
În domeniul inteligenței artificiale moderne (AI), învățarea prin consolidare (RL) este unul dintre cele mai tari subiecte de cercetare. Dezvoltatorii AI și învățarea automată (ML) se concentrează, de asemenea, pe practicile RL pentru a improviza aplicații sau instrumente inteligente pe care le dezvoltă.
Învățarea automată este principiul din spatele tuturor produselor AI. Dezvoltatorii umani folosesc diverse metodologii ML pentru a-și antrena aplicațiile inteligente, jocurile etc. ML este un domeniu foarte diversificat, iar diferite echipe de dezvoltare vin cu metode noi de antrenare a unei mașini.
O astfel de metodă profitabilă de ML este învățarea prin consolidare profundă. Aici, pedepsiți comportamentele nedorite ale mașinii și recompensați acțiunile dorite de la mașina inteligentă. Experții consideră că această metodă de ML va împinge AI să învețe din propriile experiențe.
Continuați să citiți acest ghid suprem despre metodele de învățare prin consolidare pentru aplicații și mașini inteligente dacă vă gândiți la o carieră în inteligența artificială și învățarea automată.
Cuprins
Ce este învățarea prin consolidare în învățarea automată?
RL este predarea modelelor de învățare automată pentru programe de calculator. Apoi, aplicația poate lua o secvență de decizii pe baza modelelor de învățare. Software-ul învață să atingă un obiectiv într-un mediu potențial complex și incert. În acest tip de model de învățare automată, un AI se confruntă cu un scenariu asemănător unui joc.
Aplicația AI utilizează încercări și erori pentru a inventa o soluție creativă pentru problema în cauză. Odată ce aplicația AI învață modelele ML adecvate, instruiește mașina pe care o controlează să facă unele sarcini pe care le dorește programatorul.
Pe baza deciziei corecte și a îndeplinirii sarcinii, AI primește o recompensă. Cu toate acestea, dacă AI face alegeri greșite, se confruntă cu penalități, cum ar fi pierderea punctelor de recompensă. Scopul final al aplicației AI este de a acumula numărul maxim de puncte recompensă pentru a câștiga jocul.
Programatorul aplicației AI stabilește regulile jocului sau politica de recompense. Programatorul oferă, de asemenea, problema pe care AI trebuie să o rezolve. Spre deosebire de alte modele ML, programul AI nu primește niciun indiciu de la programatorul software.
AI trebuie să descopere cum să rezolve provocările jocului pentru a câștiga recompense maxime. Aplicația poate folosi încercări și erori, încercări aleatorii, abilități de supercomputer și tactici sofisticate de proces de gândire pentru a ajunge la o soluție.
Trebuie să echipați programul AI cu o infrastructură de calcul puternică și să conectați sistemul său de gândire cu diverse jocuri paralele și istorice. Apoi, AI poate demonstra o creativitate critică și de nivel înalt pe care oamenii nu și-o pot imagina.
Exemple populare de învățare prin întărire
#1. Învingerea celui mai bun jucător Go Human
AlphaGo AI de la DeepMind Technologies, o subsidiară a Google, este unul dintre exemplele principale de învățare automată bazată pe RL. AI joacă un joc de masă chinezesc numit Go. Este un joc vechi de 3.000 de ani care se concentrează pe tactici și strategii.
Programatorii au folosit metoda RL de predare pentru AlphaGo. A jucat mii de sesiuni de jocuri Go cu oameni și cu sine. Apoi, în 2016, l-a învins pe cel mai bun jucător de Go din lume, Lee Se-dol, într-un meci unu-la-unu.
#2. Robotică din lumea reală
Oamenii folosesc robotica de mult timp în liniile de producție în care sarcinile sunt pre-planificate și repetitive. Dar, dacă trebuie să creați un robot de uz general pentru lumea reală în care acțiunile nu sunt planificate în prealabil, atunci este o mare provocare.
Dar, inteligența artificială activată prin învățare de consolidare ar putea descoperi o rută lină, navigabilă și scurtă între două locații.
#3. Vehicule autonome
Cercetătorii de vehicule autonome folosesc pe scară largă metoda RL pentru a-și preda IA pentru:
- Traseul dinamic
- Optimizarea traiectoriei
- Planificarea mișcării, cum ar fi parcarea și schimbarea benzii
- Optimizarea controlerelor, (unitate de control electronică) ECU-uri, (microcontrolere) MCU-uri etc.
- Învățare bazată pe scenarii pe autostrăzi
#4. Sisteme automate de racire

IA bazate pe RL poate ajuta la minimizarea consumului de energie al sistemelor de răcire din clădirile de birouri gigantice, centrele de afaceri, centrele comerciale și, cel mai important, centrele de date. AI colectează date de la mii de senzori de căldură.
De asemenea, colectează date despre activitățile umane și ale mașinilor. Din aceste date, AI poate prevedea potențialul viitor de generare de căldură și pornește și oprește în mod corespunzător sistemele de răcire pentru a economisi energie.
Cum să configurați un model de învățare prin întărire
Puteți configura un model RL pe baza următoarelor metode:
#1. Bazat pe politici
Această abordare permite programatorului AI să găsească politica ideală pentru recompense maxime. Aici, programatorul nu folosește funcția de valoare. Odată ce setați metoda bazată pe politici, agentul de învățare de întărire încearcă să aplice politica, astfel încât acțiunile pe care le efectuează în fiecare pas să permită AI să maximizeze punctele de recompensă.
Există în principal două tipuri de politici:
#1. Determinist: politica poate produce aceleași acțiuni în orice stare dată.
#2. Stochastic: Acțiunile produse sunt determinate de probabilitatea de apariție.
#2. Bazat pe valoare
Abordarea bazată pe valoare, dimpotrivă, ajută programatorul să găsească funcția de valoare optimă, care este valoarea maximă conform unei politici în orice stare dată. Odată aplicat, agentul RL se așteaptă la rentabilitatea pe termen lung în oricare sau mai multe state în conformitate cu politica menționată.
#3. Bazat pe model
În abordarea RL bazată pe model, programatorul AI creează un model virtual pentru mediu. Apoi, agentul RL se mișcă în jurul mediului și învață din acesta.
Tipuri de învățare prin întărire
#1. Învățare prin întărire pozitivă (PRL)
Învățarea pozitivă înseamnă adăugarea unor elemente pentru a crește probabilitatea ca comportamentul așteptat să se repete. Această metodă de învățare influențează pozitiv comportamentul agentului RL. PRL îmbunătățește, de asemenea, puterea anumitor comportamente ale inteligenței tale.
Tipul de consolidare a învățării PRL ar trebui să pregătească IA să se adapteze la schimbări pentru o lungă perioadă de timp. Dar injectarea prea multă învățare pozitivă poate duce la o suprasolicitare a statelor care pot reduce eficiența AI.

#2. Învățare prin întărire negativă (NRL)
Când algoritmul RL ajută AI să evite sau să oprească un comportament negativ, acesta învață din acesta și își îmbunătățește acțiunile viitoare. Este cunoscută ca învățare negativă. Acesta oferă AI doar o inteligență limitată doar pentru a îndeplini anumite cerințe comportamentale.
Cazuri de utilizare în viața reală ale învățării prin întărire
#1. Dezvoltatorii de soluții de comerț electronic au creat instrumente personalizate de sugestie de produse sau servicii. Puteți conecta API-ul instrumentului la site-ul dvs. de cumpărături online. Apoi, AI va învăța de la utilizatorii individuali și va sugera bunuri și servicii personalizate.
#2. Jocurile video open-world vin cu posibilități nelimitate. Cu toate acestea, în spatele programului de joc există un program AI care învață din contribuțiile jucătorilor și modifică codul jocului video pentru a se adapta la o situație necunoscută.
#3. Platformele de tranzacționare și investiții bazate pe IA folosesc modelul RL pentru a învăța din mișcarea acțiunilor și a indicilor globali. În consecință, ei formulează un model de probabilitate pentru a sugera acțiuni pentru investiții sau tranzacționare.
#4. Bibliotecile video online precum YouTube, Metacafe, Dailymotion etc., folosesc roboți AI antrenați pe modelul RL pentru a sugera videoclipuri personalizate utilizatorilor lor.
Învățare prin consolidare vs. Învățare supravegheată
Învățarea prin consolidare are ca scop instruirea agentului AI pentru a lua decizii secvenţial. Pe scurt, puteți considera că ieșirea AI depinde de starea intrării prezente. În mod similar, următoarea intrare în algoritmul RL va depinde de rezultatul intrărilor anterioare.

O mașină robotică bazată pe inteligență artificială care joacă un joc de șah împotriva unui jucător de șah uman este un exemplu al modelului de învățare automată RL.
Dimpotrivă, în învățarea supravegheată, programatorul antrenează agentul AI să ia decizii pe baza intrărilor date la început sau a oricărei alte intrări inițiale. Conducerea autonomă a mașinilor AI care recunoaște obiectele din mediu este un exemplu excelent de învățare supravegheată.
Învățare prin consolidare vs. Învățare nesupravegheată
Până acum, ați înțeles că metoda RL împinge agentul AI să învețe din politicile modelului de învățare automată. În principal, AI-ul va face doar acei pași pentru care primește maximum de puncte de recompensă. RL ajută un AI să se improvizeze prin încercări și erori.
Pe de altă parte, în învățarea nesupravegheată, programatorul AI introduce software-ul AI cu date neetichetate. De asemenea, instructorul ML nu spune nimic AI despre structura datelor sau despre ce să caute în date. Algoritmul învață diferite decizii prin catalogarea propriilor observații pe seturile de date necunoscute date.
Cursuri de învățare de consolidare
Acum că ați învățat elementele de bază, iată câteva cursuri online pentru a învăța învățarea avansată prin întărire. De asemenea, primești un certificat pe care îl poți prezenta pe LinkedIn sau alte platforme sociale:
Specializarea Învățare prin întărire: Coursera
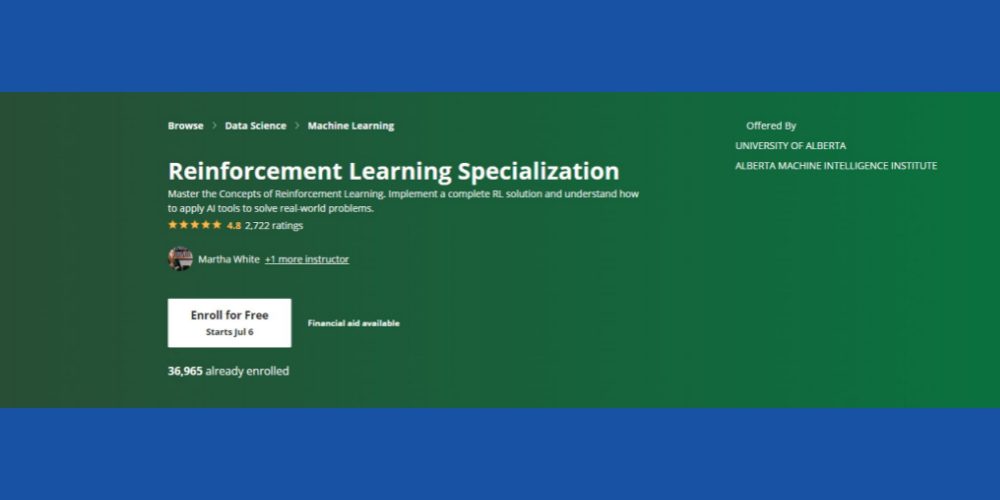
Doriți să stăpâniți conceptele de bază ale învățării prin consolidare cu context ML? Puteți încerca asta Curs Coursera RL care este disponibil online și vine cu o opțiune de învățare și certificare în ritm propriu. Cursul vă va fi potrivit dacă aduceți următoarele abilități de bază:
- Cunoștințe de programare în Python
- Concepte statistice de bază
- Puteți converti pseudocoduri și algoritmi în coduri Python
- Experiență în dezvoltare software de doi până la trei ani
- Sunt eligibili și studenții din anul II la disciplina informatică
Cursul are un rating de 4,8 stele, iar peste 36 de mii de studenți s-au înscris deja la curs în diferite cursuri de timp. În plus, cursul vine cu ajutor financiar, cu condiția ca candidatul să îndeplinească anumite criterii de eligibilitate ale Coursera.
În cele din urmă, Alberta Machine Intelligence Institute de la Universitatea din Alberta oferă acest curs (nu se acordă credit). Profesori stimați din domeniul informaticii vor funcționa ca instructori de curs. Veți obține un certificat Coursera la finalizarea cursului.
Învățare pentru consolidarea AI în Python: Udemy
Dacă sunteți interesat de piața financiară sau de marketing digital și doriți să dezvoltați pachete software inteligente pentru domeniile menționate, trebuie să consultați acest Curs Udemy pe RL. Pe lângă principiile de bază ale RL, conținutul de instruire vă va îndruma și despre cum să dezvoltați soluții RL pentru publicitate online și tranzacționare cu acțiuni.

Câteva subiecte notabile pe care le acoperă cursul sunt:
- O prezentare generală la nivel înalt a RL
- Programare dinamică
- Monet Carlo
- Metode de aproximare
- Proiect de tranzacționare cu acțiuni cu RL
Peste 42 de mii de studenți au participat până acum la curs. Resursa de învățare online deține în prezent o evaluare de 4,6 stele, ceea ce este destul de impresionant. Mai mult, cursul își propune să răspundă unei comunități studențești globale, deoarece conținutul de învățare este disponibil în franceză, engleză, spaniolă, germană, italiană și portugheză.
Învățare prin consolidare profundă în Python: Udemy
Dacă aveți curiozitate și cunoștințe de bază despre învățarea profundă și inteligența artificială, puteți încerca acest lucru avansat Curs RL în Python de la Udemy. Cu o evaluare de 4,6 stele din partea studenților, este încă un alt curs popular pentru a învăța RL în contextul AI/ML.

Cursul are 12 secțiuni și acoperă următoarele subiecte vitale:
- OpenAI Gym și tehnici de bază RL
- TD Lambda
- A3C
- Bazele Theano
- Bazele Tensorflow
- Codare Python pentru început
Întregul curs va necesita o investiție de 10 ore și 40 de minute. În afară de texte, vine și cu 79 de sesiuni de prelegeri experți.
Expert în învățare prin consolidare profundă: Udacity
Vrei să înveți învățarea automată avansată de la liderii mondiali în AI/ML, cum ar fi Nvidia Deep Learning Institute și Unity? Udacity vă permite să vă îndepliniți visul. Verifica asta Învățare prin consolidare profundă curs pentru a deveni un expert ML.

Cu toate acestea, trebuie să proveniți dintr-un mediu avansat de Python, statistici intermediare, teoria probabilității, TensorFlow, PyTorch și Keras.
Va fi nevoie de o învățare diligentă de până la 4 luni pentru a finaliza cursul. Pe parcursul cursului, veți învăța algoritmi vitali RL, cum ar fi Deep Deterministic Policy Gradients (DDPG), Deep Q-Networks (DQN) etc.
Cuvinte finale
Învățarea prin consolidare este următorul pas în dezvoltarea AI. Agențiile de dezvoltare AI și companiile IT investesc în acest sector pentru a crea metodologii de formare AI fiabile și de încredere.
Deși RL a avansat mult, există mai multe domenii de dezvoltare. De exemplu, agenții RL separați nu împărtășesc cunoștințele între ei. Prin urmare, dacă antrenați o aplicație pentru a conduce o mașină, procesul de învățare va deveni lent. Deoarece agenții RL, cum ar fi detectarea obiectelor, referințele rutiere etc., nu vor partaja date.
Există oportunități de a vă investi creativitatea și experiența ML în astfel de provocări. Înscrierea la cursuri online vă va ajuta să vă îmbunătățiți cunoștințele despre metodele avansate RL și despre aplicațiile acestora în proiecte din lumea reală.
O altă învățare legată pentru tine este diferențele dintre AI, Machine Learning și Deep Learning.