
Construirea unui sistem software automat a însemnat configurarea mai multor servere cu configurație dedicată CPU, memorie, stocare și alte resurse pentru mulți ani. În continuare, s-a format o echipă de administratori care să gestioneze aceste sisteme. Apoi echipa de dezvoltare a preluat infrastructura și a început să creeze procese care conectează serverele.
Acest proces poate fi complicat deoarece implică multe grupuri diferite care lucrează împreună pentru un obiectiv comun. Aceste conflicte de interese pot fi atunci o problemă.
De asemenea, poate fi destul de costisitor. Acest lucru necesită să aveți administratori în statul de plată. Serverele, care rulează continuu, consumă resurse chiar dacă nu sunt folosite.
Pentru a menține cea mai bună performanță în timp, aveți nevoie de o soluție de scalare automată care să scaleze automat resursele serverului.
Platforma cloud are un avantaj: vă permite să creați o arhitectură de la capăt la capăt fără a fi nevoie de configurarea clusterului de servere. Din punct de vedere administrativ, nu este nimic de menținut.
Aceasta este o opțiune rentabilă pentru startup-uri și fazele proiectelor de produs minim viabil (MVP). Este un bun punct de plecare dacă este dificil să preziceți sarcinile viitoare de producție și activitatea utilizatorului. Aici poate fi dificil să se determine configurația serverelor de cluster.
Automatizarea proceselor prin servicii cloud fără server este ceea ce face ca arhitectura fără server să iasă în evidență. Conectează servicii și produce rezultate similare cu serverele de cluster tradiționale.
Acesta este un exemplu de construire a unei astfel de arhitecturi folosind numai servicii AWS native.
Cuprins
Preluarea fluxului de servicii fără server
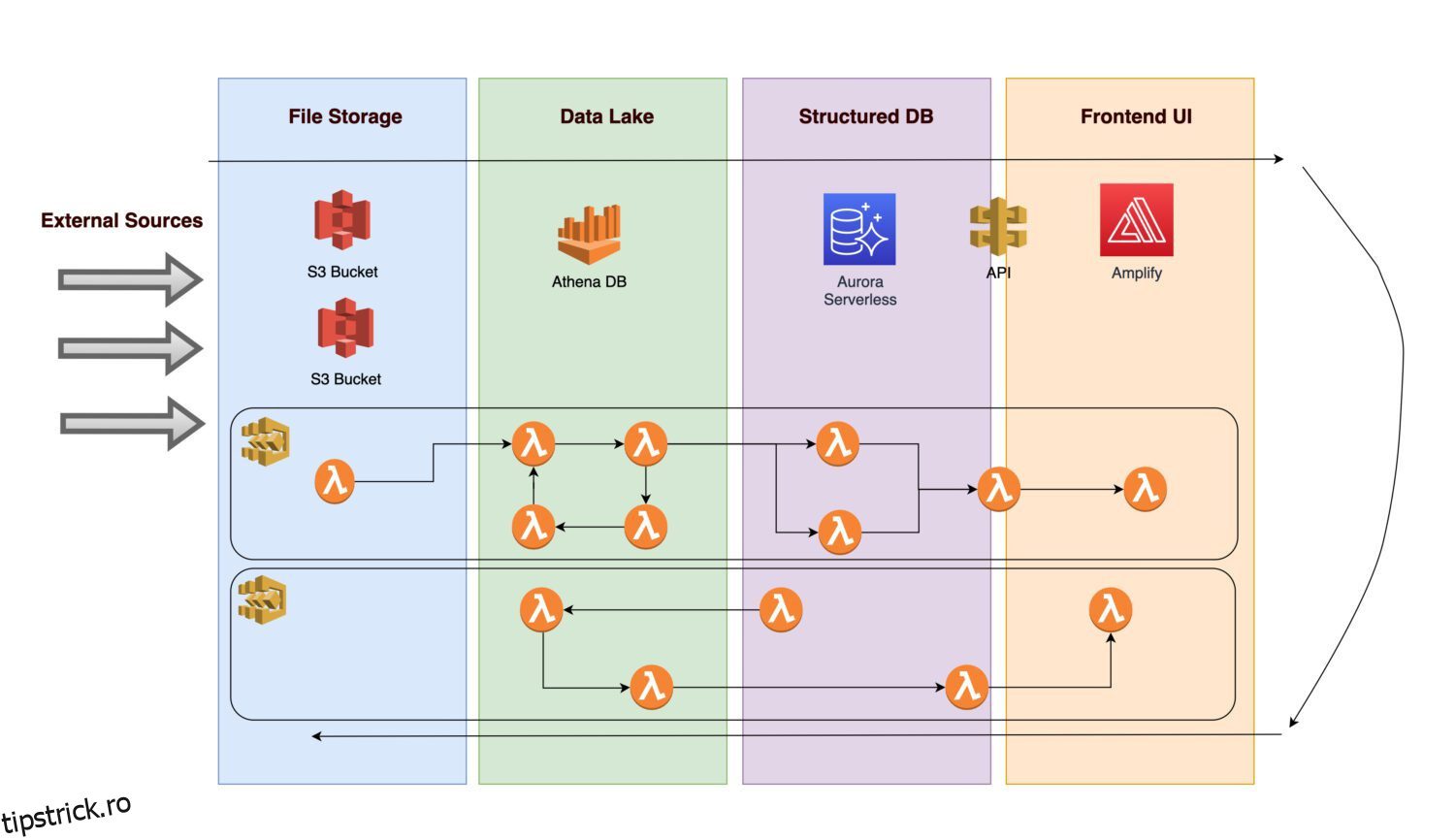
Imaginați-vă că doriți să creați o platformă pentru a aduna diverse date și imagini (sau fotografii) ale infrastructurii unor active din beton (aceasta poate fi orice activ de producție sau utilitate).
- Pentru a face posibile analize viitoare, este necesar ca datele primite să fie mai întâi ingerate.
- După aplicarea regulilor de afaceri, o procedură back-end salvează ieșirile calculate ca informații normalizate într-o bază de date relațională.
- O aplicație front-end care afișează date curate normalizate permite utilizatorilor să vadă rezultatele.
Să examinăm ce componente ar putea include arhitectura.
Găleți AWS S3
 Sursa: aws.amazon.com
Sursa: aws.amazon.com
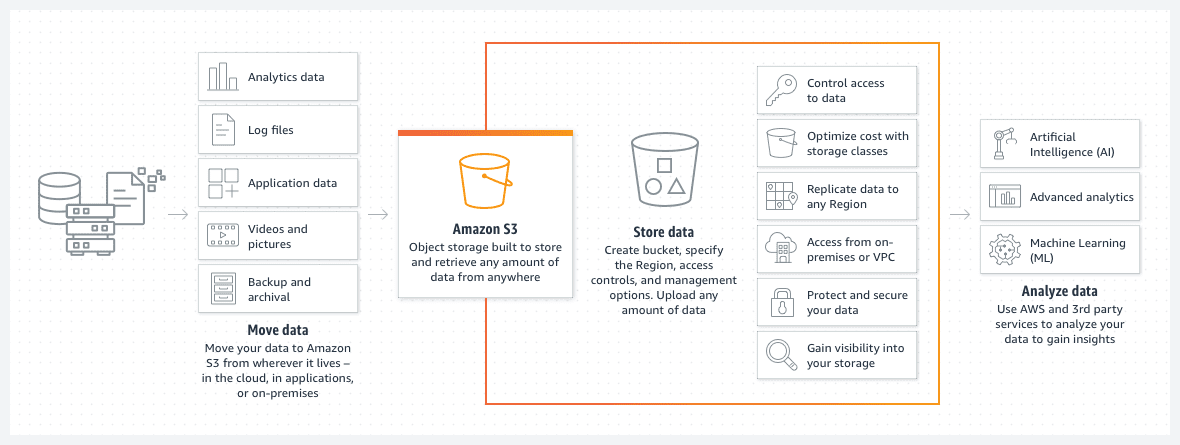
Bucket-urile Amazon S3 sunt o modalitate excelentă de a stoca fișiere sau imagini în cloud-ul AWS. Prețul stocării pe găleată S3 este remarcabil de scăzut. În plus, introducerea unei politici privind ciclul de viață al găleții S3 scade și mai mult acest preț.
O astfel de politică va muta automat fișierele mai vechi în diferite clase de compartimente S3, cum ar fi o arhivă sau acces la arhiva profundă. Clasele diferă și prin viteza timpului de acces, dar pentru datele vechi, aceasta va fi mai puțin o problemă. Acesta servește în principal pentru accesarea datelor arhivate în cazul unui eveniment urgent, mai degrabă decât pentru nevoile operaționale standard.
- Vă puteți organiza datele în subdosare.
- Ar trebui să setați restricții de permisiuni adecvate.
- Adăugați etichete în compartimente pentru a le face ușor de identificat și pentru o posibilă utilizare în cadrul politicilor dinamice de compartiment S3.
- Găleata este fără server prin design. Este pur și simplu un spațiu de stocare pentru datele dvs.
O găleată S3 este fără server prin design. Este pur și simplu un spațiu de stocare pentru datele dvs.
Baza de date AWS Athena
 Sursa: aws.amazon.com
Sursa: aws.amazon.com
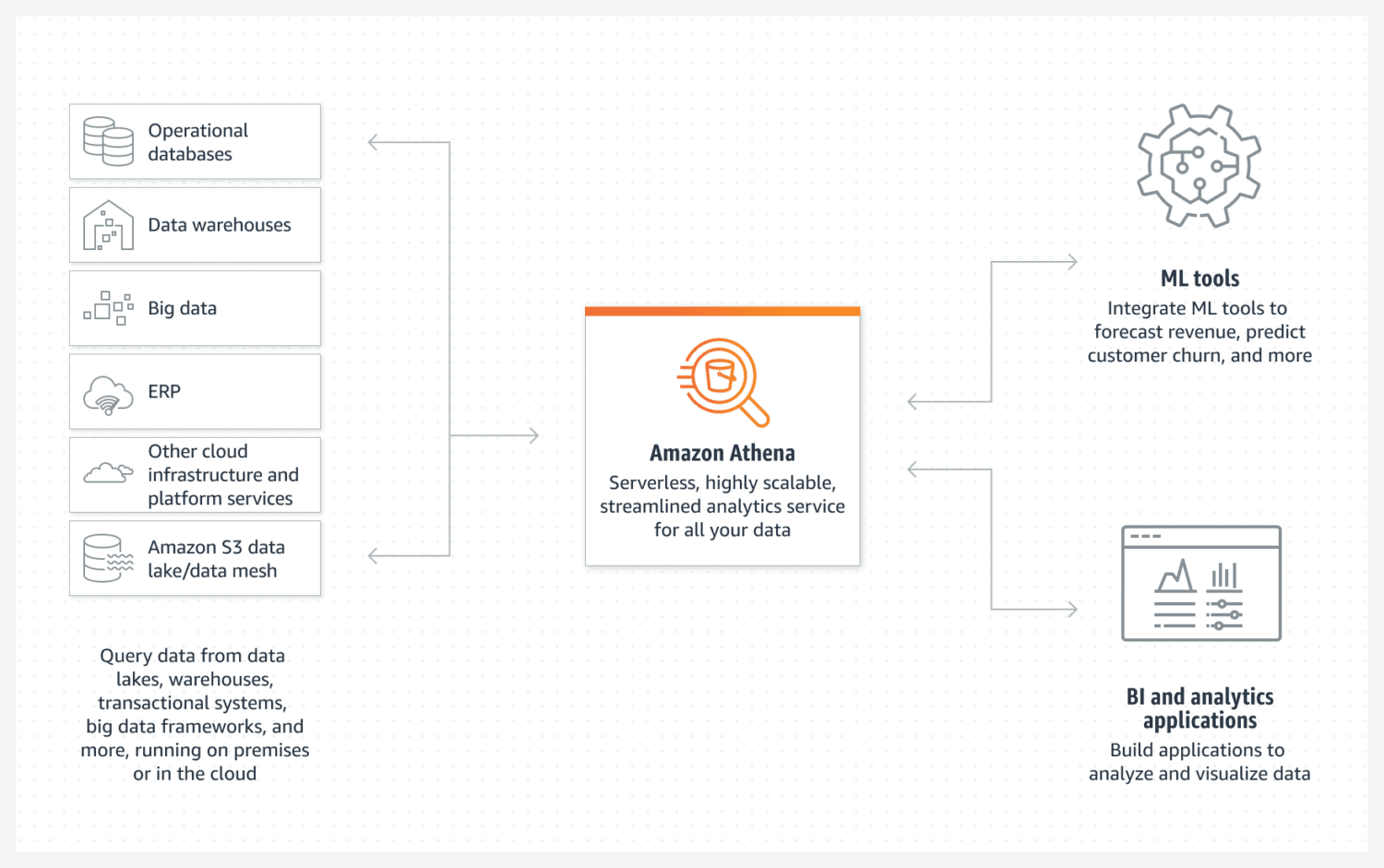
Athena facilitează crearea unui lac de date de bază AWS. Este o bază de date fără servere care utilizează o găleată S3 pentru a-și stoca datele. Organizarea datelor este menținută prin formate de fișiere structurate, cum ar fi fișierele cu parchet sau cu valori separate prin virgulă (CSV). Bucket-ul S3 deține fișierele, iar Athena se referă la ele ori de câte ori procesele selectează datele din baza de date.
Trebuie doar să știți că Athena nu acceptă diferite funcționalități considerate altfel standard, de exemplu, declarațiile de actualizare. Acesta este motivul pentru care trebuie să priviți Athena ca pe o opțiune foarte simplă.
Cu toate acestea, acceptă indexarea și partiționarea. De asemenea, se poate scala pe orizontală foarte ușor, deoarece acest lucru este la fel de complex ca și adăugarea de noi găleți la infrastructură. Pentru crearea unui lac de date simplu, dar funcțional, acest lucru poate fi suficient în majoritatea cazurilor.
Pentru o performanță bună, selectarea celui mai bun design de date, cu accent pe utilizarea viitoare, este esențială. Este esențial să fiți foarte clar cu privire la modul în care doriți să selectați datele. Recrearea tabelelor mai târziu, odată ce acestea sunt deja existente și umplute cu o mulțime de date, este dificilă.
Athena DB este o alegere excelentă și o potrivire bună pentru obiectivul dvs. dacă doriți să creați un grup de date simplu și imuabil, care este ușor de scalat orizontal în timp.
Baza de date AWS Aurora
 Sursa: aws.amazon.com
Sursa: aws.amazon.com
Athena DB excelează în stocarea datelor necurate. Acesta este modul în care doriți să stocați conținutul original pentru a maximiza reutilizarea lui viitoare, până la urmă. Cu toate acestea, este lent să furnizați rezultate selectate unei aplicații front-end.
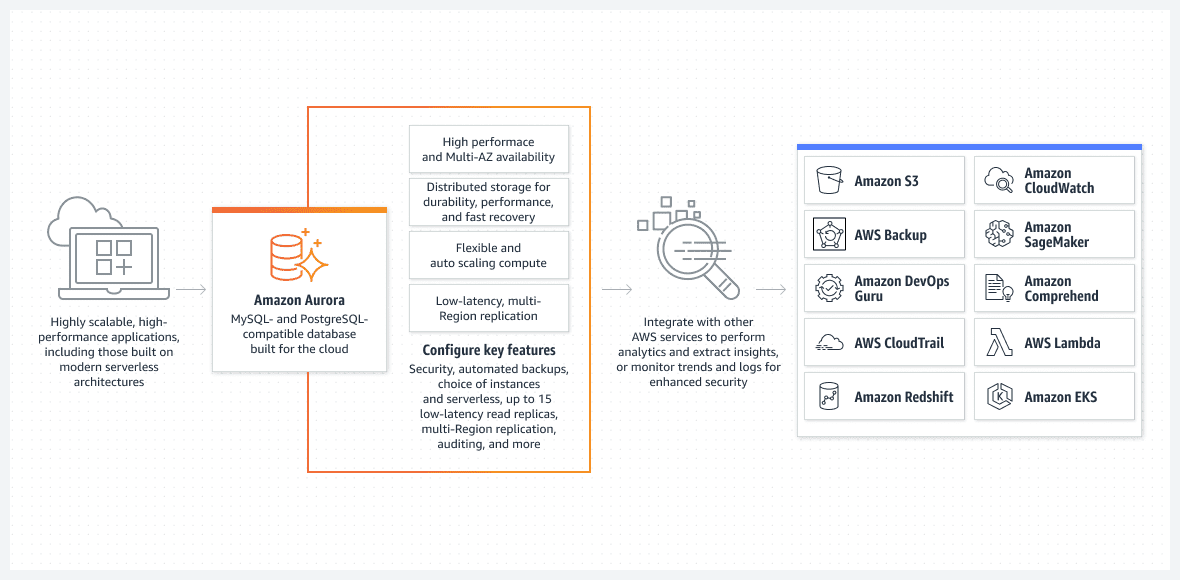
Una dintre cele mai bune opțiuni, în principal din perspectiva unei setări ușor de executat, este baza de date Aurora care rulează în modul serverless.
Aurora este departe de a fi o bază de date de bază. Este una dintre cele mai avansate soluții native de baze de date relaționale din AWS. Este, de asemenea, o soluție de bază de date relațională nativă extrem de complexă, care se îmbunătățește cu fiecare lansare.
Aurora este unică, deoarece poate rula în modul serverless, ceea ce o face să iasă în evidență față de alte servicii relaționale. Iată cum funcționează modul:
- Pentru a configura clusterul Aurora, utilizați consola AWS. Va trebui să specificați nivelurile standard de CPU și RAM, precum și intervalul maxim de funcționalitate auto-scale. Acest lucru va afecta performanța pe care clusterul Aurora o poate adăuga sau elimina dinamic. Pe baza utilizării curente a bazei de date, AWS decide să crească sau să scadă.
- Clusterul Aurora nu va porni decât dacă utilizatorul sau procesul inițiază o solicitare reală. De exemplu, când începe procesarea programată în lot. Sau dacă aplicația efectuează un apel API back-end pentru a prelua date dintr-o bază de date. Baza de date se va deschide automat și va rămâne activă o perioadă predeterminată după finalizarea proceselor de solicitare.
- Clusterul Aurora se va închide automat dacă nu mai este de lucru în baza de date.
Pentru a sublinia încă o dată, Aurora DB fără server rulează numai atunci când trebuie să facă o muncă reală. Clusterul pornit automat se va închide din nou dacă nu procesează nicio lucrare. Munca efectivă este ceea ce plătești și nu timpul tău inactiv.
Aurora fără server este gestionată integral de AWS și nu necesită administrator.
AWS Amplify
Amplify oferă o platformă fără server pentru implementarea rapidă a aplicațiilor front-end realizate cu bibliotecile JavaScript și React. Nu este nevoie să configurați servere de cluster. Utilizați consola AWS pentru a implementa codul direct sau utilizați o conductă DevOps automatizată.
Puteți apela API-uri back-end pentru a ajunge la datele stocate în bazele de date. Aceste apeluri vă permit să accesați datele reale în aplicația front-end. Principala optimizare a performanței pe back-end ar trebui făcută de echipă. Puteți reduce și mai mult posibilitatea unui răspuns lent în UI dacă proiectați direct instrucțiuni select eficiente în apelurile API.
Funcții AWS Step
 Sursa: aws.amazon.com
Sursa: aws.amazon.com
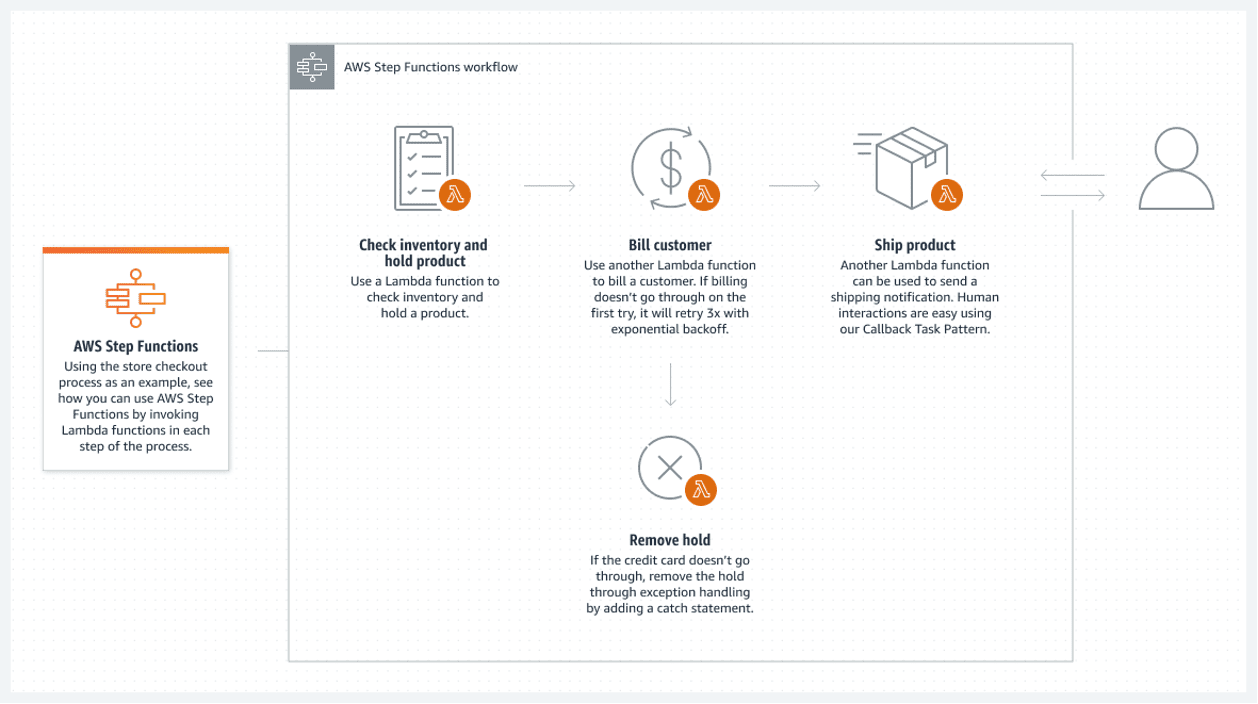
Chiar dacă toate componentele majore ale unui sistem sunt fără server, acest lucru nu garantează o arhitectură complet fără server. Acest lucru este posibil numai dacă toate procesele batch dintre componente sunt fără server.
Funcțiile AWS Step oferă cea mai bună soluție pe cloud AWS. O listă conectată de funcții AWS Lambda alcătuiește funcția pas. Aceste funcții creează o diagramă de flux care are stări clare de început și de sfârșit. O funcție lambda, de obicei scrisă în limbaje Python sau Node JS, este un fragment executabil de cod care procesează orice este necesar.
Următorul este un exemplu despre cum ați putea executa o funcție pas:
Acest flux fără server are un dezavantaj major: fiecare funcție lambda poate rula maxim 15 minute. Prin urmare, împărțirea fluxului în funcții lambda mai mici poate face acest lucru mai puțin problematic.
Este posibil să apelați mai multe funcții lambda simultan într-un singur pas, ceea ce înseamnă practic paralelizarea unui pas cu mai multe lambda executate simultan. Așteptați ca toate procesările lambda paralele să se termine înainte de a continua. Apoi, treceți la următoarea procesare lambda.
Cuvinte finale
Arhitectura serverless oferă o oportunitate unică de a crea o platformă cloud care acoperă întregul peisaj al sistemului. Această platformă este scalabilă pe orizontală și are costuri de operare scăzute în timp ce face acest lucru.
Este soluția perfectă pentru proiectele cu buget limitat. Este o opțiune excelentă de explorare, de obicei atunci când nimeni nu cunoaște realitatea încărcăturii de producție. Acest lucru este important mai ales după ce ați încorporat cu succes toți utilizatorii. Este posibil ca echipele de proiect să aibă în continuare o vedere de ansamblu asupra modului în care funcționează sistemul. Puteți avea toate aceste beneficii și tot nu este nevoie să acceptați compromisuri.
Această acoperire nu va fi adecvată pentru toate cazurile, în special pentru cele care implică o utilizare ridicată a procesorului. Cu toate acestea, cloud-ul AWS evoluează constant în ceea ce privește cazurile de utilizare fără server. De obicei, este o idee bună să efectuați o cercetare amănunțită înainte de a vă decide asupra opțiunii fără server pentru următorul dvs. proiect cloud AWS.
Apoi, verificați cele mai bune baze de date fără server pentru aplicații moderne.