

Big O Analysis este o tehnică pentru analizarea și clasarea eficienței algoritmilor.
Acest lucru vă permite să alegeți cei mai eficienți și scalabili algoritmi. Acest articol este un Big O Cheat Sheet care explică tot ce trebuie să știți despre Big O Notation.
Cuprins
Ce este analiza Big O?
Big O Analysis este o tehnică pentru analizarea gradului de scalare a algoritmilor. Mai exact, întrebăm cât de eficient este un algoritm pe măsură ce dimensiunea intrării crește.
Eficiența este cât de bine sunt utilizate resursele sistemului în timpul producerii unui rezultat. Resursele care ne preocupă în primul rând sunt timpul și memoria.
Prin urmare, atunci când efectuăm analiza Big O, întrebările pe care ni le punem sunt:
Răspunsul la prima întrebare este complexitatea spațială a algoritmului, în timp ce răspunsul la a doua este complexitatea sa în timp. Folosim o notație specială numită Big O Notation pentru a exprima răspunsurile la ambele întrebări. Acest lucru va fi tratat în continuare în Big O Cheat Sheet.
Cerințe preliminare
Înainte de a merge mai departe, trebuie să spun că pentru a profita la maximum de această fișă Big O Cheat Sheet, trebuie să înțelegeți puțin Algebra. În plus, pentru că voi da exemple Python, este de asemenea util să înțelegem puțin din Python. O înțelegere aprofundată este inutilă, deoarece nu veți scrie niciun cod.
Cum se efectuează analiza Big O
În această secțiune, vom aborda modul de realizare a analizei Big O.
Când efectuați Analiza complexității Big O, este important să rețineți că performanța algoritmului depinde de modul în care sunt structurate datele de intrare.
De exemplu, algoritmii de sortare rulează cel mai rapid atunci când datele din listă sunt deja sortate în ordinea corectă. Acesta este cel mai bun scenariu pentru performanța algoritmului. Pe de altă parte, aceiași algoritmi de sortare sunt mai lenți atunci când datele sunt structurate în ordine inversă. Acesta este cel mai rău scenariu.
Când efectuăm analiza Big O, luăm în considerare doar scenariul cel mai rău.
Analiza complexității spațiale

Să începem această fișă Big O Cheat Sheet, acoperind cum să efectuăm analiza complexității spațiului. Vrem să luăm în considerare modul în care memoria suplimentară folosește un algoritm scalele pe măsură ce intrarea devine din ce în ce mai mare.
De exemplu, funcția de mai jos folosește recursiunea pentru a bucla de la n la zero. Are o complexitate spațială direct proporțională cu n. Acest lucru se datorează faptului că pe măsură ce n crește, la fel crește și numărul de apeluri de funcție din stiva de apeluri. Deci, are o complexitate spațială de O(n).
def loop_recursively(n):
if n == -1:
return
else:
print(n)
loop_recursively(n - 1)
Cu toate acestea, o implementare mai bună ar arăta astfel:
def loop_normally(n):
count = n
while count >= 0:
print(count)
count =- 1
În algoritmul de mai sus, creăm doar o variabilă suplimentară și o folosim pentru a bucla. Dacă n ar crește din ce în ce mai mare, am folosi totuși o singură variabilă suplimentară. Prin urmare, algoritmul are o complexitate spațială constantă, notat cu simbolul „O(1)”.
Comparând complexitatea spațială a celor doi algoritmi de mai sus, am ajuns la concluzia că bucla while a fost mai eficientă decât recursiunea. Acesta este obiectivul principal al Big O Analysis: analizarea modului în care se schimbă algoritmii pe măsură ce îi rulăm cu intrări mai mari.
Analiza complexității timpului

Când efectuăm analiza complexității timpului, nu ne preocupă creșterea în timpul total luat de algoritm. Mai degrabă, suntem preocupați de creșterea pașilor de calcul luați. Acest lucru se datorează faptului că timpul real depinde de mulți factori sistemici și aleatori, care sunt greu de contabilizat. Deci, urmărim doar creșterea pașilor de calcul și presupunem că fiecare pas este egal.
Pentru a ajuta la demonstrarea analizei complexității timpului, luați în considerare următorul exemplu:
Să presupunem că avem o listă de utilizatori în care fiecare utilizator are un ID și un nume. Sarcina noastră este să implementăm o funcție care returnează numele utilizatorului atunci când i se oferă un ID. Iată cum am putea face asta:
users = [
{'id': 0, 'name': 'Alice'},
{'id': 1, 'name': 'Bob'},
{'id': 2, 'name': 'Charlie'},
]
def get_username(id, users):
for user in users:
if user['id'] == id:
return user['name']
return 'User not found'
get_username(1, users)
Având în vedere o listă de utilizatori, algoritmul nostru parcurge întreaga matrice a utilizatorului pentru a găsi utilizatorul cu ID-ul corect. Când avem 3 utilizatori, algoritmul efectuează 3 iterații. Când avem 10, face 10.
Prin urmare, numărul de pași este liniar și direct proporțional cu numărul de utilizatori. Deci, algoritmul nostru are complexitate liniară în timp. Cu toate acestea, putem îmbunătăți algoritmul nostru.
Să presupunem că, în loc să stocăm utilizatorii într-o listă, i-am stocat într-un dicționar. Apoi, algoritmul nostru de căutare a unui utilizator ar arăta astfel:
users = {
'0': 'Alice',
'1': 'Bob',
'2': 'Charlie'
}
def get_username(id, users):
if id in users:
return users[id]
else:
return 'User not found'
get_username(1, users)
Cu acest nou algoritm, să presupunem că avem 3 utilizatori în dicționarul nostru; am efectua mai mulți pași pentru a obține numele de utilizator. Și să presupunem că avem mai mulți utilizatori, să zicem zece. Am efectua același număr de pași ca înainte pentru a obține utilizatorul. Pe măsură ce numărul de utilizatori crește, numărul de pași pentru a obține un nume de utilizator rămâne constant.
Prin urmare, acest nou algoritm are o complexitate constantă. Nu contează câți utilizatori avem; numărul de pași de calcul parcurși este același.
Ce este Big O Notation?
În secțiunea anterioară, am discutat cum să calculăm complexitatea Big O spațiu și timp pentru diferiți algoritmi. Am folosit cuvinte precum liniar și constantă pentru a descrie complexitățile. Un alt mod de a descrie complexitățile este utilizarea Big O Notation.
Notația Big O este o modalitate de a reprezenta complexitățile spațiale sau temporale ale unui algoritm. Notația este relativ simplă; este un O urmat de paranteze. În paranteze, scriem o funcție a lui n pentru a reprezenta complexitatea particulară.
Complexitatea liniară este reprezentată de n, așa că am scrie ca O(n) (se citește „O din n”). Complexitatea constantă este reprezentată de 1, așa că am scrie ca O(1).
Există mai multe complexități, despre care vom discuta în secțiunea următoare. Dar, în general, pentru a scrie complexitatea unui algoritm, urmați următorii pași:
Rezultatul devine termenul pe care îl folosim în parantezele noastre.
Exemplu:
Luați în considerare următoarea funcție Python:
users = [
'Alice',
'Bob',
'Charlie'
]
def print_users(users):
number_of_users = len(users)
print("Total number of users:", number_of_users)
for i in number_of_users:
print(i, end=': ')
print(user)
Acum, vom calcula complexitatea Big O Time a algoritmului.
Mai întâi scriem o funcție matematică a lui nf(n) pentru a reprezenta numărul de pași de calcul pe care îi parcurge algoritmul. Reamintim că n reprezintă dimensiunea intrării.
Din codul nostru, funcția efectuează doi pași: unul pentru a calcula numărul de utilizatori și celălalt pentru a tipări numărul de utilizatori. Apoi, pentru fiecare utilizator, efectuează doi pași: unul pentru a tipări indexul și unul pentru a tipări utilizatorul.
Prin urmare, funcția care reprezintă cel mai bine numărul de pași de calcul parcurși poate fi scrisă ca f(n) = 2 + 2n. Unde n este numărul de utilizatori.
Trecând la pasul doi, alegem termenul cel mai dominant. 2n este un termen liniar, iar 2 este un termen constant. Liniarul este mai dominant decât constant, așa că alegem 2n, termenul liniar.
Deci, funcția noastră este acum f(n) = 2n.
Ultimul pas este eliminarea coeficienților. În funcția noastră, avem 2 ca coeficient. Așa că o eliminăm. Și funcția devine f(n) = n. Acesta este termenul pe care îl folosim între paranteze.
Prin urmare, complexitatea temporală a algoritmului nostru este O(n) sau complexitatea liniară.
Diferite complexități Big O
Ultima secțiune din Big O Cheat Sheet vă va arăta diferite complexități și graficele asociate.
#1. Constant

Complexitatea constantă înseamnă că algoritmul utilizează o cantitate constantă de spațiu (când efectuează analiza complexității spațiului) sau un număr constant de pași (când efectuează analiza complexității în timp). Aceasta este cea mai optimă complexitate, deoarece algoritmul nu are nevoie de spațiu sau timp suplimentar pe măsură ce intrarea crește. Prin urmare, este foarte scalabil.
Complexitatea constantă este reprezentată ca O(1). Cu toate acestea, nu este întotdeauna posibil să scrieți algoritmi care rulează în complexitate constantă.
#2. Logaritmic
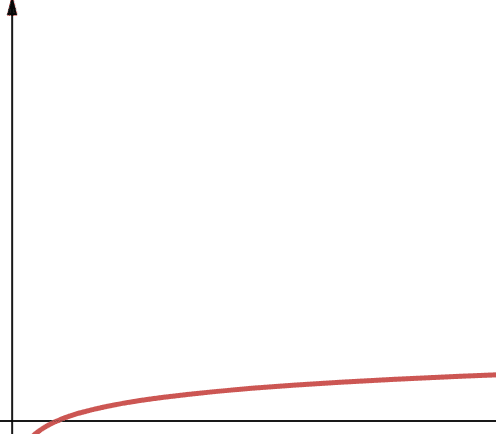
Complexitatea logaritmică este reprezentată de termenul O(log n). Este important de reținut că, dacă baza logaritmului nu este specificată în Informatică, presupunem că este 2.
Prin urmare, log n este log2n. Se știe că funcțiile logaritmice cresc rapid la început și apoi încetinesc. Aceasta înseamnă că se scalează și lucrează eficient cu un număr tot mai mare de n.
#3. Liniar
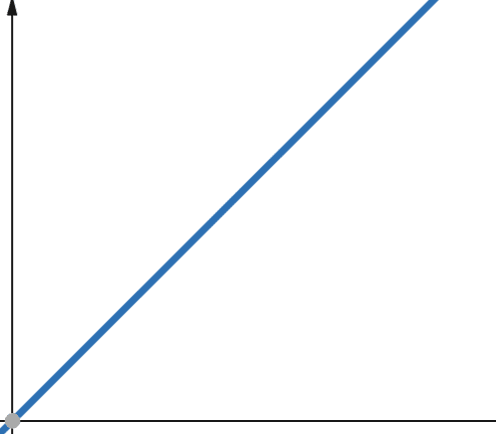
Pentru funcțiile liniare, dacă variabila independentă se scalează cu un factor de p. Variabila dependentă se scalează cu același factor de p.
Prin urmare, o funcție cu o complexitate liniară crește cu același factor ca și dimensiunea intrării. Dacă dimensiunea intrării se dublează, va crește și numărul de pași de calcul sau utilizarea memoriei. Complexitatea liniară este reprezentată de simbolul O(n).
#4. Linearitmic
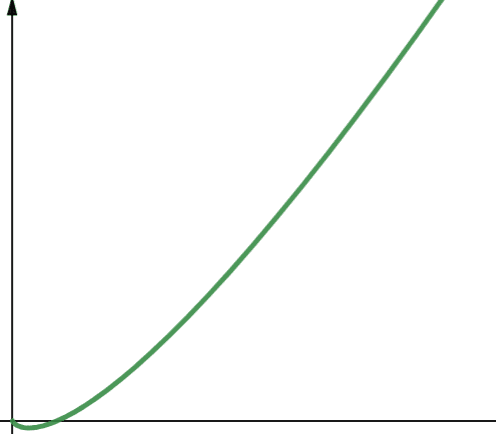
O (n * log n) reprezintă funcții liniaritmice. Funcțiile liniaritmice sunt o funcție liniară înmulțită cu funcția logaritm. Prin urmare, o funcție liniritmică dă rezultate puțin mai mari decât funcțiile liniare atunci când log n este mai mare decât 1. Acest lucru se datorează faptului că n crește atunci când este înmulțit cu un număr mai mare de 1.
Log n este mai mare decât 1 pentru toate valorile lui n mai mari decât 2 (rețineți că log n este log2n). Prin urmare, pentru orice valoare a lui n mai mare decât 2, funcțiile liniaritmice sunt mai puțin scalabile decât funcțiile liniare. Din care n este mai mare decât 2 în majoritatea cazurilor. Deci, funcțiile liniaritmice sunt în general mai puțin scalabile decât funcțiile logaritmice.
#5. cuadratic
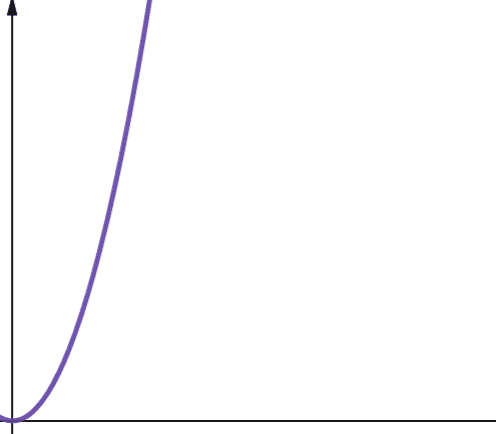
Complexitatea pătratică este reprezentată de O(n2). Aceasta înseamnă că dacă dimensiunea de intrare crește de 10 ori, numărul de pași parcurși sau spațiul utilizat crește de 102 ori de 100! Acest lucru nu este foarte scalabil și, după cum puteți vedea din grafic, complexitatea explodează foarte repede.
Complexitatea cuadratică apare în algoritmi în care buclă de n ori și pentru fiecare iterație, buclă din nou de n ori, de exemplu, în Bubble Sort. Deși în general nu este ideal, uneori, nu aveți altă opțiune decât să implementați algoritmi cu complexitate pătratică.
#6. Polinom
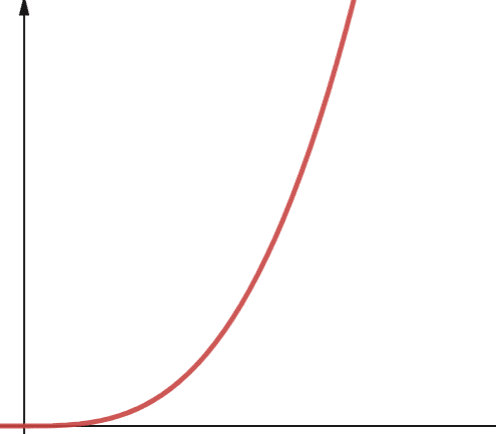
Un algoritm cu complexitate polinomială este reprezentat de O(np), unde p este un număr întreg constant. P reprezintă ordinea în care n este ridicat.
Această complexitate apare atunci când aveți un număr ap de bucle imbricate. Diferența dintre complexitatea polinomială și complexitatea pătratică este pătratică este de ordinul a 2, în timp ce polinomul are orice număr mai mare de 2.
#7. Exponenţial
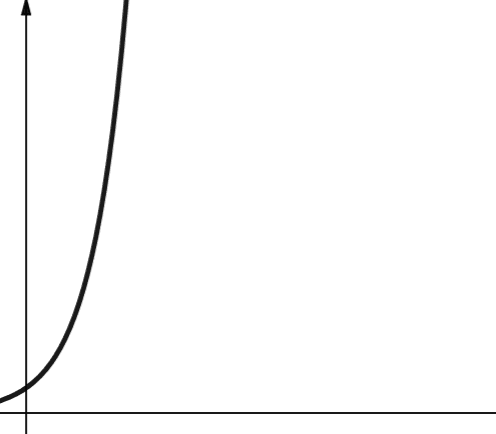
Complexitatea exponențială crește chiar mai repede decât complexitatea polinomială. În matematică, valoarea implicită pentru funcția exponențială este constanta e (numărul lui Euler). În informatică, totuși, valoarea implicită pentru funcția exponențială este 2.
Complexitatea exponenţială este reprezentată de simbolul O(2n). Când n este 0, 2n este 1. Dar când n este crescut la 5, 2n explodează până la 32. O creștere a lui n cu unu va dubla numărul anterior. Prin urmare, funcțiile exponențiale nu sunt foarte scalabile.
#8. Factorială
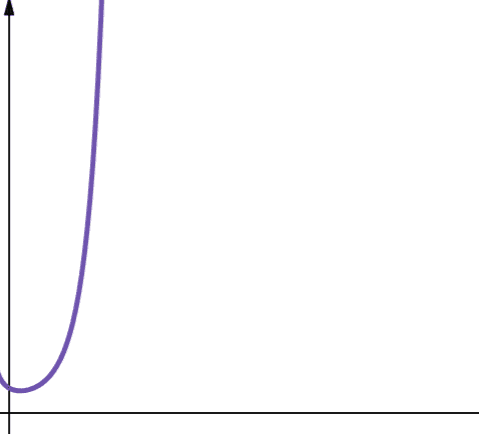
Complexitatea factorială este reprezentată de simbolul O(n!). Această funcție crește, de asemenea, foarte rapid și, prin urmare, nu este scalabilă.
Concluzie
Acest articol a tratat analiza Big O și cum să o calculăm. De asemenea, am discutat despre diferitele complexități și am discutat despre scalabilitatea acestora.
În continuare, poate doriți să exersați analiza Big O pe algoritmul de sortare Python.