Llama 2, un model lingvistic extins (LLM) cu cod sursă deschisă, este creat de Meta și se remarcă ca o alternativă performantă, posibil superioară unor modele închise precum GPT-3.5 și PaLM 2. Acesta este disponibil în trei variante de dimensiuni, pre-antrenate și ajustate pentru generarea textului, având 7 miliarde, 13 miliarde și respectiv 70 de miliarde de parametri.
În acest context, vom explora abilitățile conversaționale ale Llama 2 prin dezvoltarea unui chatbot folosind Streamlit și Llama 2.
Înțelegerea detaliată a Llama 2: caracteristici și avantaje cheie
Care sunt diferențele semnificative între Llama 2 și predecesorul său, Llama 1?
- Dimensiune superioară a modelului: Llama 2 se distinge printr-o dimensiune extinsă, ajungând până la 70 de miliarde de parametri, fapt ce îi oferă capacitatea de a învăța asocieri mai sofisticate între cuvinte și fraze.
- Abilități conversaționale avansate: Prin implementarea învățării prin consolidare cu feedback uman (RLHF), Llama 2 îmbunătățește capacitatea de a gestiona conversațiile, generând conținut cu nuanțe umane, chiar și în situații complexe.
- Inferență accelerată: Introducerea unei metode inovatoare, numită atenție la interogare grupată, contribuie la accelerarea procesului de inferență, făcând modelul mai eficient în aplicații precum chatbot-uri și asistenți virtuali.
- Eficiență sporită: Llama 2 este superior predecesorului său în ceea ce privește utilizarea memoriei și a resurselor de calcul.
- Licență open-source și non-comercială: Modelul are codul sursă deschis, permițând cercetătorilor și dezvoltatorilor să-l utilizeze și să-l adapteze liber.
Llama 2 marchează un progres considerabil față de versiunea anterioară. Aceste caracteristici fac din el un instrument puternic pentru o gamă variată de aplicații, cum ar fi chatbot-uri, asistenți virtuali și procesarea limbajului natural.
Configurarea mediului Streamlit pentru crearea chatbot-ului
Pentru a demara dezvoltarea aplicației, este necesară configurarea unui mediu de lucru izolat, care să nu interfereze cu proiectele existente pe computerul dumneavoastră.
Primul pas este crearea unui mediu virtual cu ajutorul bibliotecii Pipenv:
pipenv shell
În continuare, trebuie instalate bibliotecile necesare pentru construirea chatbot-ului:
pipenv install streamlit replicate
Streamlit: un cadru open-source pentru aplicații web, ideal pentru vizualizarea rapidă a proiectelor de învățare automată și știința datelor.
Replicate: o platformă cloud care oferă acces la modele de învățare automată extinse, cu cod sursă deschis, pentru implementare.
Obținerea tokenului API Llama 2 de la Replicate
Pentru a obține o cheie token Replicate, este necesară înregistrarea unui cont pe Replicate, folosind contul dumneavoastră GitHub.
După accesarea panoului de control, navigați la secțiunea Explore și căutați chat-ul Llama 2, selectând modelul llama-2–70b-chat.
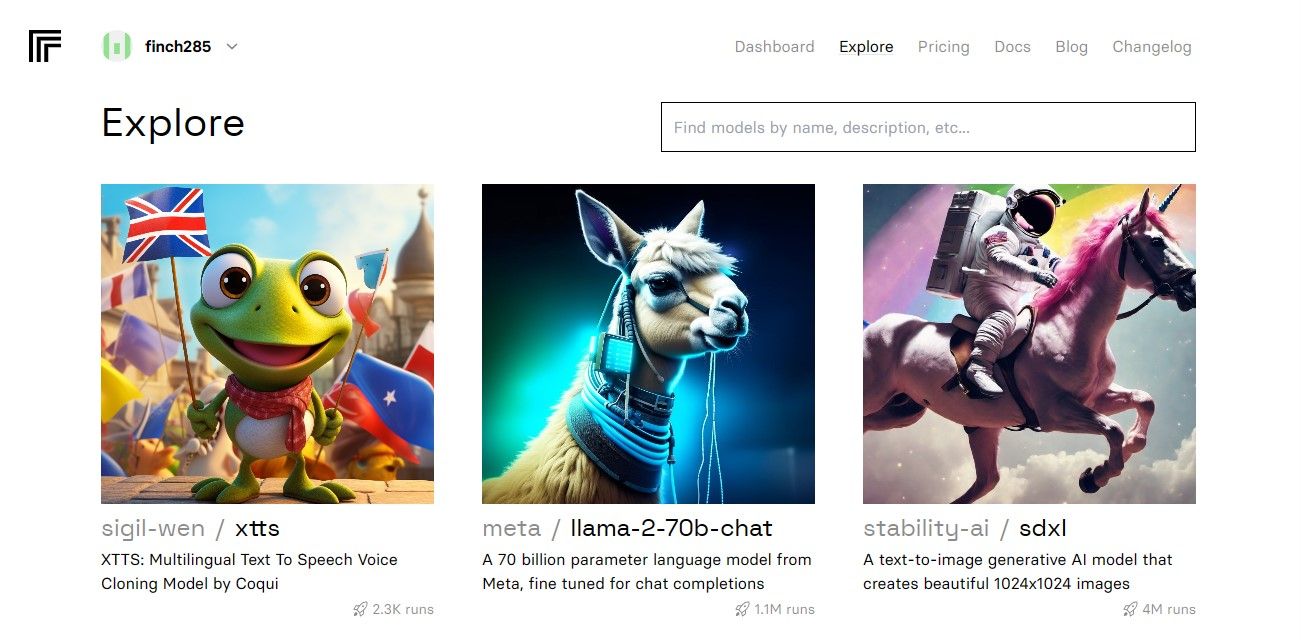
Selectați modelul llama-2–70b-chat pentru a vedea punctele finale API Llama 2. În bara de navigare a modelului, dați click pe butonul API. În partea dreaptă a paginii, selectați butonul Python, pentru a obține acces la tokenul API pentru aplicațiile Python.
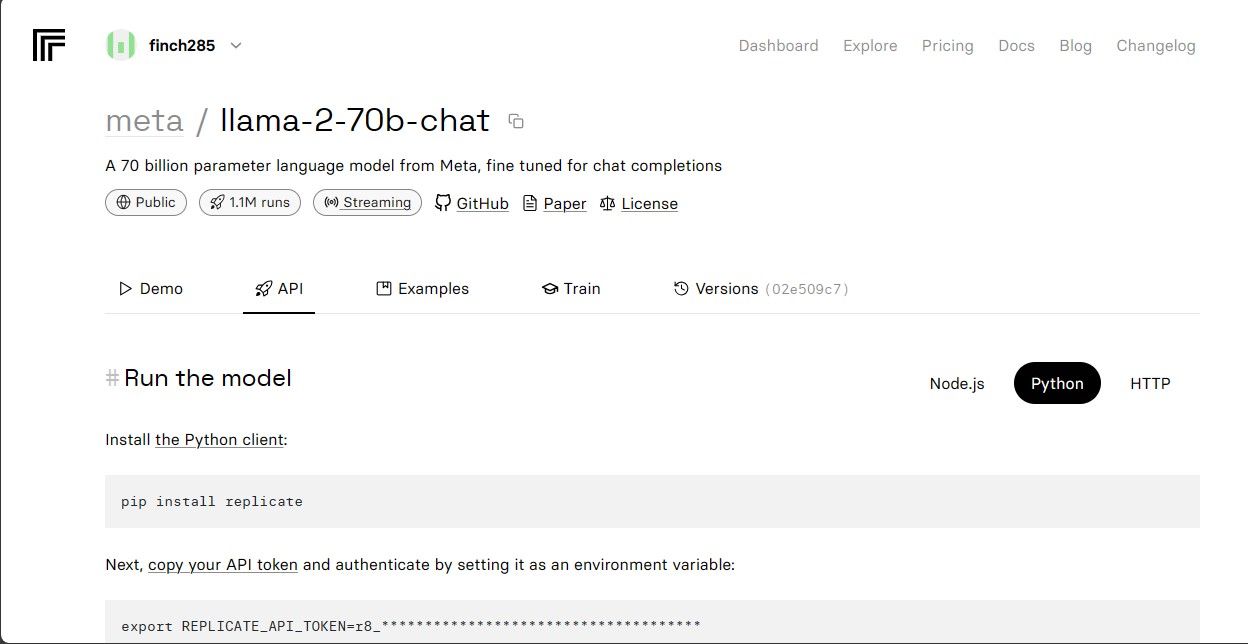
Copiați REPLICATE_API_TOKEN și salvați-l într-un loc sigur pentru utilizare ulterioară.
Dezvoltarea chatbot-ului
În primul rând, creați un fișier Python numit llama_chatbot.py și un fișier env (.env). Codul va fi scris în llama_chatbot.py, iar cheile secrete și tokenurile API vor fi stocate în fișierul .env.
În fișierul llama_chatbot.py, importați bibliotecile necesare:
import streamlit as st
import os
import replicate
Apoi, setați variabilele globale pentru modelul llama-2–70b-chat:
REPLICATE_API_TOKEN = os.environ.get('REPLICATE_API_TOKEN', default="")
LLaMA2_7B_ENDPOINT = os.environ.get('MODEL_ENDPOINT7B', default="")
LLaMA2_13B_ENDPOINT = os.environ.get('MODEL_ENDPOINT13B', default="")
LLaMA2_70B_ENDPOINT = os.environ.get('MODEL_ENDPOINT70B', default="")
În fișierul .env, adăugați tokenul Replicate și punctele finale ale modelului, după următorul format:
REPLICATE_API_TOKEN='Introduceți_Tokenul_Replicate'
MODEL_ENDPOINT7B='a16z-infra/llama7b-v2-chat:4f0a4744c7295c024a1de15e1a63c880d3da035fa1f49bfd344fe076074c8eea'
MODEL_ENDPOINT13B='a16z-infra/llama13b-v2-chat:df7690f1994d94e96ad9d568eac121aecf50684a0b0963b25a41cc40061269e5'
MODEL_ENDPOINT70B='replicate/llama70b-v2-chat:e951f18578850b652510200860fc4ea62b3b16fac280f83ff32282f87bbd2e48'
Lipiți tokenul de replicare și salvați fișierul .env.
Crearea fluxului conversațional al chatbot-ului
Definiți o solicitare inițială pentru a ghida modelul Llama 2, în funcție de rolul dorit. În acest scenariu, modelul va funcționa ca un asistent.
PRE_PROMPT = "Ești un asistent util. Nu răspunde ca 'Utilizator' sau nu te preface că ești 'Utilizator'." \
" Răspunde o singură dată ca Asistent."
Configurați setările paginii pentru chatbot, astfel:
st.set_page_config(
page_title="LLaMA2Chat",
page_icon=":volleyball:",
layout="wide"
)
Creați o funcție care să inițializeze și să stabilească variabilele de stare a sesiunii:
LLaMA2_MODELS = {
'LLaMA2-7B': LLaMA2_7B_ENDPOINT,
'LLaMA2-13B': LLaMA2_13B_ENDPOINT,
'LLaMA2-70B': LLaMA2_70B_ENDPOINT,
}
DEFAULT_TEMPERATURE = 0.1
DEFAULT_TOP_P = 0.9
DEFAULT_MAX_SEQ_LEN = 512
DEFAULT_PRE_PROMPT = PRE_PROMPTdef setup_session_state():
st.session_state.setdefault('chat_dialogue', [])
selected_model = st.sidebar.selectbox(
'Alege un model LLaMA2:', list(LLaMA2_MODELS.keys()), key='model')
st.session_state.setdefault(
'llm', LLaMA2_MODELS.get(selected_model, LLaMA2_70B_ENDPOINT))
st.session_state.setdefault('temperature', DEFAULT_TEMPERATURE)
st.session_state.setdefault('top_p', DEFAULT_TOP_P)
st.session_state.setdefault('max_seq_len', DEFAULT_MAX_SEQ_LEN)
st.session_state.setdefault('pre_prompt', DEFAULT_PRE_PROMPT)
Această funcție stabilește variabilele esențiale, cum ar fi chat_dialogue, pre_prompt, llm, top_p, max_seq_len și temperature în starea sesiunii. De asemenea, se ocupă de selectarea modelului Llama 2 în funcție de alegerea utilizatorului.
Scrieți o funcție pentru a afișa conținutul barei laterale a aplicației Streamlit:
def render_sidebar():
st.sidebar.header("Chatbot LLaMA2")
st.session_state['temperature'] = st.sidebar.slider('Temperatura:',
min_value=0.01, max_value=5.0, value=DEFAULT_TEMPERATURE, step=0.01)
st.session_state['top_p'] = st.sidebar.slider('Top P:', min_value=0.01,
max_value=1.0, value=DEFAULT_TOP_P, step=0.01)
st.session_state['max_seq_len'] = st.sidebar.slider('Lungimea maximă a secvenței:',
min_value=64, max_value=4096, value=DEFAULT_MAX_SEQ_LEN, step=8)
new_prompt = st.sidebar.text_area(
'Prompt înainte de începerea chat-ului. Editați aici, dacă doriți:',
DEFAULT_PRE_PROMPT,height=60)
if new_prompt != DEFAULT_PRE_PROMPT and new_prompt != "" and
new_prompt is not None:
st.session_state['pre_prompt'] = new_prompt + "\n"
else:
st.session_state['pre_prompt'] = DEFAULT_PRE_PROMPT
Funcția afișează antetul și variabilele de configurare ale chatbot-ului Llama 2 pentru ajustări.
Scrieți funcția care redă istoricul chatului în zona principală a aplicației Streamlit:
def render_chat_history():
response_container = st.container()
for message in st.session_state.chat_dialogue:
with st.chat_message(message["role"]):
st.markdown(message["content"])
Funcția parcurge istoria chat-ului stocată în starea sesiunii, afișând fiecare mesaj cu rolul specificat (utilizator sau asistent).
Gestionați introducerea utilizatorului prin următoarea funcție:
def handle_user_input():
user_input = st.chat_input(
"Introduceți aici întrebarea dumneavoastră pentru a vorbi cu LLaMA2"
)
if user_input:
st.session_state.chat_dialogue.append(
{"role": "user", "content": user_input}
)
with st.chat_message("user"):
st.markdown(user_input)
Această funcție prezintă utilizatorului un câmp de introducere unde acesta poate trimite mesaje și întrebări. Mesajul este adăugat la chat_dialogue în starea sesiunii cu rolul de utilizator, după trimitere.
Scrieți o funcție care generează răspunsuri de la modelul Llama 2 și le afișează în zona de chat:
def generate_assistant_response():
message_placeholder = st.empty()
full_response = ""
string_dialogue = st.session_state['pre_prompt']
for dict_message in st.session_state.chat_dialogue:
speaker = "Utilizator" if dict_message["role"] == "user" else "Asistent"
string_dialogue += f"{speaker}: {dict_message['content']}\n"
output = debounce_replicate_run(
st.session_state['llm'],
string_dialogue + "Asistent: ",
st.session_state['max_seq_len'],
st.session_state['temperature'],
st.session_state['top_p'],
REPLICATE_API_TOKEN
)
for item in output:
full_response += item
message_placeholder.markdown(full_response + "▌")
message_placeholder.markdown(full_response)
st.session_state.chat_dialogue.append({"role": "assistant",
"content": full_response})
Această funcție creează un șir de istoric de conversație ce include atât mesajele utilizatorului, cât și cele ale asistentului, înainte de a apela funcția debounce_replicate_run pentru a obține răspunsul asistentului. Actualizează constant răspunsul în interfața de utilizare, oferind o experiență de chat în timp real.
Scrieți funcția principală responsabilă pentru afișarea întregii aplicații Streamlit:
def render_app():
setup_session_state()
render_sidebar()
render_chat_history()
handle_user_input()
generate_assistant_response()
Aceasta apelează toate funcțiile definite, configurând starea sesiunii, afișând bara laterală și istoricul chatului, gestionând introducerea utilizatorului și generând răspunsurile asistentului, într-o ordine logică.
Scrieți o funcție pentru a invoca funcția render_app și pentru a porni aplicația la rularea scriptului:
def main():
render_app()if __name__ == "__main__":
main()
Aplicația ar trebui să fie acum pregătită pentru execuție.
Gestionarea cererilor API
Creați un fișier utils.py în directorul proiectului și adăugați următoarea funcție:
import replicate
import time
last_call_time = 0
debounce_interval = 2def debounce_replicate_run(llm, prompt, max_len, temperature, top_p,
API_TOKEN):
global last_call_time
print("Ultima oră apel: ", last_call_time)current_time = time.time()
elapsed_time = current_time - last_call_timeif elapsed_time < debounce_interval:
print("Amânare")
return "Salut! Cererile dumneavoastră sunt prea rapide. Vă rugăm să așteptați câteva " \
" secunde înainte de a trimite o altă cerere."last_call_time = time.time()
output = replicate.run(llm, input={"prompt": prompt + "Asistent: ",
"max_length": max_len, "temperature":
temperature, "top_p": top_p,
"repetition_penalty": 1}, api_token=API_TOKEN)
return output
Această funcție implementează un mecanism de amânare pentru a preveni interogările API frecvente și excesive de la introducerea unui utilizator.
Apoi, importați funcția de răspuns la amânare în fișierul llama_chatbot.py, astfel:
from utils import debounce_replicate_run
Acum, rulați aplicația:
streamlit run llama_chatbot.py
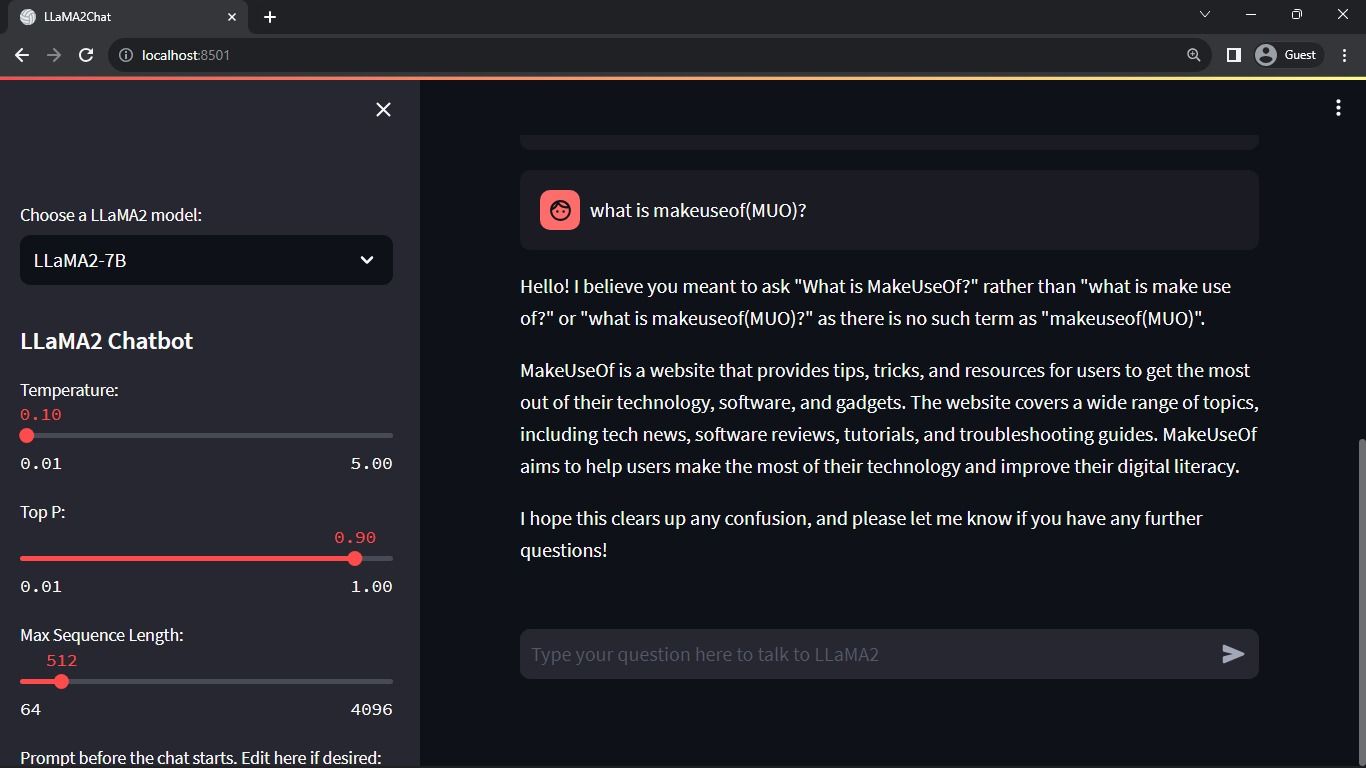
Rezultat așteptat:
Rezultatul va afișa o conversație între model și un utilizator uman.
Aplicații practice ale chatbot-urilor Streamlit și Llama 2
Câteva exemple de aplicații Llama 2 din lumea reală includ:
- Chatboți: Utilitatea sa se extinde la crearea de chatbot-uri cu răspunsuri similare cu cele umane, capabile să susțină conversații în timp real pe o varietate de subiecte.
- Asistenți virtuali: Se poate folosi pentru dezvoltarea asistenților virtuali care înțeleg și răspund la întrebările formulate în limbaj natural.
- Traducerea limbilor: Poate fi aplicată în sarcini de traducere lingvistică.
- Sumarizarea textelor: Eficient în sumarizarea textelor lungi, facilitând înțelegerea rapidă a informațiilor principale.
- Cercetare: Llama 2 poate fi utilizat în scopuri de cercetare, răspunzând la întrebări pe o gamă largă de subiecte.
Viitorul inteligenței artificiale
În contextul modelelor închise precum GPT-3.5 și GPT-4, dezvoltarea de soluții semnificative folosind LLM-uri poate fi dificilă pentru companiile mici, din cauza costurilor ridicate asociate accesului la API-ul modelului GPT.
Deschiderea către comunitatea de dezvoltatori a modelelor lingvistice avansate precum Llama 2 marchează începutul unei noi ere în inteligența artificială. Aceasta va stimula o implementare mai creativă și inovatoare a modelelor în aplicații practice, accelerând competiția pentru obținerea unei Super Inteligențe Artificiale (ASI).