În acest material, vom analiza procesul de vectorizare, o tehnică cheie în NLP (Procesarea Limbajului Natural), și vom clarifica importanța acesteia printr-un ghid detaliat care acoperă diversele modalități de vectorizare.
Am explorat anterior fundamentele preprocesării NLP și curățarea textelor. Am parcurs bazele NLP, diferitele sale utilizări și tehnici precum segmentarea în unități (tokenizare), normalizarea, standardizarea și curățarea datelor text.

Înainte de a discuta despre vectorizare, vom revedea conceptul de tokenizare și modul în care se diferențiază acesta de vectorizare.
Ce este tokenizarea?
Tokenizarea este procesul prin care împărțim frazele în componente mai mici, denumite token-uri. Aceste token-uri ajută computerele să înțeleagă și să manipuleze mai ușor textul.
Exemplu: „Acest articol este valoros.”
Token-uri: [‘Acest’, ‘articol’, ‘este’, ‘valoros’.]
Ce reprezintă vectorizarea?
După cum știm, algoritmii și modelele de învățare automată procesează date numerice. Vectorizarea transformă datele textuale sau categoriale în vectori numerici. Convertind datele în format numeric, modelul poate fi antrenat cu o precizie mai mare.
De ce avem nevoie de vectorizare?
❇️ Atât tokenizarea, cât și vectorizarea au roluri distincte în NLP. Tokenizarea descompune frazele în unități mici, în timp ce vectorizarea transformă aceste unități într-un format numeric, esențial pentru ca modelele computerizate să le poată interpreta.
❇️ Vectorizarea nu se rezumă doar la conversia într-un format numeric, ci și la capturarea înțelesului semantic al cuvintelor.
❇️ Vectorizarea poate reduce dimensiunea datelor, sporindu-le eficiența. Acest lucru este foarte util, mai ales atunci când lucrăm cu seturi mari de date.
❇️ Mulți algoritmi de învățare automată, cum ar fi rețelele neuronale, necesită date de intrare numerice, iar vectorizarea oferă această transformare esențială.
Există o varietate de tehnici de vectorizare pe care le vom analiza în acest articol.
Reprezentarea „Sac de Cuvinte” (Bag of Words)
Dacă aveți un număr mare de documente sau fraze pe care doriți să le analizați, reprezentarea „Sac de Cuvinte” simplifică acest proces, considerând fiecare document ca un „sac” plin cu cuvinte.
Metoda „sac de cuvinte” poate fi eficientă în categorizarea textelor, analiza sentimentelor și localizarea documentelor.
Să presupunem că lucrați cu un volum mare de text. „Sacul de cuvinte” vă ajută să reprezentați datele text, creând un vocabular de cuvinte unice din datele respective. După crearea vocabularului, fiecare cuvânt va fi codificat ca un vector bazat pe frecvența sa (de câte ori apare în text).
Acești vectori sunt compuși din numere nenegative (0, 1, 2 etc.) care indică frecvența de apariție a fiecărui cuvânt în document.
Procesul „sac de cuvinte” se desfășoară în trei etape:
Etapa 1: Tokenizarea
Aceasta constă în divizarea documentelor în unități mai mici, token-uri.
Exemplu – (Fraza: „Ador pizza și îmi plac burgerii”)
Etapa 2: Identificarea cuvintelor unice și crearea vocabularului
Se creează o listă cu toate cuvintele unice care apar în frazele dumneavoastră.
[„Eu”, „ador”, „pizza”, „și”, „burgeri”]
Etapa 3: Numărarea frecvenței cuvintelor și generarea vectorului
În această etapă, se numără de câte ori apare fiecare cuvânt din vocabular și se stochează rezultatul într-o matrice rară. Fiecare linie a matricei corespunde unui vector reprezentativ pentru o frază, iar lungimea acesteia (numărul de coloane) este egală cu dimensiunea vocabularului.
Importarea CountVectorizer
Vom importa CountVectorizer pentru a instrui modelul „sac de cuvinte”.
from sklearn.feature_extraction.text import CountVectorizer
Crearea unui vectorizator
În această etapă, vom construi modelul nostru folosind CountVectorizer și îl vom instrui cu un set de documente text de exemplu.
# Exemple de documente text
documents = [
"Acesta este primul document.",
"Acest document este al doilea document.",
"Și acesta este al treilea.",
"Este acesta primul document?",
]
# Crearea unui CountVectorizer
cv = CountVectorizer()
# Antrenarea și transformarea datelor X = cv.fit_transform(documents)
Convertirea într-o matrice densă
Aici, transformăm reprezentările noastre într-o matrice densă. De asemenea, vom obține numele caracteristicilor (cuvintele).
# Obținerea numelor caracteristicilor (cuvintele) feature_names = cv.get_feature_names_out() # Convertirea în matrice densă X_dense = X.toarray()
Afișarea matricei termen-document și a numelor de caracteristici
# Afișarea matricei termen-document și a numelor caracteristicilor
print("Matricea Termen-Document (MTD):")
print(X_dense)
print("\nNumele caracteristicilor:")
print(feature_names)
Matricea Termen-Document (MTD):
 Matrice
Matrice
Numele caracteristicilor:
 Cuvinte caracteristice
Cuvinte caracteristice
După cum se poate observa, vectorii sunt compuși din numere nenegative (0, 1, 2 etc.) care indică frecvența de apariție a cuvintelor în document.
Avem patru exemple de documente text din care am identificat nouă cuvinte unice. Aceste cuvinte unice au fost stocate în vocabularul nostru, atribuindu-le denumirea de „Nume caracteristici”.
Ulterior, modelul „sac de cuvinte” verifică dacă primul cuvânt unic este prezent în primul document. Dacă este prezent, atribuie valoarea 1, în caz contrar atribuie 0.
Dacă un cuvânt se repetă de mai multe ori (de exemplu, de două ori), atunci atribuie o valoare corespunzătoare (în cazul nostru, 2).
De exemplu, în cel de-al doilea document, cuvântul „document” apare de două ori, deci valoarea sa în matrice va fi 2.
În cazul în care dorim un singur cuvânt ca element de caracteristică în vocabular, atunci avem o reprezentare Unigram.
n-grame = Unigrame, Bigrame etc.
Există multiple biblioteci, cum ar fi scikit-learn, pentru a implementa metoda „sac de cuvinte”, precum și Keras, Gensim și altele. Această metodă este simplă și poate fi utilă în diferite situații.
Cu toate acestea, deși „sacul de cuvinte” este rapid, prezintă și câteva limitări:
- Oferă aceeași importanță fiecărui cuvânt, indiferent de semnificația sa. În multe cazuri, anumite cuvinte sunt mai relevante decât altele.
- „Sacul de cuvinte” contorizează pur și simplu frecvența de apariție a unui cuvânt într-un document. Acest lucru poate duce la o偏向 către cuvinte uzuale precum „un”, „și”, „este” etc., care s-ar putea să nu aibă o importanță semantică semnificativă.
- Documentele mai lungi pot conține mai multe cuvinte și pot genera vectori mai mari, ceea ce poate complica compararea. Acest lucru poate crea o matrice rară, care poate fi ineficientă pentru proiecte NLP complexe.
Pentru a aborda aceste probleme, putem utiliza tehnici mai avansate, cum ar fi TF-IDF. Să explorăm această tehnică mai în detaliu.
TF-IDF
TF-IDF, sau Frecvența Termenului – Frecvența Inversă a Documentului, este o metodă de reprezentare numerică care evaluează importanța cuvintelor într-un document.
De ce TF-IDF este preferabilă față de „sacul de cuvinte”?
Metoda „sacul de cuvinte” tratează toate cuvintele în mod egal și se concentrează doar pe frecvența cuvintelor unice în fraze. TF-IDF, pe de altă parte, evaluează importanța cuvintelor dintr-un document, luând în considerare atât frecvența, cât și unicitatea acestora.
Cuvintele care se repetă foarte des sunt echilibrate de cuvintele mai puțin frecvente, dar mai importante.
TF (Frecvența Termenului): măsoară importanța unui cuvânt într-o frază.
IDF (Frecvența Inversă a Documentului): măsoară importanța unui cuvânt într-o colecție de documente.
TF = Frecvența unui cuvânt într-un document / Numărul total de cuvinte din document
DF = Numărul de documente care conțin cuvântul / Numărul total de documente
IDF = log (Numărul total de documente / Numărul de documente care conțin cuvântul w)
IDF este inversul DF. Cu cât un cuvânt este mai răspândit în toate documentele, cu atât este mai mică importanța sa în documentul actual.
Scorul final TF-IDF: TF-IDF = TF * IDF
Această metodă determină ce cuvinte sunt frecvente într-un singur document și rare în toate documentele. Aceste cuvinte pot fi utile pentru identificarea subiectului principal al documentului.
Exemplu:
Doc1 = „Îmi place învățarea automată”
Doc2 = „Îmi place tipstrick.ro”
Să construim matricea TF-IDF pentru aceste documente.
Mai întâi, creăm un vocabular cu cuvinte unice.
Vocabular = [„Eu”, „place”, „învățarea”, „automată”, „tipstrick.ro”]
Deci, avem 5 cuvinte. Calculăm TF și IDF pentru acestea.
TF = Frecvența unui cuvânt într-un document / Numărul total de cuvinte din document
TF:
- Pentru „Eu”: TF pentru Doc1: 1/4 = 0,25 și pentru Doc2: 1/3 ≈ 0,33
- Pentru „place”: TF pentru Doc1: 1/4 = 0,25 și pentru Doc2: 1/3 ≈ 0,33
- Pentru „învățarea”: TF pentru Doc1: 1/4 = 0,25 și pentru Doc2: 0/3 ≈ 0
- Pentru „automată”: TF pentru Doc1: 1/4 = 0,25 și pentru Doc2: 0/3 ≈ 0
- Pentru „tipstrick.ro”: TF pentru Doc1: 0/4 = 0 și pentru Doc2: 1/3 ≈ 0,33
Acum, calculăm IDF.
IDF = log (Numărul total de documente / Numărul de documente care conțin cuvântul w)
IDF:
- Pentru „Eu”: IDF este log(2/2) = 0
- Pentru „place”: IDF este log(2/2) = 0
- Pentru „învățarea”: IDF este log(2/1) = log(2) ≈ 0,69
- Pentru „automată”: IDF este log(2/1) = log(2) ≈ 0,69
- Pentru „tipstrick.ro”: IDF este log(2/1) = log(2) ≈ 0,69
Acum, calculăm scorul final TF-IDF:
- Pentru „Eu”: TF-IDF pentru Doc1: 0,25 * 0 = 0 și TF-IDF pentru Doc2: 0,33 * 0 = 0
- Pentru „place”: TF-IDF pentru Doc1: 0,25 * 0 = 0 și TF-IDF pentru Doc2: 0,33 * 0 = 0
- Pentru „învățarea”: TF-IDF pentru Doc1: 0,25 * 0,69 ≈ 0,17 și TF-IDF pentru Doc2: 0 * 0,69 = 0
- Pentru „automată”: TF-IDF pentru Doc1: 0,25 * 0,69 ≈ 0,17 și TF-IDF pentru Doc2: 0 * 0,69 = 0
- Pentru „tipstrick.ro”: TF-IDF pentru Doc1: 0 * 0,69 = 0 și TF-IDF pentru Doc2: 0,33 * 0,69 ≈ 0,23
Matricea TF-IDF arată astfel:
Eu place învățarea automată tipstrick.ro Doc1 0.0 0.0 0.17 0.17 0.0 Doc2 0.0 0.0 0.0 0.0 0.23
Valorile dintr-o matrice TF-IDF indică importanța fiecărui termen în fiecare document. Valorile ridicate sugerează că un termen este semnificativ într-un anumit document, în timp ce valorile scăzute sugerează că termenul este mai puțin important sau comun în contextul dat.
TF-IDF este utilizat pe scară largă în clasificarea textului, crearea de informații pentru chatbot-uri și rezumarea textului.
Importarea TfidfVectorizer
Importăm TfidfVectorizer din sklearn.
from sklearn.feature_extraction.text import TfidfVectorizer
Crearea unui vectorizator
Construim modelul nostru TF-IDF utilizând TfidfVectorizer.
# Exemple de documente text
text = [
"Acesta este primul document.",
"Acest document este al doilea document.",
"Și acesta este al treilea.",
"Este acesta primul document?",
]
# Crearea unui TfidfVectorizer
cv = TfidfVectorizer()
Crearea matricei TF-IDF
Instruim modelul nostru cu textul dat. Apoi, transformăm matricea într-o matrice densă.
# Antrenarea și transformarea pentru a crea matricea TF-IDF X = cv.fit_transform(text)
# Obținerea numelor caracteristicilor (cuvintele) feature_names = cv.get_feature_names_out() # Convertirea matricei TF-IDF într-o matrice densă pentru manipulare mai facilă X_dense = X.toarray()
Afișarea matricei TF-IDF și a numelor caracteristicilor
# Afișarea matricei TF-IDF și a cuvintelor caracteristice
print("Matricea TF-IDF:")
print(X_dense)
print("\nNumele caracteristicilor:")
print(feature_names)
Matricea TF-IDF:
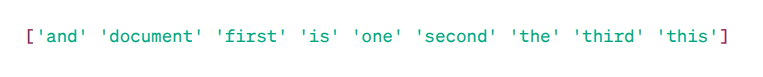 Cuvinte caracteristice
Cuvinte caracteristice
După cum se observă, aceste numere zecimale indică importanța cuvintelor în documente specifice.
De asemenea, putem combina cuvinte în grupuri de 2, 3, 4 etc. folosind n-grame.
Există și alți parametri pe care îi putem include: min_df, max_feature, subliner_tf etc.
Până acum, am explorat tehnici de bază bazate pe frecvență.
Cu toate acestea, TF-IDF nu este capabilă să ofere un sens semantic și o înțelegere contextuală a textului.
Să analizăm tehnici mai avansate, care au revoluționat reprezentarea cuvintelor și care sunt mai eficiente în capturarea sensului semantic și a contextului.
Word2Vec
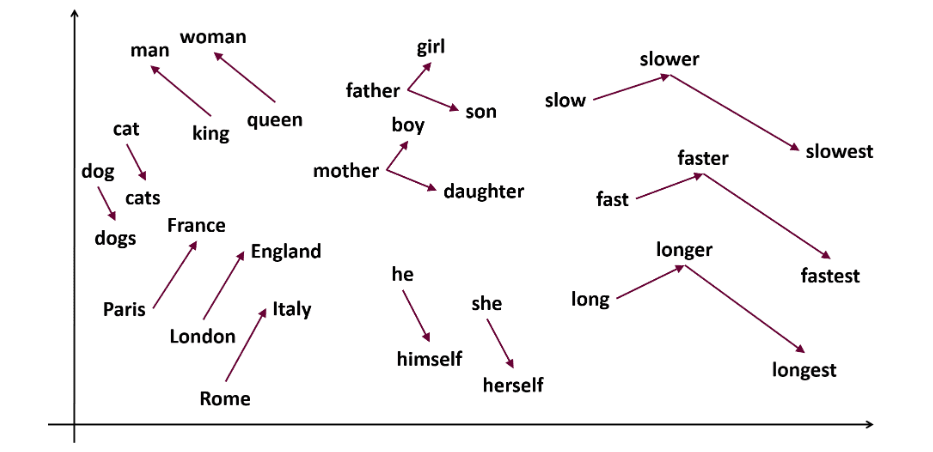
Word2vec este o tehnică populară de încorporare a cuvintelor (un tip de vector de cuvinte util pentru a evidenția similaritățile semantice și sintactice) în NLP. A fost dezvoltată de Tomas Mikolov și echipa sa la Google în 2013. Word2vec reprezintă cuvintele ca vectori continui într-un spațiu multidimensional.
Scopul Word2vec este de a reprezenta cuvintele într-un mod care să reflecte sensul lor semantic. Vectorii de cuvinte generați de word2vec sunt poziționați într-un spațiu vectorial continuu.
Exemplu: Vectorii pentru „Pisică” și „Câine” ar fi mai apropiați decât vectorii pentru „pisică” și „fată”.
 Sursă: usna.edu
Sursă: usna.edu
Word2vec utilizează două arhitecturi de model pentru a crea reprezentarea cuvintelor:
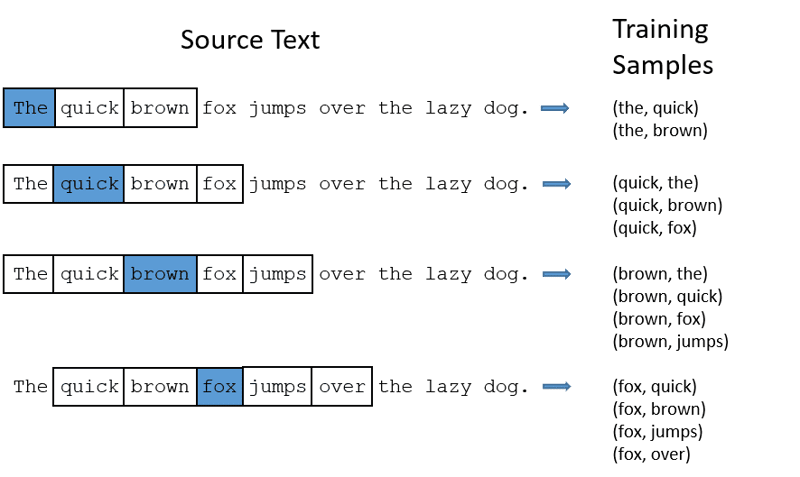
CBOW (Continuous Bag of Words): CBOW încearcă să prezică un cuvânt prin medierea sensului cuvintelor învecinate. Are nevoie de un număr fix sau o fereastră de cuvinte în jurul cuvântului țintă, pe care le convertește într-un format numeric (încorporare), apoi calculează media și o folosește pentru a prezice cuvântul țintă printr-o rețea neuronală.
Exemplu, ținta de predicție: „Vulpe”
Cuvintele frazei: „The”, „rapid”, „maro”, „sare”, „peste”, „the”
 Word2Vec
Word2Vec
- CBOW preia o fereastră de dimensiune fixă (un număr) de cuvinte, de exemplu, 2 (2 la stânga și 2 la dreapta).
- Le convertește în încorporări de cuvinte.
- CBOW calculează media încorporărilor de cuvinte.
- CBOW calculează media încorporărilor cuvintelor din context.
- Vectorul mediu încearcă să prezică cuvântul țintă folosind o rețea neuronală.
Acum, să înțelegem diferența dintre skip-gram și CBOW.
Skip-gram: Este un model de încorporare a cuvintelor care funcționează diferit. În loc să prezică cuvântul țintă, skip-gram prezice cuvintele din context, pornind de la cuvântul țintă.
Skip-gram este mai eficient în capturarea relațiilor semantice dintre cuvinte.
Exemplu: „Rege – bărbați + femei = regină”
Pentru a lucra cu Word2Vec, aveți două opțiuni: puteți antrena propriul model sau puteți folosi un model pre-antrenat. Vom analiza utilizarea unui model pre-antrenat.
Importarea Gensim
Puteți instala Gensim utilizând pip install:
pip install gensim
Tokenizarea frazelor utilizând word_tokenize:
Mai întâi, convertim frazele la litere mici. Apoi, tokenizăm frazele folosind word_tokenize.
# Importarea bibliotecilor necesare
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
# Exemple de fraze
sentences = [
"Îl ador pe thor",
"Hulk este un membru important al Răzbunătorilor",
"Ironman îl ajută pe Spiderman",
"Spiderman este unul dintre membrii populari ai Răzbunătorilor",
]
# Tokenizarea frazelor
tokenized_sentences = [word_tokenize(sentence.lower()) for sentence in sentences]
Instruirea modelului:
Vom instrui modelul folosind frazele tokenizate. Folosim o fereastră de dimensiune 5 pentru acest model de antrenament, dar aceasta poate fi ajustată în funcție de necesități.
# Instruirea modelului Word2Vec
model = Word2Vec(sentences=tokenized_sentences, vector_size=100, window=5, min_count=1, sg=0)
# Identificarea cuvintelor similare
similar_words = model.wv.most_similar("avengers")
# Afișarea cuvintelor similare
print("Cuvinte similare cu 'avengers':")
for word, score in similar_words:
print(f"{word}: {score}")
Cuvinte similare cu „avengers”:
 Similaritatea Word2Vec
Similaritatea Word2Vec
Acestea sunt câteva cuvinte similare cu „avengers” identificate de modelul Word2Vec, împreună cu scorurile lor de similaritate.
Modelul calculează un scor de similaritate (în general, similaritatea cosinusului) între vectorii de cuvinte pentru „avengers” și alte cuvinte din vocabularul său. Scorul de similaritate indică cât de strâns legate sunt două cuvinte în spațiul vectorial.
Exemplu:
În acest caz, cuvântul „ajută” are o similaritate cosinus de -0,005911458611011982 cu cuvântul „avengers”. Valoarea negativă sugerează că acestea sunt diferite unul de celălalt.
Valorile similarității cosinusului variază de la -1 la 1, unde:
- 1 indică faptul că doi vectori sunt identici și au similarități pozitive.
- Valorile apropiate de 1 indică o similaritate pozitivă ridicată.
- Valorile apropiate de 0 indică faptul că vectorii nu sunt puternic legați.
- Valorile apropiate de -1 indică o mare diferență.
- -1 indică faptul că cei doi vectori sunt total opuși și au o similaritate negativă perfectă.
Vizitați această legătură pentru o mai bună înțelegere a modelelor word2vec și pentru o reprezentare vizuală a modului în care funcționează. Este un instrument excelent pentru a vedea CBOW și skip-gram în acțiune.
Similar cu Word2Vec, avem GloVe. GloVe poate genera încorporări care necesită mai puțină memorie în comparație cu Word2Vec. Să explorăm mai mult despre GloVe.
GloVe
Vectorii Globali pentru Reprezentarea Cuvintelor (GloVe) sunt o tehnică similară cu word2vec. Este utilizată pentru a reprezenta cuvintele ca vectori într-un spațiu continuu. Conceptul din spatele GloVe este similar cu cel al Word2Vec: generează încorporări contextuale de cuvinte, având în vedere performanța superioară a Word2Vec.
De ce este necesar GloVe?
Word2vec este o metodă bazată pe ferestre și folosește cuvinte din apropiere pentru a înțelege cuvintele. Aceasta înseamnă că sensul semantic al unui cuvânt țintă este afectat doar de cuvintele din apropiere, ceea ce duce la o utilizare ineficientă a statisticilor.
În schimb, GloVe surprinde atât statisticile globale, cât și cele locale, pentru a genera încorporări de cuvinte.
Când ar trebui să utilizăm GloVe?
Utilizați GloVe când doriți încorporări de cuvinte care să reflecte relații semantice mai extinse și asocieri globale de cuvinte.
GloVe este superior altor modele în sarcinile de recunoaștere a entităților numite, analogia cuvintelor și similaritatea cuvintelor.
Mai întâi, trebuie să instalăm Gensim:
pip install gensim
Etapa 1: Instalarea bibliotecilor esențiale
# Importarea bibliotecilor necesare import numpy as np import matplotlib.pyplot as plt from sklearn.manifold import TSNE import gensim.downloader as api
Etapa 2: Importarea modelului GloVe
import gensim.downloader as api
glove_model = api.load('glove-wiki-gigaword-300')
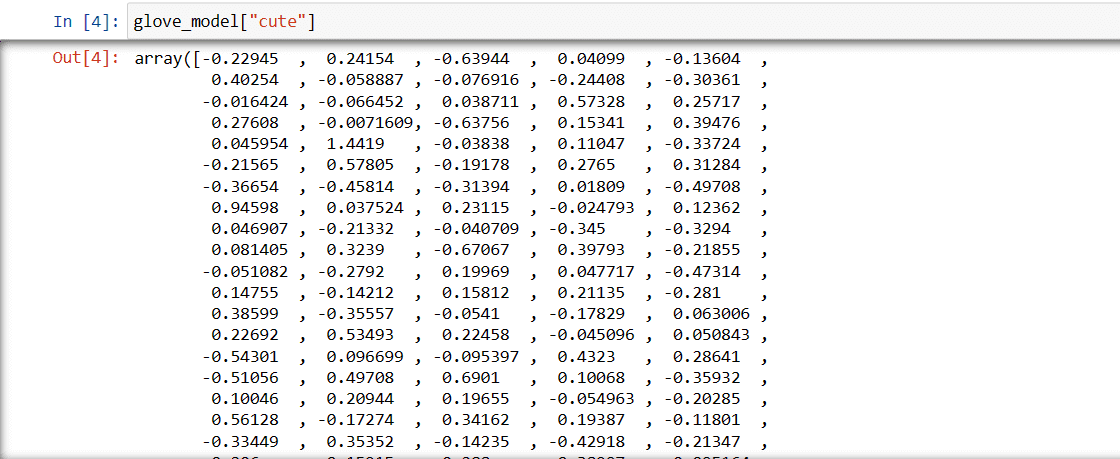
Etapa 3: Obținerea reprezentării vectoriale a cuvântului „drăguț”
glove_model["cute"]
 Vector pentru cuvântul „drăguț”
Vector pentru cuvântul „drăguț”
Aceste valori reflectă semnificația cuvântului și relațiile sale cu alte cuvinte. Valorile pozitive indică asocieri pozitive cu anumite concepte, în timp ce valorile negative indică asocieri negative cu altele.
Într-un model GloVe, fiecare dimensiune a vectorului de cuvânt reprezintă un anumit aspect al sensului sau contextului cuvântului.
Valorile negative și pozitive din aceste dimensiuni contribuie la gradul în care „drăguț” este asociat semantic cu alte cuvinte din vocabularul modelului.
Valorile pot varia în funcție de model. Să identificăm câteva cuvinte similare cu cuvântul „băiat”.
Primele 10 cuvinte similare pe care modelul le consideră cele mai apropiate de cuvântul „băiat”.
# Identificarea cuvintelor similare
glove_model.most_similar("boy")
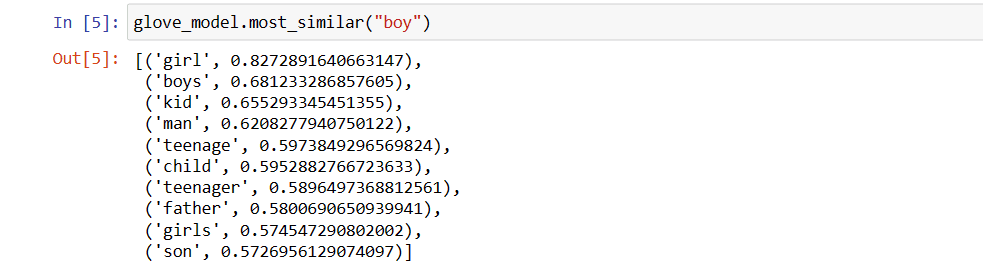 Primele 10 cuvin
Primele 10 cuvin