Introducere
În contextul actual al digitalizării rapide, fiecare inovație tehnologică promite să revoluționeze modul în care interacționăm, muncim și ne organizăm activitățile cotidiene. În acest peisaj, modelele lingvistice au cunoscut o evoluție fulminantă, devenind o componentă vitală a inteligenței artificiale. În mod special, modelele lingvistice de dimensiuni reduse (SLM) atrag tot mai multă atenție, captând interesul unor giganți tehnologici precum OpenAI, Google, Microsoft și Meta. Aceste companii investesc considerabil în dezvoltarea SLM-urilor, considerându-le viitorul inteligenței artificiale. Pe măsură ce tot mai multe organizații adoptă SLM-urile pentru o diversitate de aplicații, devine esențial să ne familiarizăm cu aceste modele, să înțelegem avantajele și dezavantajele lor în raport cu modelele lingvistice mari (LLM).
Aspecte Principale
- Companii majore ca OpenAI, Google, Microsoft și Meta investesc în SLM-uri.
- SLM-urile câștigă popularitate în industrie, fiind considerate viitorul inteligenței artificiale.
- Printre exemple de SLM-uri se numără Google Nano, Phi-3 de la Microsoft și mini GPT-4o de la OpenAI.
Modelele lingvistice mari (LLM) au apărut odată cu lansarea ChatGPT de către OpenAI. De atunci, mai multe companii au introdus propriile LLM-uri, însă acum multe organizații se orientează către modelele lingvistice mici (SLM). Acestea câștigă teren, dar ce sunt ele și prin ce se deosebesc de LLM-uri?
Ce reprezintă un model lingvistic mic?
Un model lingvistic mic (SLM) este un tip de model AI care utilizează un număr redus de parametri (aceștia fiind valori pe care modelul le învață în timpul antrenamentului). Similar cu modelele mai mari, SLM-urile pot genera text și realiza diverse sarcini. Însă, SLM-urile se bazează pe seturi de date mai restrânse pentru antrenament, au un număr mai mic de parametri și necesită o putere de calcul mai mică pentru antrenare și utilizare.
SLM-urile se concentrează pe funcții esențiale, iar dimensiunile lor reduse le fac potrivite pentru implementare pe o varietate de dispozitive, inclusiv cele cu performanțe hardware mai modeste, cum ar fi dispozitivele mobile. De exemplu, Nano de la Google este un SLM dezvoltat special pentru a funcționa pe telefoane mobile. Datorită dimensiunii sale, Nano poate opera local, cu sau fără conexiune la internet, conform companiei.
Pe lângă Nano, există numeroase alte SLM-uri dezvoltate de companii de top și startup-uri din domeniul inteligenței artificiale. Printre cele mai populare SLM-uri se numără Phi-3 de la Microsoft, mini GPT-4o de la OpenAI, Claude 3 Haiku de la Anthropic, Llama 3 de la Meta și Mixtral 8x7B de la Mistral AI.
Există și alte opțiuni care ar putea fi considerate LLM-uri, dar care, în realitate, sunt SLM-uri. Acest lucru este valabil mai ales având în vedere că majoritatea companiilor adoptă o abordare multi-model, lansând mai multe modele lingvistice în portofoliul lor, oferind atât LLM-uri cât și SLM-uri. Un exemplu este GPT-4, care oferă mai multe modele, inclusiv GPT-4, GPT-4o (Omni) și mini GPT-4o.
Comparație între modelele lingvistice mici și cele mari
Când discutăm despre SLM-uri, nu putem ignora omologii lor mari: LLM-urile. Diferența principală dintre un SLM și un LLM este dimensiunea modelului, măsurată prin numărul de parametri.
Până la momentul redactării acestui articol, nu există un consens în industria inteligenței artificiale cu privire la numărul maxim de parametri pe care un model nu ar trebui să-l depășească pentru a fi considerat un SLM, sau numărul minim necesar pentru a fi considerat un LLM. Cu toate acestea, SLM-urile au, în mod tipic, între milioane și câteva miliarde de parametri, în timp ce LLM-urile au mai mulți, ajungând chiar și la trilioane.
De exemplu, GPT-3, lansat în 2020, are 175 de miliarde de parametri (iar modelul GPT-4 se speculează că ar avea aproximativ 1,76 trilioane), în timp ce SLM-urile Phi-3-mini, Phi-3-small și Phi-3-medium de la Microsoft din 2024 au 3,8 miliarde, 7 miliarde, respectiv 14 miliarde de parametri.
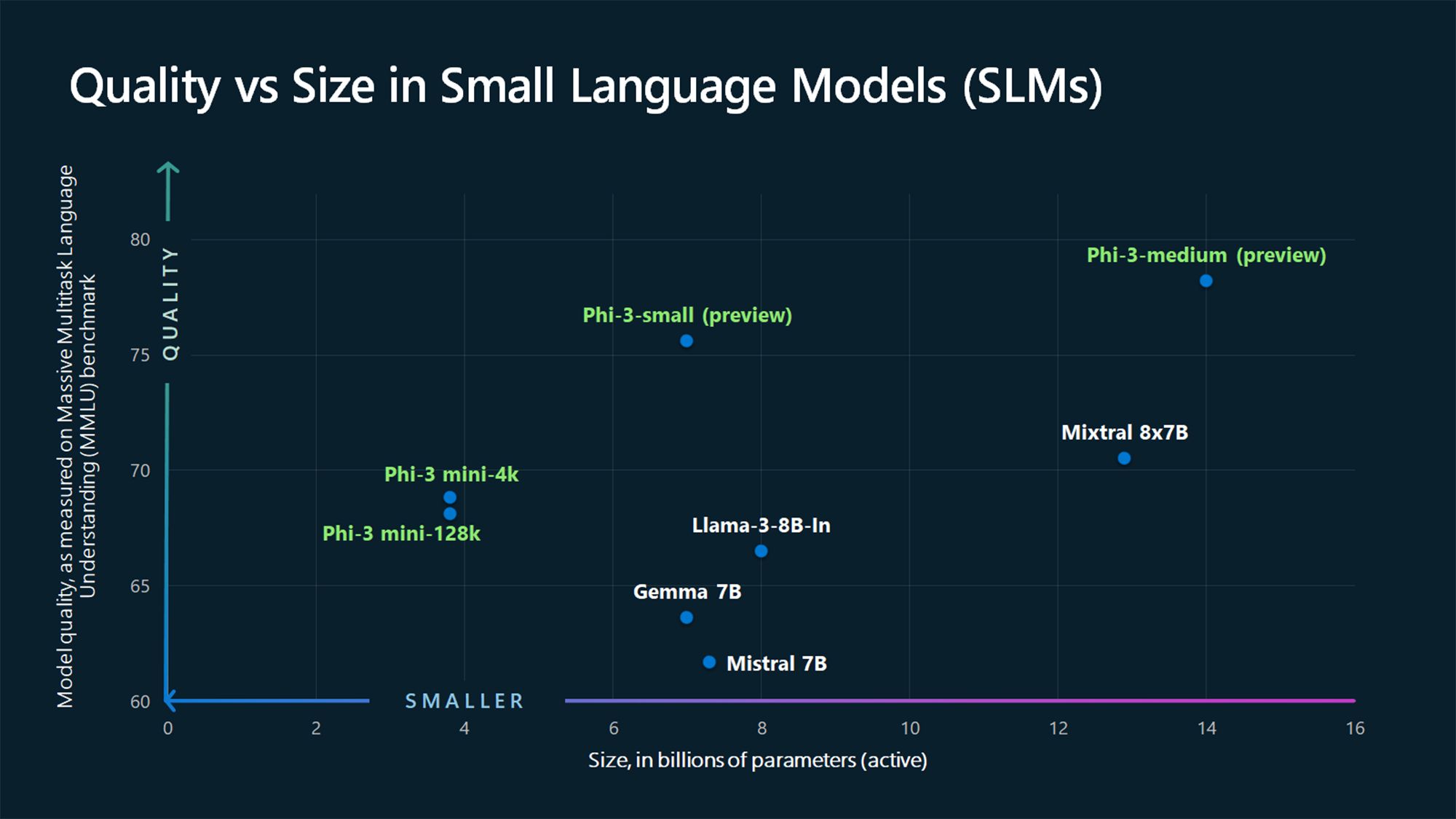
Un alt factor de diferențiere între SLM-uri și LLM-uri este volumul de date utilizat pentru antrenament. SLM-urile sunt antrenate cu cantități mai reduse de date, în timp ce LLM-urile folosesc seturi mari de date. Această diferență afectează și capacitatea modelului de a rezolva sarcini complexe.
Datorită cantității mari de date folosite la antrenament, LLM-urile sunt mai bine echipate pentru a rezolva sarcini complexe ce necesită raționament avansat, în timp ce SLM-urile sunt mai adecvate pentru sarcini simple. Spre deosebire de LLM-uri, SLM-urile folosesc mai puține date de antrenament, însă datele folosite trebuie să fie de o calitate superioară pentru a atinge multe dintre capacitățile LLM-urilor, dar într-un format compact.
De ce modelele lingvistice mici reprezintă viitorul
Pentru majoritatea cazurilor de utilizare, SLM-urile sunt mai bine poziționate pentru a deveni modelele de bază adoptate de companii și consumatori pentru o gamă largă de sarcini. Desigur, LLM-urile au avantajele lor și sunt mai potrivite pentru anumite cazuri, cum ar fi rezolvarea sarcinilor complexe. Cu toate acestea, SLM-urile sunt considerate viitorul pentru majoritatea aplicațiilor, din motivele enumerate mai jos.
1. Costuri reduse de antrenament și întreținere
 Timofeev Vladimir/Shutterstock
Timofeev Vladimir/Shutterstock
SLM-urile necesită mai puține date pentru antrenament comparativ cu LLM-urile, ceea ce le face o opțiune viabilă pentru persoane fizice și companii mici și mijlocii care au date de antrenament limitate, resurse financiare restrânse sau ambele. LLM-urile au nevoie de cantități mari de date pentru antrenament și, implicit, de resurse computaționale imense pentru antrenare și utilizare.
Pentru a oferi o perspectivă concretă, CEO-ul OpenAI, Sam Altman, a confirmat că antrenarea GPT-4 a costat peste 100 de milioane de dolari, declarație făcută la un eveniment MIT (conform Wired). Un alt exemplu este modelul LLM OPT-175B de la Meta. Meta afirmă că a fost antrenat folosind 992 de GPU-uri NVIDIA A100 de 80GB, care costă aproximativ 10.000 de dolari fiecare, conform CNBC. Asta înseamnă un cost de aproximativ 9 milioane de dolari, fără a include alte cheltuieli, precum energia electrică, salariile, etc.
Având în vedere aceste cifre, antrenarea unui LLM nu este viabilă pentru companiile mici și mijlocii. În contrast, SLM-urile au o barieră de intrare mai mică în ceea ce privește costurile și resursele, ceea ce va stimula adopția lor de către un număr tot mai mare de companii.
2. Performanță superioară
 GBJSTOCK / Shutterstock
GBJSTOCK / Shutterstock
Performanța este un alt domeniu în care SLM-urile depășesc LLM-urile, datorită dimensiunii lor compacte. SLM-urile au o latență mai mică și sunt mai potrivite pentru scenariile în care sunt necesare răspunsuri rapide, cum ar fi aplicațiile în timp real. De exemplu, un timp de răspuns rapid este esențial în sistemele de răspuns vocal, cum ar fi asistenții digitali.
Funcționarea pe dispozitive (detalii mai jos) înseamnă că solicitările nu trebuie să mai fie trimise către serverele online pentru a primi un răspuns, ceea ce reduce timpii de reacție.
3. Mai precise
 ZinetroN / Shutterstock
ZinetroN / Shutterstock
În contextul inteligenței artificiale generative, un aspect rămâne constant: calitatea precară a datelor duce la rezultate slabe. LLM-urile actuale au fost antrenate cu ajutorul unor seturi mari de date colectate de pe internet. Ca urmare, ele nu sunt întotdeauna precise în toate situațiile. Aceasta este una dintre problemele lui ChatGPT și a altor modele similare, și motivul pentru care nu ar trebui să avem încredere absolută în tot ceea ce afirmă un chatbot bazat pe inteligență artificială. Pe de altă parte, SLM-urile sunt antrenate utilizând date de o calitate superioară comparativ cu LLM-urile, ceea ce se traduce prin precizie sporită.
SLM-urile pot fi optimizate și printr-un antrenament suplimentar, concentrat pe sarcini sau domenii specifice, rezultând o precizie mai bună în acele domenii, comparativ cu modelele mai mari și generaliste.
4. Capacitatea de a funcționa pe dispozitive
 Pete Hansen/Shutterstock
Pete Hansen/Shutterstock
SLM-urile necesită o putere de calcul mai mică decât LLM-urile, fiind ideale pentru scenariile de procesare la nivel local. Ele pot fi implementate pe dispozitive precum smartphone-uri și vehicule autonome, care nu dispun de multă putere sau resurse de calcul. Modelul Nano de la Google poate funcționa direct pe dispozitive, chiar și atunci când nu există o conexiune la internet activă.
Această capacitate generează un beneficiu atât pentru companii, cât și pentru consumatori. În primul rând, reprezintă un avantaj pentru confidențialitate, deoarece datele utilizatorilor sunt prelucrate local, fără a fi transmise în cloud, ceea ce este important odată cu integrarea tot mai profundă a inteligenței artificiale în smartphone-urile noastre, care stochează aproape fiecare detaliu personal. Este, de asemenea, un avantaj pentru companii, deoarece nu mai trebuie să dezvolte și să opereze servere mari pentru a gestiona sarcinile AI.
SLM-urile câștigă teren, iar cei mai mari actori din industrie, cum ar fi OpenAI, Google, Microsoft, Anthropic și Meta, lansează astfel de modele. Aceste modele sunt mai potrivite pentru sarcini simple, care, de fapt, reprezintă și cea mai mare parte din utilizarea LLM-urilor; prin urmare, ele reprezintă viitorul.
Totuși, LLM-urile nu vor dispărea. Ele vor fi folosite în continuare pentru aplicații avansate, care combină informații din diverse domenii pentru a genera ceva nou, cum ar fi în cercetarea medicală.