
Apache Parquet oferă mai multe beneficii pentru stocarea și recuperarea datelor în comparație cu metodele tradiționale precum CSV.
Formatul parchet este conceput pentru procesarea mai rapidă a datelor de tipuri complexe. În acest articol, vorbim despre modul în care formatul Parquet este potrivit pentru nevoile de date în continuă creștere de astăzi.
Înainte de a pătrunde în detaliile formatului Parquet, să înțelegem ce sunt datele CSV și provocările pe care le reprezintă pentru stocarea datelor.
Cuprins
Ce este stocarea CSV?
Cu toții am auzit multe despre CSV (Comma Separated Values) – una dintre cele mai comune moduri de organizare și formatare a datelor. Stocarea datelor CSV se bazează pe rânduri. Fișierele CSV sunt stocate cu extensia .csv. Putem stoca și deschide date CSV folosind Excel, Foi de calcul Google sau orice editor de text. Datele sunt ușor de vizualizat odată ce fișierul este deschis.
Ei bine, asta nu este bine – cu siguranță nu pentru un format de bază de date.
Mai mult, pe măsură ce volumul de date crește, devine dificil de interogat, gestionat și preluat.
Iată un exemplu de date stocate într-un fișier .CSV:
EmpId,First name,Last name, Division 2012011,Sam,Butcher,IT 2013031,Mike,Johnson,Human Resource 2010052,Bill,Matthew,Architect 2010079,Jose,Brian,IT 2012120,Adam,James,Solutions
Dacă îl vedem în Excel, putem vedea o structură rând-coloană ca mai jos:
Provocări legate de stocarea CSV
Stocările bazate pe rânduri, cum ar fi CSV, sunt potrivite pentru operațiunile de creare, actualizare și ștergere.
Cum rămâne cu Citirea în CRUD, atunci?
Imaginează-ți un milion de rânduri în fișierul .csv de mai sus. Ar dura un timp rezonabil pentru a deschide fișierul și a căuta datele pe care le căutați. Nu atât de tare. Majoritatea furnizorilor de servicii cloud precum AWS taxează companiile pe baza cantității de date scanate sau stocate – din nou, fișierele CSV consumă mult spațiu.
Stocarea CSV nu are o opțiune exclusivă de stocare a metadatelor, făcând scanarea datelor o sarcină plictisitoare.
Deci, care este soluția optimă și rentabilă pentru efectuarea tuturor operațiunilor CRUD? Haideti sa exploram.
Ce este stocarea datelor Parquet?
Parchet este un format de stocare open-source pentru stocarea datelor. Este utilizat pe scară largă în ecosistemele Hadoop și Spark. Fișierele parchet sunt stocate ca extensie .parquet.
Parchetul este un format foarte structurat. Poate fi folosit și pentru a optimiza datele brute complexe prezente în vrac în lacurile de date. Acest lucru poate reduce semnificativ timpul de interogare.
Parquet face ca stocarea datelor să fie eficientă și recuperarea mai rapidă datorită unui amestec de formate de stocare pe rând și coloane (hibrid). În acest format, datele sunt împărțite atât orizontal, cât și vertical. Formatul de parchet elimină, de asemenea, în mare măsură costul general de analizare.
Formatul restricționează numărul total de operațiuni I/O și, în cele din urmă, costul.
Parquet stochează, de asemenea, metadatele, care stochează informații despre date cum ar fi schema de date, numărul de valori, locația coloanelor, valoarea minimă, valoarea maximă a numărului de grupuri de rânduri, tipul de codificare etc. Metadatele sunt stocate la diferite niveluri în fișier. , făcând accesul la date mai rapid.
În accesul pe rând, cum ar fi CSV, regăsirea datelor necesită timp, deoarece interogarea trebuie să navigheze prin fiecare rând și să obțină anumite valori ale coloanei. Cu depozitarea cu parchet, toate coloanele necesare pot fi accesate simultan.
În concluzie,
- Parchetul se bazează pe structura coloanei pentru stocarea datelor
- Este un format de date optimizat pentru a stoca date complexe în vrac în sistemele de stocare
- Formatul parchet include diverse metode de comprimare și codificare a datelor
- Reduce semnificativ timpul de scanare a datelor și timpul de interogare și ocupă mai puțin spațiu pe disc în comparație cu alte formate de stocare precum CSV
- Minimizează numărul de operațiuni IO, scăzând costul de stocare și de execuție a interogărilor
- Include metadate care facilitează găsirea datelor
- Oferă suport open-source
Format de date parchet
Înainte de a intra într-un exemplu, să înțelegem mai detaliat cum sunt stocate datele în formatul Parquet:
Putem avea mai multe partiții orizontale cunoscute sub numele de grupuri de rânduri într-un singur fișier. În cadrul fiecărui grup de rânduri, se aplică partiția verticală. Coloanele sunt împărțite în mai multe coloane. Datele sunt stocate ca pagini în interiorul coloanelor. Fiecare pagină conține valorile și metadatele codificate ale datelor. După cum am menționat anterior, metadatele pentru întregul fișier sunt stocate și în subsolul fișierului la nivel de grup de rânduri.
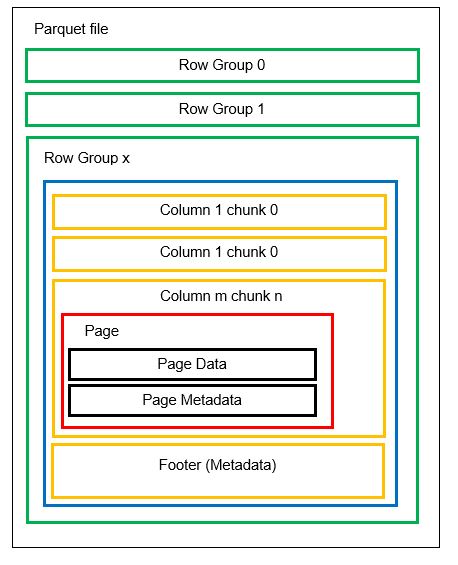
Deoarece datele sunt împărțite în coloane, adăugarea de noi date prin codificarea noilor valori într-o nouă bucată și fișier este, de asemenea, ușoară. Metadatele sunt apoi actualizate pentru fișierele și grupurile de rânduri afectate. Astfel, putem spune că Parchetul este un format flexibil.
Parquet acceptă în mod nativ comprimarea datelor utilizând tehnici de comprimare a paginilor și de codificare a dicționarului. Să vedem un exemplu simplu de compresie de dicționar:
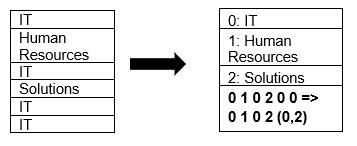
Rețineți că în exemplul de mai sus, vedem diviziunea IT de 4 ori. Deci, în timpul stocării în dicționar, formatul codifică datele cu o altă valoare ușor de stocat (0,1,2…) împreună cu numărul de ori se repetă continuu – IT, IT este schimbat la 0,2 pentru a salva mai mult spatiu. Interogarea datelor comprimate durează mai puțin.
Comparație cap la cap
Acum că avem o idee corectă despre cum arată formatele CSV și Parquet, este timpul ca unele statistici să compare ambele formate:
CSV
Parchet
Format de stocare pe rând.
Un hibrid de formate de stocare bazate pe rânduri și pe coloane.
Consumă mult spațiu, deoarece nu este disponibilă nicio opțiune de compresie implicită. De exemplu, un fișier de 1 TB va ocupa același spațiu atunci când este stocat pe Amazon S3 sau orice alt cloud.
Comprimă datele în timpul stocării, consumând astfel mai puțin spațiu. Un fișier de 1 TB stocat în format Parquet va ocupa doar 130 GB de spațiu.
Timpul de rulare a interogării este lent din cauza căutării bazate pe rând. Pentru fiecare coloană, fiecare rând de date trebuie să fie preluat.
Timpul de interogare este de aproximativ 34 de ori mai rapid din cauza stocării pe coloană și a prezenței metadatelor.
Mai multe date trebuie scanate pentru fiecare interogare.
Aproximativ 99% mai puține date sunt scanate pentru executarea interogării, optimizând astfel performanța.
Majoritatea dispozitivelor de stocare se încarcă în funcție de spațiul de stocare, așa că formatul CSV înseamnă costul ridicat de stocare.
Costuri de stocare mai mici, deoarece datele sunt stocate în format comprimat, codificat.
Schema de fișiere trebuie fie dedusă (care duce la erori) fie furnizată (obositoare).
Schema de fișiere este stocată în metadate.
Formatul este potrivit pentru tipurile de date simple.
Parchetul este potrivit chiar și pentru tipuri complexe, cum ar fi scheme imbricate, matrice, dicționare.
Concluzie 👩💻
Am văzut prin exemple că parchetul este mai eficient decât CSV în ceea ce privește costul, flexibilitatea și performanța. Este un mecanism eficient pentru stocarea și preluarea datelor, mai ales atunci când întreaga lume se îndreaptă către stocarea în cloud și optimizarea spațiului. Toate platformele majore precum Azure, AWS și BigQuery acceptă formatul Parquet.