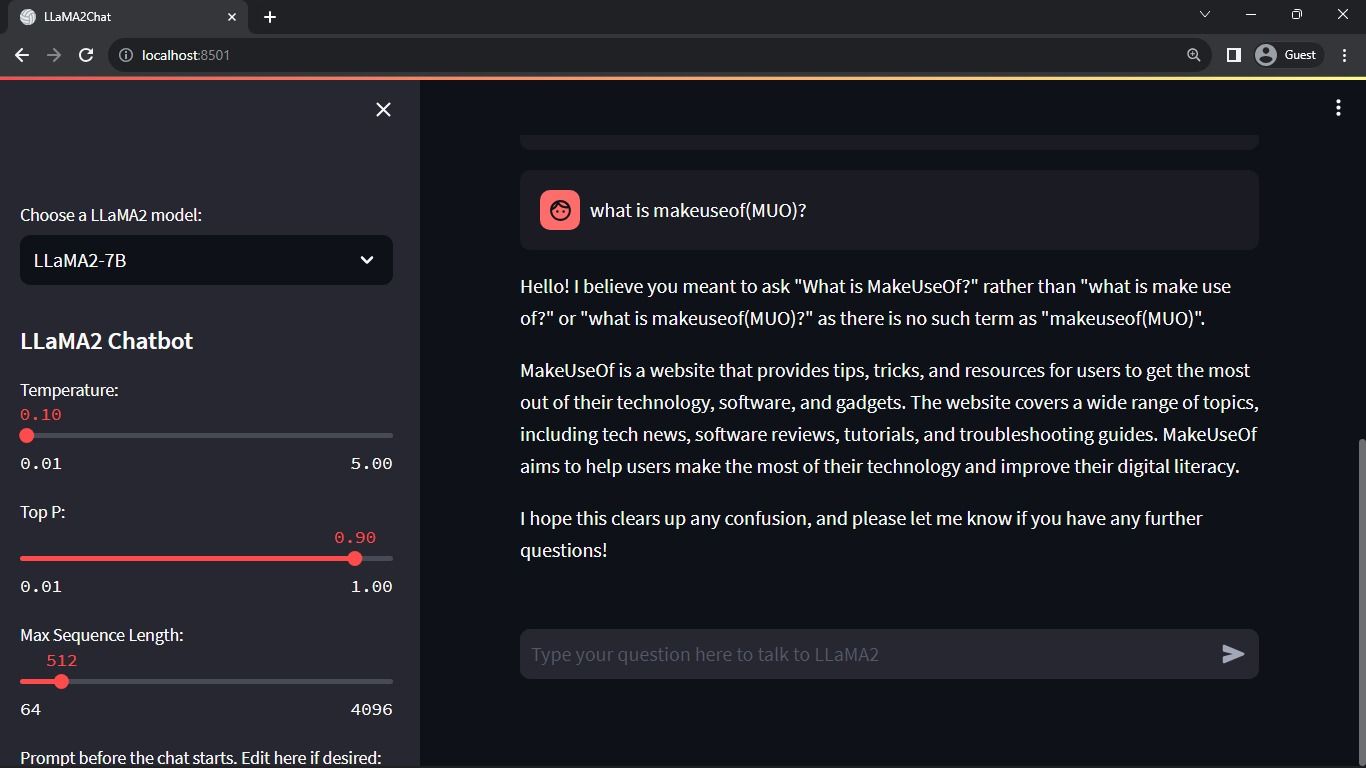
Rezultat așteptat:
Ieșirea arată o conversație între model și un om.
Aplicații reale ale chatbot-urilor Streamlit și Llama 2
Câteva exemple din lumea reală de aplicații Llama 2 includ:
- Chatboți: utilizarea sa se aplică pentru crearea de chatbot-uri cu răspuns uman care pot ține conversații în timp real pe mai multe subiecte.
- Asistenți virtuali: utilizarea sa se aplică pentru crearea de asistenți virtuali care înțeleg și răspund la interogările limbajului uman.
- Traducerea limbii: utilizarea sa se aplică sarcinilor de traducere a limbii.
- Rezumat text: Utilizarea sa este aplicabilă în rezumarea textelor mari în texte scurte pentru o înțelegere ușoară.
- Cercetare: puteți aplica Llama 2 în scopuri de cercetare, răspunzând la întrebări pe o serie de subiecte.
Viitorul AI
Cu modele închise precum GPT-3.5 și GPT-4, este destul de dificil pentru jucătorii mici să construiască ceva substanțial folosind LLM-uri, deoarece accesarea API-ului model GPT poate fi destul de costisitoare.
Deschiderea unor modele avansate de limbaj mari, cum ar fi Llama 2, către comunitatea de dezvoltatori este doar începutul unei noi ere a AI. Va duce la o implementare mai creativă și inovatoare a modelelor în aplicațiile din lumea reală, ceea ce va duce la o cursă accelerată pentru obținerea Super Inteligentei Artificiale (ASI).