
Reddit oferă fluxuri JSON pentru fiecare subreddit. Iată cum puteți crea un script Bash care descarcă și analizează o listă de postări din orice subreddit care vă place. Acesta este doar un lucru pe care îl puteți face cu fluxurile JSON ale Reddit.
Cuprins
Instalarea Curl și JQ
Vom folosi curl pentru a prelua feedul JSON din Reddit și jq pentru a analiza datele JSON și a extrage câmpurile pe care le dorim din rezultate. Instalați aceste două dependențe folosind apt-get pe Ubuntu și alte distribuții Linux bazate pe Debian. Pe alte distribuții Linux, utilizați în schimb instrumentul de gestionare a pachetelor din distribuția dvs.
sudo apt-get install curl jq
Preluați câteva date JSON de la Reddit
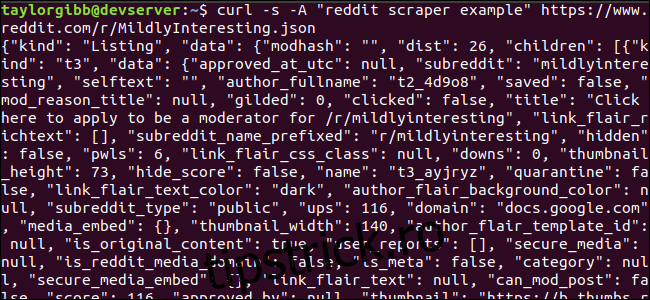
Să vedem cum arată fluxul de date. Folosiți curl pentru a obține cele mai recente postări din Ușor Interesant subreddit:
curl -s -A “reddit scraper example” https://www.reddit.com/r/MildlyInteresting.json
Observați cum opțiunile utilizate înainte de URL: -s forțează curl să ruleze în modul silențios, astfel încât să nu vedem nicio ieșire, cu excepția datelor de pe serverele Reddit. Următoarea opțiune și parametrul care urmează, -Un „exemplu reddit scraper” setează un șir personalizat de agent de utilizator care ajută Reddit să identifice serviciul care accesează datele lor. Serverele Reddit API aplică limite de rată bazate pe șirul de agent de utilizator. Setarea unei valori personalizate va face ca Reddit să segmenteze limita noastră de rată departe de alți apelanți și va reduce șansa de a primi o eroare HTTP 429 Rate Limit Exceeded.
Ieșirea ar trebui să umple fereastra terminalului și să arate cam așa:
Există o mulțime de câmpuri în datele de ieșire, dar tot ceea ce ne interesează sunt Titlu, Permalink și URL. Puteți vedea o listă exhaustivă de tipuri și câmpurile acestora pe pagina de documentație a API-ului Reddit: https://github.com/reddit-archive/reddit/wiki/JSON
Extragerea datelor din ieșirea JSON
Dorim să extragem Titlu, Permalink și URL din datele de ieșire și să le salvăm într-un fișier delimitat de tabulatori. Putem folosi instrumente de procesare a textului precum sed și grep , dar avem la dispoziție un alt instrument care înțelege structurile de date JSON, numit jq . Pentru prima noastră încercare, să-l folosim pentru a imprima și a codifica culorile rezultatul. Vom folosi același apel ca înainte, dar de data aceasta, transmiteți ieșirea prin jq și instruiți-i să analizeze și să imprime datele JSON.
curl -s -A “reddit scraper example” https://www.reddit.com/r/MildlyInteresting.json | jq .
Observați perioada care urmează comenzii. Această expresie pur și simplu analizează intrarea și o tipărește așa cum este. Ieșirea arată frumos formatată și codată în culori:
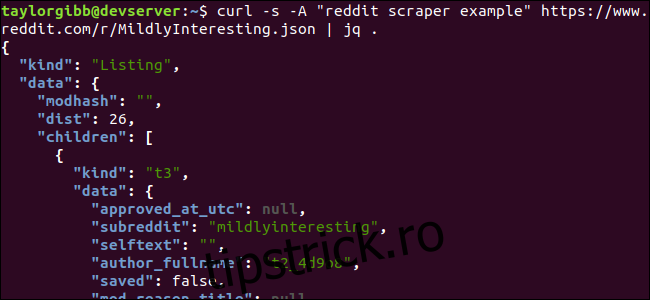
Să examinăm structura datelor JSON pe care le primim de la Reddit. Rezultatul rădăcină este un obiect care conține două proprietăți: tip și date. Acesta din urmă deține o proprietate numită copii, care include o serie de postări în acest subreddit.
Fiecare element din matrice este un obiect care conține și două câmpuri numite fel și date. Proprietățile pe care vrem să le luăm sunt în obiectul de date. jq așteaptă o expresie care poate fi aplicată datelor de intrare și produce rezultatul dorit. Trebuie să descrie conținutul în termeni de ierarhie și apartenență la o matrice, precum și modul în care datele ar trebui să fie transformate. Să rulăm din nou întreaga comandă cu expresia corectă:
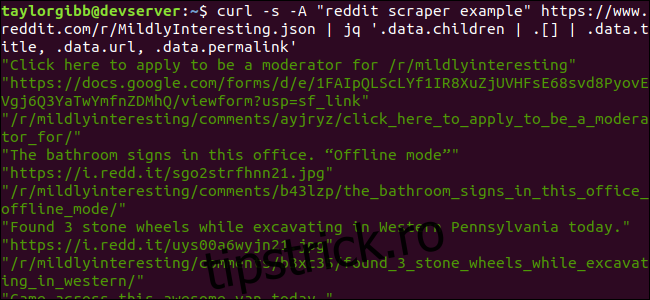
curl -s -A “reddit scraper example” https://www.reddit.com/r/MildlyInteresting.json | jq ‘.data.children | .[] | .data.title, .data.url, .data.permalink’
Rezultatul afișează titlul, adresa URL și linkul permanent, fiecare pe rândul său:
Să ne aprofundăm în comanda jq pe care am numit-o:
jq ‘.data.children | .[] | .data.title, .data.url, .data.permalink’
Există trei expresii în această comandă separate de două simboluri pipe. Rezultatele fiecărei expresii sunt trecute la următoarea pentru evaluare ulterioară. Prima expresie filtrează totul, cu excepția matricei de listări Reddit. Această ieșire este transmisă în a doua expresie și forțată într-o matrice. A treia expresie acționează asupra fiecărui element din matrice și extrage trei proprietăți. Mai multe informații despre jq și sintaxa expresiei sale pot fi găsite în manualul oficial al lui jq.
Punând totul împreună într-un scenariu
Să punem apelul API și post-procesarea JSON împreună într-un script care va genera un fișier cu postările pe care le dorim. Vom adăuga suport pentru preluarea postărilor din orice subreddit, nu doar /r/MildlyInteresting.
Deschideți editorul și copiați conținutul acestui fragment într-un fișier numit scrape-reddit.sh
#!/bin/bash
if [ -z "$1" ]
then
echo "Please specify a subreddit"
exit 1
fi
SUBREDDIT=$1
NOW=$(date +"%m_%d_%y-%H_%M")
OUTPUT_FILE="${SUBREDDIT}_${NOW}.txt"
curl -s -A "bash-scrape-topics" https://www.reddit.com/r/${SUBREDDIT}.json |
jq '.data.children | .[] | .data.title, .data.url, .data.permalink' |
while read -r TITLE; do
read -r URL
read -r PERMALINK
echo -e "${TITLE}t${URL}t${PERMALINK}" | tr --delete " >> ${OUTPUT_FILE}
done
Acest script va verifica mai întâi dacă utilizatorul a furnizat un nume subreddit. Dacă nu, se închide cu un mesaj de eroare și un cod de returnare diferit de zero.
În continuare, va stoca primul argument ca nume subreddit și va construi un nume de fișier marcat cu data în care rezultatul va fi salvat.
Acțiunea începe atunci când curl este apelat cu un antet personalizat și adresa URL a subreddit-ului de răzuit. Ieșirea este transmisă la jq, unde este analizată și redusă la trei câmpuri: Titlu, URL și Permalink. Aceste linii sunt citite, una la un moment dat, și salvate într-o variabilă folosind comanda read, toate în interiorul unei bucle while, care va continua până când nu mai sunt linii de citit. Ultima linie a blocului interior while ecou cele trei câmpuri, delimitate de un caracter tabulator, apoi o direcționează prin comanda tr, astfel încât ghilimelele duble să poată fi îndepărtate. Ieșirea este apoi atașată la un fișier.
Înainte de a putea executa acest script, trebuie să ne asigurăm că i s-au acordat permisiuni de execuție. Utilizați comanda chmod pentru a aplica aceste permisiuni fișierului:
chmod u+x scrape-reddit.sh
Și, în sfârșit, executați scriptul cu un nume subreddit:
./scrape-reddit.sh MildlyInteresting
Un fișier de ieșire este generat în același director și conținutul său va arăta cam așa:
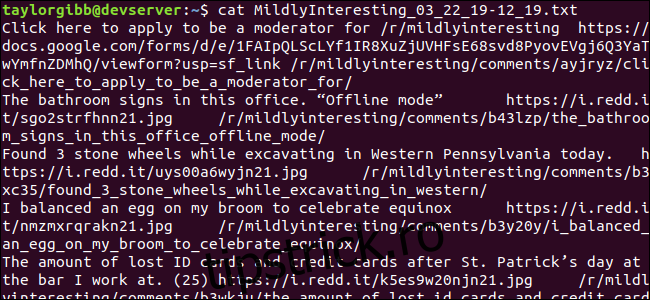
Fiecare linie conține cele trei câmpuri pe care le urmărim, separate folosind un caracter tabulator.
Mergând mai departe
Reddit este o mină de aur de conținut și conținut media interesant și toate sunt ușor de accesat folosind API-ul său JSON. Acum că aveți o modalitate de a accesa aceste date și de a procesa rezultatele, puteți face lucruri precum:
Luați cele mai recente titluri din /r/WorldNews și trimiteți-le pe desktop folosind notifica-trimite
Integrați cele mai bune glume de la /r/DadJokes în mesajul zilei al sistemului dvs.
Obțineți cea mai bună imagine de astăzi din /r/aww și faceți-o fundalul desktopului
Toate acestea sunt posibile folosind datele furnizate și instrumentele pe care le aveți în sistemul dumneavoastră. Hacking fericit!