Un plan de revenire după un eveniment catastrofal reprezintă o necesitate fundamentală pentru orice organizație, fiind esențial să fie implementat înainte ca o situație neprevăzută să se abată asupra ei.
În sectorul IT, acest demers începe prin elaborarea unui document oficial care să cuprindă strategiile, acțiunile și protocoalele necesare pentru a gestiona un dezastru și consecințele sale.
Un dezastru, prin definiție, este un eveniment neașteptat, care se produce fără avertisment și poate lua diverse forme. Atunci când un astfel de eveniment are loc, indivizii și organizațiile se confruntă cu dificultăți multiple, incluzând probleme financiare și o experiență negativă a utilizatorilor.
În cazul unui atac, este crucial să existe un plan pentru a minimiza impactul acestuia și a restabili operațiunile cât mai rapid posibil. Un plan de recuperare solid în caz de dezastru ajută la prevenirea sau limitarea daunelor. Totodată, permite reducerea efectelor secundare negative asupra experienței utilizatorilor, a costurilor și a timpului de nefuncționare.
Mai mult, este vital să existe planuri, personal, strategii, echipamente și sisteme pregătite pentru a repune totul în funcțiune. Pentru aceasta, este necesară o înțelegere profundă a conceptului de recuperare în caz de dezastru.
În acest articol, vom analiza în detaliu acest subiect, împreună cu terminologia cheie asociată recuperării în caz de dezastru, astfel încât să puteți reacționa eficient și să ieșiți mai puternici din situații adverse.
Să începem!
Ce reprezintă un dezastru?
Un dezastru este un eveniment imprevizibil care poate surveni oriunde, inclusiv în domeniul IT. Acesta poate avea cauze naturale sau umane și poate perturba activitatea unei companii, afectând infrastructura.
Consecința este că organizația, împreună cu clienții, furnizorii, angajații și partenerii săi, este afectată. Acest lucru exercită presiuni asupra organizației în termeni financiari, de reputație în industrie, de încredere a clienților și de securitate.
Prin urmare, este esențială o pregătire prealabilă pentru a depăși astfel de situații. Aceasta implică recuperarea imediată a tuturor operațiunilor și datelor. Cu alte cuvinte, organizația trebuie să fie pregătită să restabilească totul în cel mai scurt timp posibil pentru clienții săi.
Dezastrele pot fi diverse, incluzând atacuri cibernetice, sabotaje, acte teroriste, ransomware sau amenințări fizice, uragane, cutremure, incendii, inundații, accidente industriale, întreruperi de curent și multe altele.
Ce înseamnă recuperarea în caz de dezastru?
Recuperarea în caz de dezastru reprezintă procesul prin care se restabilesc operațiunile normale după un eveniment catastrofal. Aceasta implică restabilirea accesului la hardware, software, echipamente, conectivitate, rețea, energie și date. Este necesară definirea unor reguli și proceduri într-un proces documentat pentru a pregăti organizația înaintea unui dezastru.
În cazul în care sediul organizației este afectat, este necesară extinderea activităților, abordând aspecte precum comunicarea, transportul, aprovizionarea, locațiile de lucru și altele.
De ce este important un plan de recuperare în caz de dezastru?
Elaborarea unui plan eficient de recuperare în caz de dezastru, indiferent dacă acesta are cauze naturale sau umane, este crucială pentru orice entitate din sectorul IT. Trebuie să existe personalul și instrumentele potrivite, la locul potrivit, pentru a implementa planul fără dificultăți.
Să analizăm mai detaliat de ce este vitală recuperarea în caz de dezastru.
Limitarea daunelor
Un dezastru este imprevizibil. Nimeni nu știe când va surveni. Însă, prin pregătirea anticipată, se pot controla daunele aduse infrastructurii.
De exemplu, în zonele predispuse la inundații, documentele esențiale și echipamentele pot fi stocate la etajele superioare pentru a preveni deteriorarea lor.
Similar, este important să se efectueze copii de rezervă ale datelor esențiale înainte ca atacurile cibernetice să le poată compromite sau fura.
Restabilirea serviciilor
Un plan solid de recuperare în caz de dezastru permite restabilirea rapidă și eficientă a tuturor serviciilor la starea lor normală. Aceasta înseamnă că, într-un interval scurt de timp, se pot recupera majoritatea activelor și serviciilor esențiale.
Minimizarea întreruperilor
Nu se poate anticipa ce se va întâmpla în viitorul apropiat. Însă, cu un plan de recuperare adecvat, nu este necesară o îngrijorare excesivă în legătură cu consecințele. Infrastructura poate continua să funcționeze cu întreruperi minime.
Instruire și pregătire

O infrastructură IT include numeroși angajați care lucrează împreună. Toți aceștia trebuie să fie familiarizați cu planul de recuperare, astfel încât să poată acționa prompt și eficient în situații de urgență.
O pregătire adecvată va reduce, de asemenea, nivelul de stres pentru toți cei asociați cu organizația. În plus, angajații pot fi instruiți pentru a lua măsurile necesare în cazul unui eveniment neprevăzut.
Terminologia recuperării în caz de dezastru
Să începem cu terminologia pentru a înțelege recuperarea în caz de dezastru dintr-o perspectivă mai detaliată.
RTO
Obiectivul de timp de recuperare (RTO) reprezintă intervalul de timp pe care o organizație, ținând cont de specificul activității sale, îl consideră acceptabil pentru a tolera un dezastru, fără a afecta creșterea financiară.
La stabilirea RTO, o companie trebuie să evalueze timpul de nefuncționare care ar putea afecta negativ organizația. Acesta servește drept bază pentru dezvoltarea unor strategii viabile, care să permită continuarea activității, chiar și după un dezastru. Când clienții întâmpină dificultăți în utilizarea unei aplicații, ei vor dori să știe cât timp va dura până când aceasta va redeveni funcțională. Răspunsul la această întrebare este RTO pentru fiecare organizație.
Exemplu: Să presupunem că sunteți o companie de tranzacții online, precum PayPal sau Pioneer, care se confruntă cu evenimente neprevăzute. În acest caz, RTO-ul trebuie să fie cât mai rapid pentru a restabili operațiunile.
Cu alte cuvinte, o companie poate stabili un RTO de o oră sau două pentru a evita pierderile financiare sau de date.
RPO
Obiectivul punctului de recuperare (RPO) reprezintă cantitatea de date pe care o infrastructură IT o poate pierde, exprimată în timp și cantitate de informații.
Sună complicat?
Să luăm exemplul unei baze de date care înregistrează tranzacțiile unei bănci, inclusiv transferurile, programările, plățile etc. În cazul unui dezastru, baza de date este recuperată în timp real. Diferența dintre starea bazei de date în momentul dezastrului și cea recuperată după dezastru este zero în acest caz.
Pentru anumite companii, poate fi acceptabil să dureze 24 de ore pentru a recupera toate informațiile dintr-o copie de rezervă, însă, în alte situații, aceasta ar putea fi o catastrofă. Este esențial ca infrastructura să fie configurată în conformitate cu cerințele RPO. Aceasta presupune creșterea frecvenței copiilor de rezervă, adăugarea unei baze de date de rezervă și multe altele.
Failover
Să ne imaginăm o călătorie lungă. Dintr-o dată, o pană de cauciuc apare în mod neașteptat. În acest caz, vă bazați pe roata de rezervă și pe instrumentele necesare pentru a schimba roata defectă.
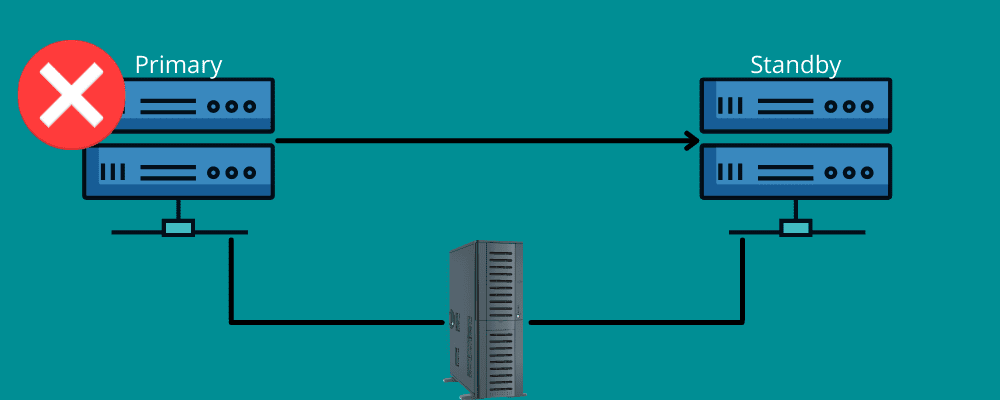
Failover-ul funcționează în mod similar.
Acesta presupune existența unei conexiuni de rezervă în cazul unui dezastru. Pe scurt, failover-ul înseamnă existența unor rețele și sisteme care pot fi utilizate în timpul unui dezastru pentru a transfera informațiile în sistemul de recuperare.
Failover-ul asigură funcționarea neîntreruptă a serviciilor, chiar și în cazul unei defecțiuni la nivelul infrastructurii sau hardware. Astfel, organizația evită pierderea de date și venituri și oferă utilizatorilor un serviciu neîntrerupt.
Failover-ul poate fi setat manual sau poate funcționa automat, transferând datele pe serverul de rezervă.
Failback
Failback-ul IT reprezintă procesul prin care producția inițială este restabilită la locația (sistemul) originală, după ce un dezastru a fost gestionat. În timpul unui atac, companiile utilizează operațiunea de failover, transferând sarcinile de lucru într-o replică VM sau un sistem de rezervă.
Însă, următorul pas, failback-ul, nu poate fi omis. După ce totul este recuperat și readus la funcționare, sarcinile de lucru trebuie transferate înapoi pe mașinile virtuale sau sistemele originale. Acest proces de returnare a sarcinilor de lucru la locul de muncă sau sistemul inițial este cunoscut sub numele de failback. Cu alte cuvinte, se revine „înapoi” după atac.
Failback-ul este utilizat și în cadrul operațiunilor de întreținere programată. În general, failback-ul are loc după failover. Failover-ul este primul pas, iar failback-ul, al doilea, în recuperarea datelor esențiale. Acesta poate fi configurat de la cloud la cloud, de la local la local, de la local la cloud sau orice altă combinație.
DR
Recuperarea în caz de dezastru (DR) reprezintă procesul prin care se implementează planuri prestabilite pentru recuperarea activelor într-un interval de timp definit.
DR oferă unei organizații capacitatea de a reacționa rapid și de a recupera toate serviciile după un eveniment neașteptat. Totodată, oferă documentația oficială, cu instrucțiuni pentru acțiuni imediate în cazul unor incidente neprevăzute.
BCP
Planul de continuitate a afacerii (BCP) este un plan de recuperare în caz de dezastru, utilizat pentru a gestiona întreruperile IT la nivelul serverelor, dispozitivelor mobile, calculatoarelor personale și rețelelor.
BCP este ușor diferit de recuperarea în caz de dezastru, deoarece ajută organizația să dezvolte strategii pentru restabilirea software-ului și a productivității, în vederea satisfacerii necesităților fundamentale ale afacerii.
În acest context, o companie creează un sistem de recuperare pentru a depăși potențialele amenințări, precum atacurile cibernetice sau dezastrele naturale. Acesta este conceput pentru a proteja activele și pentru a se asigura că serviciile vor redeveni funcționale rapid, după un incident.
BCM

Managementul continuității afacerii (BCM) este un proces de gestionare a riscurilor, conceput pentru a proteja procesele de afaceri împotriva amenințărilor. BCM este pasul următor după BCP, validând planurile de recuperare pentru a se asigura că toți membrii organizației răspund imediat și recuperează elementele esențiale.
BCM oferă un cadru de gestionare pentru identificarea riscurilor la nivelul infrastructurii, în fața amenințărilor externe sau interne. Totodată, se asigură că acest cadru funcționează eficient, prin teste periodice, pentru a îmbunătăți previzibilitatea, a reduce riscurile și a adapta planul la atacurile viitoare.
BIA
Analiza impactului asupra afacerii (BIA) reprezintă procesul de evaluare a capacității de supraviețuire a unei afaceri, prin identificarea sistemelor, operațiunilor și proceselor esențiale. Aceasta evidențiază efectele unui dezastru asupra organizației, cauzate de întreruperea operațiunilor.
BIA anticipează consecințele înainte de a se produce un atac, pentru a colecta informații valoroase, care pot contribui la crearea unor strategii de recuperare eficiente. Aceasta identifică, de asemenea, costurile implicate în cazul unor defecțiuni, precum costul de înlocuire a echipamentelor, pierderile de numerar, profituri, salarii etc.
La elaborarea unui raport BIA, trebuie luate în considerare procesele critice ale afacerii, impactul întreruperilor asupra diferitelor domenii, durata acceptabilă a întreruperilor, zonele tolerabile, costurile financiare și alte aspecte relevante.
Arborele de apeluri
Un arbore de apeluri este un proces de creare a unei liste cu personalul care trebuie contactat în caz de urgență. Această procedură urmează o structură arborescentă.
De exemplu, în timpul unui dezastru, o persoană contactează un grup mic de membri, transmițând un mesaj urgent, iar acei membri contactează alte grupuri, separat. Astfel, tot personalul este informat în timpul amenințării și începe activitățile alocate, pentru a restabili funcțiile și procesele în timp util. Crearea unei astfel de liste este simplă, însă implementarea acesteia în timp real poate genera confuzie.
Este necesară efectuarea regulată de activități de apelare, pentru a menține fiecare membru al personalului pregătit. Testele periodice pot contribui la identificarea numerelor modificate sau lipsă, care ar putea afecta performanța.
Un arbore de apeluri conține informațiile necesare în caz de urgență, oferind instrucțiuni. Deși poate fi creat manual, în prezent se utilizează automatizarea pentru a accelera procesul și pentru a notifica membrii în mediul digital actual.
Centrul de comandă/Centrul de control
Aceasta este o facilitate virtuală sau fizică, creată special pentru a oferi coordonare și control în cadrul planurilor de recuperare în timpul unei crize. Centrul comunică cu echipa pentru a gestiona sistemele și funcțiile în timpul unui dezastru.
În mod tradițional, infrastructura depindea de centrul de comandă care gestiona crizele fără o abordare adecvată. În prezent, organizațiile au proiectat centre de control eficiente, transformând reacția imediată într-o competență esențială.
Imediat ce un dezastru este sesizat, centrul de comandă trece rapid la etapa de recuperare. Totodată, acesta servește drept punct de raportare în ceea ce privește serviciile, presa, livrările etc. Acesta reunește specialiști din diverse domenii în astfel de situații.
Răspunsul la incident

Răspunsul la incident reprezintă un tip de reacție la un atac. Acesta este realizat prin proceduri și personal calificat, care să asigure securitatea rețelei și a datelor, în mod eficient și la momentul potrivit.
O organizație care are un plan de răspuns la incident, înainte de un eveniment neașteptat, își poate proteja datele de amenințările în timp real. Specialiștii în răspunsul la incidente sunt permanent vigilenți și acționează eficient în timpul unui incident. Aceștia iau măsurile necesare pentru a evita încălcările de securitate, asigurându-se că niciun pas nu este omis în timpul recuperării în caz de dezastru.
Inițial, este necesară identificarea datelor critice și stocarea acestora în cloud sau în orice altă locație la distanță, pentru a garanta securitatea. Abordarea necesităților actuale la nivelul infrastructurii, precum și amenințările cibernetice în evoluție, implică actualizarea periodică a planurilor de răspuns la incidente.
Backup
Soluțiile de backup ajută infrastructura IT să mențină copii ale datelor și să le stocheze în siguranță, pentru a le accesa la momentul potrivit. În cazul unei corupții a bazei de date, a ștergerii accidentale a datelor sau a oricărei alte probleme, este necesară existența unor copii de rezervă pentru a restaura datele rapid și a continua oferirea serviciilor.

Acest proces presupune replicarea fișierelor și stocarea lor într-o locație sigură, pentru a accesa ușor datele după un eveniment neobișnuit. Este indicat să se efectueze copii de rezervă în mai multe locații, pentru a asigura restaurarea datelor, chiar dacă un site eșuează.
Reziliența
Capacitatea comunităților, statelor, organizațiilor și indivizilor de a rezista la un dezastru, fără a compromite serviciile și sistemele, este denumită reziliență la dezastre.
O organizație trebuie să fie pregătită să suporte o cantitate mare de stres, cauzat de pericole. Trebuie să existe capacitatea de a minimiza pierderile, printr-o planificare eficientă, în loc să se aștepte ca altcineva să intervină pentru a ajuta. Această abordare ajută la gestionarea dezastrelor și la restabilirea eficientă a infrastructurii IT.
Obiectivul principal este conservarea și restaurarea funcțiilor și structurilor esențiale, în mod eficient și la momentul potrivit. Pentru a deveni o organizație rezistentă la dezastre, este necesară pregătirea anticipată, capacitatea de a anticipa riscurile, de a se adapta la schimbări, de a învăța, de a integra diverse sectoare și de a gestiona nivelul de risc.
SLA

Acordul privind nivelul de servicii (SLA) este un plan în care se specifică, pentru utilizatorii finali, timpul necesar pentru restabilirea serviciilor, în timpul unei urgențe.
SLA garantează clienților că datele lor sunt în siguranță și nu sunt compromise sau partajate cu terțe părți. Acesta este singurul punct de contact pentru problemele utilizatorilor finali.
Fiecare infrastructură IT oferă clienților asigurări cu privire la SLA. Prin urmare, este necesară comunicarea prealabilă cu utilizatorii.
SPOF
Un Singur Punct de Eșec (SPOF) este un echipament, o persoană, o resursă sau o aplicație, de care sunt conectate multe alte sisteme sau aplicații.
În cazul unei defecțiuni a unui astfel de echipament sau resurse, toate componentele esențiale conectate la acesta vor fi afectate. Astfel, întregul proces și operațiunile afacerii vor fi perturbate.
Prin urmare, este necesară o strategie pentru gestionarea acestor situații și pentru menținerea activității organizației. Primul pas este identificarea acelor echipamente sau sisteme care au un impact major. Apoi, se efectuează o analiză a impactului asupra afacerii și se obține un scor de evaluare a riscurilor. Trebuie identificate și remediate toate aceste elemente înainte de apariția evenimentului.
După ce se întocmește o listă cu toate SPOF-urile, acestea se clasifică în funcție de procesul de recuperare. Fiecare SPOF se plasează în una dintre cele trei categorii:
- Elemente ușor de recuperat, rapid și cu costuri reduse.
- Elemente a căror recuperare este dificilă, dar se poate dezvolta un proces fiabil pentru restaurare.
- Elemente pentru care nu se poate face nimic, odată ce au căzut.
Se pot lua măsuri în funcție de categoria în care se află elementele.
Recuperarea sistemului
În cazul unei defecțiuni hardware, este necesară rularea unui proces de recuperare pentru a readuce un sistem sau un server la starea inițială. Pentru recuperarea sistemului, trebuie să existe cerințe de recuperare, copii de rezervă, compatibilitate cu firmware-ul și compatibilitate hardware.
Recuperarea sistemului este un proces prin care un sistem este readus la setările anterioare sau la starea inițială. Acest proces elimină toate infecțiile cu viruși cauzate de software sau aplicații instalate.
Acest proces include planificarea recuperării infrastructurii IT, care definește și urmează anumite proceduri, pentru a asigura disponibilitatea datelor, în fața perturbărilor provocate de factori umani sau naturali.
Restaurarea sistemului
Restaurarea sistemului este un instrument de recuperare care permite recuperarea anumitor fișiere și informații, la starea lor anterioară.
Cu ajutorul restaurării sistemului, pot fi recuperate chei de registru, programe instalate, drivere, fișiere de sistem etc., la versiunile lor anterioare. Acesta este un element important în cazul unui dezastru.
Planul de testare
Acesta reprezintă un document care include informații despre strategia de testare, estimări, resurse, termene, obiective și calendare. Acesta funcționează ca un model care rulează teste, pentru a asigura siguranța hardware-ului și a software-ului.
Planul include diverse teste, conform procedurilor și pașilor planificați pentru gestionarea efectelor unui dezastru. Testele periodice pregătesc personalul și organizația pentru a acționa eficient în timpul unui eveniment neașteptat. Astfel, infrastructura IT poate identifica deficiențele și se poate pregăti în mod corespunzător.
Concluzie
Nimeni nu știe când va avea loc un dezastru. Prin urmare, măsurile adecvate de siguranță și securitate sunt esențiale pentru orice afacere.
Terminologia specifică recuperării în caz de dezastru ajută la înțelegerea modului în care trebuie abordate atacurile și dezastrele. Aceasta permite o pregătire anticipată, astfel încât infrastructura să poată fi protejată în timpul unui eveniment neașteptat. În acest fel, se poate crea o strategie de recuperare în timp real, care poate economisi sume mari de bani și poate menține încrederea clienților.