
Să aflăm cum vă puteți menține producția de încredere cu ajutorul instrumentelor Chaos Engineering.
Ingineria haosului este o disciplină în care experimentezi sistemul sau aplicația pentru a-i dezvălui punctele slabe și deficiența capacității. Acestea sunt ceva ce nu credeai că s-ar putea întâmpla în timp ce le creați. Deci, ați provoca unele defecțiuni intenționate ale sistemului dvs. pentru a-și arăta punctele slabe pentru a face remedierea și a face sistemul și aplicația dvs. mai rezistente.
Multe organizații populare precum Netflix, LinkedIn și Facebook efectuează inginerie haos pentru a înțelege mai bine arhitectura microserviciilor și sistemele distribuite. Vă ajută să găsiți noi probleme mai devreme decât plângerile reale ale utilizatorilor și să luați măsurile necesare pentru a le corecta. Astfel, aceste organizații pot deservi milioane de utilizatori, își pot crește productivitatea și pot economisi milioane de dolari 🤑.
Beneficiile Chaos Engineering:
- Controlați pierderile din venituri prin găsirea problemelor critice
- Reducerea defecțiunilor sistemului sau aplicației
- Experiență de utilizator mai bună, cu mai puține întreruperi și disponibilitate ridicată a serviciilor
- Te ajută să înveți despre sistem și să câștigi încredere.
Cât de încrezător sunteți în ceea ce privește fiabilitatea producției dvs.? Este adevărat rezistent la dezastre?
Să aflăm cu ajutorul următoarelor instrumente populare de testare a haosului.
Cuprins
Chaos Mesh
Chaos Mesh este o soluție de management al ingineriei haosului care injectează defecte în fiecare strat al unui sistem Kubernetes. Aceasta include pod-uri, rețeaua, I/O de sistem și nucleul. Chaos Mesh poate ucide automat podurile Kubernetes și poate simula latențe. Poate perturba comunicarea de la pod la pod și poate simula erori de citire/scriere. Poate programa reguli pentru experimente și poate defini domeniul de aplicare a acestora. Aceste experimente sunt specificate folosind fișiere YAML.
Chaos Mesh are un tablou de bord pentru a vizualiza analizele experimentelor. Acesta rulează pe Kubernetes și acceptă majoritatea platformei cloud. Este open-source și a fost acceptat recent ca proiect sandbox CNCF. Folosind principiile ingineriei haosului, puteți adăuga Chaos Mesh fluxului de lucru DevOps pentru a crea aplicații rezistente.
Caracteristici Chaos Engineering:
- Este ușor de implementat pe clustere Kubernetes, fără nicio modificare a logicii de implementare
- Nu sunt necesare dependențe unice pentru implementare
- Definește obiectele haos folosind CustomResourceDefinitions (CRD)
- Oferă un tablou de bord pentru a urmări toate experimentele
Kit de instrumente Chaos este un instrument simplu și open-source pentru Chaos Engineering Experiment Automation.
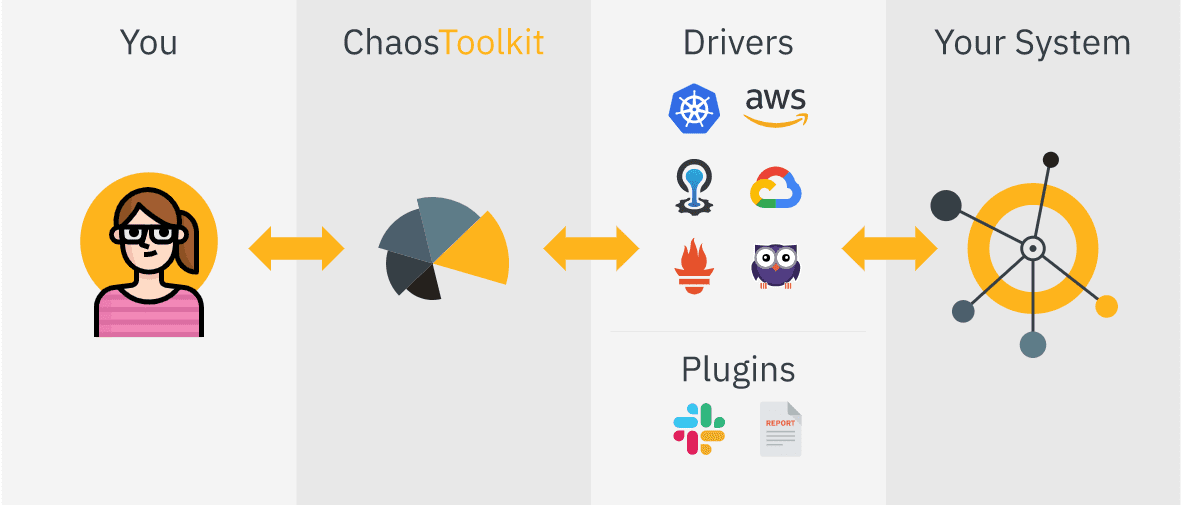
Integrați Chaos ToolKit cu sistemul dvs. folosind un set de drivere sau pluginuri pe care le acceptă AWS, Google Cloud, Slack, Prometheus etc.
Caracteristici Chaos Toolkit:
- Oferă API deschisă declarativă pentru a crea experimente haos independente de un furnizor sau tehnologie
- Poate fi ușor încorporat în conductele CICD pentru automatizare
- Oferă suport comercial și de întreprindere și prin ChaosIQ
ChaosKube
După cum puteți ghici după nume, este pentru Kubernetes.
Chaoskube este un instrument de haos open-source care ucide periodic poduri aleatorii din clusterul Kubernetes. Vă ajută să înțelegeți cum va reacționa sistemul dvs. atunci când podul eșuează. În mod implicit, omoara un pod în orice spațiu de nume la fiecare 10 minute. Puteți filtra podurile țintă în Chaoskube folosind spații de nume, etichete, adnotări etc. Poate fi instalat cu ușurință folosind Chaoskube.

Maimuța haosului
Maimuța haosului este un instrument folosit pentru a verifica rezistența sistemelor cloud prin crearea intenționată de defecțiuni pentru ca acele sisteme să înțeleagă reacția lor. Netflix l-a creat pentru a-și testa rezistența și recuperabilitatea infrastructurii AWS. A fost numită Chaos Monkey pentru că creează distrugere ca o maimuță sălbatică și înarmată pentru a testa eșecurile.
De asemenea, a fost Chaos Monkey, care a dat naștere noii practici de inginerie Chaos Engineering. A fost creat pe principiul că este mai bine să eșuezi în mod repetat pentru a evita orice eșec semnificativ brusc.
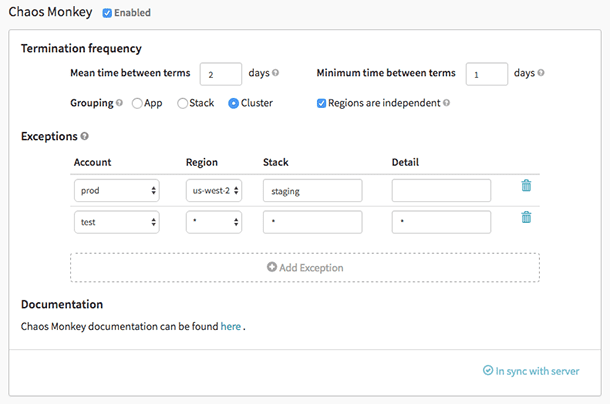
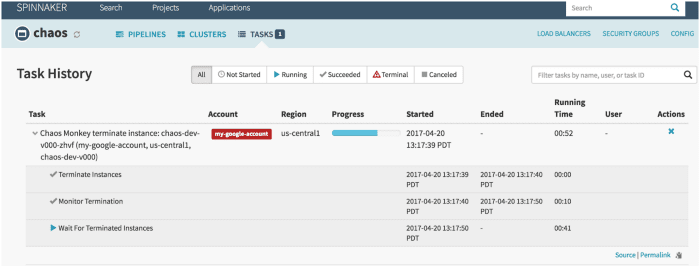
Caracteristicile Chaos Monkey:
- Vă ajută să vă pregătiți pentru erori aleatorii ale instanțelor.
- Încurajează redundanța pentru eșecuri neașteptate
- Utilizează Spinnaker pentru a activa compatibilitatea între cloud
- Oferă un program configurabil pentru a simula defecțiunile
- Integrat cu guvernator pentru a adăuga orice dependențe noi la maimuța haos
Simmy
Simmy este un instrument de haos de injectare a erorilor care se integrează cu proiectul de rezistență Polly pentru .NET. Vă permite să creați politici de injectare haos prin Polly, unde vă executați codurile. Oferă politici diferite, cum ar fi politica de excepții pentru a injecta excepții în sistem, politica de comportament pentru a injecta orice comportament nou etc. Aceste politici sunt concepute pentru a injecta comportamentul la întâmplare.
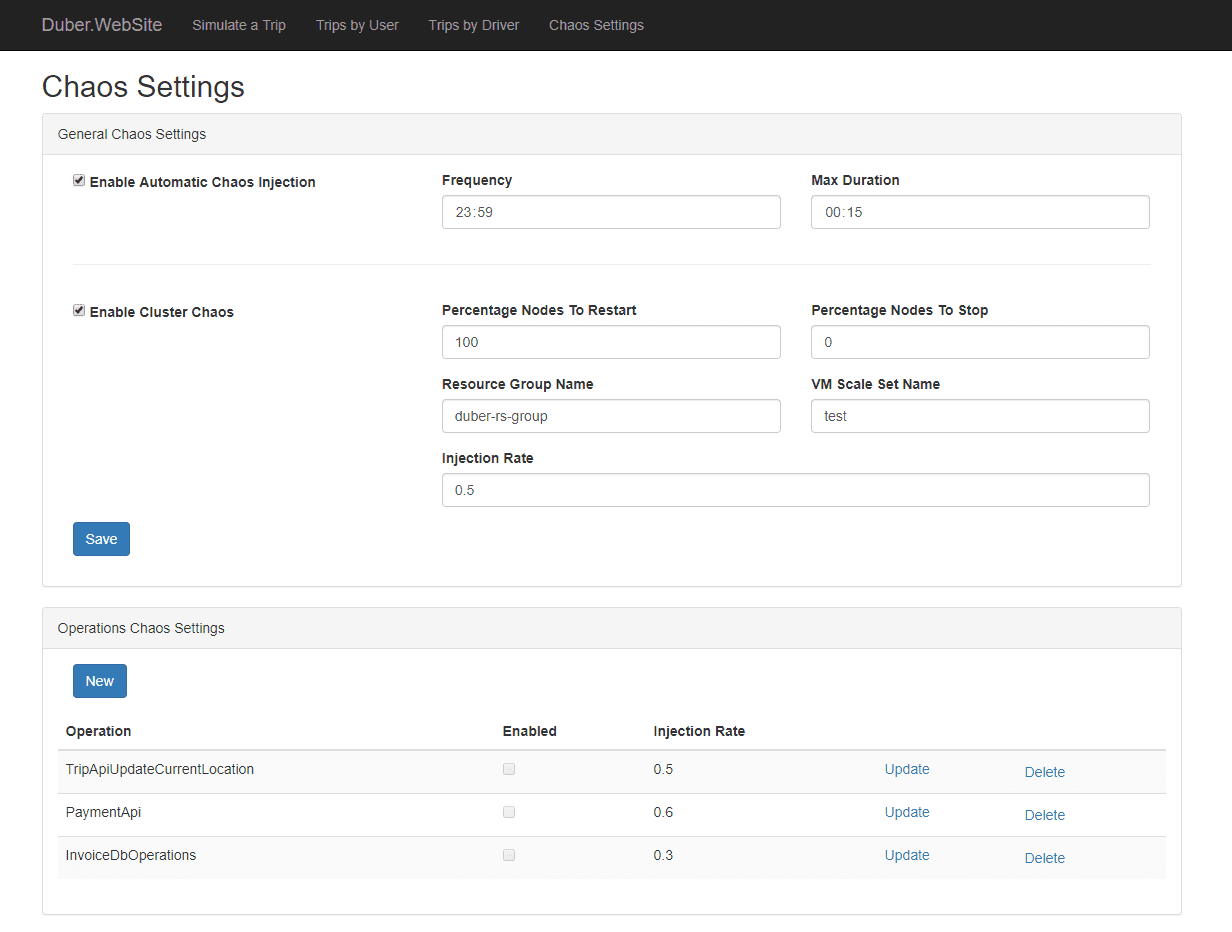
Caracteristicile Simmy:
- Oferă politici Monkey sau Chaos pentru a injecta haos
- Ușor de testat orice eșec de dependență
- Ajută la revenirea rapidă la modelul de lucru și controlează raza exploziei.
- Este gata pentru producție.
- Poate defini defecțiuni pe baza unor factori externi (de exemplu, eșecuri datorate configurației globale)
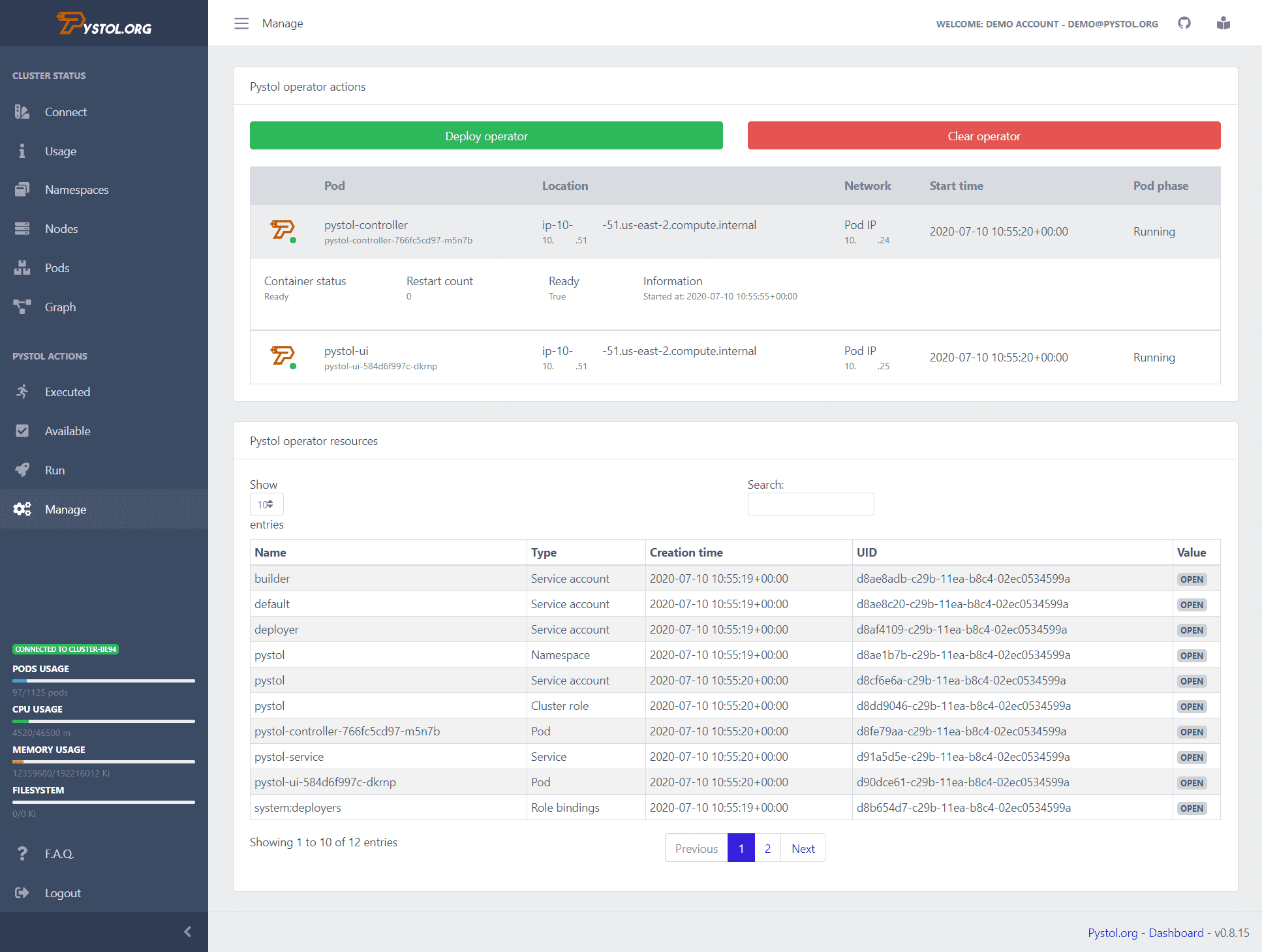
Pistol
Pistol este un instrument care este utilizat pentru injectarea injecțiilor defecte în medii native cloud. Urmărește evenimentele din ETCD prin operatorii Kubernetes. Când se execută o acțiune de injectare a erorilor, operatorii creează pod-urile și rulează unele colecții Ansible. Deci, dezvoltatorii nu trebuie să își scrie propriile acțiuni pentru a efectua.
Pystol oferă acțiuni gata făcute pentru a testa sistemul. Totuși, dacă un dezvoltator dorește să creeze o acțiune nouă, aceasta poate fi făcută folosind GoLang și Python.
Oferă un tablou de bord de integrare continuă pentru a oferi o imagine rezumată a tuturor operațiunilor de muncă. Puteți rula Pystol local sau îl puteți implementa într-un container folosind imaginea docker. Pystol oferă două interfețe, una este Web UI, iar cealaltă este prin CLI. Evident, Web UI este o opțiune mai bună.
Muxy
Muxy este un proxy pentru a vă testa reziliența și modelele de toleranță la erori pentru defecțiunile sistemelor distribuite din lumea reală. Poate modifica nivelul de transport (nivelul 4), nivelul sesiunii TCP (stratul 5) și nivelul protocolului HTTP (nivelul 7).
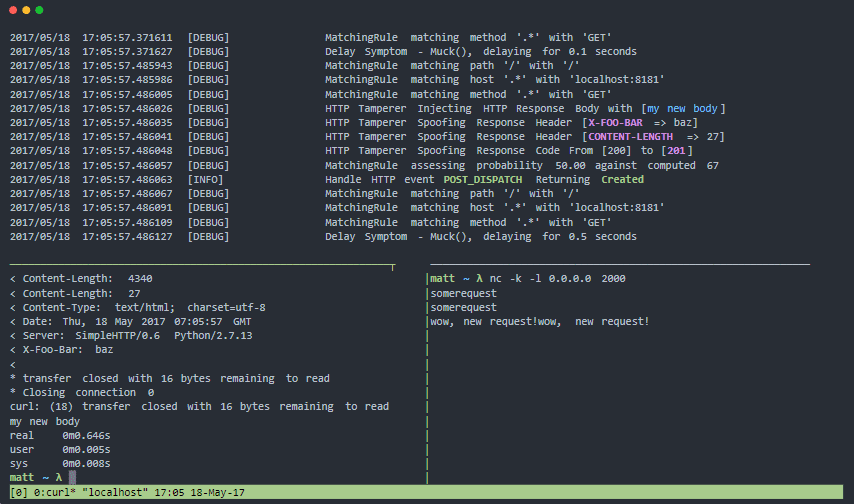
Caracteristici Muxy:
- Arhitectura modulara si usor extensibila
- Are container docker oficial
- Ușor de instalat, nu necesită dependențe.
- Ideal pentru testarea continuă a rezistenței
- Simulează problemele de conectivitate la rețea pentru sistemele distribuite și dispozitivele mobile
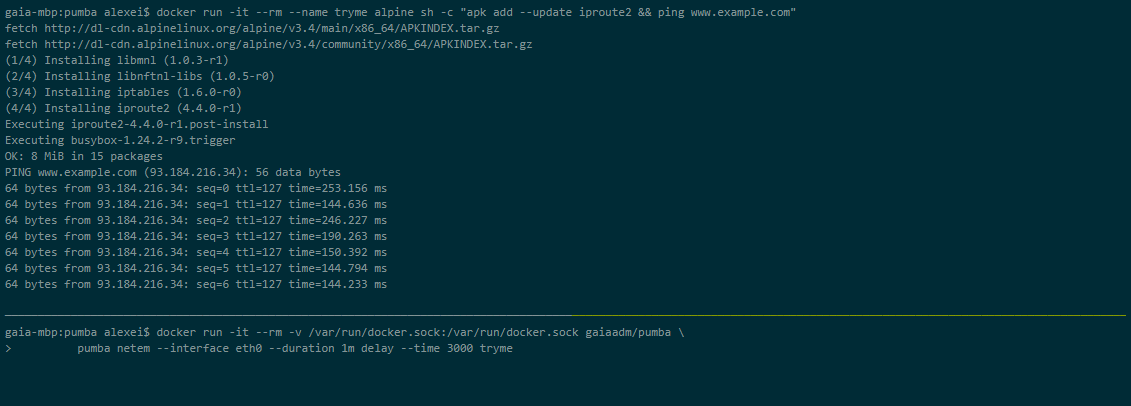
Pumba
Pumba este un instrument de linie de comandă care efectuează teste de haos pentru containerele docker. Cu Pumba, blocați în mod intenționat containerele docker ale aplicației pentru a vedea cum reacționează sistemul. De asemenea, puteți efectua teste de stres asupra resurselor containerului, cum ar fi CPU, memorie, sistem de fișiere, intrare/ieșire etc.
Puteți rula Pumba și pe un cluster Kubernetes. Trebuie să utilizați DaemonSets pentru a implementa Pumba pe nodurile Kubernetes. Puteți utiliza mai multe containere Pumba pentru a rula mai multe comenzi Pumba în același DaemonSet.
ChaosBlade
ChaosBlade este un instrument open-source pentru a injecta experimente în sistemele Alibaba. Testează toate eșecurile cu care s-a confruntat Alibaba în ultimii zece ani și aplică cele mai bune practici pentru a le evita. Urmează principiile ingineriei haosului pentru a verifica toleranța la erori a sistemelor distribuite.
Caracteristicile ChaosBlade:
- Oferă scenarii experimentale pentru mai multe resurse, cum ar fi CPU, rețea, memorie, disc etc.
- Oferă scenarii experimentale pentru noduri, rețele și pod-uri pe platforma Kubernetes
- Oferă comenzi CLI ușor de utilizat pentru a executa experimente
Turnesol
Turnesol urmează principiile de inginerie a haosului nativ din cloud. Misiunea instrumentului turnesol este de a oferi un cadru complet pentru identificarea punctelor slabe în sistemele dvs. Kubernetes și în aplicațiile dvs. care rulează pe Kubernetes.
Are un operator de haos și CRD-urile (CustomResourceDefinitions) în jurul acestuia, permițând capacitatea plug-and-play. Totul este să vă puneți logica haosului într-o imagine docker, să o aruncați într-un cadru de turnesol și să le orchestrați folosind CRD-urile.

Caracteristici de turnesol:
- Ajută inginerii și dezvoltatorii Site Reliability să găsească punctele slabe ale sistemului Kubernetes
- Oferă experimente generice gata de utilizare
- Oferă Chaos API pentru gestionarea fluxului de lucru haos
- Litmus SDK acceptă Go, Python și Ansible pentru a vă crea propriile experimente.
Gremlin
Gremlin ajută inginerii să construiască software mai rezistent. Oferă o platformă pentru a rula experimente de inginerie haos în siguranță, în siguranță și direct.

Puteți injecta cu atenție eșec în gazde sau containere cu gremlin, indiferent de locul în care se află, fie că este vorba despre cloud public sau propriul dvs. centru de date.
Caracteristicile Gremlin:
- Instalează un agent ușor pe gazde sau containere pentru a injecta erori
- Oferă peste 10 moduri diferite de atac la infrastructură
- State gremlins vă permit să manipulați timpul sistemului, să închideți sau reporniți gazdele și să ucideți procesoarele.
- Gremlinii din rețea pot injecta latență pentru a introduce pierderi de pachete sau pentru a reduce traficul.
- Atacurile de bibliotecă Alfi ale lui Gremlin pot fi configurate, pornite și oprite prin intermediul aplicației web. API sau CLI
- Vă permite să vizați cu precizie raza exploziei pe care doriți să o atacați
- Vă permite să opriți toate atacurile și să aduceți sistemul înapoi la o stare de echilibru
Steadybit
Steadybit își propune să reducă timpul de nefuncționare în mod proactiv și oferă vizibilitate asupra problemelor sistemului. Puteți rula acest instrument local pe infrastructura dvs. sau cloud ca serviciu (SaaS).
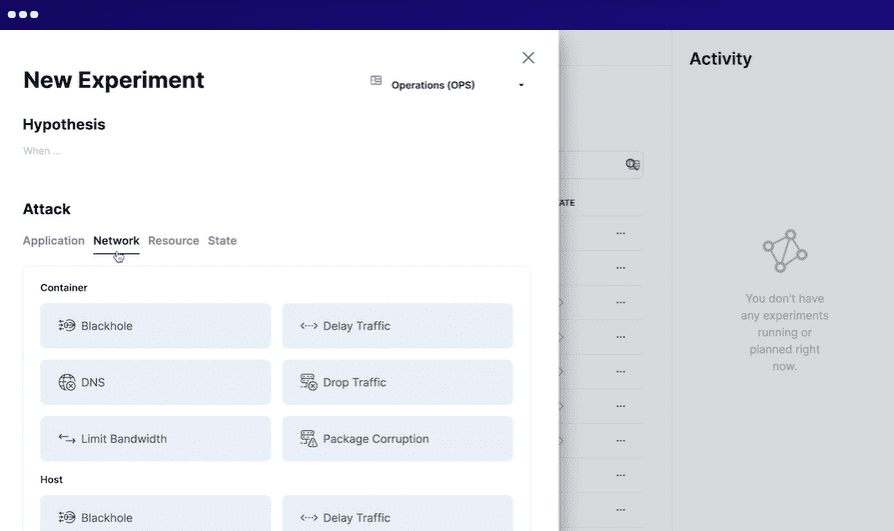
Pentru a utiliza Steadybit, definiți situația, simulați experimentele, executați experimentele simulate în producție și automatizați toate experimentele. Rulează agenți inteligenți pe sistemul dvs. pentru a descoperi potențiale probleme și puncte slabe. Se integrează cu mai multe sisteme cu ușurință.
Concluzie
Continuați și fiți suficient de curajos pentru a aplica principiile ingineriei haosului și a vă testa producția cu instrumentele menționate mai sus. Aceste instrumente vă vor ajuta să găsiți mai multe puncte slabe neidentificate în sistemul dvs. și vă vor ajuta să vă faceți sistemul mai rezistent.