

Datele sunt o parte indispensabilă a afacerilor și organizațiilor și sunt valoroase doar atunci când sunt structurate corespunzător și gestionate eficient.
Potrivit unei statistici, 95% dintre companii de astăzi consideră gestionarea și structurarea datelor nestructurate o problemă.
Aici intervine data mining-ul. Este procesul de descoperire, analiză și extragere a modelelor semnificative și a informațiilor valoroase din seturi mari de date nestructurate.
Companiile folosesc software pentru a identifica modele în loturi mari de date pentru a afla mai multe despre clienții lor și publicul țintă și pentru a dezvolta strategii de afaceri și de marketing pentru a îmbunătăți vânzările și a reduce costurile.
Pe lângă acest beneficiu, detectarea fraudei și a anomaliilor sunt cele mai importante aplicații ale minării de date.
Acest articol explică detectarea anomaliilor și explorează în continuare modul în care poate ajuta la prevenirea încălcării datelor și a intruziunilor în rețea pentru a asigura securitatea datelor.
Cuprins
Ce este detectarea anomaliilor și tipurile acesteia?
În timp ce data mining implică găsirea de modele, corelații și tendințe care se leagă între ele, este o modalitate excelentă de a găsi anomalii sau puncte de date aberante în rețea.
Anomaliile în data mining sunt puncte de date care diferă de alte puncte de date din setul de date și se abat de la modelul de comportament normal al setului de date.
Anomaliile pot fi clasificate în tipuri și categorii distincte, inclusiv:
- Schimbări în evenimente: se referă la schimbări bruște sau sistematice față de comportamentul normal anterior.
- Valori aberante: modele mici anormale care apar într-un mod nesistematic în colectarea datelor. Acestea pot fi clasificate în continuare în valori aberante globale, contextuale și colective.
- Derive: modificare treptată, nedirecțională și pe termen lung a setului de date.
Astfel, detectarea anomaliilor este o tehnică de procesare a datelor extrem de utilă pentru detectarea tranzacțiilor frauduloase, tratarea studiilor de caz cu dezechilibru de înaltă clasă și detectarea bolilor pentru a construi modele solide de știință a datelor.
De exemplu, o companie poate dori să-și analizeze fluxul de numerar pentru a găsi tranzacții anormale sau recurente către un cont bancar necunoscut pentru a detecta frauda și a efectua investigații suplimentare.
Beneficiile detectării anomaliilor
Detectarea anomaliilor de comportament ale utilizatorilor ajută la consolidarea sistemelor de securitate și le face mai precise și mai precise.
Analizează și dă sens informațiilor variate pe care sistemele de securitate le oferă pentru a identifica amenințările și riscurile potențiale din rețea.
Iată avantajele detectării anomaliilor pentru companii:
- Detectarea în timp real a amenințărilor de securitate cibernetică și a încălcărilor de date, deoarece algoritmii de inteligență artificială (AI) vă scanează în mod constant datele pentru a găsi un comportament neobișnuit.
- Face urmărirea activităților și modelelor anormale mai rapidă și mai ușoară decât detectarea manuală a anomaliilor, reducând munca și timpul necesar pentru a rezolva amenințările.
- Minimizează riscurile operaționale prin identificarea erorilor operaționale, cum ar fi scăderile bruște de performanță, înainte ca acestea să apară.
- Ajută la eliminarea daunelor majore ale afacerii prin detectarea rapidă a anomaliilor, deoarece fără un sistem de detectare a anomaliilor, companiile pot dura săptămâni și luni pentru a identifica potențialele amenințări.
Astfel, detectarea anomaliilor este un atu imens pentru companiile care stochează seturi extinse de date despre clienți și afaceri pentru a găsi oportunități de creștere și pentru a elimina amenințările de securitate și blocajele operaționale.
Tehnici de detectare a anomaliilor
Detectarea anomaliilor folosește mai multe proceduri și algoritmi de învățare automată (ML) pentru a monitoriza datele și a detecta amenințările.
Iată principalele tehnici de detectare a anomaliilor:
#1. Tehnici de învățare automată

Tehnicile de învățare automată folosesc algoritmi ML pentru a analiza datele și a detecta anomalii. Diferitele tipuri de algoritmi de învățare automată pentru detectarea anomaliilor includ:
- Algoritmi de grupare
- Algoritmi de clasificare
- Algoritmi de învățare profundă
Iar tehnicile ML utilizate în mod obișnuit pentru detectarea anomaliilor și amenințărilor includ mașini vector de suport (SVM), clustering k-means și autoencodere.
#2. Tehnici statistice
Tehnicile statistice folosesc modele statistice pentru a detecta modele neobișnuite (cum ar fi fluctuațiile neobișnuite ale performanței unei anumite mașini) în date pentru a detecta valori care se încadrează dincolo de intervalul valorilor așteptate.
Tehnicile comune de detectare a anomaliilor statistice includ testarea ipotezelor, IQR, scorul Z, scorul Z modificat, estimarea densității, diagrama cu casete, analiza valorilor extreme și histograma.
#3. Tehnici de extragere a datelor

Tehnicile de extragere a datelor folosesc tehnici de clasificare și grupare a datelor pentru a găsi anomalii în setul de date. Unele tehnici comune de analiză a anomaliilor de extragere a datelor includ gruparea spectrală, gruparea bazată pe densitate și analiza componentelor principale.
Algoritmii de extragere a datelor în cluster sunt utilizați pentru a grupa diferite puncte de date în clustere pe baza similitudinii lor pentru a găsi puncte de date și anomalii care se încadrează în afara acestor clustere.
Pe de altă parte, algoritmii de clasificare alocă puncte de date unor clase specifice predefinite și detectează puncte de date care nu aparțin acestor clase.
#4. Tehnici bazate pe reguli
După cum sugerează și numele, tehnicile de detectare a anomaliilor bazate pe reguli folosesc un set de reguli predeterminate pentru a găsi anomalii în date.
Aceste tehnici sunt relativ mai ușor și mai simplu de configurat, dar pot fi inflexibile și pot să nu fie eficiente în adaptarea la comportamentul și modelele de date în schimbare.
De exemplu, puteți programa cu ușurință un sistem bazat pe reguli pentru a semnala tranzacțiile care depășesc o anumită sumă de dolari ca fiind frauduloase.
#5. Tehnici specifice domeniului
Puteți utiliza tehnici specifice domeniului pentru a detecta anomalii în anumite sisteme de date. Cu toate acestea, deși pot fi foarte eficienți în detectarea anomaliilor în domenii specifice, ele pot fi mai puțin eficiente în alte domenii în afara celui specificat.
De exemplu, folosind tehnici specifice domeniului, puteți proiecta tehnici special pentru a găsi anomalii în tranzacțiile financiare. Dar, este posibil să nu funcționeze pentru a găsi anomalii sau scăderi de performanță într-o mașină.
Nevoia de învățare automată pentru detectarea anomaliilor
Învățarea automată este foarte importantă și foarte utilă în detectarea anomaliilor.
Astăzi, majoritatea companiilor și organizațiilor care necesită detectarea valorii aberante se ocupă cu cantități uriașe de date, de la text, informații despre clienți și tranzacții până la fișiere media, cum ar fi imagini și conținut video.
Parcurgerea tuturor tranzacțiilor bancare și a datelor generate manual în fiecare secundă pentru a obține o perspectivă semnificativă este aproape imposibilă. Mai mult, majoritatea companiilor se confruntă cu provocări și dificultăți majore în structurarea datelor nestructurate și aranjarea datelor într-un mod semnificativ pentru analiza datelor.
Aici instrumentele și tehnicile precum învățarea automată (ML) joacă un rol important în colectarea, curățarea, structurarea, aranjarea, analizarea și stocarea unor volume uriașe de date nestructurate.
Tehnicile și algoritmii de învățare automată procesează seturi mari de date și oferă flexibilitatea de a utiliza și combina diferite tehnici și algoritmi pentru a oferi cele mai bune rezultate.
În plus, învățarea automată ajută și la eficientizarea proceselor de detectare a anomaliilor pentru aplicațiile din lumea reală și economisește resurse valoroase.
Iată câteva beneficii suplimentare și importanța învățării automate în detectarea anomaliilor:
- Face detectarea anomaliilor de scalare mai ușoară prin automatizarea identificării tiparelor și a anomaliilor fără a necesita programare explicită.
- Algoritmii de învățare automată sunt foarte adaptabili la schimbarea tiparelor setului de date, făcându-i extrem de eficienți și robusti în timp.
- Gestionează cu ușurință seturi de date mari și complexe, făcând eficientă detectarea anomaliilor în ciuda complexității setului de date.
- Asigură identificarea și detectarea precoce a anomaliilor prin identificarea anomaliilor pe măsură ce apar, economisind timp și resurse.
- Sistemele de detectare a anomaliilor bazate pe Machine Learning ajută la atingerea unor niveluri mai ridicate de precizie în detectarea anomaliilor în comparație cu metodele tradiționale.
Astfel, detectarea anomaliilor asociată cu învățarea automată ajută la detectarea mai rapidă și mai timpurie a anomaliilor pentru a preveni amenințările de securitate și încălcările rău intenționate.
Algoritmi de învățare automată pentru detectarea anomaliilor
Puteți detecta anomalii și valori aberante în date cu ajutorul diferiților algoritmi de extragere a datelor pentru clasificare, grupare sau învățare a regulilor de asociere.
De obicei, acești algoritmi de extragere a datelor sunt clasificați în două categorii diferite – algoritmi de învățare supravegheați și nesupravegheați.
Învățare supravegheată
Învățarea supravegheată este un tip comun de algoritm de învățare care constă din algoritmi precum mașini de suport vector, regresie logistică și liniară și clasificare multi-clasă. Acest tip de algoritm este antrenat pe date etichetate, ceea ce înseamnă că setul său de date de antrenament include atât date de intrare normale, cât și rezultate corecte corespunzătoare sau exemple anormale pentru a construi un model predictiv.
Astfel, scopul său este de a face predicții de ieșire pentru date nevăzute și noi pe baza modelelor setului de date de antrenament. Aplicațiile algoritmilor de învățare supravegheată includ recunoașterea imaginilor și a vorbirii, modelarea predictivă și procesarea limbajului natural (NLP).
Învățare nesupravegheată
Învățarea nesupravegheată nu este instruită pe date etichetate. În schimb, descoperă procese complicate și structurile de date subiacente fără a furniza ghidarea algoritmului de antrenament și în loc să facă predicții specifice.
Aplicațiile algoritmilor de învățare nesupravegheată includ detectarea anomaliilor, estimarea densității și compresia datelor.
Acum, să explorăm câțiva algoritmi populari de detectare a anomaliilor bazați pe învățarea automată.
Factorul Outlier Local (LOF)
Local Outlier Factor sau LOF este un algoritm de detectare a anomaliilor care ia în considerare densitatea datelor locale pentru a determina dacă un punct de date este o anomalie.
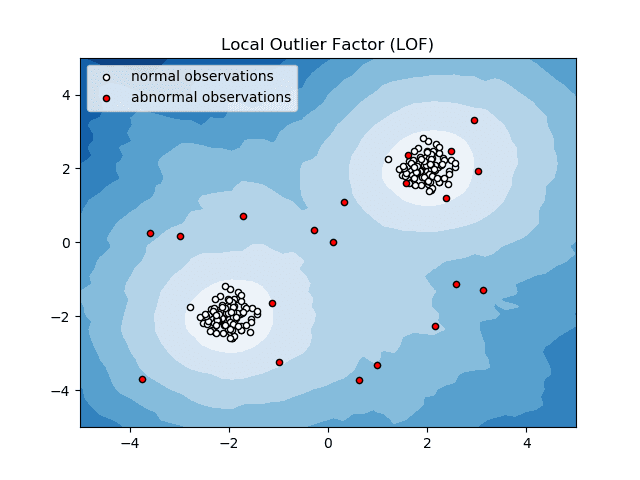 Sursa: scikit-learn.org
Sursa: scikit-learn.org
El compară densitatea locală a unui articol cu densitățile locale ale vecinilor săi pentru a analiza zone cu densități similare și articole cu densități comparativ mai mici decât vecinii lor – care nu sunt altceva decât anomalii sau valori aberante.
Astfel, în termeni simpli, densitatea din jurul unui element anormal sau anormal diferă de densitatea din jurul vecinilor săi. Prin urmare, acest algoritm este numit și algoritm de detectare a valorii aberante bazat pe densitate.
K-Cel mai apropiat vecin (K-NN)
K-NN este cel mai simplu algoritm de clasificare și de detectare a anomaliilor supravegheate care este ușor de implementat, stochează toate exemplele și datele disponibile și clasifică noile exemple pe baza asemănărilor din metrica distanței.
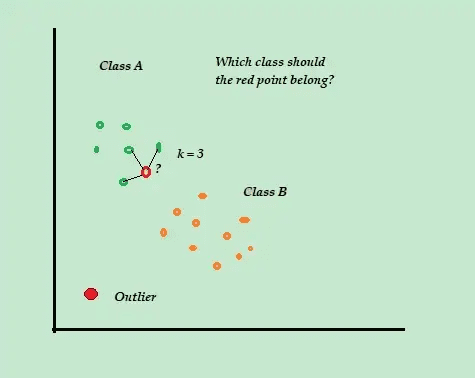 Sursa: aboutdatascience.com
Sursa: aboutdatascience.com
Acest algoritm de clasificare mai este numit și învățator leneș, deoarece stochează doar datele de antrenament etichetate, fără a face nimic altceva în timpul procesului de antrenament.
Când sosește noul punct de date de antrenament neetichetat, algoritmul analizează punctele K de date de antrenament cele mai apropiate sau cele mai apropiate pentru a le utiliza pentru a clasifica și determina clasa noului punct de date neetichetat.
Algoritmul K-NN utilizează următoarele metode de detectare pentru a determina cele mai apropiate puncte de date:
- Distanța euclidiană pentru a măsura distanța pentru date continue.
- Distanța Hamming pentru a măsura proximitatea sau „apropierea” celor două șiruri de text pentru date discrete.
De exemplu, luați în considerare seturile dvs. de date de antrenament constau din două etichete de clasă, A și B. Dacă sosește un nou punct de date, algoritmul va calcula distanța dintre noul punct de date și fiecare dintre punctele de date din setul de date și va selecta punctele. care sunt numărul maxim cel mai apropiat de noul punct de date.
Deci, să presupunem că K=3 și 2 din 3 puncte de date sunt etichetate ca A, apoi noul punct de date este etichetat ca clasa A.
Prin urmare, algoritmul K-NN funcționează cel mai bine în medii dinamice cu cerințe frecvente de actualizare a datelor.
Este un algoritm popular de detectare a anomaliilor și extragere de text cu aplicații în finanțe și afaceri pentru a detecta tranzacțiile frauduloase și a crește rata de detectare a fraudei.
Suport Vector Machine (SVM)
Mașina vectorială de suport este un algoritm de detectare a anomaliilor bazat pe învățarea automată supravegheat, utilizat în principal în probleme de regresie și clasificare.
Utilizează un hiperplan multidimensional pentru a segrega datele în două grupuri (nou și normal). Astfel, hiperplanul acționează ca o limită de decizie care separă observațiile de date normale și datele noi.
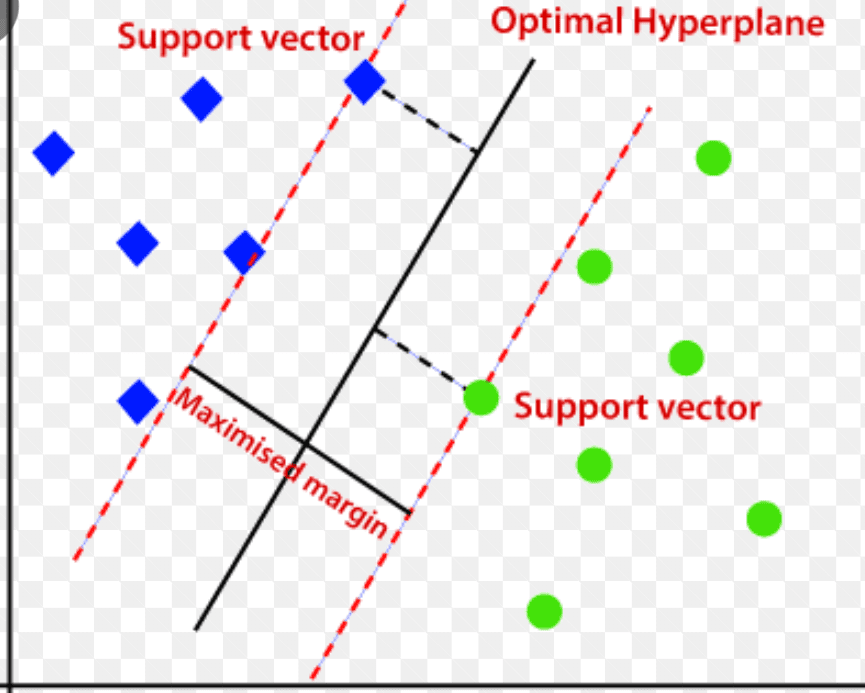 Sursa: www.analyticsvidhya.com
Sursa: www.analyticsvidhya.com
Distanța dintre aceste două puncte de date este denumită margini.
Deoarece scopul este de a crește distanța dintre cele două puncte, SVM determină cel mai bun sau cel mai optim hiperplan cu marja maximă pentru a se asigura că distanța dintre cele două clase este cât mai mare posibil.
În ceea ce privește detectarea anomaliilor, SVM calculează marja noului punct de observație de date din hiperplan pentru a o clasifica.
Dacă marja depășește pragul stabilit, aceasta clasifică noua observație drept anomalie. În același timp, dacă marja este mai mică decât pragul, observația este clasificată ca normală.
Astfel, algoritmii SVM sunt extrem de eficienți în manipularea seturilor de date de dimensiuni mari și complexe.
Pădure de izolare
Isolation Forest este un algoritm de detectare a anomaliilor de învățare automată nesupravegheat, bazat pe conceptul unui clasificator de pădure aleatoriu.
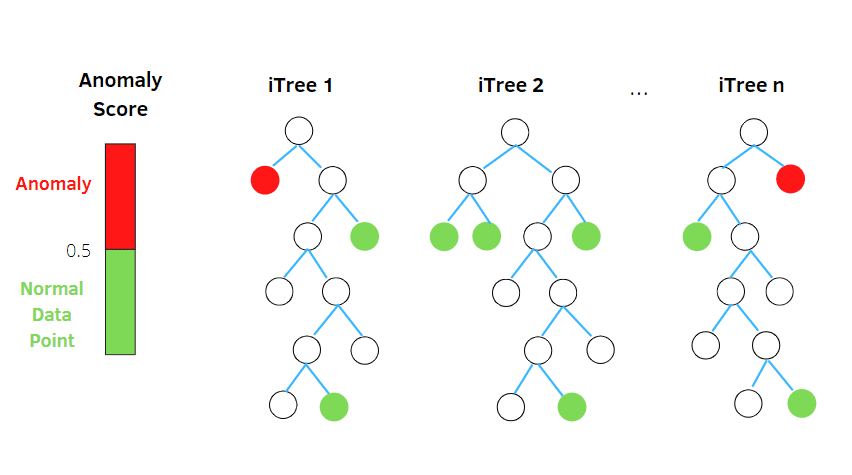 Sursa: betterprogramming.pub
Sursa: betterprogramming.pub
Acest algoritm procesează date aleator subeșantionate în setul de date într-o structură arborescentă bazată pe atribute aleatorii. Construiește mai mulți arbori de decizie pentru a izola observațiile. Și consideră o anumită observație o anomalie dacă este izolată în mai puțini copaci pe baza ratei sale de contaminare.
Astfel, în termeni simpli, algoritmul pădurii de izolare împarte punctele de date în arbori de decizie diferiți – asigurându-se că fiecare observație este izolată de alta.
Anomaliile se află în mod obișnuit departe de clusterul de puncte de date, ceea ce face mai ușor identificarea anomaliilor în comparație cu punctele de date normale.
Algoritmii pădurii de izolare pot gestiona cu ușurință date categorice și numerice. Drept urmare, sunt mai rapid de antrenat și sunt foarte eficienți în detectarea anomaliilor în seturi de date mari și de dimensiuni mari.
Gama inter-quartile
Intervalul interquartile sau IQR este folosit pentru a măsura variabilitatea statistică sau dispersia statistică pentru a găsi puncte anormale în seturile de date prin împărțirea lor în quartile.
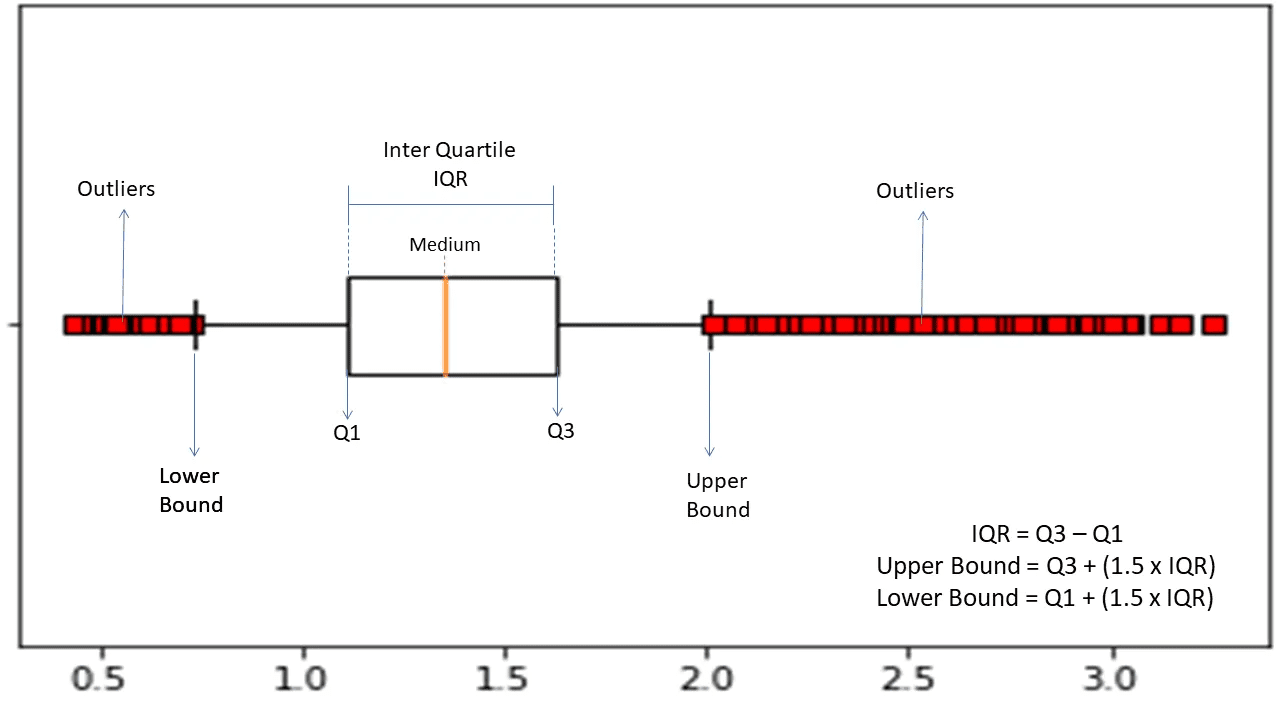 Sursa: morioh.com
Sursa: morioh.com
Algoritmul sortează datele în ordine crescătoare și împarte setul în patru părți egale. Valorile care separă aceste părți sunt Q1, Q2 și Q3 – primul, al doilea și al treilea quartile.
Iată distribuția în percentile a acestor quartile:
- Q1 înseamnă a 25-a percentila a datelor.
- Q2 înseamnă a 50-a percentila a datelor.
- Q3 înseamnă a 75-a percentila a datelor.
IQR este diferența dintre setul de date al treilea (75) și primul (25) percentile, reprezentând 50% din date.
Utilizarea IQR pentru detectarea anomaliilor necesită să calculați IQR-ul setului de date și să definiți limitele inferioare și superioare ale datelor pentru a găsi anomalii.
- Limita inferioară: Q1 – 1,5 * IQR
- Limita superioară: Q3 + 1,5 * IQR
De obicei, observațiile care se încadrează în afara acestor limite sunt considerate anomalii.
Algoritmul IQR este eficient pentru seturile de date cu date distribuite neuniform și unde distribuția nu este bine înțeleasă.
Cuvinte finale
Riscurile de securitate cibernetică și încălcările de date nu par să se reducă în următorii ani – iar această industrie riscantă este de așteptat să crească în continuare în 2023, iar atacurile cibernetice IoT singure se anticipează să se dubleze până în 2025.
În plus, infracțiunile cibernetice vor costa companii și organizații globale aproximativ 10,3 trilioane de dolari anual până în 2025.
Acesta este motivul pentru care nevoia de tehnici de detectare a anomaliilor devine din ce în ce mai răspândită și necesară astăzi pentru detectarea fraudelor și prevenirea intruziunilor în rețea.
Acest articol vă va ajuta să înțelegeți ce sunt anomaliile în data mining, diferite tipuri de anomalii și modalități de a preveni intruziunile în rețea folosind tehnici de detectare a anomaliilor bazate pe ML.
În continuare, puteți explora totul despre matricea de confuzie în învățarea automată.