Tehnici de optimizare a performanței sistemelor la scară largă
Fragmentarea bazelor de date reprezintă o strategie cheie pentru a obține scalabilitate orizontală în sistemele de mari dimensiuni. În practică, majoritatea sistemelor includ un server de baze de date care procesează un volum mare de solicitări de citire și un număr considerabil de solicitări de scriere. Această situație poate duce la supraîncărcarea serverului și la deteriorarea performanțelor sistemului.
Pentru a contracara aceste probleme și a spori eficiența sistemului, se utilizează diverse metode, printre care replicarea bazelor de date și fragmentarea. În acest material, vom analiza în detaliu diverse tehnici de îmbunătățire a performanței sistemului, inclusiv:
- Extinderea serverului de baze de date
- Replicarea bazei de date
- Partiționarea orizontală
După analiza acestor strategii, vom aprofunda înțelegerea modului în care funcționează fragmentarea bazei de date și vom evalua avantajele și dezavantajele acestei abordări.
Să începem explorarea!
Tehnici de îmbunătățire a performanței sistemului
Să discutăm despre metodele de îmbunătățire a performanței sistemului, în special când serverul de baze de date devine un blocaj:
1. Extinderea serverului de baze de date
Un mod aparent simplu de a îmbunătăți performanța sistemului este extinderea capacității serverului de baze de date. Aceasta implică creșterea puterii de calcul, adăugarea de memorie RAM suplimentară și alte îmbunătățiri similare.
Cu toate acestea, această abordare vine cu o limitare fundamentală. Nu se poate avea un server cu capacități infinite de stocare și procesare. Dincolo de un anumit punct, beneficiile aduse de creșterea resurselor scad.
2. Replicarea bazei de date
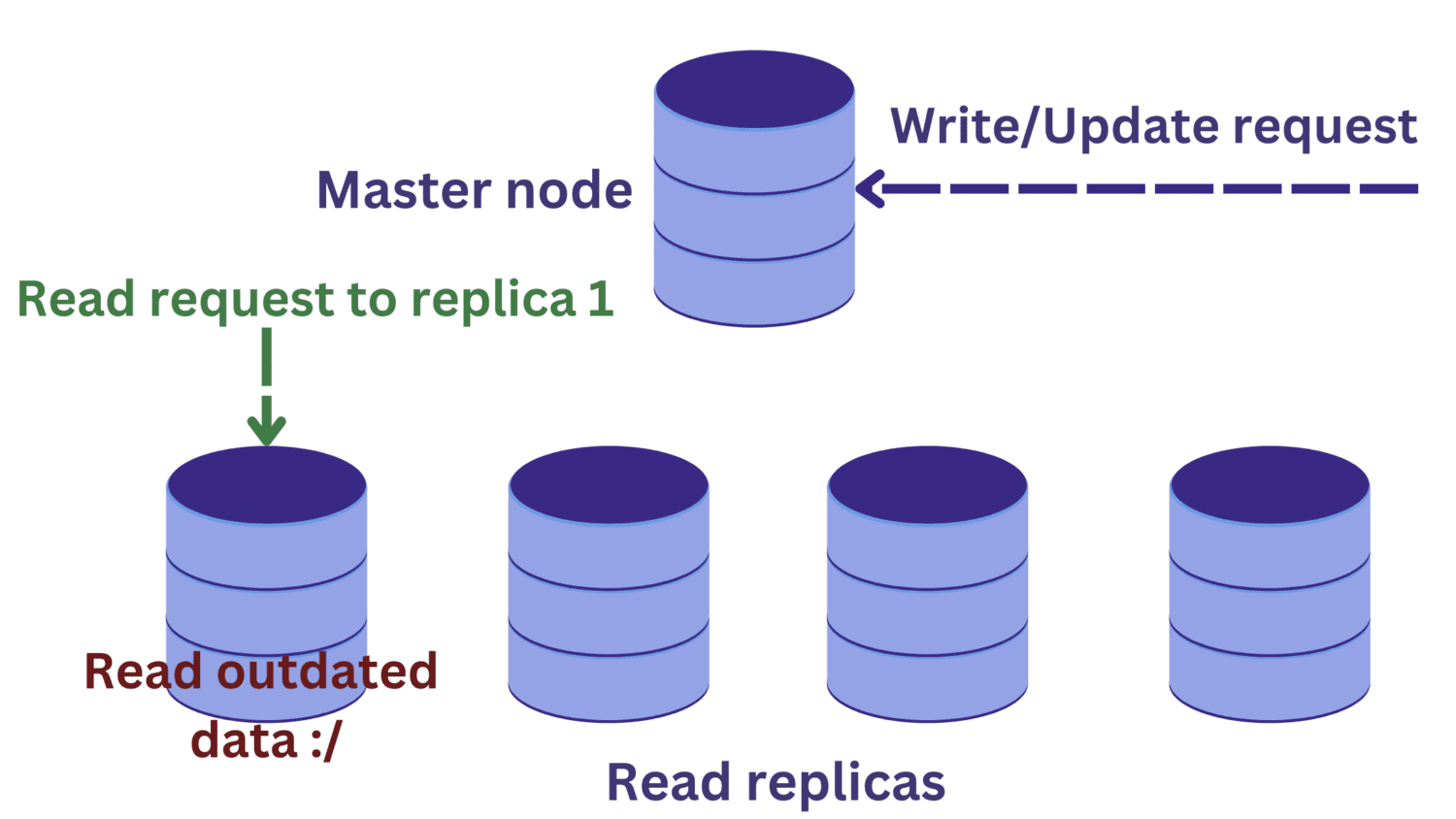
Când un server de baze de date este suprasolicitat datorită numărului mare de solicitări primite, replicarea bazei de date este o strategie eficientă.
Replicarea presupune un nod principal, care gestionează în general operațiunile de scriere, și mai multe replici de citire.
Această abordare îmbunătățește disponibilitatea și reduce supraîncărcarea sistemului. Acum, este posibil să se proceseze mai multe interogări în paralel, deoarece solicitările de citire pot fi direcționate către una dintre replicile disponibile.
Totuși, această metodă introduce o nouă provocare. Solicitările de scriere către nodul principal modifică datele, iar aceste modificări sunt transmise periodic replicilor de citire.
Dacă o solicitare de citire către o replică are loc concomitent cu o operațiune de scriere la nodul principal, este posibil ca modificările să nu fi fost încă propagate la replicile de citire. În acest scenariu, se pot citi date învechite, ceea ce nu este dezirabil.
3. Partiționarea orizontală
Partiționarea orizontală reprezintă o altă tehnică de optimizare a performanțelor sistemului. Este posibil să avem un tabel foarte mare cu miliarde de înregistrări (de exemplu, un tabel cu detalii despre clienți și tranzacții).
Operațiile de citire dintr-un asemenea tabel pot fi lente. Prin utilizarea partiționării orizontale, un singur tabel mare este divizat în mai multe partiții (sau tabele mai mici), din care se pot realiza citirile. Bazele de date relaționale, cum ar fi PostgreSQL, oferă suport nativ pentru partiționare.
Totuși, toate partițiile se află tot în cadrul unei singure instanțe a serverului de baze de date. Diferența constă în faptul că acum se poate citi din partiții, în loc de un singur tabel mare.
În consecință, dacă numărul de solicitări primite crește, serverul ar putea fi depășit de volumul mare de lucru.
Cum funcționează fragmentarea bazei de date?
Acum, după ce am analizat metodele de îmbunătățire a performanței sistemului și limitele acestora, vom explora modul în care funcționează fragmentarea bazei de date.
Prin sharding, o bază de date mare este împărțită în mai multe baze de date mai mici, fiecare rulând pe o instanță separată a serverului. Fiecare bază de date mai mică se numește shard, iar fiecare fragment conține un subset distinct de date.
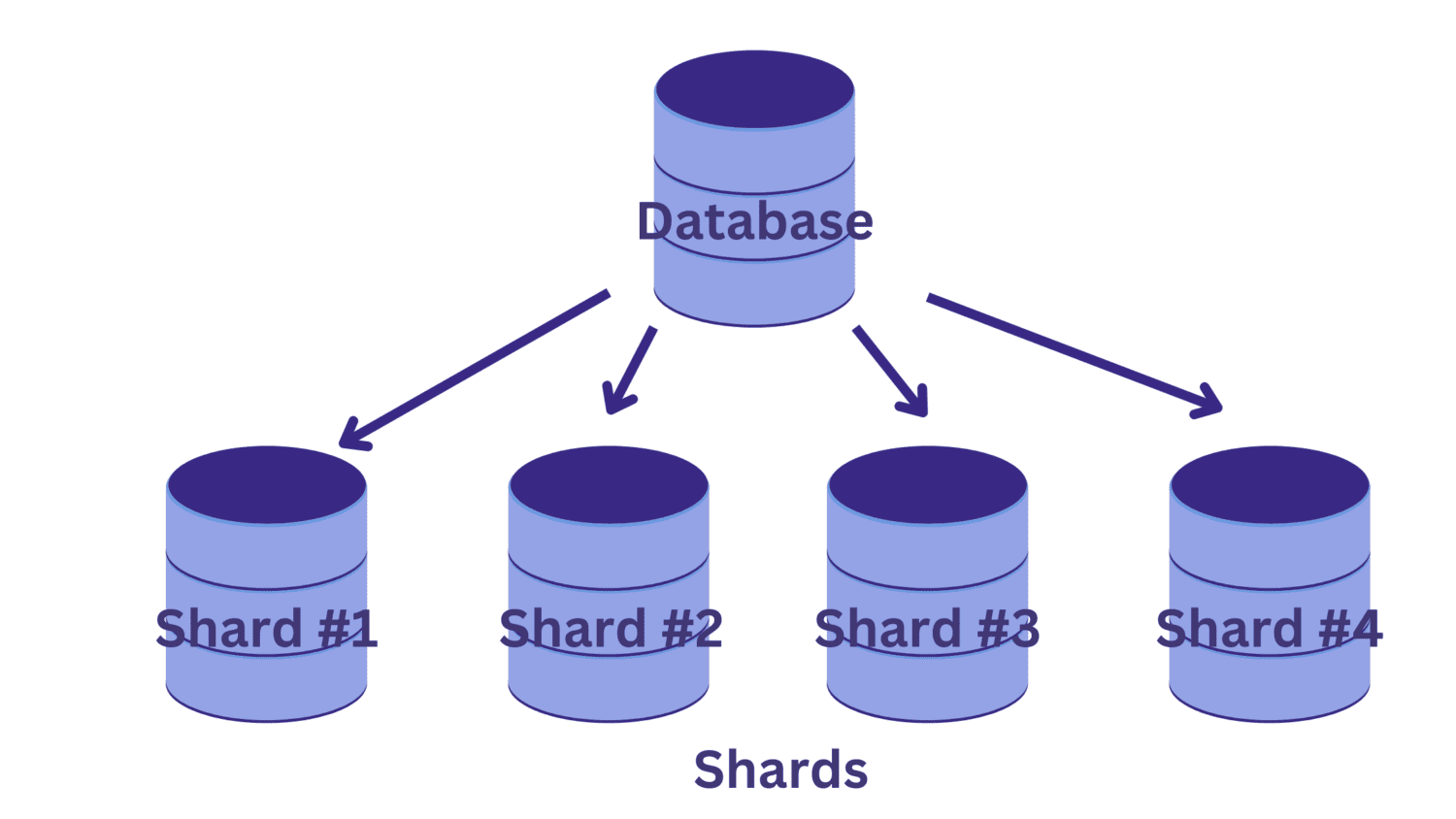
Dar cum se împarte baza de date în fragmente? Și cum se stabilește care înregistrări sunt alocate fiecărui fragment?
🔑 Aici intervine cheia de fragmentare.
Înțelegerea cheii de fragmentare
Să analizăm rolul cheii de fragmentare.
Cheia de fragmentare, reprezentată de obicei de o coloană (sau o combinație de coloane) din tabelul bazei de date, trebuie selectată astfel încât datele să fie distribuite uniform între fragmente. Se evită, astfel, situația în care un anumit fragment devine mult mai mare decât celelalte.
Într-o bază de date care stochează informații despre clienți și tranzacții, client_ID este un candidat bun pentru cheia de fragmentare.
Odată stabilită cheia de fragmentare, se poate defini o funcție de hash care să determine alocarea înregistrărilor la fragmentele corespunzătoare.
Să presupunem că baza de date trebuie divizată în cinci fragmente (de la fragmentul #0 la fragmentul #4), folosind client_ID ca cheie de fragmentare. O funcție simplă de hash în acest caz ar fi customer_ID % 5.
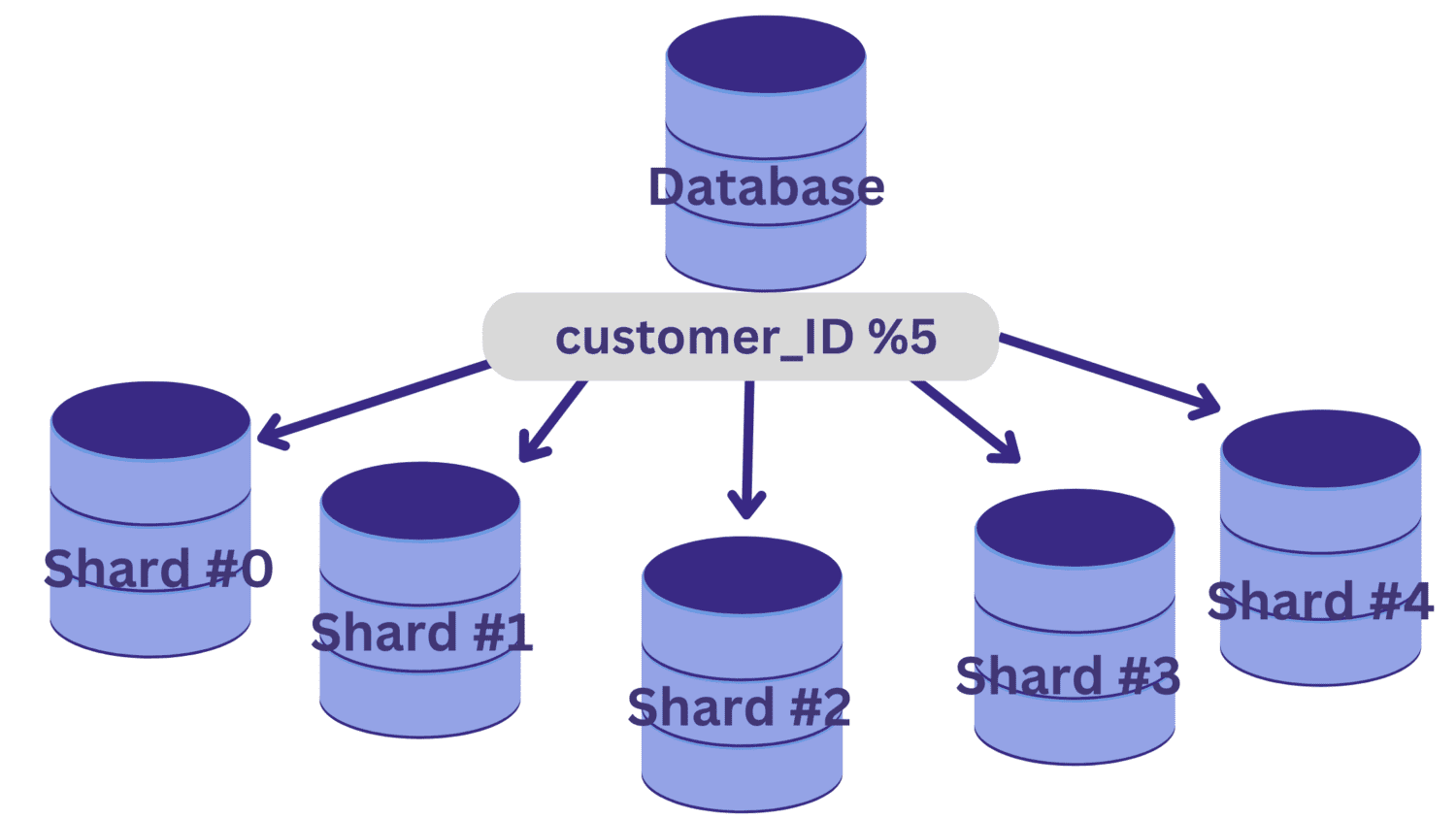
Toate valorile customer_ID care dau restul zero la împărțirea cu 5 vor fi alocate fragmentului #0. Valorile care dau resturi de la 1 la 4 vor fi alocate fragmentelor #1 până la #4, respectiv.
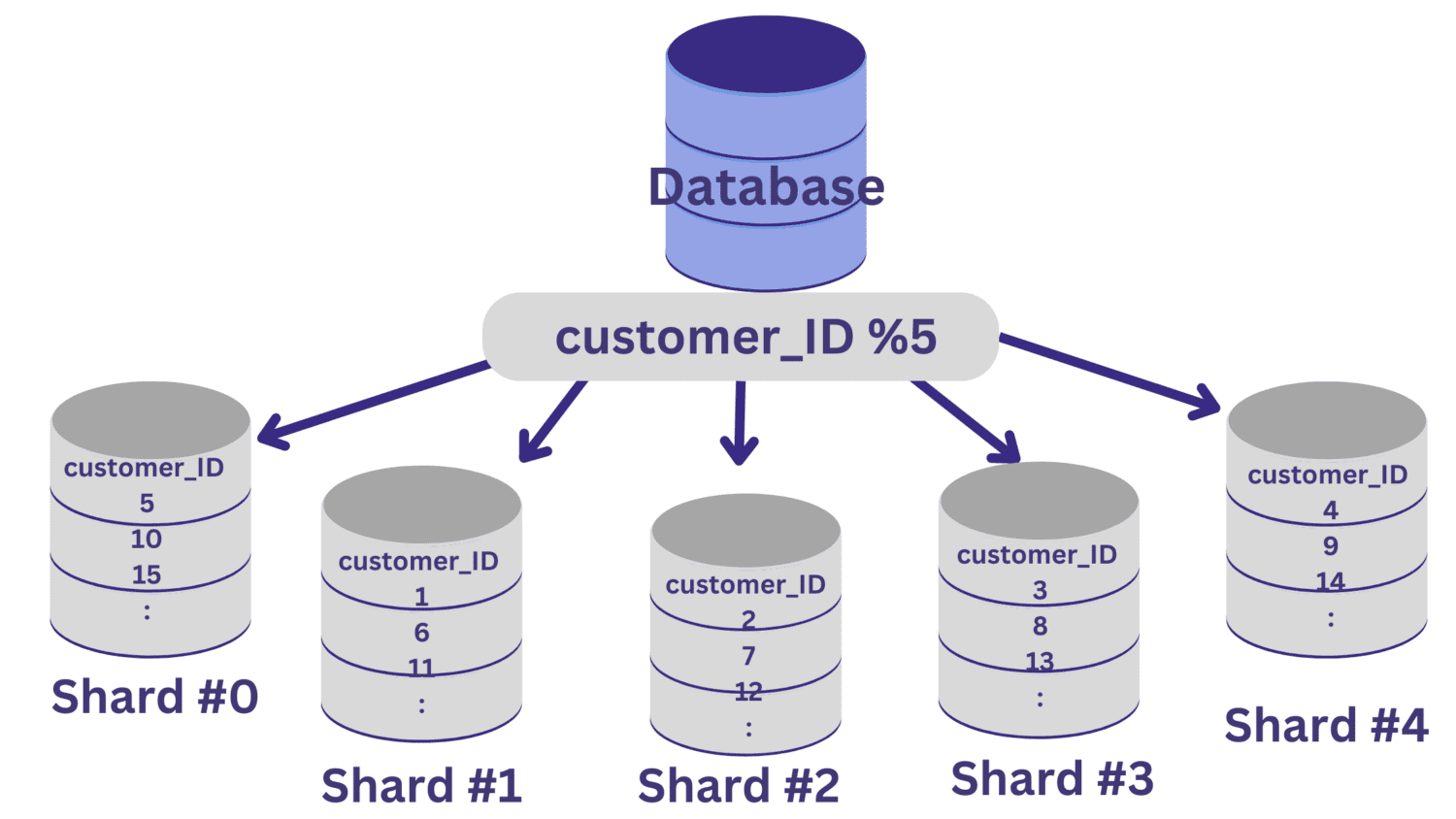
Odată implementată fragmentarea, este esențial un strat de rutare, care direcționează solicitările primite către fragmentul corect al bazei de date.
Avantajele fragmentării bazei de date
Iată câteva dintre avantajele fragmentării bazei de date:
1. Scalabilitate ridicată
O bază de date mare poate fi fragmentată în mai multe fragmente de dimensiuni mai mici. Fragmentarea facilitează scalarea orizontală.
2. Disponibilitate ridicată
Când o singură instanță a serverului gestionează toate solicitările, se creează un punct unic de eșec. Dacă serverul devine indisponibil, întreaga aplicație este oprită.
Prin fragmentarea bazei de date, riscul ca toate fragmentele să fie indisponibile simultan este redus considerabil. În situația în care un anumit fragment nu este disponibil, solicitările de citire către acel fragment nu vor putea fi procesate. Totuși, celelalte fragmente vor continua să proceseze cererile. Aceasta contribuie la o disponibilitate ridicată și la o toleranță sporită la erori.
Limitări ale fragmentării bazei de date
Să analizăm acum câteva limitări ale fragmentării bazelor de date:
1. Complexitate
Deși fragmentarea are avantaje în ceea ce privește scalabilitatea și toleranța la erori, aceasta introduce complexitate în sistem.
De la maparea înregistrărilor la partiții, până la implementarea stratului de rutare și direcționarea interogărilor către fragmentele corespunzătoare, implementarea fragmentării bazei de date presupune o complexitate considerabilă.
2. Refragmentarea
O altă limitare este necesitatea de refragmentare.
Deși se utilizează o funcție de hash pentru a asigura o distribuție uniformă a înregistrărilor, este posibil ca un fragment să devină mult mai mare decât celelalte și să se ocupe mai repede. În acest caz, este necesară refragmentarea, o operațiune complexă și costisitoare.
3. Rularea de interogări complexe
Executarea interogărilor complexe, care implică îmbinări și date din mai multe fragmente, poate fi mai dificilă în comparație cu interogările dintr-o singură bază de date. Aceasta poate fi o provocare în cazul interogărilor analitice complexe. Denormalizarea bazelor de date poate ocoli problema, dar necesită efort suplimentar.
Concluzie
Să recapitulăm aspectele esențiale discutate.
Extinderea hardware-ului nu este întotdeauna soluția optimă. De aceea, nu este recomandată extinderea instanței serverului. De asemenea, am analizat tehnici cum ar fi replicarea și partiționarea orizontală și limitele lor.
Apoi, am explorat cum funcționează fragmentarea bazei de date, prin divizarea unei baze de date mari în fragmente mai mici și mai ușor de gestionat. Am analizat importanța alegerii atente a cheii de fragmentare pentru obținerea unor partiții echilibrate, și necesitatea unui strat de rutare pentru a direcționa cererile către fragmentul corect.
Fragmentarea bazei de date oferă beneficii precum disponibilitatea ridicată și scalabilitatea. Unele dezavantaje includ complexitatea configurării fragmentării și a refragmentării când unul sau mai multe fragmente devin pline.
Prin urmare, fragmentarea este o soluție potrivită atunci când avantajele depășesc complexitatea implementării. În continuare, este util să analizați comparativ diferitele baze de date relaționale AWS.