
Fiecare administrator de rețea dorește să se asigure că performanța a ceea ce administrează este optimă. Este o simplă chestiune de a menține utilizatorii fericiți. La urma urmei, ei tind să fie primii care observă chiar și cea mai mică degradare a performanței. Așadar, dacă doriți să puteți răspunde la orice reclamație de performanță despre care știți și că lucrați la remedierea acesteia, aveți nevoie de câteva instrumente de performanță. Dacă lucrezi într-un magazin Linux, această postare este pentru tine. Suntem pe cale să revizuim unele dintre cele mai bune instrumente de performanță a rețelei Linux.
Vom începe prin a discuta pe scurt despre monitorizarea performanței rețelei. Scopul nostru nu este să vă facem experți în domeniu, ci mai degrabă să ne asigurăm că suntem cu toții pe aceeași pagină în timp ce explorăm diferitele instrumente disponibile. Vom trece apoi direct în miezul problemei și introducem câteva zece instrumente Linux diferite pe care le puteți utiliza pentru a monitoriza, gestiona și depana performanța rețelei dvs.
Cuprins
Despre monitorizarea și testarea performanței rețelei
Problema cu monitorizarea și testarea performanței rețelei este că se pare că fiecare are propria idee despre ce înseamnă asta. De exemplu, vedem adesea că instrumentele de monitorizare a lățimii de bandă ale rețelei sunt denumite monitorizare a performanței. Același lucru este valabil și pentru instrumentul de analiză a traficului sau pentru sniffer-urile de pachete. Aceasta ridică următoarea întrebare: Ce este monitorizarea și testarea performanței rețelei?
În scopul acestei postări, să lăsăm această dezbatere deoparte și să acceptăm că instrumentele de monitorizare a performanței rețelei sunt pur și simplu orice instrument care poate fi folosit pentru a măsura, evalua, depana sau îmbunătăți performanța rețelei. Folosind o astfel de definiție atotcuprinzătoare, vă vom putea aduce cea mai bună gamă de instrumente și vă vom lăsa la latitudinea alegerii celor care vă pot ajuta cu situația sau problema dvs. specifică.
Cele mai bune instrumente de performanță a rețelei pentru Linux
Așadar, am compilat această listă cu unele dintre cele mai utilizate instrumente Linux care pot fi folosite pentru a testa sau monitoriza diferitele valori asociate cu performanța rețelei. Sunt disponibile în majoritatea distribuțiilor Linux. Fiecare este util pentru a monitoriza și a găsi cauzele reale ale problemelor de performanță. Dintre toate sugestiile de mai jos, una este aproape sigură că se va potrivi nevoilor dumneavoastră specifice.
1. Tcpdump
Tcpdump este sniffer-ul original de pachete. Este un instrument care este folosit pentru a descărca – de unde și numele – conținutul întregului trafic de rețea la ieșirea standard. Prin magia redirecționării și a conductelor, rezultatul său poate fi, desigur, direcționat către orice fișier sau chiar către alt proces. De la lansarea sa inițială, instrumentul a trecut prin unele îmbunătățiri și remedieri de erori, dar rămâne în esență neschimbat. Este disponibil practic pe orice distribuție Linux și a devenit standardul de facto pentru un instrument rapid de capturare a pachetelor. Tcpdump folosește biblioteca libpcap pentru capturarea efectivă a pachetelor.
Unul dintre dezavantajele unui instrument precum tcpdump este că poate colecta o cantitate imensă de date. Atât de mult încât ar putea fi imposibil să găsești exact ceea ce se caută. Din fericire, una dintre cheile pentru puterea și utilitatea instrumentului este posibilitatea de a aplica filtre care vă vor permite să specificați exact ce trafic să captați. De asemenea, puteți canaliza ieșirea comenzii către grep — un alt utilitar comun de linie de comandă — pentru filtrare ulterioară. Cineva care stăpânește tcpdump, grep și shell-ul de comandă îl poate face să capteze exact traficul potrivit pentru orice sarcină de depanare.
Iată un exemplu de utilizare a tcpdump:
# tcpdump -i eth0 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on eth0, link-type EN10MB (Ethernet), capture size 96 bytes 22:08:59.617628 IP tecmint.com.ssh > 115.113.134.3.static-mumbai.vsnl.net.in.28472: P 2532133365:2532133481(116) ack 3561562349 win 9648 22:09:07.653466 IP tecmint.com.ssh > 115.113.134.3.static-mumbai.vsnl.net.in.28472: P 116:232(116) ack 1 win 9648 22:08:59.617916 IP 115.113.134.3.static-mumbai.vsnl.net.in.28472 > tecmint.com.ssh: . ack 116 win 64347
Cu siguranță veți fi de acord că o astfel de ieșire poate fi puțin criptică. Aici poate fi util un adevărat analizor de protocol de rețea.
2. Wireshark
Vă puteți gândi la Wireshark ca tcpdump pe steroizi, dar, de fapt, este mult mai mult decât atât. Referința în sniffer de pachete, a devenit standardul de facto și majoritatea celorlalte instrumente încearcă să-l emuleze. Acest lucru face mult mai mult decât tcpdump, totuși. Nu numai că va capta traficul. Este un analizor de trafic de rețea la fel de mult pe cât este un instrument de capturare a pachetelor. Este atât de puternic încât mulți administratori folosesc alte instrumente, cum ar fi tcpdump, pentru a capta traficul către un fișier, apoi îl încarcă în Wireshark pentru analiză. De fapt, este o modalitate atât de comună de a folosi Wireshark încât, la pornire, vi se solicită fie să deschideți un fișier de captură existent, fie să începeți să capturați trafic. Un alt punct forte al Wireshark sunt toate filtrele pe care le încorporează, care vă permit să vă concentrați exact asupra datelor care vă interesează.
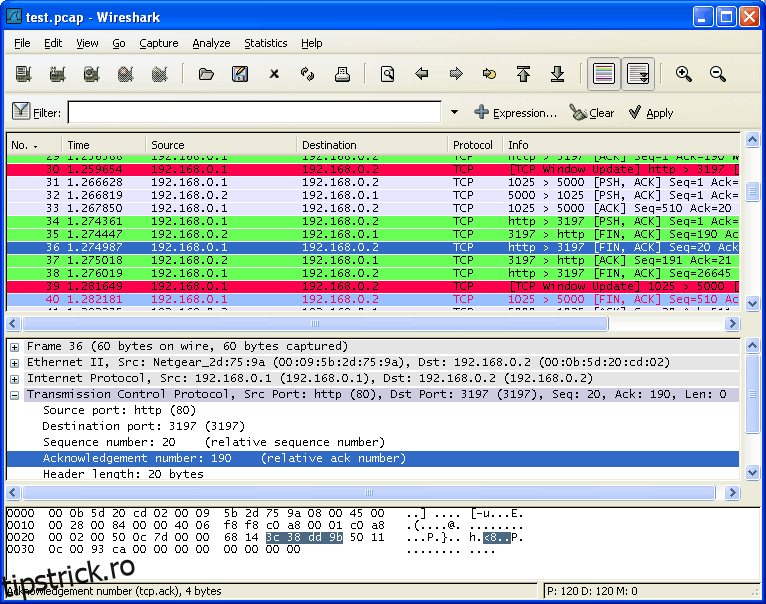
Wireshark are o curbă de învățare abruptă, dar merită învățat. Se va dovedi neprețuit din când în când. Și odată ce l-ați învățat, îl veți putea folosi peste tot, deoarece a fost portat în aproape orice sistem de operare. Și pentru a-l face și mai bun, este open-source și disponibil gratuit.
3. Netstat
Una dintre problemele legate de depanarea problemelor de conectivitate TCP/IP vine din numărul mare de conexiuni și servicii care rulează de obicei pe orice sistem. Netstat poate fi folosit pentru a ajuta la identificarea stării fiecărei conexiuni și a procesului care deservește fiecare, ajutându-vă să restrângeți căutarea. Netstat, care este disponibil pe fiecare distribuție Linux, poate oferi rapid detalii despre serviciile client și comunicațiile TCP/IP. În forma sa cea mai de bază, comanda afișează toate conexiunile active pe computerul local, atât cele de intrare cât și cele de ieșire.
Netstat poate afișa și porturile de ascultare pe computerul pe care rulează. De fapt, comanda acceptă multe opțiuni. Cu toate acestea, opțiunile disponibile diferă între platforme și unele opțiuni funcționează diferit pe platforme diferite. De exemplu, opțiunea -b pe Windows ar afișa numele executabilului asociat fiecărei conexiuni – procesul care deservește conexiunea – în timp ce, pe Mac OS X sau BSD, este folosită împreună cu -i pentru a afișa statisticile în octeți. decât biți. Cel mai bun mod de a afla despre toți parametrii disponibili ai versiunii dvs. specifice pe Netstat este să îl rulați cu -? opțiunea de a afișa ecranul de ajutor al instrumentului. Pe Linux, puteți afișa și pagina de manual Netstat pentru a obține practic aceleași informații.
Iată cum arată o comandă netstat obișnuită și rezultatul acesteia:
# netstat -a | more Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 *:mysql *:* LISTEN tcp 0 0 *:sunrpc *:* LISTEN tcp 0 0 *:realm-rusd *:* LISTEN tcp 0 0 *:ftp *:* LISTEN tcp 0 0 localhost.localdomain:ipp *:* LISTEN tcp 0 0 localhost.localdomain:smtp *:* LISTEN tcp 0 0 localhost.localdomain:smtp localhost.localdomain:42709 TIME_WAIT tcp 0 0 localhost.localdomain:smtp localhost.localdomain:42710 TIME_WAIT tcp 0 0 *:http *:* LISTEN tcp 0 0 *:ssh *:* LISTEN tcp 0 0 *:https *:* LISTEN
4. IPTraf
IPTraf este un utilitar de statistică de rețea bazat pe consolă pentru Linux. Puteți utiliza instrumentul pentru a aduna o varietate de informații, cum ar fi numărul de pachete și octeți de conexiuni TCP, statistici de interfață și indicatori de activitate, întreruperi de trafic TCP sau UDP și număr de pachete și octeți de stație LAN. Dispune de un monitor de trafic IP care afișează informații despre traficul IP din rețeaua dvs., inclusiv informații despre flag TCP, număr de pachete și octeți, detalii ICMP și tipuri de pachete OSPF. Cu cea mai recentă versiune datând din 2005, este oarecum un instrument învechit, dar poate oferi o mulțime de informații utile dacă doriți să învățați cum să îl utilizați.
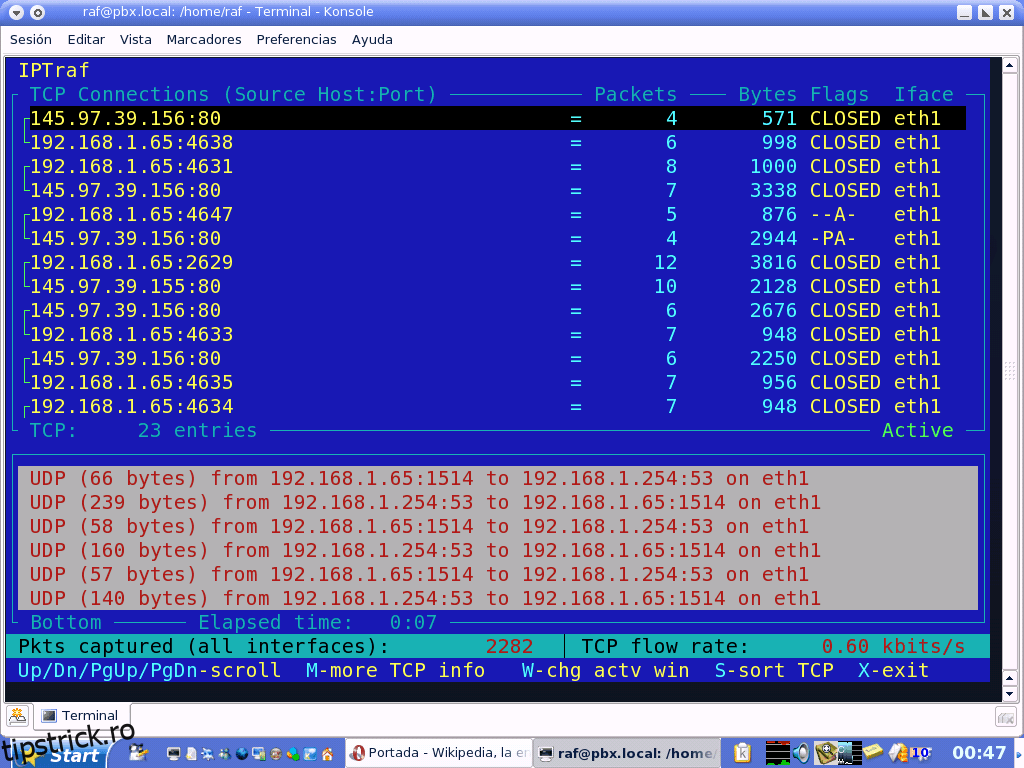
Alte caracteristici ale IPTraf includ statistici generale și detaliate ale interfeței care arată numărul de pachete IP, TCP, UDP, ICMP, non-IP și alte IP, erori de sumă de control IP, activitatea interfeței, numărarea dimensiunilor pachetelor. De asemenea, se mândrește cu un monitor de servicii TCP și UDP care arată numărul de pachete de intrare și de ieșire pentru porturile comune de aplicație TCP și UDP. Mai mult, un modul de statistici LAN încorporat descoperă gazdele active și arată statistici care arată activitatea lor de date. În cele din urmă, instrumentul are, de asemenea, filtre de afișare TCP, UDP și alte protocole, permițându-vă să vizualizați numai traficul care vă interesează.
Instrumentul care are o operație pe ecran complet, condusă de meniu, va gestiona majoritatea tipurilor de interfețe de rețea și folosește interfața socket brută încorporată a nucleului Linux. Acest lucru îi permite să fie utilizat pe o gamă largă de plăci de rețea acceptate.
5. Nagios
Nagios este diferit de instrumentele anterioare prin faptul că este o soluție completă de monitorizare a rețelei, mai degrabă decât un instrument de testare sau evaluare a performanței. Este disponibil în două versiuni diferite, Nagios Core gratuit și open-source și Nagios XI plătit. Ambele au același motor de bază, dar asemănarea se oprește aici. Nagios Core este un sistem de monitorizare open-source care rulează pe Linux. Sistemul este complet modular cu motorul de monitorizare propriu-zis în centrul său. Motorul este completat de zeci de pluginuri disponibile care pot fi descărcate pentru a adăuga funcționalitate sistemului. Fiecare plugin adaugă câteva caracteristici la bază.
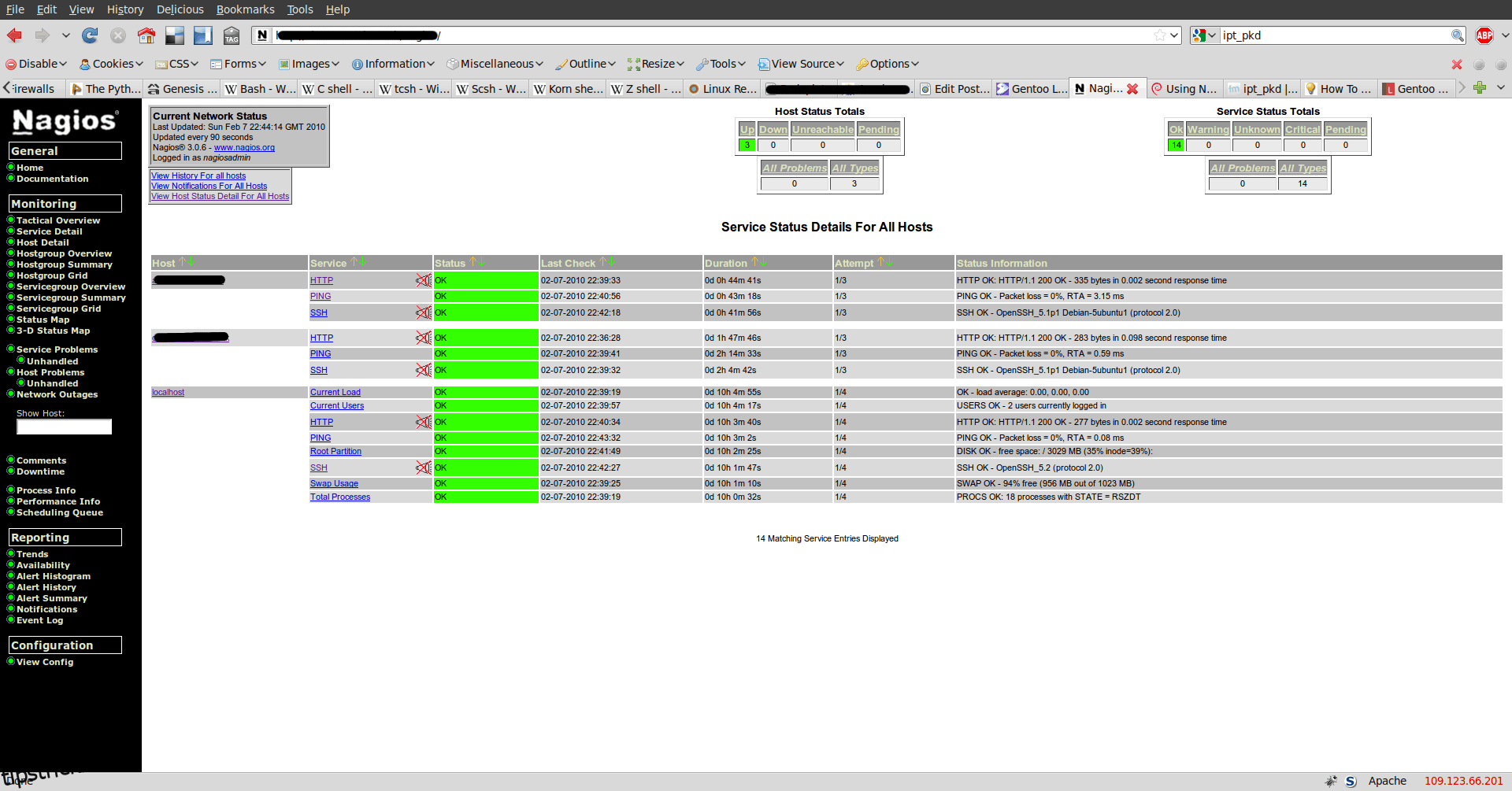
Păstrând această abordare modulară, interfața de utilizator a instrumentului este, de asemenea, modulară și mai multe opțiuni diferite dezvoltate de comunitate sunt, de asemenea, disponibile pentru descărcare. Nucleul Nagios, pluginurile și interfața cu utilizatorul se combină pentru a crea un sistem complet de monitorizare. Acest lucru, desigur, poate însemna că configurarea Nagios Core nu este pentru cei slabi de inimă.
În ceea ce privește Nagios XI, este un produs comercial bazat pe același motor de bază. Este, totuși, o soluție completă de monitorizare autonomă. Nu este nevoie să-l asamblați din diverse părți. Produsul vizează un public larg, de la întreprinderi mici până la corporații mari. După cum ați fi ghicit, este mult mai simplu de instalat și configurat decât Nagios Core, datorită parțial unui expert de configurare și unui motor de auto-descoperire. Principalul dezavantaj al lui Nagios XI este prețul său, care începe de la aproximativ 2 000 USD pentru o licență cu 100 de noduri.
CITURI LEGATE: SolarWinds NPM vs Nagios
6. Observium
Observium este o altă platformă de monitorizare atotcuprinzătoare. Acceptă o gamă largă de tipuri de dispozitive, platforme și sisteme de operare, inclusiv, printre altele, Cisco, Windows, Linux, HP, Juniper, Dell, FreeBSD, Brocade, Netscaler, NetApp. Mă îndoiesc că puteți găsi un dispozitiv conectat la rețea care nu este acceptat. Obiectivul principal al instrumentului este să ofere o interfață de utilizator frumoasă, intuitivă și simplă, dar puternică, care ilustrează vizual starea de sănătate și starea rețelei dvs.
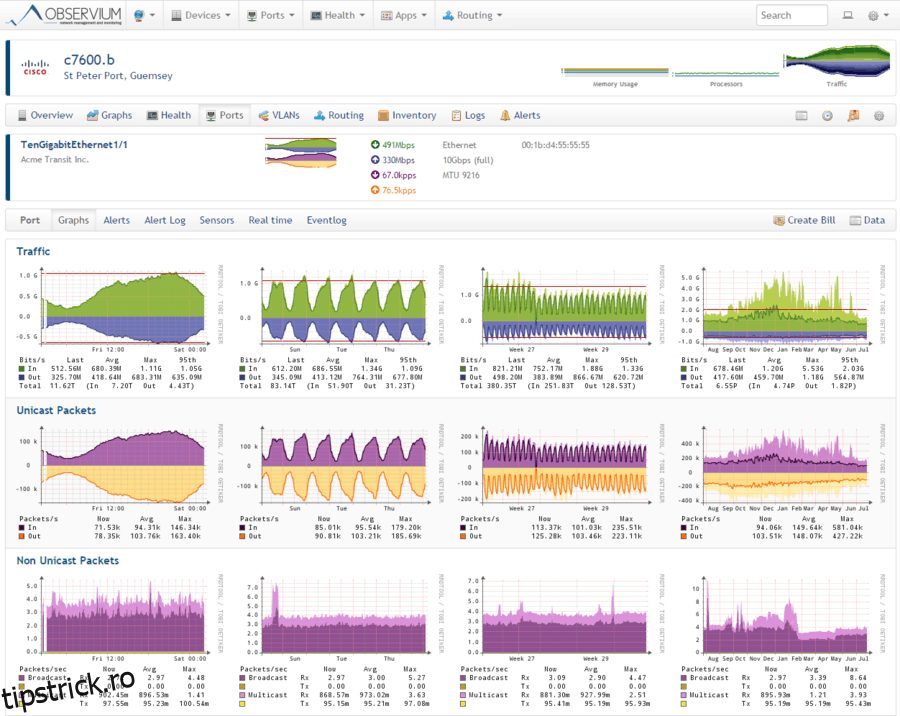
Deși mulți cred că Observium este un instrument de monitorizare a lățimii de bandă, acesta are mult mai multe de oferit. De exemplu, are un sistem de contabilitate care va măsura utilizarea totală lunară a lățimii de bandă în percentila 95 sau în totalul octeților transferați. De asemenea, are o funcție de alertă cu praguri definite de utilizator. În plus, Observium se integrează cu alte sisteme și le poate extrage informațiile și le poate afișa în interfața sa.
Observium este de configurat și aproape se configurează prin procesul său de auto-descoperire. Deși nu pare să existe o secțiune de descărcare pe site-ul Observium, există instrucțiuni detaliate de instalare pentru mai multe distribuții Linux care includ link-uri pentru a obține pachetul potrivit pentru fiecare distribuție. Instrucțiunile sunt foarte detaliate, așa că găsirea și instalarea software-ului ar trebui să fie ușoară.
Acest produs este disponibil în două versiuni. Există Comunitatea Observium, care este disponibilă gratuit pentru toată lumea. Această versiune primește actualizări și funcții noi de două ori pe an. Există și Observium Professional care are funcții suplimentare și vine cu actualizări zilnice.
7. Icinga
Icinga este încă o altă platformă de monitorizare a rețelei open-source. Instrumentul este prevăzut cu o interfață de utilizator simplă și curată și un set de caracteristici care rivalizează cu unele produse comerciale. La fel ca majoritatea sistemelor de monitorizare a lățimii de bandă, Icinga utilizează în principal SNMP pentru a colecta date de utilizare de pe dispozitive. Cu toate acestea, unul dintre domeniile în care instrumentul iese în evidență este în utilizarea pluginurilor. Există o mulțime de pluginuri dezvoltate de comunitate pentru a efectua diverse sarcini de monitorizare a performanței și pentru a extinde funcționalitatea produsului. Și dacă nu găsiți pluginul potrivit pentru nevoile dvs., puteți să scrieți unul singur și să contribuiți la comunitate.
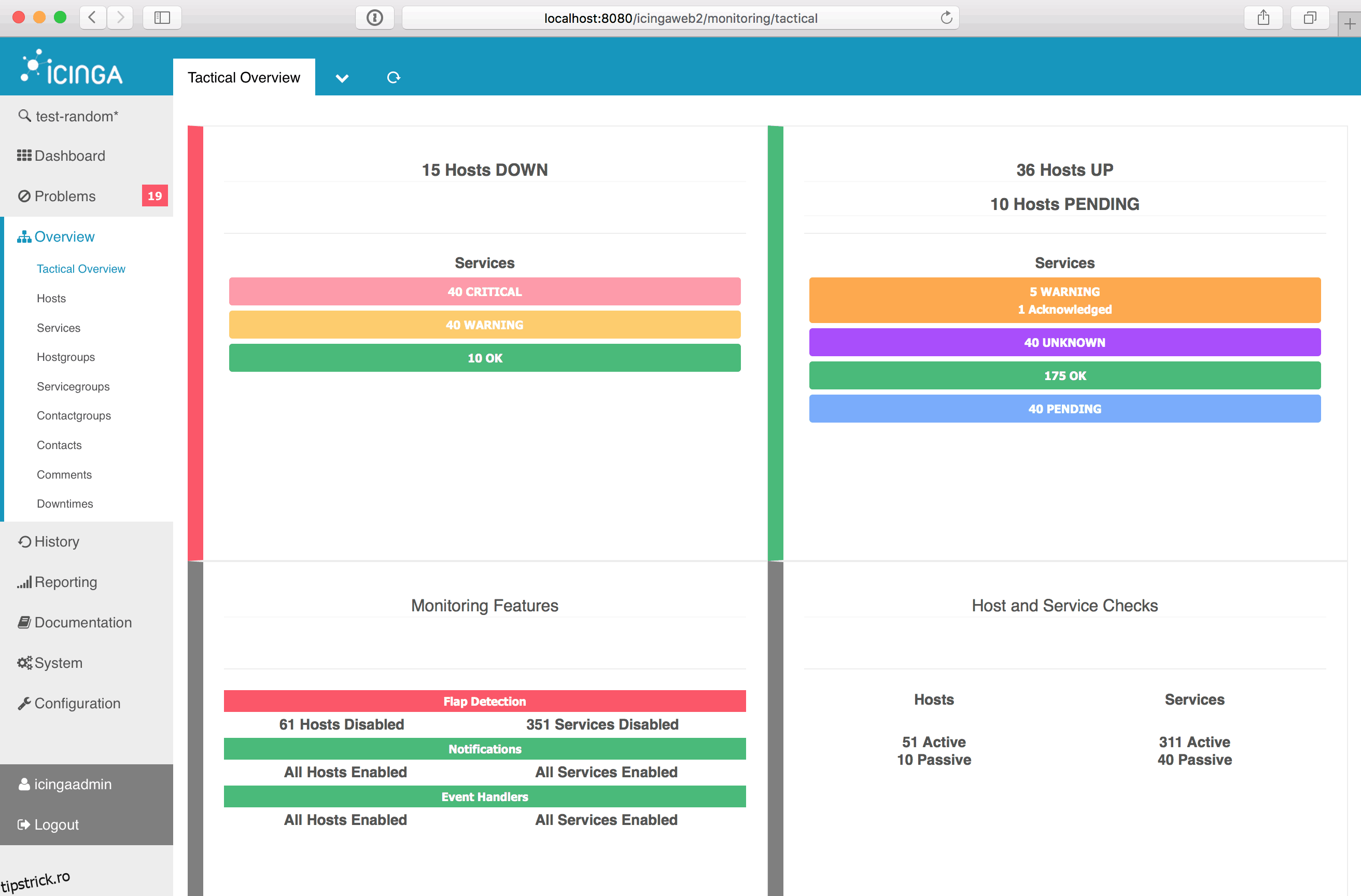
Alertarea și notificarea sunt două dintre cele mai bune caracteristici ale Icinga. Alertele sunt complet configurabile în ceea ce privește ceea ce le declanșează și modul în care sunt transmise. Instrumentul oferă, de asemenea, alerte segmentate. Cu această caracteristică, puteți trimite unele alerte unor utilizatori și alte alerte către diferite persoane. Aceasta este o caracteristică excelentă atunci când aveți sisteme diferite gestionate de grupuri diferite. S-ar putea, de exemplu, să trimiteți toate alertele legate de server către echipa de administrare a serverului și toate alertele legate de rețea trimise echipei de asistență a rețelei.
8. Zabbix
Zabbix este un alt instrument gratuit și open-source de monitorizare a performanței rețelei. Are un aspect și o senzație extrem de profesională, așa cum v-ați aștepta de la un produs comercial. Cu toate acestea, aspectul bun al interfeței sale cu utilizatorul nu este singurul său atu. Produsul are, de asemenea, un set de caracteristici impresionant. Platforma poate monitoriza majoritatea dispozitivelor atașate la rețea, pe lângă echipamentele de rețea. Este o opțiune perfectă pentru monitorizarea performanței întregii infrastructuri.
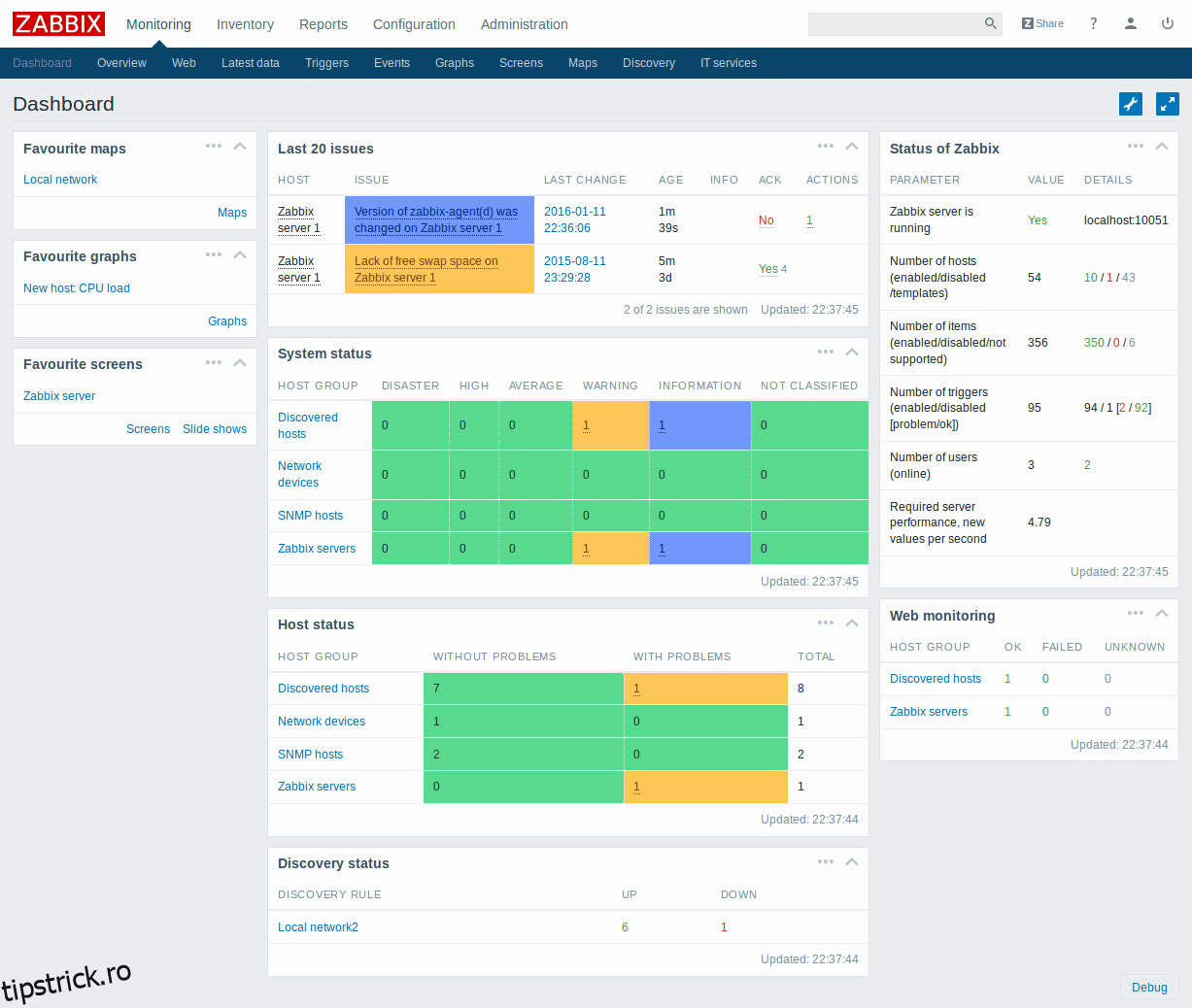
Zabbix folosește SNMP, precum și interfața inteligentă de monitorizare a platformei (IMPI) pentru monitorizarea dispozitivelor. Puteți utiliza software-ul pentru a monitoriza lățimea de bandă, CPU-ul dispozitivului și utilizarea memoriei, starea generală de sănătate și performanța dispozitivului, precum și modificările configurației. Produsul are, de asemenea, un sistem de alertă impresionant și complet personalizabil. Nu numai că va trimite alerte prin e-mail sau SMS, dar poate rula și scripturi locale care ar putea fi folosite, de exemplu, pentru a remedia automat unele probleme.
9. Cactusi
O postare despre instrumentele de performanță a rețelei Linux nu ar fi completă fără mențiunea Cacti, un instrument complet gratuit și open-source de monitorizare a performanței rețelei. Există de vreo cincisprezece ani și, deși s-ar putea să nu fie cel mai sofisticat dintre instrumente, este încă dezvoltat activ – cu cea mai recentă versiune veche de doar o lună – și își face treaba destul de eficient. Componentele sale principale sunt un sondaj rapid, șabloane de grafice avansate și metode multiple de achiziție de date. Cacti dispune de control al accesului utilizatorului integrat chiar în produs, iar produsul se mândrește, de asemenea, cu o interfață de utilizator bazată pe web, ușor de utilizat, deși cu aspect antic. Instrumentul se scalează foarte bine de la cele mai mici instalări cu un singur dispozitiv până la rețele complexe cu multe site-uri WAN diferite.
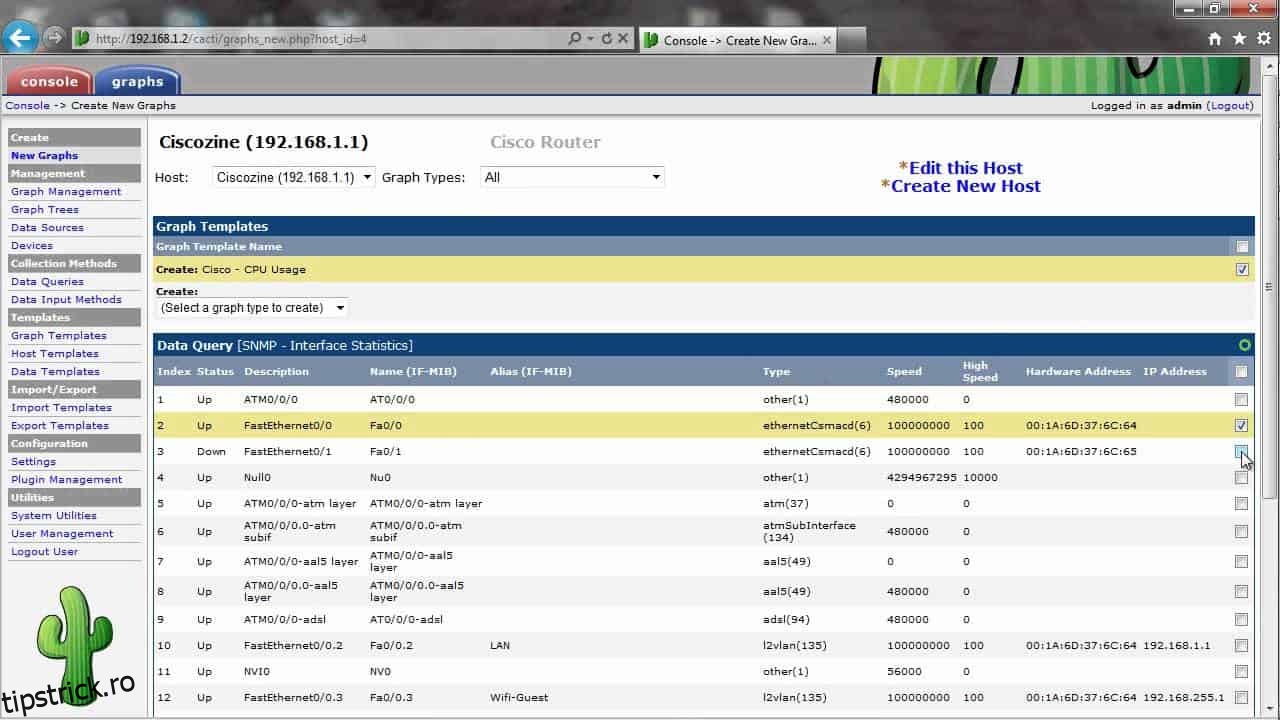
Cacti, care, în esență, este un front end pentru RRDtools, folosește SNMP pentru a prelua datele pe care le stochează într-o bază de date SQL. Este scris în PHP și poate fi modificat pentru a se potrivi nevoilor dumneavoastră. Una dintre cele mai puternice caracteristici ale produsului este utilizarea de șabloane. Există șabloane încorporate, de exemplu, pentru routerele Cisco care includ deja majoritatea elementelor pe care ați putea dori să le monitorizați pe astfel de dispozitive. Dar nu există doar șabloane de dispozitive, există și șabloane de grafice. Împreună, șabloanele facilitează mult configurarea software-ului. Puteți, de asemenea, să vă creați propriile șabloane personalizate, dacă cele potrivite nu sunt deja disponibile. De asemenea, multe șabloane specifice dispozitivului pot fi descărcate de pe site-urile web ale furnizorilor de dispozitive și mai multe forumuri Cacti conduse de comunitate le oferă pentru descărcare.
10. Munin
Munin este încă un alt front-end GUI pentru RRDtools, este scris în Perl și este licențiat sub GPL. Este un instrument bun de utilizat pentru a monitoriza performanța rețelelor, sistemelor, aplicațiilor și serviciilor. Funcționează pe toate sistemele de operare asemănătoare Unix și dispune de un sistem excelent de pluginuri cu aproximativ 500 de plugin-uri diferite disponibile pentru a monitoriza aproape orice doriți în rețeaua dvs.
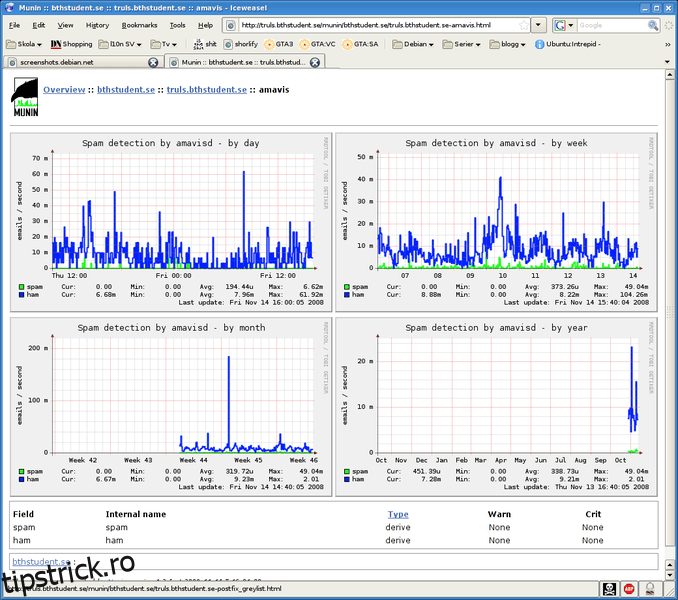
Munin prezintă toate informațiile pe care le adună în grafice pe o interfață web, dar principalul său punct forte este modul în care se bazează pe analiza comparativă pentru a încerca să identifice ce s-a schimbat pentru a provoca o degradare a performanței. Un sistem de notificări este disponibil pentru a trimite mesaje administratorului atunci când apare o eroare sau când eroarea este rezolvată.