
Acest articol menționează și expune unele dintre cele mai bune biblioteci Python pentru oamenii de știință de date și echipa de învățare automată.
Python este un limbaj ideal folosit celebru în aceste două domenii, în principal pentru bibliotecile pe care le oferă.
Acest lucru se datorează aplicațiilor bibliotecilor Python, cum ar fi I/O de intrare/ieșire a datelor și analiza datelor, printre alte operațiuni de manipulare a datelor pe care oamenii de știință de date și experții în învățarea automată le folosesc pentru a manipula și explora datele.
Cuprins
Bibliotecile Python, care sunt acestea?
O bibliotecă Python este o colecție extinsă de module încorporate care conțin cod pre-compilat, inclusiv clase și metode, eradicând nevoia dezvoltatorului de a implementa codul de la zero.
Importanța lui Python în Data Science și Machine Learning
Python are cele mai bune biblioteci pentru utilizare de către experții în învățarea automată și în știința datelor.
Sintaxa sa este ușoară, făcând astfel eficientă implementarea algoritmilor complexi de învățare automată. Mai mult, sintaxa simplă scurtează curba de învățare și facilitează înțelegerea.
Python acceptă dezvoltarea rapidă a prototipurilor și testarea fără probleme a aplicațiilor.
Comunitatea mare a lui Python este la îndemână pentru oamenii de știință de date pentru a căuta cu ușurință soluții la întrebările lor atunci când este necesar.
Cât de utile sunt bibliotecile Python?
Bibliotecile Python sunt esențiale în crearea de aplicații și modele în învățarea automată și știința datelor.
Aceste biblioteci ajută foarte mult dezvoltatorul cu reutilizarea codului. Prin urmare, puteți importa o bibliotecă relevantă care implementează o caracteristică specifică în programul dvs., alta decât reinventarea roții.
Bibliotecile Python utilizate în învățarea automată și în știința datelor
Experții în știința datelor recomandă diferite biblioteci Python cu care pasionații științei datelor trebuie să fie familiarizați. În funcție de relevanța lor în aplicație, experții în învățarea automată și în știința datelor aplică diferite biblioteci Python clasificate în biblioteci pentru implementarea modelelor, extragerea și răzuirea datelor, procesarea datelor și vizualizarea datelor.
Acest articol identifică câteva biblioteci Python utilizate în mod obișnuit în Data Science și Machine Learning.
Să ne uităm la ele acum.
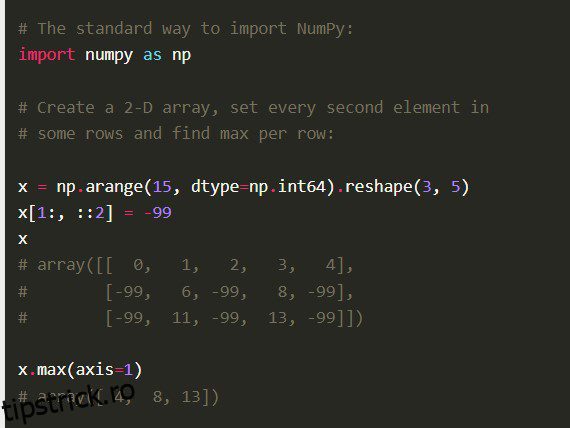
Numpy
Biblioteca Numpy Python, de asemenea Numerical Python Code în întregime, este construită cu cod C bine optimizat. Oamenii de știință de date îl preferă pentru calculele sale matematice profunde și calculele științifice.
Caracteristici
Numpy vine cu alte caracteristici cuprinzătoare, cum ar fi vectorizarea operațiilor matematice, indexare și concepte cheie în implementarea matricelor și matricelor.
panda
Pandas este o bibliotecă renumită în Machine Learning care oferă structuri de date de nivel înalt și numeroase instrumente pentru a analiza seturi masive de date fără efort și eficient. Cu foarte puține comenzi, această bibliotecă poate traduce operațiuni complexe cu date.
Numeroase metode încorporate care pot grupa, indexa, extrage, împărți, restructura date și filtre seturi înainte de a le introduce în tabele unice și multidimensionale; alcătuiește această bibliotecă.
Principalele caracteristici ale bibliotecii Pandas
Este foarte eficient pentru funcționalitatea sa bună de analiză a datelor și flexibilitatea ridicată.
Matplotlib
Biblioteca grafică Python Matplotlib 2D poate gestiona cu ușurință date din numeroase surse. Vizualizările pe care le creează sunt statice, animate și interactive pe care utilizatorul le poate mări, făcând astfel eficientă pentru vizualizări și crearea de diagrame. De asemenea, permite personalizarea aspectului și a stilului vizual.
Documentația sa este open source și oferă o colecție profundă de instrumente necesare implementării.
Matplotlib importă clase de ajutor pentru a implementa an, lună, zi și săptămână, făcând eficientă manipularea datelor din seria temporală.
Scikit-învață
Dacă vă gândiți la o bibliotecă care să vă ajute să lucrați cu date complexe, Scikit-learn ar trebui să fie biblioteca dvs. ideală. Experții în învățarea automată folosesc pe scară largă Scikit-learn. Biblioteca este asociată cu alte biblioteci precum NumPy, SciPy și matplotlib. Oferă atât algoritmi de învățare supravegheați, cât și nesupravegheați care pot fi utilizați pentru aplicații de producție.

Caracteristicile bibliotecii Scikit-learn Python
Biblioteca Scikit-learn este eficientă în extragerea caracteristicilor din seturi de date text și imagini. Mai mult, este posibil să se verifice acuratețea modelelor supravegheate pe date nevăzute. Numeroșii algoritmi disponibili fac posibile extragerea datelor și alte sarcini de învățare automată.
SciPy
SciPy (Scientific Python Code) este o bibliotecă de învățare automată care oferă module aplicate la funcții și algoritmi matematici care sunt aplicabile pe scară largă. Algoritmii săi rezolvă ecuații algebrice, interpolare, optimizare, statistici și integrare.
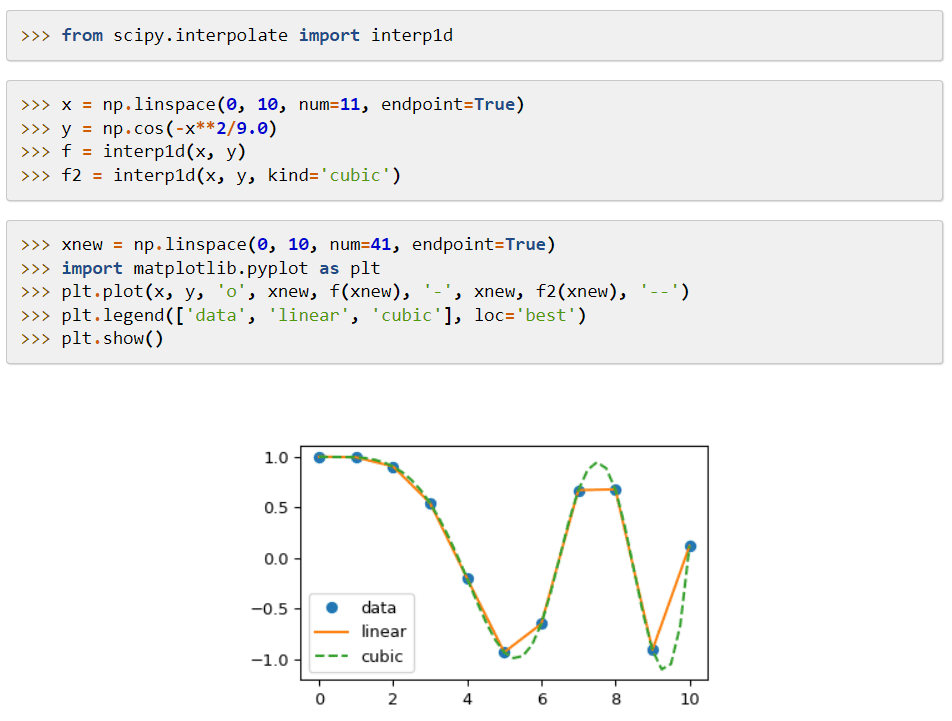
Caracteristica sa principală este extensia la NumPy, care adaugă instrumente pentru a rezolva funcțiile matematice și oferă structuri de date precum matrici rare.
SciPy folosește comenzi și clase de nivel înalt pentru a manipula și vizualiza datele. Sistemele sale de procesare a datelor și prototipuri îl fac un instrument și mai eficient.
Mai mult decât atât, sintaxa de nivel înalt a lui SciPy îl face ușor de utilizat de către programatori de orice nivel de experiență.
Singurul dezavantaj al lui SciPy este concentrarea exclusivă pe obiecte numerice și algoritmi; prin urmare, nu poate oferi nicio funcție de plotare.
PyTorch
Această bibliotecă diversă de învățare automată implementează eficient calculele tensorilor cu accelerare GPU, creând grafice de calcul dinamice și calcule automate de gradienți. Biblioteca Torch, o bibliotecă open-source de învățare automată dezvoltată pe C, construiește biblioteca PyTorch.

Caracteristicile cheie includ:
Puteți utiliza PyTorch în dezvoltarea aplicațiilor NLP.
Keras
Keras este o bibliotecă Python de învățare automată cu sursă deschisă folosită pentru a experimenta rețele neuronale profunde.
Este renumit pentru că oferă utilități care suportă sarcini precum compilarea modelelor și vizualizările grafice, printre altele. Acesta aplică Tensorflow pentru backend-ul său. Alternativ, puteți utiliza Theano sau rețele neuronale precum CNTK în backend. Această infrastructură backend îl ajută să creeze grafice de calcul utilizate pentru implementarea operațiunilor.
Caracteristicile cheie ale bibliotecii
Aplicațiile Keras includ blocuri de construcție a rețelei neuronale, cum ar fi straturi și obiective, printre alte instrumente care facilitează lucrul cu imagini și date text.
Seaborn
Seaborn este un alt instrument valoros în vizualizarea datelor statistice.
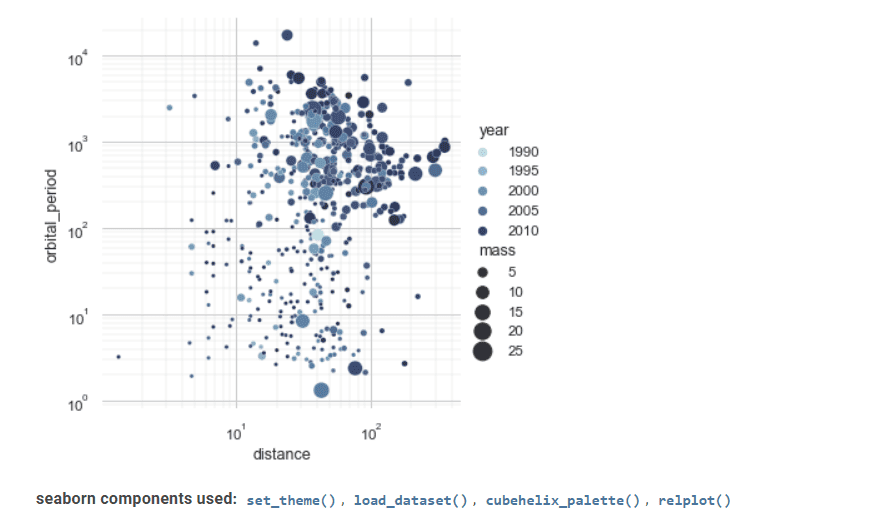
Interfața sa avansată poate implementa desene grafice statistice atractive și informative.
Complot
Plotly este un instrument de vizualizare 3D bazat pe web, construit pe biblioteca Plotly JS. Are suport larg pentru diferite tipuri de diagrame, cum ar fi diagrame cu linii, diagrame de dispersie și linii sparkline cu tipuri de casete.
Aplicația sa include crearea de vizualizări de date bazate pe web în notebook-uri Jupyter.
Plotly este potrivit pentru vizualizare, deoarece poate indica valori aberante sau anomalii în grafic cu ajutorul instrumentului său de trecere. De asemenea, puteți personaliza graficele pentru a se potrivi preferințelor dvs.
Pe dezavantajul lui Plotly, documentația sa este depășită; prin urmare, folosirea acestuia ca ghid poate fi dificilă pentru utilizator. În plus, are numeroase instrumente pe care utilizatorul ar trebui să le învețe. Poate fi o provocare să ținem evidența tuturor.
Caracteristicile bibliotecii Plotly Python
SimpluITK
SimpleITK este o bibliotecă de analiză a imaginilor care oferă o interfață pentru Insight Toolkit (ITK). Se bazează pe C++ și este open-source.
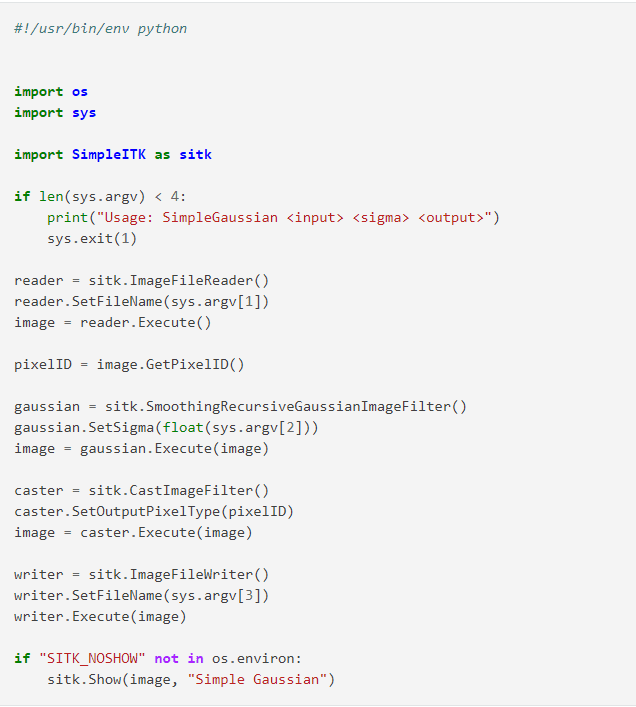
Caracteristicile bibliotecii SimpleITK
Interfața sa simplificată este disponibilă în diferite limbaje de programare precum R, C#, C++, Java și Python.
Statmodel
Statsmodel estimează modele statistice, implementează teste statistice și explorează datele statistice folosind clase și funcții.
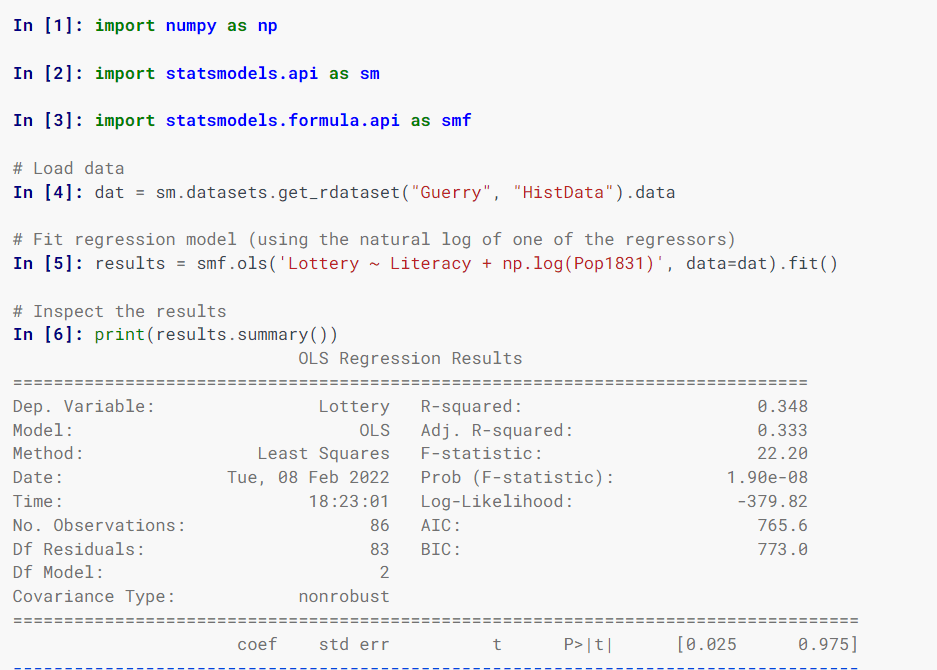
Specificarea modelelor utilizează formule în stil R, matrice NumPy și cadre de date Pandas.
Scrapy
Acest pachet open-source este un instrument preferat pentru preluarea (răzuirea) și accesarea cu crawlere a datelor de pe un site web. Este asincron și, prin urmare, relativ rapid. Scrapy are arhitectură și caracteristici care îl fac eficient.
Pe de altă parte, instalarea sa diferă pentru diferite sisteme de operare. În plus, nu îl puteți utiliza pe site-uri web construite pe JS. De asemenea, poate funcționa numai cu Python 2.7 sau versiuni ulterioare.
Experții în știința datelor îl aplică în extragerea datelor și în testarea automată.
Caracteristici
Pernă
Pillow este o bibliotecă de imagini Python care manipulează și procesează imagini.
Se adaugă la funcțiile de procesare a imaginii interpretului Python, acceptă diferite formate de fișiere și oferă o reprezentare internă excelentă.
Datele stocate în formate de fișiere de bază pot fi accesate cu ușurință datorită Pillow.
Încheierea💃
Aceasta rezumă explorarea noastră a unora dintre cele mai bune biblioteci Python pentru oamenii de știință de date și experții în învățarea automată.
După cum arată acest articol, Python are pachete mai utile de învățare automată și știință a datelor. Python are alte biblioteci pe care le puteți aplica în alte domenii.
Poate doriți să aflați despre unele dintre cele mai bune caiete de știință a datelor.
Învățare fericită!