
Ești interesat să-ți analizezi datele folosind limbajul natural? Aflați cum să faceți acest lucru folosind biblioteca Python PandasAI.
Într-o lume în care datele sunt cruciale, înțelegerea și analizarea lor este esențială. Cu toate acestea, analiza tradițională a datelor poate fi complexă. Aici intervine PandasAI. Simplifică analiza datelor, permițându-vă să vorbiți cu datele dvs. folosind limbajul natural.
Pandas AI funcționează transformându-ți întrebările în cod pentru analiza datelor. Se bazează pe popularele biblioteci panda Python. PandasAI este o bibliotecă Python care extinde panda, binecunoscutul instrument de analiză și manipulare a datelor, cu funcții Generative AI. Este destinat să completeze panda, mai degrabă decât să-i înlocuiască.
PandasAI introduce un aspect conversațional pentru panda (precum și alte biblioteci de analiză a datelor utilizate pe scară largă), permițându-vă să interacționați cu datele dvs. folosind interogări în limbaj natural.
Acest tutorial vă va ghida prin pașii de configurare a Pandas AI, utilizându-l cu un set de date din lumea reală, crearea de diagrame, explorarea comenzilor rapide și explorarea punctelor forte și limitărilor acestui instrument puternic.
După ce o finalizați, veți putea efectua analiza datelor mai ușor și intuitiv, folosind limbajul natural.
Deci, haideți să explorăm lumea fascinantă a analizei datelor în limbaj natural cu Pandas AI!
Cuprins
Configurarea mediului
Pentru a începe cu PandasAI, ar trebui să începeți prin a instala biblioteca PandasAI.
Folosesc un Jupyter Notebook pentru acest proiect. Dar puteți utiliza Google Colab sau VS Code conform cerințelor dvs.
Dacă intenționați să utilizați Open AI Large Language Models (LLM), este, de asemenea, important să instalați Open AI Python SDK pentru o experiență fără probleme.
# Installing Pandas AI !pip install pandas-ai # Pandas AI uses OpenAI's language models, so you need to install the OpenAI Python SDK !pip install openai
Acum, să importăm toate bibliotecile necesare:
# Importing necessary libraries import pandas as pd import numpy as np # Importing PandasAI and its components from pandasai import PandasAI, SmartDataframe from pandasai.llm.openai import OpenAI
Un aspect cheie al analizei datelor folosind PandasAI este cheia API. Acest instrument acceptă mai multe modele de limbaj mari (LLM) și modele LangChains, care sunt folosite pentru a genera cod din interogări în limbaj natural. Acest lucru face analiza datelor mai accesibilă și mai ușor de utilizat.
PandasAI este versatil și poate funcționa cu diferite tipuri de modele. Acestea includ modele Hugging Face, Azure OpenAI, Google PALM și Google VertexAI. Fiecare dintre aceste modele aduce propriile sale puncte forte la masă, sporind capacitățile PandasAI.
Rețineți, pentru a utiliza aceste modele, veți avea nevoie de cheile API corespunzătoare. Aceste chei vă autentifică cererile și vă permit să utilizați puterea acestor modele de limbaj avansate în sarcinile dvs. de analiză a datelor. Prin urmare, asigurați-vă că aveți cheile API la îndemână atunci când configurați PandasAI pentru proiectele dvs.
Puteți prelua cheia API și o puteți exporta ca variabilă de mediu.
În pasul următor, veți învăța cum să utilizați PandasAI cu diferite tipuri de modele de limbaj mari (LLM) de la OpenAI și Hugging Face Hub.
Utilizarea modelelor de limbaj mari
Puteți fie să alegeți un LLM prin instanțierea unuia și transmiterea acestuia către constructorul SmartDataFrame sau SmartDatalake, fie să specificați unul în fișierul pandasai.json.
Dacă modelul așteaptă unul sau mai mulți parametri, îi puteți transmite constructorului sau îi puteți specifica în fișierul pandasai.json în parametrul llm_options, după cum urmează:
{
"llm": "OpenAI",
"llm_options": {
"api_token": "API_TOKEN_GOES_HERE"
}
}
Cum se utilizează modelele OpenAI?
Pentru a utiliza modelele OpenAI, trebuie să aveți o cheie API OpenAI. Puteți obține unul Aici.
Odată ce aveți o cheie API, o puteți folosi pentru a instanția un obiect OpenAI:
#We have imported all necessary libraries in privious step
llm = OpenAI(api_token="my-api-key")
pandas_ai = SmartDataframe("data.csv", config={"llm": llm})
Nu uitați să înlocuiți „my-api-key” cu cheia API originală
Ca alternativă, puteți seta variabila de mediu OPENAI_API_KEY și instanția obiectul OpenAI fără a trece cheia API:
# Set the OPENAI_API_KEY environment variable
llm = OpenAI() # no need to pass the API key, it will be read from the environment variable
pandas_ai = SmartDataframe("data.csv", config={"llm": llm})
Dacă sunteți în spatele unui proxy explicit, puteți specifica openai_proxy atunci când instanțiați obiectul OpenAI sau puteți seta variabila de mediu OPENAI_PROXY să treacă.
Notă importantă: atunci când utilizați biblioteca PandasAI pentru analiza datelor cu cheia dvs. API, este important să urmăriți utilizarea simbolurilor pentru a gestiona costurile.
Te întrebi cum să faci asta? Pur și simplu rulați următorul cod de contor de jeton pentru a obține o imagine clară a utilizării jetonului și a taxelor corespunzătoare. În acest fel, vă puteți gestiona eficient resursele și puteți evita orice surprize în facturare.
Puteți număra numărul de jetoane utilizate de un prompt după cum urmează:
"""Example of using PandasAI with a pandas dataframe"""
from pandasai import SmartDataframe
from pandasai.llm import OpenAI
from pandasai.helpers.openai_info import get_openai_callback
import pandas as pd
llm = OpenAI()
# conversational=False is supposed to display lower usage and cost
df = SmartDataframe("data.csv", {"llm": llm, "conversational": False})
with get_openai_callback() as cb:
response = df.chat("Calculate the sum of the gdp of north american countries")
print(response)
print(cb)
Veți obține rezultate ca acestea:
# The sum of the GDP of North American countries is 19,294,482,071,552. # Tokens Used: 375 # Prompt Tokens: 210 # Completion Tokens: 165 # Total Cost (USD): $ 0.000750
Nu uitați să țineți o evidență a costului total dacă aveți credit limitat!
Cum se utilizează modelele Hugging Face?
Pentru a utiliza modelele HuggingFace, trebuie să aveți o cheie API HuggingFace. Puteți crea un cont HuggingFace Aici și obțineți o cheie API Aici.
Odată ce aveți o cheie API, o puteți folosi pentru a instanția unul dintre modelele HuggingFace.
În acest moment, PandasAI acceptă următoarele modele HuggingFace:
- Starcoder: bigcode/starcoder
- Soimul: tiiuae/soimul-7b-instruct
from pandasai.llm import Starcoder, Falcon
llm = Starcoder(api_token="my-huggingface-api-key")
# or
llm = Falcon(api_token="my-huggingface-api-key")
df = SmartDataframe("data.csv", config={"llm": llm})
Ca alternativă, puteți seta variabila de mediu HUGGINGFACE_API_KEY și puteți instanția obiectul HuggingFace fără a trece cheia API:
from pandasai.llm import Starcoder, Falcon
llm = Starcoder() # no need to pass the API key, it will be read from the environment variable
# or
llm = Falcon() # no need to pass the API key, it will be read from the environment variable
df = SmartDataframe("data.csv", config={"llm": llm})
Starcoder și Falcon sunt ambele modele LLM disponibile pe Hugging Face.
Ne-am configurat cu succes mediul și am explorat cum să folosim atât modelele OpenAI, cât și Hugging Face LLM. Acum, să mergem mai departe cu călătoria noastră de analiză a datelor.
Vom folosi setul de date Big Mart Sales data, care conține informații despre vânzările diferitelor produse în diferite puncte de vânzare ale Big Mart. Setul de date are 12 coloane și 8524 de rânduri. Veți primi linkul la sfârșitul articolului.
Analiza datelor cu PandasAI
Acum că am instalat și importat cu succes toate bibliotecile necesare, să continuăm să încărcăm setul de date.
Încărcați setul de date
Puteți alege fie un LLM prin instanțierea unuia și transmiterea acestuia către SmartDataFrame. Veți primi linkul către setul de date la sfârșitul articolului.
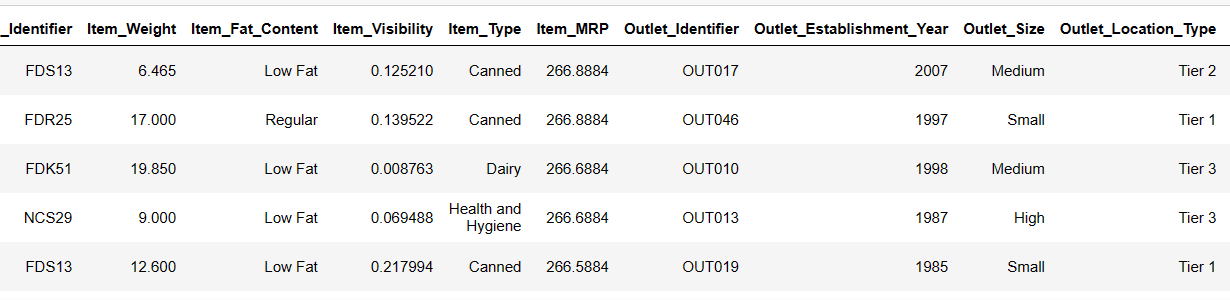
#Load the dataset from device path = r"D:\Pandas AI\Train.csv" df = SmartDataframe(path)
Utilizați modelul LLM al OpenAI
După încărcarea datelor noastre. Voi folosi modelul LLM al OpenAI pentru a folosi PandasAI
llm = OpenAI(api_token="API_Key") pandas_ai = PandasAI(llm, conversational=False)
Toate bune! Acum, să încercăm să folosim prompturi.
Tipăriți primele 6 rânduri ale setului nostru de date
Să încercăm să încărcăm primele 6 rânduri, oferind instrucțiuni:
Result = pandas_ai(df, "Show the first 6 rows of data in tabular form") Result
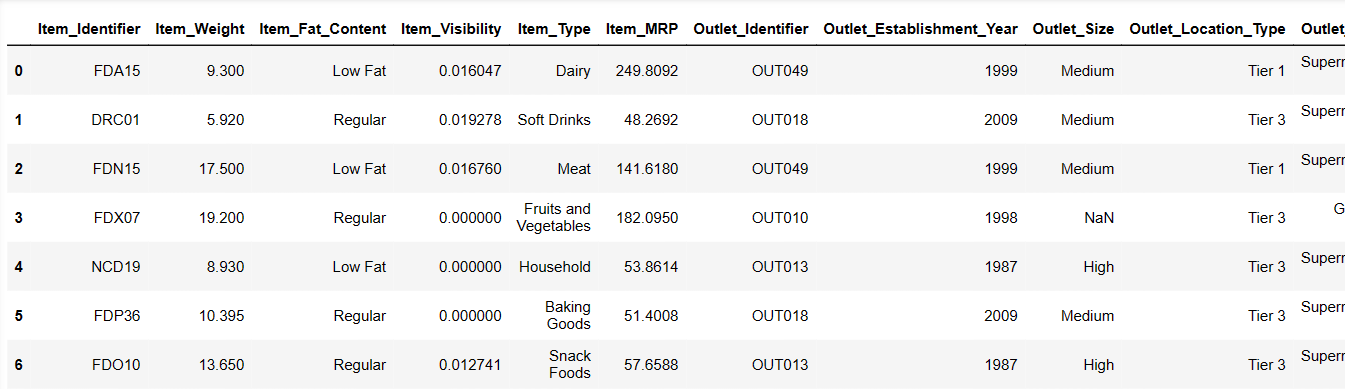 Primele 6 rânduri din setul de date
Primele 6 rânduri din setul de date
A fost foarte rapid! Să înțelegem setul nostru de date.
Generarea statisticilor descriptive ale DataFrame
# To get descriptive statistics Result = pandas_ai(df, "Show the description of data in tabular form") Result
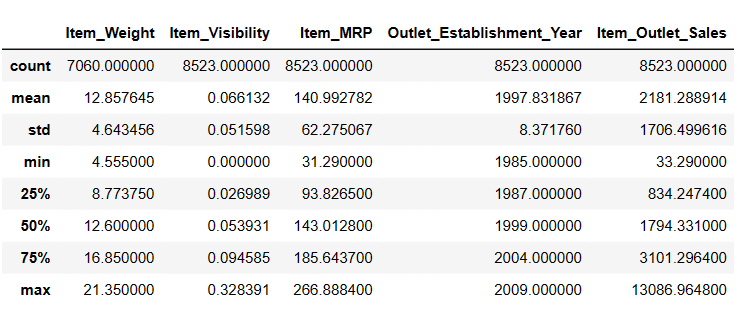 Descriere
Descriere
Există 7060 de valori în Item_Weigth; poate lipsesc niște valori.
Găsiți valorile lipsă
Există două moduri de a găsi valorile lipsă folosind panda ai.
#Find missing values Result = pandas_ai(df, "Show the missing values of data in tabular form") Result
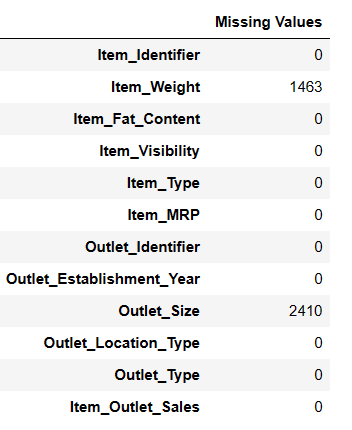 Găsirea valorilor lipsă
Găsirea valorilor lipsă
# Comandă rapidă pentru curățarea datelor
df = SmartDataframe('data.csv')
df.clean_data()
Această comandă rapidă va face curățarea datelor pe cadrul de date.
Acum, să completăm valorile nule lipsă.
Completați valorile lipsă
#Fill Missing values result = pandas_ai(df, "Fill Item Weight with median and Item outlet size null values with mode and Show the missing values of data in tabular form") result
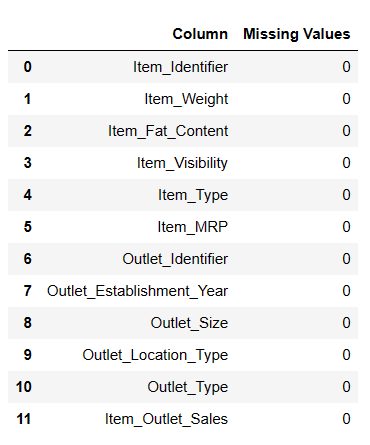 Valori nule completate
Valori nule completate
Este o metodă utilă de a completa valori nule, dar m-am confruntat cu unele probleme în timp ce completam valorile nule.
# Comandă rapidă pentru completarea valorilor nule
df = SmartDataframe('data.csv')
df.impute_missing_values()
Această comandă rapidă va imputa valorile lipsă în cadrul de date.
Eliminați valorile nule
Dacă doriți să eliminați toate valorile nule din df, atunci puteți încerca această metodă.
result = pandas_ai(df, "Drop the row with missing values with inplace=True") result
Analiza datelor este esențială pentru identificarea tendințelor, atât pe termen scurt, cât și pe termen lung, care pot fi de neprețuit pentru întreprinderi, guverne, cercetători și persoane fizice.
Să încercăm să găsim o tendință generală de vânzări de-a lungul anilor de la înființare.
Găsirea tendinței de vânzări
# finding trend in sales result = pandas_ai(df, "What is the overall trend in sales over the years since outlet establishment?") result
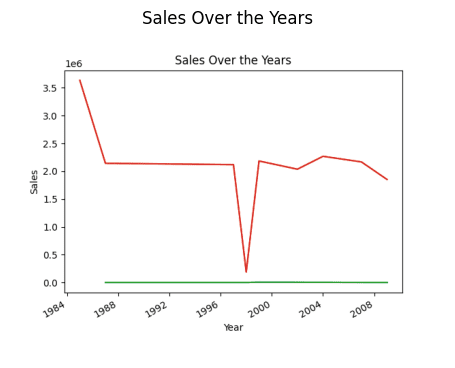 Vânzări de-a lungul anului (diagramă cu linii)
Vânzări de-a lungul anului (diagramă cu linii)
Procesul inițial de creare a parcelei a fost puțin lent, dar după ce a repornit nucleul și a rulat totul, a rulat mai repede.
# Comandă rapidă pentru a trasa diagrame cu linii
df.plot_line_chart(x = ['a', 'b', 'c'], y = [1, 2, 3])
Această comandă rapidă va reprezenta o diagramă cu linii a cadrului de date.
S-ar putea să vă întrebați de ce există o scădere a tendinței. Se datorează faptului că nu avem date din 1989 până în 1994.
Găsirea anului cu cele mai mari vânzări
Acum, să aflăm care an are cele mai mari vânzări.
# finding year of highest sales result = pandas_ai(df, "Explain which years have highest sales") result

Deci, anul cu cele mai mari vânzări este 1985.
Dar, vreau să aflu ce tip de articol generează cele mai mari vânzări medii și care tip generează cele mai mici vânzări medii.
Vânzări medii cele mai mari și cele mai scăzute
# finding highest and lowest average sale result = pandas_ai(df, "Which item type generates the highest average sales, and which one generates the lowest?") result

Alimentele cu amidon au cele mai mari vânzări medii, iar altele au cele mai scăzute vânzări medii. Dacă nu doriți ca alții să fie cele mai mici vânzări, puteți îmbunătăți promptul în funcție de nevoile dvs.
Superb! Acum, vreau să aflu distribuția vânzărilor în diferite puncte de vânzare.
Distribuția vânzărilor în diferite puncte de vânzare
Există patru tipuri de magazine: Supermarket tip 1/2/3 și magazine alimentare.
# distribution of sales across different outlet types since establishment response = pandas_ai(df, "Visualize the distribution of sales across different outlet types since establishment using bar plot, plot size=(13,10)") response
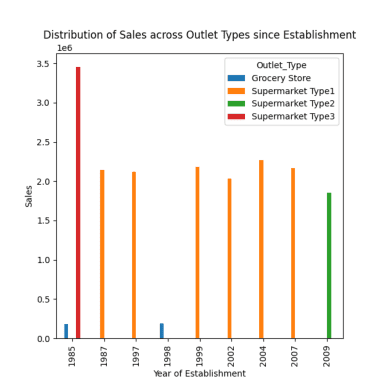 Distribuția vânzărilor în diferite puncte de vânzare
Distribuția vânzărilor în diferite puncte de vânzare
După cum sa observat în solicitările anterioare, vârful vânzărilor a avut loc în 1985, iar acest grafic evidențiază cele mai mari vânzări din 1985 de la magazinele de tip 3 de supermarket.
# Comandă rapidă pentru Plot Bar Chart
df = SmartDataframe('data.csv')
df.plot_bar_chart(x = ['a', 'b', 'c'], y = [1, 2, 3])
Această comandă rapidă va reprezenta o diagramă cu bare a cadrului de date.
# Comandă rapidă pentru a trasa histograma
df = SmartDataframe('data.csv')
df.plot_histogram(column = 'a')
Această comandă rapidă va reprezenta o histogramă a cadrului de date.
Acum, să aflăm care sunt vânzările medii pentru articolele cu conținut de grăsime „Scăzut în grăsimi” și „obișnuit”.
Găsiți vânzări medii pentru articole cu conținut de grăsime
# finding index of a row using value of a column result = pandas_ai(df, "What is the average sales for the items with 'Low Fat' and 'Regular' item fat content?") result
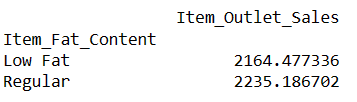
Scrierea unor astfel de solicitări vă permite să comparați două sau mai multe produse.
Vânzări medii pentru fiecare tip de articol
Vreau să compar toate produsele cu vânzările lor medii.
#Average Sales for Each Item Type result = pandas_ai(df, "What are the average sales for each item type over the past 5 years?, use pie plot, size=(6,6)") result
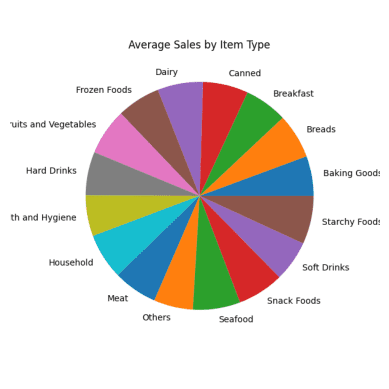 Diagramă circulară a vânzărilor medii
Diagramă circulară a vânzărilor medii
Toate secțiunile diagramei circulare par similare, deoarece au aproape aceleași cifre de vânzări.
# Comandă rapidă pentru a trasa diagrama circulară
df.plot_pie_chart(labels = ['a', 'b', 'c'], values = [1, 2, 3])
Această comandă rapidă va reprezenta o diagramă circulară a cadrului de date.
Top 5 tipuri de articole cele mai vândute
Deși am comparat deja toate produsele pe baza vânzărilor medii, acum aș dori să identific primele 5 articole cu cele mai mari vânzări.
#Finding top 5 highest selling items result = pandas_ai(df, "What are the top 5 highest selling item type based on average sells? Write in tablular form") result
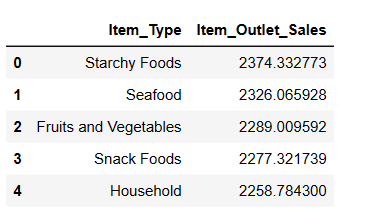
După cum era de așteptat, Starchy Foods este cel mai vândut articol pe baza vânzărilor medii.
Top 5 tipuri de articole cel mai puțin vândute
result = pandas_ai(df, "What are the top 5 lowest selling item type based on average sells?") result
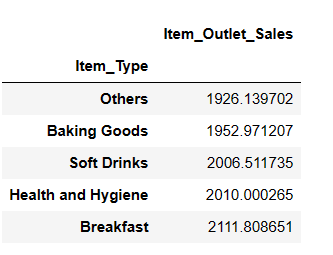
S-ar putea să fii surprins să vezi băuturi răcoritoare în categoria cel mai puțin vândută. Cu toate acestea, este esențial să rețineți că aceste date merg până în 2008, iar tendința pentru băuturile răcoritoare a început câțiva ani mai târziu.
Vânzări de categorii de produse
Aici, am folosit cuvântul „categorie de produs” în loc de „tip de articol”, iar PandasAI a creat în continuare diagramele, arătând înțelegerea cuvintelor similare.
result = pandas_ai(df, "Give a stacked large size bar chart of the sales of the various product categories for the last FY") result
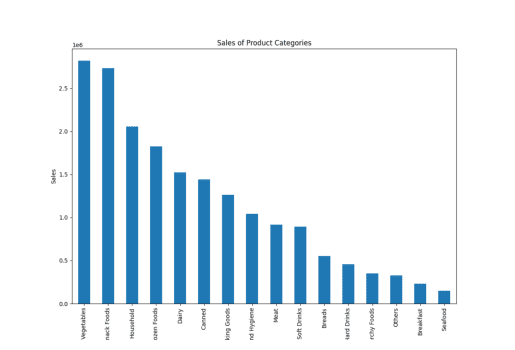 Vânzări de tip de articol
Vânzări de tip de articol
Puteți găsi comenzile rapide rămase Aici.
Este posibil să observați că atunci când scriem o solicitare și oferim instrucțiuni unui PandasAI, acesta oferă rezultate bazate exclusiv pe acel prompt specific. Nu analizează solicitările tale anterioare pentru a oferi răspunsuri mai precise.
Cu toate acestea, cu asistența unui agent de chat, puteți realiza și această funcționalitate.
Agent de chat
Cu agentul de chat, vă puteți angaja în conversații dinamice în care agentul păstrează contextul pe tot parcursul discuției. Acest lucru vă permite să aveți schimburi mai interactive și semnificative.
Caracteristicile cheie care împuternicesc această interacțiune includ retenția contextului, în care agentul își amintește istoricul conversației, permițând interacțiuni fără întreruperi, conștiente de context. Puteți folosi metoda Întrebări de clarificare pentru a solicita clarificări cu privire la orice aspect al conversației, asigurându-vă că înțelegeți pe deplin informațiile furnizate.
Mai mult, metoda Explain este disponibilă pentru a obține explicații detaliate despre modul în care agentul a ajuns la o anumită soluție sau răspuns, oferind transparență și perspective asupra procesului de luare a deciziilor agentului.
Simțiți-vă liber să inițiați conversații, să căutați clarificări și să explorați explicații pentru a vă îmbunătăți interacțiunile cu agentul de chat!
from pandasai import Agent
agent = Agent(df, config={"llm": llm}, memory_size=10)
result = agent.chat("Which are top 5 items with highest MRP")
result
Spre deosebire de un SmartDataframe sau un SmartDatalake, un agent va ține evidența stării conversației și va putea răspunde la conversații cu mai multe rânduri.
Să ne îndreptăm spre Avantajele și Limitările PandasAI
Avantajele PandasAI
Utilizarea Pandas AI oferă mai multe avantaje care o fac un instrument valoros pentru analiza datelor, cum ar fi:
- Accesibilitate: PandasAI simplifică analiza datelor, făcându-le accesibile unei game largi de utilizatori. Oricine, indiferent de experiența sa tehnică, îl poate folosi pentru a extrage informații din date și pentru a răspunde la întrebări de afaceri.
- Interogări în limbaj natural: abilitatea de a pune întrebări direct și de a primi răspunsuri din date folosind interogări în limbaj natural face explorarea și analiza datelor mai ușor de utilizat. Această caracteristică permite chiar și utilizatorilor netehnici să interacționeze eficient cu datele.
- Funcționalitate de chat agent: funcția de chat permite utilizatorilor să interacționeze cu datele în mod interactiv, în timp ce funcția de chat agent folosește istoricul chatului anterior pentru a oferi răspunsuri conștient de context. Acest lucru promovează o abordare dinamică și conversațională a analizei datelor.
- Vizualizarea datelor: PandasAI oferă o gamă largă de opțiuni de vizualizare a datelor, inclusiv hărți termice, diagrame de dispersie, diagrame cu bare, diagrame circulare, diagrame cu linii și multe altele. Aceste vizualizări ajută la înțelegerea și prezentarea modelelor și tendințelor de date.
- Comenzi rapide care economisesc timp: Disponibilitatea comenzilor rapide și a funcțiilor de economisire a timpului simplifică procesul de analiză a datelor, ajutând utilizatorii să lucreze mai eficient și mai eficient.
- Compatibilitate cu fișierele: PandasAI acceptă diferite formate de fișiere, inclusiv CSV, Excel, Foi de calcul Google și multe altele. Această flexibilitate permite utilizatorilor să lucreze cu date dintr-o varietate de surse și formate.
- Solicitări personalizate: utilizatorii pot crea solicitări personalizate folosind instrucțiuni simple și cod Python. Această caracteristică permite utilizatorilor să își adapteze interacțiunile cu datele pentru a se potrivi nevoilor și interogărilor specifice.
- Salvare modificări: abilitatea de a salva modificările aduse cadrelor de date asigură păstrarea lucrărilor dvs. și vă puteți revedea și partaja analiza în orice moment.
- Răspunsuri personalizate: opțiunea de a crea răspunsuri personalizate le permite utilizatorilor să definească comportamente sau interacțiuni specifice, făcând instrumentul și mai versatil.
- Integrarea modelelor: PandasAI acceptă diverse modele de limbaj, inclusiv cele de la modelele Hugging Face, Azure, Google Palm, Google VertexAI și LangChain. Această integrare îmbunătățește capacitățile instrumentului și permite procesarea și înțelegerea avansată a limbajului natural.
- Suport LangChain încorporat: Suportul încorporat pentru modelele LangChain extinde și mai mult gama de modele și funcționalități disponibile, sporind profunzimea analizei și perspectivele care pot fi derivate din date.
- Înțelegerea numelor: PandasAI demonstrează capacitatea de a înțelege corelația dintre numele coloanelor și terminologia din viața reală. De exemplu, chiar dacă folosiți termeni precum „categorie de produs” în loc de „tip de articol” în solicitări, instrumentul poate oferi în continuare rezultate relevante și precise. Această flexibilitate în recunoașterea sinonimelor și maparea lor la coloanele de date adecvate îmbunătățește confortul utilizatorului și adaptabilitatea instrumentului la interogări în limbaj natural.
Deși PandasAI oferă mai multe avantaje, vine și cu anumite limitări și provocări de care utilizatorii ar trebui să fie conștienți:
Limitările PandasAI
Iată câteva limitări pe care le-am observat:
- Cerință pentru cheia API: Pentru a utiliza PandasAI, este esențial să aveți o cheie API. Dacă nu aveți suficiente credite în contul dvs. OpenAI, este posibil să nu puteți utiliza serviciul. Cu toate acestea, merită remarcat faptul că OpenAI oferă un credit de 5 USD pentru noii utilizatori, făcându-l accesibil pentru cei noi pe platformă.
- Timp de procesare: uneori, serviciul poate întâmpina întârzieri în furnizarea rezultatelor, care pot fi atribuite utilizării ridicate sau încărcării serverului. Utilizatorii ar trebui să fie pregătiți pentru potențiali timpi de așteptare atunci când solicită serviciul.
- Interpretarea solicitărilor: deși puteți pune întrebări prin intermediul solicitărilor, abilitatea sistemului de a explica răspunsurile poate să nu fie complet dezvoltată, iar calitatea explicațiilor poate varia. Acest aspect al PandasAI se poate îmbunătăți în viitor odată cu dezvoltarea ulterioară.
- Sensibilitate la prompt: utilizatorii trebuie să fie atenți atunci când creează solicitări, deoarece chiar și modificări ușoare pot duce la rezultate diferite. Această sensibilitate la formularea și structura promptă poate afecta consistența rezultatelor, mai ales atunci când lucrați cu diagrame de date sau interogări mai complexe.
- Limitări ale solicitărilor complexe: este posibil ca PandasAI să nu gestioneze solicitările sau interogările foarte complexe la fel de eficient ca cele mai simple. Utilizatorii ar trebui să fie atenți la complexitatea întrebărilor lor și să se asigure că instrumentul este potrivit pentru nevoile lor specifice.
- Modificări inconsecvente ale cadrelor de date: utilizatorii au raportat probleme cu efectuarea modificărilor cadrelor de date, cum ar fi completarea valorilor nule sau eliminarea rândurilor cu valori nule, chiar și atunci când specificau „Inplace=True”. Această inconsecvență poate fi frustrantă pentru utilizatorii care încearcă să-și modifice datele.
- Rezultate variabile: la repornirea unui nucleu sau la re-rularea solicitărilor, este posibil să primiți rezultate sau interpretări diferite ale datelor din rulările anterioare. Această variabilitate poate fi o provocare pentru utilizatorii care au nevoie de rezultate consistente și reproductibile. Nu se aplică tuturor solicitărilor.
Puteți descărca setul de date Aici.
Codul este disponibil pe GitHub.
Concluzie
PandasAI oferă o abordare ușor de utilizat a analizei datelor, accesibilă chiar și celor fără abilități extinse de codare.
În acest articol, am descris cum să configurați și să utilizați PandasAI pentru analiza datelor, inclusiv crearea de diagrame, gestionarea valorilor nule și profitarea de funcționalitatea de chat al agentului.
Abonați-vă la buletinul nostru informativ pentru mai multe articole informative. Ați putea fi interesat să aflați despre modelele AI pentru crearea AI generativă.
A fost de ajutor articolul?
Multumim pentru feedback-ul dvs!