

Milioane de înregistrări de date sunt generate în fiecare zi în sistemele de calcul actuale. Acestea includ tranzacțiile dvs. financiare, plasarea unei comenzi sau datele de la senzorul mașinii dvs. Pentru a procesa aceste evenimente de streaming de date în timp real și pentru a muta în mod fiabil înregistrările evenimentelor între diferite sisteme de întreprindere, aveți nevoie Apache Kafka.
Apache Kafka este o soluție de flux de date open-source care gestionează peste 1 milion de înregistrări pe secundă. Pe lângă acest debit mare, Apache Kafka oferă scalabilitate și disponibilitate ridicate, latență scăzută și stocare permanentă.
Companii precum LinkedIn, Uber și Netflix se bazează pe Apache Kafka pentru procesarea în timp real și fluxul de date. Cel mai simplu mod de a începe să utilizați Apache Kafka este să îl aveți în funcțiune pe mașina dvs. locală. Acest lucru vă permite nu numai să vedeți serverul Apache Kafka în acțiune, dar vă permite și să produceți și să consumați mesaje.
Având experiență practică în pornirea serverului, crearea de subiecte și scrierea codului Java utilizând clientul Kafka, veți fi gata să utilizați Apache Kafka pentru a vă îndeplini toate nevoile pipelinei de date.
Cuprins
Cum să descărcați Apache Kafka pe mașina dvs. locală
Puteți descărca cea mai recentă versiune de Apache Kafka din link oficial. Conținutul descărcat va fi comprimat în format .tgz. Odată descărcat, va trebui să extrageți același lucru.
Dacă sunteți Linux, deschideți terminalul. Apoi, navigați la locația de unde ați descărcat versiunea comprimată Apache Kafka. Rulați următoarea comandă:
tar -xzvf kafka_2.13-3.5.0.tgz
După finalizarea comenzii, veți găsi că un nou director numit kafka_2.13-3.5.0. Navigați în interiorul folderului folosind:
cd kafka_2.13-3.5.0
Acum puteți lista conținutul acestui director folosind comanda ls.
Pentru utilizatorii de Windows, puteți urma aceiași pași. Dacă nu puteți găsi comanda tar, puteți utiliza un instrument terță parte precum WinZip pentru a deschide arhiva.
Cum să porniți Apache Kafka pe mașina dvs. locală
După ce ați descărcat și extras Apache Kafka, este timpul să începeți să îl rulați. Nu are instalatori. Puteți începe direct să îl utilizați prin linia de comandă sau prin fereastra terminalului.
Înainte de a începe cu Apache Kafka, asigurați-vă că aveți Java 8+ instalat pe sistemul dvs. Apache Kafka necesită o instalare Java care rulează.
#1. Rulați serverul Apache Zookeeper
Primul pas este rularea Apache Zookeeper. Îl primiți pre-descărcat ca parte a arhivei. Este un serviciu care este responsabil pentru menținerea configurațiilor și furnizarea de sincronizare pentru alte servicii.
Odată ce vă aflați în directorul de unde ați extras conținutul arhivei, executați următoarea comandă:
Pentru utilizatorii Linux:
bin/zookeeper-server-start.sh config/zookeeper.properties
Pentru utilizatorii de Windows:
bin/windows/zookeeper-server-start.bat config/zookeeper.properties
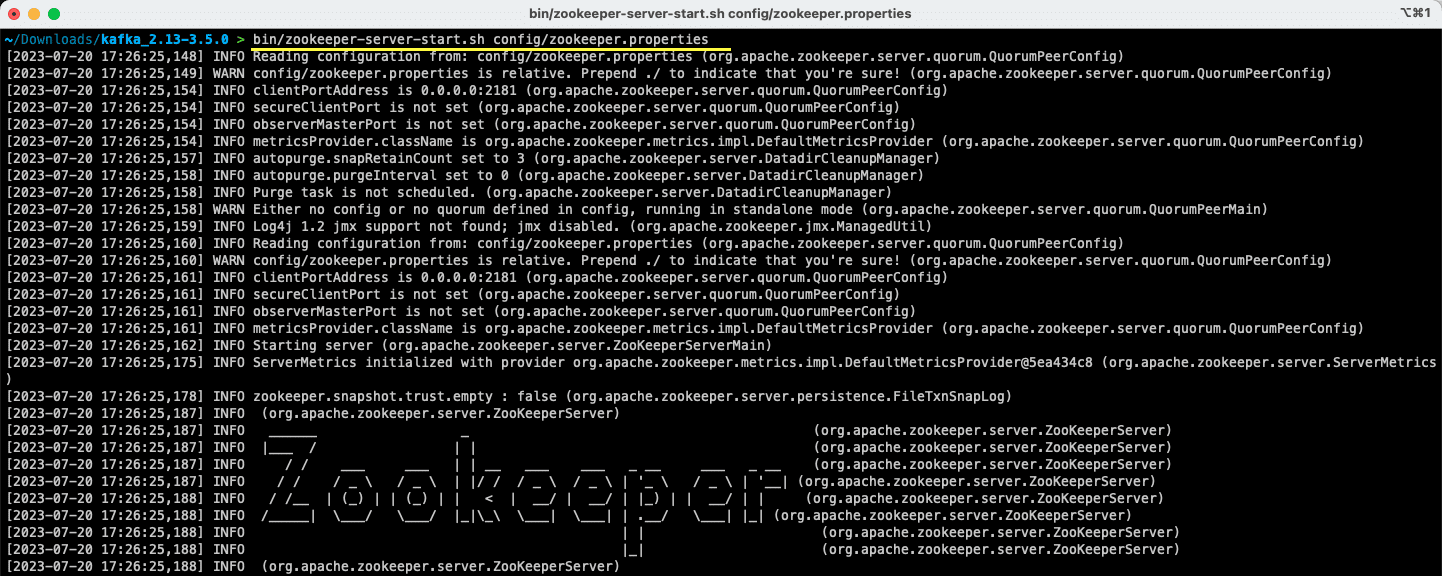
Fișierul zookeeper.properties oferă configurațiile pentru rularea serverului Apache Zookeeper. Puteți configura proprietăți precum directorul local în care vor fi stocate datele și portul pe care va rula serverul.
#2. Porniți serverul Apache Kafka
Acum că serverul Apache Zookeeper a fost pornit, este timpul să porniți serverul Apache Kafka.
Deschideți un nou terminal sau fereastră de linie de comandă și navigați la directorul în care sunt prezente fișierele extrase. Apoi puteți porni serverul Apache Kafka folosind comanda de mai jos:
Pentru utilizatorii Linux:
bin/kafka-server-start.sh config/server.properties
Pentru utilizatorii de Windows:
bin/windows/kafka-server-start.bat config/server.properties
Aveți serverul Apache Kafka în funcțiune. În cazul în care doriți să modificați configurația implicită, puteți face acest lucru modificând fișierul server.properties. Diferitele valori sunt prezente în documentație oficială.
Cum să utilizați Apache Kafka pe mașina dvs. locală
Acum sunteți gata să începeți să utilizați Apache Kafka pe mașina dvs. locală pentru a produce și consuma mesaje. Deoarece serverele Apache Zookeeper și Apache Kafka sunt în funcțiune, haideți să vedem cum puteți crea primul subiect, produce primul mesaj și consuma același lucru.
Care sunt pașii pentru a crea un subiect în Apache Kafka?
Înainte de a crea primul subiect, să înțelegem ce este de fapt un subiect. În Apache Kafka, un subiect este un depozit de date logic care ajută la fluxul de date. Gândiți-vă la el ca la canalul prin care datele sunt transportate de la o componentă la alta.
Un subiect acceptă multi-producători și multi-consumatori – mai mult de un sistem poate scrie și citi dintr-un subiect. Spre deosebire de alte sisteme de mesagerie, orice mesaj dintr-un subiect poate fi consumat de mai multe ori. În plus, puteți menționa și perioada de păstrare a mesajelor dvs.
Să luăm exemplul unui sistem (producător) care produce date pentru tranzacțiile bancare. Și un alt sistem (consumator) consumă aceste date și trimite o notificare de aplicație utilizatorului. Pentru a facilita acest lucru, este necesar un subiect.
Deschideți un nou terminal sau o fereastră de linie de comandă și navigați la directorul de unde ați extras arhiva. Următoarea comandă va crea un subiect numit tranzacții:
Pentru utilizatorii Linux:
bin/kafka-topics.sh --create --topic transactions --bootstrap-server localhost:9092
Pentru utilizatorii de Windows:
bin/windows/kafka-topics.bat --create --topic transactions --bootstrap-server localhost:9092
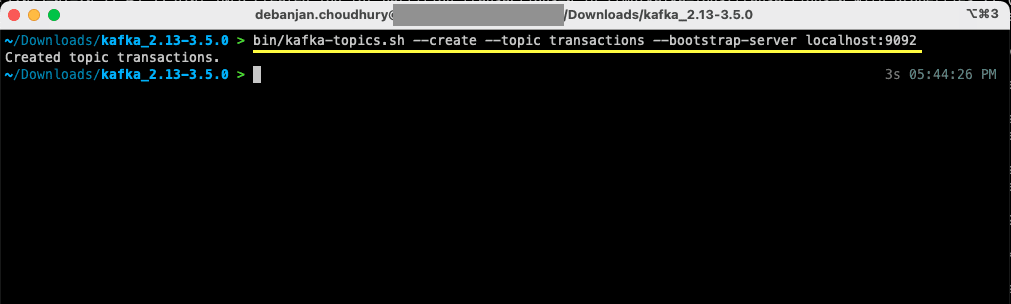
Acum ați creat primul subiect și sunteți gata să începeți să produceți și să consumați mesaje.
Cum se transmite un mesaj către Apache Kafka?
Cu subiectul dvs. Apache Kafka gata, acum puteți produce primul mesaj. Deschideți un nou terminal sau o fereastră de prompt de comandă sau utilizați aceeași pe care ați folosit-o pentru a crea subiectul. Apoi, asigurați-vă că vă aflați în directorul corespunzător de unde ați extras conținutul arhivei. Puteți utiliza linia de comandă pentru a produce mesajul dvs. pe acest subiect utilizând următoarea comandă:
Pentru utilizatorii Linux:
bin/kafka-console-producer.sh --topic transactions --bootstrap-server localhost:9092
Pentru utilizatorii de Windows:
bin/windows/kafka-console-producer.bat --topic transactions --bootstrap-server localhost:9092
Odată ce executați comanda, veți vedea că terminalul sau fereastra promptului de comandă așteaptă intrarea. Scrie primul tău mesaj și apasă Enter.
> This is a transactional record for $100
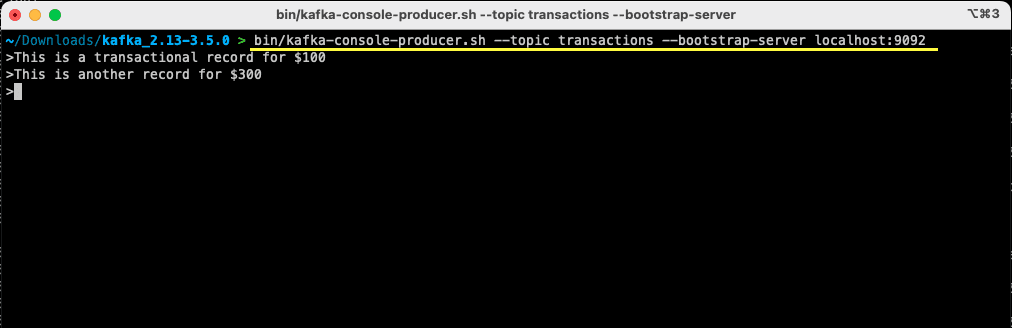
Ați transmis primul mesaj către Apache Kafka pe mașina dvs. locală. Ulterior, sunteți acum gata să consumați acest mesaj.
Cum să consumi un mesaj de la Apache Kafka?
Cu condiția ca subiectul dvs. să fi fost creat și ați produs un mesaj pentru subiectul dvs. Kafka, acum puteți consuma acel mesaj.
Apache Kafka vă permite să atașați mai mulți consumatori la același subiect. Fiecare consumator poate face parte dintr-un grup de consumatori – un identificator logic. De exemplu, dacă aveți două servicii care trebuie să consume aceleași date, atunci acestea pot avea grupuri de consumatori diferite.
Cu toate acestea, dacă aveți două instanțe ale aceluiași serviciu, atunci ați dori să evitați să consumați și să procesați același mesaj de două ori. În acest caz, ambii vor avea același grup de consumatori.
În fereastra terminalului sau prompt de comandă, asigurați-vă că vă aflați în directorul corespunzător. Utilizați următoarea comandă pentru a porni consumatorul:
Pentru utilizatorii Linux:
bin/kafka-console-consumer.sh --topic transactions --from-beginning --bootstrap-server localhost:9092 --group notif-consumer
Pentru utilizatorii de Windows:
bin/windows/kafka-console-consumer.bat --topic transactions --from-beginning --bootstrap-server localhost:9092 --group notif-consumer

Veți vedea pe terminalul dvs. mesajul pe care l-ați produs anterior. Acum ați folosit Apache Kafka pentru a vă consuma primul mesaj.
Comanda kafka-console-consumer preia o mulțime de argumente transmise. Să vedem ce înseamnă fiecare dintre ele:
- Subiectul menționează subiectul de unde vei consuma
- –de la început îi spune consumatorului consolei să înceapă să citească mesajele chiar de la primul mesaj prezent
- Serverul dvs. Apache Kafka este menționat prin opțiunea –bootstrap-server
- În plus, puteți menționa grupul de consumatori trecând parametrul –group
- În absența unui parametru de grup de consumatori, acesta este generat automat
Cu consumatorul de consolă în funcțiune, puteți încerca să produceți mesaje noi. Vei vedea că toate sunt consumate și apar în terminalul tău.
Acum că ți-ai creat subiectul și ai produs și consumat cu succes mesaje, haideți să îl integrăm cu o aplicație Java.
Cum să creați producător și consumator Apache Kafka folosind Java
Înainte de a începe, asigurați-vă că aveți instalat Java 8+ pe mașina dvs. locală. Apache Kafka oferă propria bibliotecă client care vă permite să vă conectați fără probleme. Dacă utilizați Maven pentru a vă gestiona dependențele, adăugați următoarea dependență la pom.xml
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.5.0</version>
</dependency>
De asemenea, puteți descărca biblioteca din Depozitul Maven și adăugați-l la calea clasei Java.
Odată ce biblioteca este la locul său, deschideți un editor de cod la alegere. Să vedem cum vă puteți porni producătorul și consumatorul folosind Java.
Creați producător Apache Kafka Java
Cu biblioteca-clienți kafka, acum sunteți gata să începeți să vă creați producătorul Kafka.
Să creăm o clasă numită SimpleProducer.java. Acesta va fi responsabil pentru producerea de mesaje pe tema pe care ați creat-o mai devreme. În cadrul acestei clase, veți crea o instanță pentru org.apache.kafka.clients.producer.KafkaProducer. Ulterior, veți folosi acest producător pentru a vă trimite mesajele.
Pentru a crea producătorul Kafka, aveți nevoie de gazda și portul serverului dvs. Apache Kafka. Deoarece îl rulați pe mașina dvs. locală, gazda va fi localhost. Având în vedere că nu ați modificat proprietățile implicite la pornirea serverului, portul va fi 9092. Luați în considerare următorul cod de mai jos, care vă va ajuta să vă creați producătorul:
package org.example.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SimpleProducer {
private final KafkaProducer<String, String> producer;
public SimpleProducer(String host, String port) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
this.producer = new KafkaProducer<>(properties);
}
}
Veți observa că sunt setate trei proprietăți. Să trecem rapid prin fiecare dintre ele:
- BOOTSTRAP_SERVERS_CONFIG vă permite să definiți unde rulează serverul Apache Kafka
- KEY_SERIALIZER_CLASS_CONFIG îi spune producătorului ce format să folosească pentru trimiterea cheilor de mesaje.
- Formatul pentru trimiterea mesajului real este definit folosind proprietatea VALUE_SERIALIZER_CLASS_CONFIG.
Deoarece veți trimite mesaje text, ambele proprietăți sunt setate să folosească StringSerializer.class.
Pentru a trimite efectiv un mesaj la subiectul dvs., trebuie să utilizați metoda producer.send() care preia un ProducerRecord. Următorul cod vă oferă o metodă care va trimite un mesaj la subiect și va imprima răspunsul împreună cu compensarea mesajului.
public void produce(String topic, String message) throws ExecutionException, InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
final Future<RecordMetadata> send = this.producer.send(record);
final RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}
Cu întregul cod la loc, acum puteți trimite mesaje la subiectul dvs. Puteți utiliza o metodă principală pentru a testa acest lucru, așa cum este prezentat în codul de mai jos:
package org.example.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SimpleProducer {
private final KafkaProducer<String, String> producer;
public SimpleProducer(String host, String port) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
this.producer = new KafkaProducer<>(properties);
}
public void produce(String topic, String message) throws ExecutionException, InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
final Future<RecordMetadata> send = this.producer.send(record);
final RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}
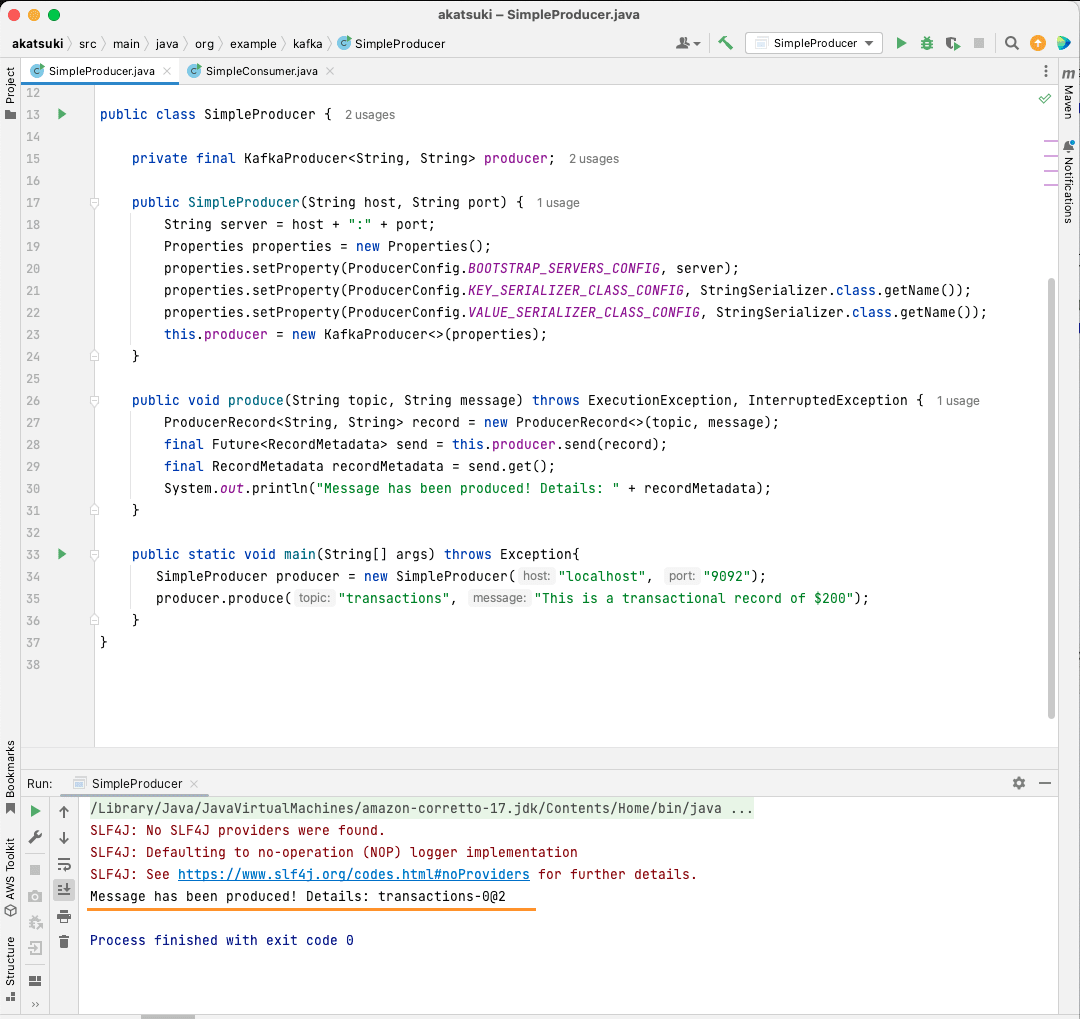
public static void main(String[] args) throws Exception{
SimpleProducer producer = new SimpleProducer("localhost", "9092");
producer.produce("transactions", "This is a transactional record of $200");
}
}
În acest cod, creați un SimpleProducer care se conectează la serverul dvs. Apache Kafka de pe mașina dvs. locală. Utilizează intern KafkaProducer pentru a produce mesaje text pe tema dvs.
Creați consumator Apache Kafka Java
Este timpul să faci un consumator Apache Kafka folosind clientul Java. Creați o clasă numită SimpleConsumer.java. În continuare, veți crea un constructor pentru această clasă, care inițializează org.apache.kafka.clients.consumer.KafkaConsumer. Pentru a crea consumatorul, aveți nevoie de gazda și portul pe care rulează serverul Apache Kafka. În plus, aveți nevoie de Grupul de consumatori, precum și de subiectul din care doriți să consumați. Utilizați fragmentul de cod de mai jos:
package org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class SimpleConsumer {
private static final String OFFSET_RESET = "earliest";
private final KafkaConsumer<String, String> consumer;
private boolean keepConsuming = true;
public SimpleConsumer(String host, String port, String consumerGroupId, String topic) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OFFSET_RESET);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(List.of(topic));
}
}
Similar cu Kafka Producer, Kafka Consumer preia și un obiect Properties. Să ne uităm la toate seturile de proprietăți diferite:
- BOOTSTRAP_SERVERS_CONFIG spune consumatorului unde rulează serverul Apache Kafka
- Grupul de consumatori este menționat folosind GROUP_ID_CONFIG
- Când consumatorul începe să consume, AUTO_OFFSET_RESET_CONFIG vă permite să menționați cât de departe doriți să începeți să consumați mesaje de la
- KEY_DESERIALIZER_CLASS_CONFIG spune consumatorului tipul cheii de mesaj
- VALUE_DESERIALIZER_CLASS_CONFIG indică tipul de consumator al mesajului real
Deoarece, în cazul dvs., veți consuma mesaje text, proprietățile deserializatorului sunt setate la StringDeserializer.class.
Acum vei consuma mesajele din subiectul tău. Pentru a menține lucrurile simple, odată ce mesajul este consumat, veți imprima mesajul pe consolă. Să vedem cum poți realiza acest lucru folosind codul de mai jos:
private boolean keepConsuming = true;
public void consume() {
while (keepConsuming) {
final ConsumerRecords<String, String> consumerRecords = this.consumer.poll(Duration.ofMillis(100L));
if (consumerRecords != null && !consumerRecords.isEmpty()) {
consumerRecords.iterator().forEachRemaining(consumerRecord -> {
System.out.println(consumerRecord.value());
});
}
}
}
Acest cod va continua să interogheze subiectul. Când primiți orice înregistrare de consumator, mesajul va fi tipărit. Testează-ți consumatorul în acțiune folosind o metodă principală. Veți porni o aplicație Java care va continua să consume subiectul și să imprime mesajele. Opriți aplicația Java pentru a termina consumatorul.
package org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class SimpleConsumer {
private static final String OFFSET_RESET = "earliest";
private final KafkaConsumer<String, String> consumer;
private boolean keepConsuming = true;
public SimpleConsumer(String host, String port, String consumerGroupId, String topic) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OFFSET_RESET);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(List.of(topic));
}
public void consume() {
while (keepConsuming) {
final ConsumerRecords<String, String> consumerRecords = this.consumer.poll(Duration.ofMillis(100L));
if (consumerRecords != null && !consumerRecords.isEmpty()) {
consumerRecords.iterator().forEachRemaining(consumerRecord -> {
System.out.println(consumerRecord.value());
});
}
}
}
public static void main(String[] args) {
SimpleConsumer simpleConsumer = new SimpleConsumer("localhost", "9092", "transactions-consumer", "transactions");
simpleConsumer.consume();
}
}
Când rulați codul, veți observa că nu numai că le consumă mesajul produs de producătorul dvs. Java, ci și pe cele pe care le-ați produs prin intermediul Producătorului de consolă. Acest lucru se datorează faptului că proprietatea AUTO_OFFSET_RESET_CONFIG a fost setată la cel mai devreme.
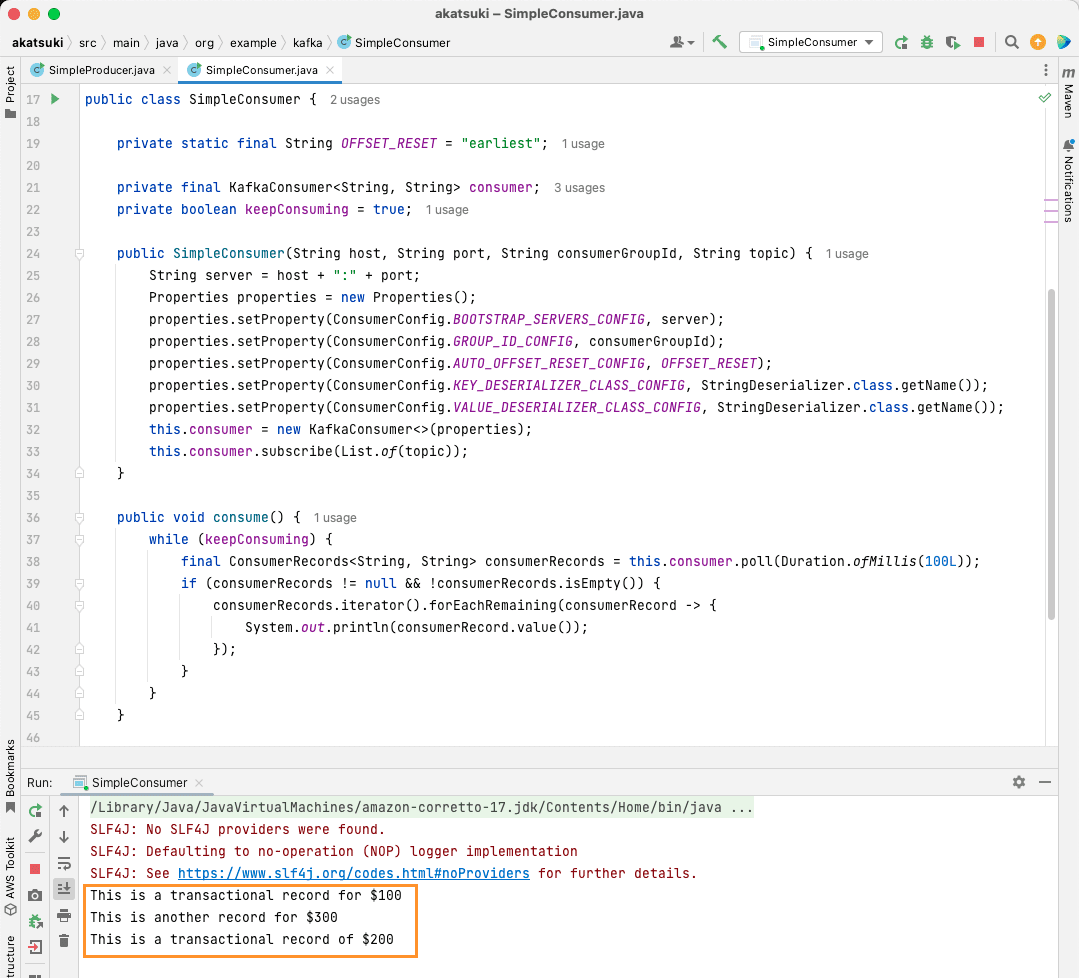
Cu SimpleConsumer rulând, puteți utiliza producătorul de consolă sau aplicația Java SimpleProducer pentru a produce mesaje suplimentare la acest subiect. Le vei vedea consumate și tipărite pe consolă.
Îndepliniți toate nevoile dvs. de pipeline de date cu Apache Kafka
Apache Kafka vă permite să vă gestionați cu ușurință toate cerințele conductei de date. Cu configurarea Apache Kafka pe mașina dvs. locală, puteți explora toate caracteristicile diferite pe care le oferă Kafka. În plus, clientul oficial Java vă permite să scrieți, să vă conectați și să comunicați eficient cu serverul dvs. Apache Kafka.
Fiind un sistem de streaming de date versatil, scalabil și foarte performant, Apache Kafka poate fi cu adevărat un schimbător de joc pentru tine. Îl puteți folosi pentru dezvoltarea locală sau chiar îl puteți integra în sistemele dumneavoastră de producție. La fel cum este ușor de configurat local, setarea Apache Kafka pentru aplicații mai mari nu este o sarcină mare.
Dacă sunteți în căutarea unor platforme de streaming de date, vă puteți uita la cele mai bune platforme de streaming de date pentru analiza și procesarea în timp real.