

Dacă utilizați Linux de ceva vreme, știți deja despre grep — Global Regular Expression Print, un instrument de procesare a textului pe care îl puteți utiliza pentru a căuta fișiere și directoare. Este foarte util în mâinile unui utilizator cu putere Linux. Cu toate acestea, folosirea fără regex îi poate limita capacitățile.
Dar ce este Regex?
Regex sunt expresii regulate pe care le puteți folosi pentru a îmbunătăți funcționalitatea de căutare grep. Regex, prin definiție, este un model avansat de filtrare a ieșirii. Cu practică, puteți utiliza expresia regex în mod eficient, așa cum o puteți utiliza și cu alte comenzi Linux.
În tutorialul nostru, vom învăța cum să folosim Grep și Regex în mod eficient.
Cuprins
Condiție prealabilă
Utilizarea grep cu regex necesită cunoștințe bune de Linux. Dacă sunteți începător, consultați ghidurile noastre Linux.
De asemenea, aveți nevoie de acces la un laptop sau un computer care rulează sistemul de operare Linux. Puteți utiliza orice distribuție Linux la alegere. Și, dacă aveți o mașină Windows, puteți utiliza în continuare Linux cu WSL2. Consultați interpretarea noastră detaliată aici.
Accesul la linia de comandă/terminal vă permite să rulați toate comenzile furnizate în tutorialul nostru grep/regex.
Mai mult, aveți nevoie și de acces la fișiere text de care veți avea nevoie pentru a rula exemplele. Am folosit ChatGPT pentru a genera un perete de text, spunându-i să scrie despre tehnologie. Promptul pe care l-am folosit este ca mai jos.
„Generează 400 de cuvinte despre tehnologie. Ar trebui să includă majoritatea tehnologiei. De asemenea, asigurați-vă că repetați numele tehnologiei pe tot textul.”
Odată ce a generat textul, l-am copiat-lipit și l-am salvat în fișierul tech.txt, pe care îl vom folosi pe tot parcursul tutorialului.
În cele din urmă, o înțelegere de bază a comenzii grep este o necesitate. Puteți consulta 16 exemple de comandă grep pentru a vă reîmprospăta cunoștințele. De asemenea, vom introduce pe scurt comanda grep pentru a începe.
Sintaxă și exemple de comandă grep
Sintaxa comenzii grep este simplă.
$ grep -options [regex/pattern] [files]
După cum puteți observa, se așteaptă un model și lista de fișiere pe care doriți să rulați comanda.
Există o mulțime de opțiuni grep disponibile care îi modifică funcționalitatea. Acestea includ:
- – i: ignora cazurile
- -r: face căutare recursivă
- -w: efectuați o căutare pentru a găsi numai cuvinte întregi
- -v: afișați toate liniile care nu se potrivesc
- -n: afișați toate numerele de linii care se potrivesc
- -l: tipăriți numele fișierelor
- –culoare: rezultat colorat
- -c: arată numărul de potriviri pentru modelul utilizat
#1. Căutați un cuvânt întreg
Va trebui să utilizați argumentul -w cu grep pentru o căutare întreagă de cuvinte. Folosind-o, ocoliți orice șiruri care se potrivesc cu modelul dat.
$ grep -w ‘tech\|5G’ tech.txt
După cum puteți vedea, comanda are ca rezultat o ieșire în care caută două cuvinte, „5G” și „tech”, în text. Apoi le marchează cu culoare roșie.
Aici, | simbolul pipe este scapat, astfel încât grep să nu-l proceseze ca metacaracter.
#2. Căutare fără majuscule
Pentru a face o căutare care nu ține seama de majuscule și minuscule, utilizați grep cu argumentul -i.
$ grep -i ‘tech’ tech.txt
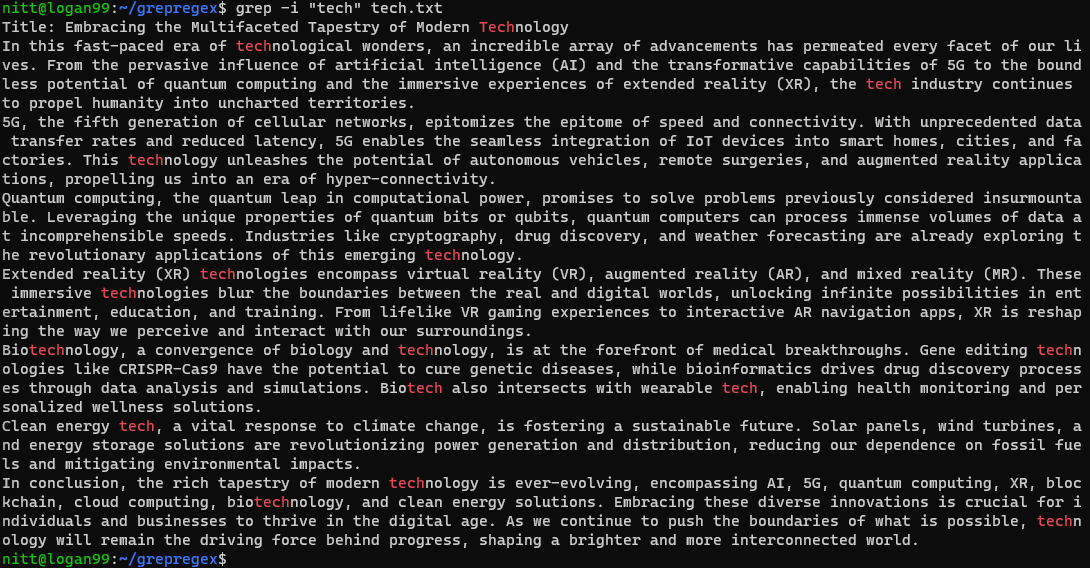
Comanda caută orice instanță care nu ține seama de majuscule și minuscule din șirul „tech”, fie că este vorba despre un cuvânt complet sau o parte din acesta.
#3. Efectuați o căutare de linii care nu se potrivește
Pentru a afișa toate liniile care nu conțin un model dat, va trebui să utilizați argumentul -v.
$ grep -v ‘tech’ tech.txt

Ieșirea arată toate liniile care nu conțin cuvântul „tehnologie”. De asemenea, veți vedea și linii goale. Aceste rânduri sunt liniile care sunt după un paragraf.
#4. Faceți o căutare recursiva
Pentru a efectua o căutare recursivă, utilizați argumentul -r cu grep.
$ grep -R ‘error\|warning’ /var/log/*.log
#output /var/log/bootstrap.log:2023-01-03 21:40:18 URL:http://ftpmaster.internal/ubuntu/pool/main/libg/libgpg-error/libgpg-erro 0_1.43-3_amd64.deb [69684/69684] -> "/build/chroot//var/cache/apt/archives/partial/libgpg-error0_1.43-3_amd64.deb" [1] /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: ignoring pre-dependency problem!
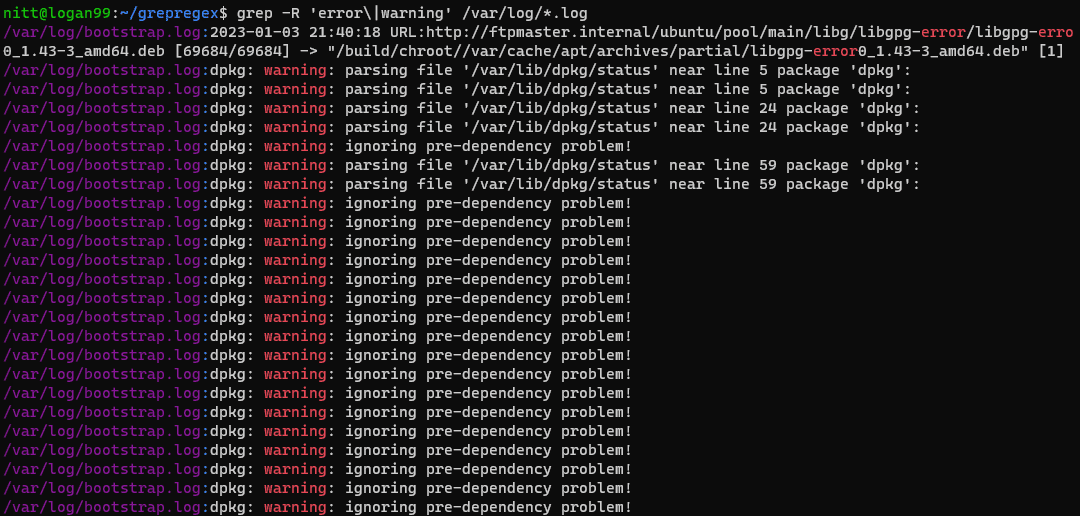
Comanda grep caută recursiv două cuvinte, „eroare” și „avertizare”, în directorul /var/log. Aceasta este o comandă utilă pentru a afla despre orice avertismente și erori din fișierele jurnal.
Grep și Regex: Ce este și exemple
Pe măsură ce lucrăm cu regex, trebuie să știți că regex oferă trei opțiuni de sintaxă. Acestea includ:
- Expresii regulate de bază (BRE)
- Expresii regulate extinse (ERE)
- Expresii regulate compatibile cu Pearl (PCRE)
Comanda grep folosește BRE ca opțiune implicită. Deci, dacă doriți să utilizați alte moduri regex, va trebui să le menționați. Comanda grep tratează și metacaracterele așa cum sunt. Deci, dacă utilizați metacaractere precum ?, +, ), va trebui să le scăpați cu comanda backslash (\).
Sintaxa grep cu regex este ca mai jos.
$ grep [regex] [filenames]
Să vedem grep și regex în acțiune cu exemplele de mai jos.
#1. Potriviri literale de cuvinte
Pentru a face o potrivire literală a cuvintelor, va trebui să furnizați un șir ca regex. La urma urmei, un cuvânt este și un regex.
$ grep "technologies" tech.txt

În mod similar, puteți utiliza și potriviri literale pentru a găsi utilizatorii actuali. Pentru a face asta, fugi,
$ grep bash /etc/passwd
#output root:x:0:0:root:/root:/bin/bash nitt:x:1000:1000:,,,:/home/nitt:/bin/bash
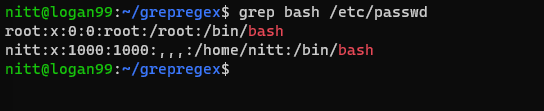
Aceasta afișează utilizatorii care pot accesa bash.
#2. Potrivirea ancorelor
Potrivirea ancorelor este o tehnică utilă pentru căutări avansate folosind caractere speciale. În regex, există diferite caractere de ancorare pe care le puteți folosi pentru a reprezenta poziții specifice într-un text. Acestea includ:
- Simbolul „^”: simbolul care se potrivește cu începutul șirului sau al liniei de intrare și caută un șir gol.
- Simbolul dolarului „$”: simbolul dolarului se potrivește cu sfârșitul șirului sau al liniei de intrare și caută un șir gol.
Celelalte două caractere de potrivire ancoră includ limita cuvântului „\ b” și limita „\ B” fără cuvinte.
- Limita cuvântului „\ b”: Cu \b, puteți afirma poziția dintre un cuvânt și un caracter necuvânt. Cu cuvinte simple, vă permite să potriviți cuvinte complete. În acest fel, puteți evita potrivirile parțiale. De asemenea, îl puteți folosi pentru a înlocui cuvinte sau pentru a număra aparițiile cuvintelor dintr-un șir.
- \B graniță non-cuvânt: este opusul \b graniță cuvânt în regex, deoarece afirmă o poziție care nu se află între caracterele cu două cuvinte sau fără cuvinte.
Să trecem prin exemple pentru a ne face o idee clară.
$ grep ‘^From’ tech.txt

Folosirea accentului necesită introducerea cuvântului sau modelului în cazul corect. Asta pentru că este sensibil la majuscule. Deci, dacă rulați următoarea comandă, nu va returna nimic.
$ grep ‘^from’ tech.txt
În mod similar, puteți folosi simbolul $ pentru a găsi propoziția care se potrivește cu un anumit model, șir sau cuvânt.
$ grep ‘technology.$' tech.txt

Puteți combina și simbolurile ^ și $. Să ne uităm la exemplul de mai jos.
$ grep “^From \| technology.$” tech.txt
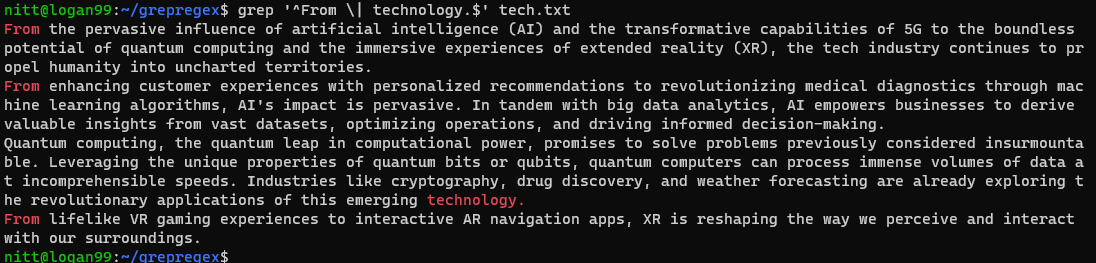
După cum puteți vedea, rezultatul conține propoziții care încep cu „De la” și propoziții care se termină cu „tehnologie”.
#3. Gruparea
Dacă doriți să căutați mai multe modele simultan, va trebui să utilizați Gruparea. Vă ajută să creați grupuri mici de personaje și modele pe care le puteți trata ca o singură unitate. De exemplu, puteți crea un grup (tehnologie) care include termenul „t”, „e”, „c”, „h”.
Pentru a vă face o idee clară, să vedem un exemplu.
$ grep 'technol\(ogy\)\?' tech.txt

Cu gruparea, puteți potrivi modele repetate, puteți captura grupuri și puteți căuta alternative.
Căutare alternativă cu grupare
Să vedem un exemplu de căutare alternativă.
$ grep "\(tech\|technology\)" tech.txt
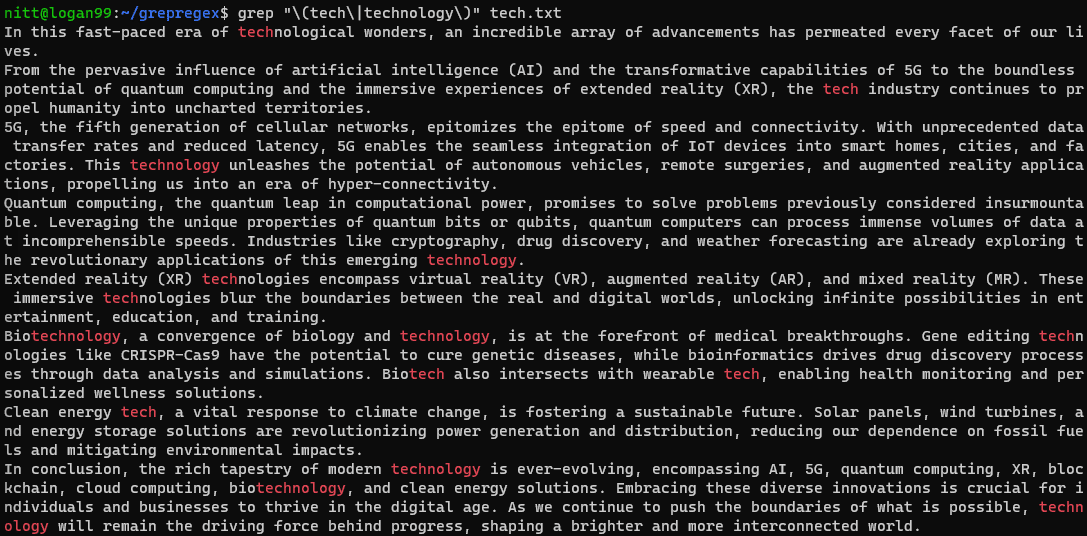
Dacă doriți să efectuați o căutare pe un șir, atunci va trebui să îl treceți cu simbolul țevii. Să o vedem în exemplul de mai jos.
$ echo “tech technological technologies technical” | grep "\(tech\|technology\)"
#output “tech technological technologies technical”

Grupuri de captură, grupuri fără captură și modele repetate
Și cum rămâne cu grupurile de captură și non-captură?
Va trebui să creați un grup în expresia regex și să-l transmiteți șirului sau unui fișier pentru a captura grupuri.
$ echo 'tech655 tech655nical technologies655 tech655-oriented 655' | grep "\(tech\)\(655\)"
#output tech655 tech655nical technologies655 tech655-oriented 655

Și, pentru grupurile care nu captează, va trebui să utilizați ?: în paranteză.
În cele din urmă, avem modele repetate. Va trebui să modificați expresia regex pentru a verifica dacă există modele repetate.
$ echo ‘teach tech ttrial tttechno attest’ | grep '\(t\+\)'
#output ‘teach tech ttrial tttechno attest’
Aici, expresia regex caută una sau mai multe instanțe ale caracterului „t”.
#4. Clasele de caractere
Cu clasele de caractere, puteți scrie cu ușurință expresii regex. Aceste clase de caractere folosesc paranteze drepte. Unele dintre clasele de personaje binecunoscute includ:
- [:digit:] – 0 până la 9 cifre
- [:alpha:] – caractere alfabetice
- [:alnum:] – caractere alfanumerice
- [:lower:] – litere mici
- [:upper:] – litere mari
- [:xdigit:] – cifre hexazecimale, inclusiv 0-9, AF, af
- [:blank:] – caractere goale, cum ar fi tab sau spațiu
Și așa mai departe!
Să verificăm câteva dintre ele în acțiune.
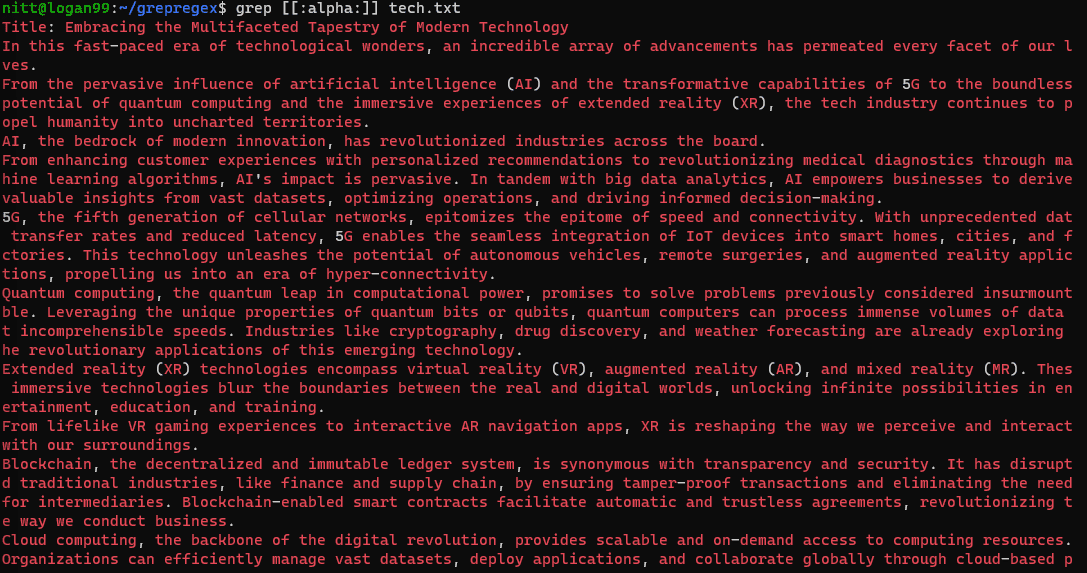
$ grep [[:digit]] tech.txt

$ grep [[:alpha:]] tech.txt
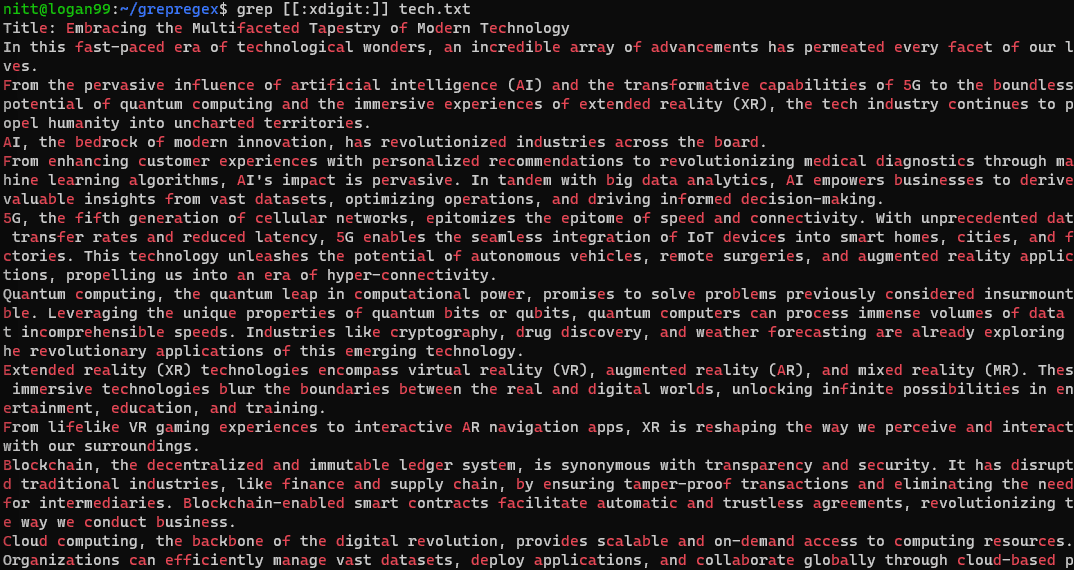
$ grep [[:xdigit:]] tech.txt
#5. Cuantificatori
Cuantificatorii sunt metacaractere și sunt în centrul expresiei regex. Acestea vă permit să potriviți exact aparițiile. Să le privim mai jos.
- * → Zero sau mai multe potriviri
- + → una sau mai multe potriviri
- ? → Zero sau unul se potrivește
- {x} → x se potrivește
- {x, } → x sau mai multe potriviri
- {x,z} → de la x la z se potrivește
- {, z} → până la z potriviri
$ echo ‘teach tech ttrial tttechno attest’ | grep -E 't+'
#output ‘teach tech ttrial tttechno attest’
Aici, caută caracterul „t” pentru una sau mai multe potriviri. Aici -E reprezintă expresia regex extinsă (despre care vom discuta mai târziu.)

#6. Regex extins
Dacă nu vă place să adăugați caractere de escape în modelul regex, trebuie să utilizați regex extins. Îndepărtează necesitatea de a adăuga caractere de evacuare. Pentru a face acest lucru, va trebui să utilizați steag-ul -E.
$ grep -E 'in+ovation' tech.txt

#7. Utilizarea PCRE pentru a face căutări complexe
PCRE (Perl Compatible Regular Expression) vă permite să faceți mult mai mult decât să scrieți expresii de bază. De exemplu, puteți scrie „\d” care denotă [0-9].
De exemplu, puteți utiliza PCRE pentru a căuta adrese de e-mail.
echo "Contact me at [email protected]" | grep -P "\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}\b"
#output Contact me at [email protected]

Aici, PCRE se asigură că modelul este potrivit. În mod similar, puteți utiliza, de asemenea, un model PCRE pentru a verifica modelele de dată.
$ echo "The Sparkain site launched on 2023-07-29" | grep -P "\b\d{4}-\d{2}-\d{2}\b"
#output The Sparkain site launched on 2023-07-29

Comanda găsește data în format AAAA-LL-ZZ. Îl puteți modifica pentru a se potrivi și cu alt format de dată.
#8. Alternanţă
Dacă doriți potriviri alternative, puteți utiliza caracterele pipe (\|).
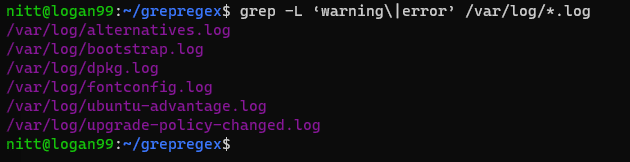
$ grep -L ‘warning\|error’ /var/log/*.log
#output /var/log/alternatives.log /var/log/bootstrap.log /var/log/dpkg.log /var/log/fontconfig.log /var/log/ubuntu-advantage.log /var/log/upgrade-policy-changed.log
Ieșirea listează numele fișierelor care conțin „avertisment” sau „eroare”.
Cuvinte finale
Acest lucru ne conduce la sfârșitul ghidului nostru grep și regex. Puteți folosi grep cu regex pe scară largă pentru a rafina căutările. Cu o utilizare corectă, puteți economisi mult timp și puteți ajuta la automatizarea multor sarcini, mai ales dacă le utilizați pentru a scrie scripturi sau utilizați regex în efectuarea căutărilor prin text.
Apoi, consultați întrebările și răspunsurile frecvente la interviu Linux.