O matrice de confuzie reprezintă un instrument fundamental pentru aprecierea eficienței algoritmilor de învățare automată supravegheați, în special în sarcinile de clasificare.
Ce reprezintă o matrice de confuzie?
Percepția asupra realității variază de la individ la individ, inclusiv în distincția dintre adevăr și eroare. Un segment de 10 cm poate fi interpretat ca având 9 cm de către o altă persoană, iar valoarea sa reală poate fi diferită de ambele măsurători. Această variație evidențiază diferența dintre valoarea prezisă și valoarea reală.
Similar modului în care gândim noi, oamenii
Asemenea creierului uman, care aplică o logică proprie în procesul de predicție, mașinile utilizează algoritmi complecși (cunoscuți sub denumirea de algoritmi de învățare automată) pentru a determina o valoare predictivă. Aceste valori pot corespunde sau nu valorii reale.
Într-un mediu competitiv, este esențial să cunoaștem acuratețea predicțiilor noastre. La fel, putem evalua performanța unui algoritm de învățare automată în funcție de corectitudinea predicțiilor sale.
Dar ce este un algoritm de învățare automată?
Mașinile utilizează algoritmi de învățare automată, un set de instrucțiuni logice, pentru a rezolva probleme și a ajunge la răspunsuri. Algoritmii de învățare automată se împart în trei categorii principale: supravegheați, nesupravegheați și cu întărire.
Tipuri de algoritmi de învățare automată
Algoritmii supravegheați sunt cei mai simpli, în cadrul cărora cunoaștem rezultatul dorit și antrenăm mașinile să atingă acel rezultat prin expunerea la o cantitate mare de date. Un exemplu este un copil care învață să deosebească oamenii de vârste diferite prin observarea repetată a trăsăturilor lor.
Algoritmii ML supravegheați se împart în două categorii: clasificare și regresie.
Algoritmii de clasificare organizează datele pe baza unor criterii prestabilite. De exemplu, pentru a grupa clienții în funcție de preferințele alimentare (cei cărora le place pizza și cei cărora nu le place), se folosesc algoritmi de clasificare precum arborele decizional, pădurea aleatoare, Bayes naiv sau SVM (Support Vector Machine).
Care dintre acești algoritmi este cel mai eficient? De ce am alege un algoritm în detrimentul altuia?
Aici intervine matricea de confuzie…
Matricea de confuzie este un tabel ce oferă informații despre precizia unui algoritm de clasificare în procesul de categorizare a datelor. Deși numele poate induce confuzie, un număr ridicat de predicții incorecte semnalează că algoritmul a fost probabil confuz 😉!
Așadar, matricea de confuzie este un instrument pentru evaluarea eficienței unui algoritm de clasificare.
Cum funcționează?
Să presupunem că ați testat diferiți algoritmi pe problema binară de clasificare: clasificarea persoanelor în funcție de preferința pentru pizza. Pentru a determina algoritmul care generează cele mai precise rezultate, se utilizează matricea de confuzie. Într-o problemă de clasificare binară (like/dislike, true/false, 1/0), matricea de confuzie prezintă patru valori:
- Adevărat pozitiv (TP)
- Adevărat negativ (TN)
- Fals pozitiv (FP)
- Fals negativ (FN)
Care sunt cele patru componente ale unei matrice de confuzie?
Cele patru valori obținute prin matricea de confuzie constituie componentele matricei.
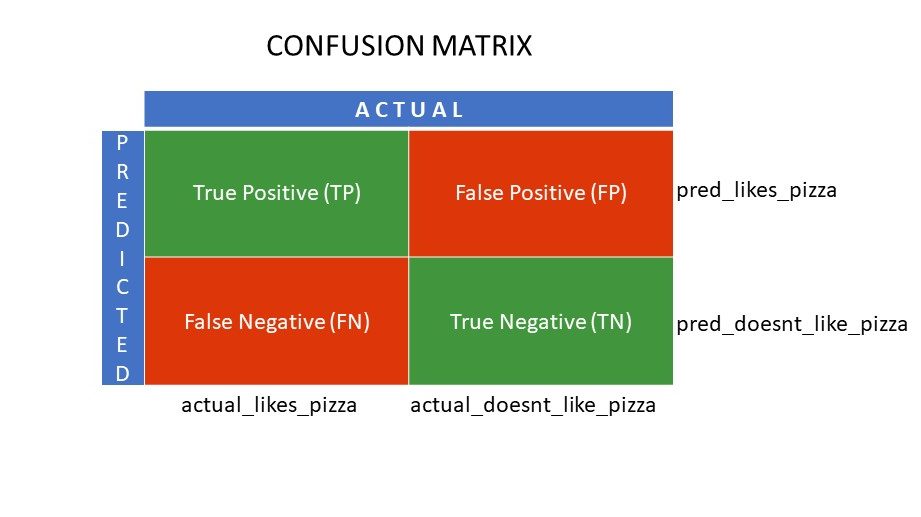 Componentele matricei de confuzie
Componentele matricei de confuzie
True Positive (TP) și True Negative (TN) sunt valorile corect prezise de algoritmul de clasificare,
- TP reprezintă persoanele cărora le place pizza și pe care modelul le-a clasificat corect,
- TN reprezintă persoanele cărora nu le place pizza și pe care modelul le-a clasificat corect,
Fals pozitiv (FP) și fals negativ (FN) sunt valorile prezise incorect de clasificator,
- FP reprezintă persoanele cărora nu le place pizza (negativ), dar clasificatorul a prezis că le place pizza (fals pozitiv). FP este denumită și eroare de tip I.
- FN reprezintă persoanele cărora le place pizza (pozitiv), dar clasificatorul a prezis că nu le place (fals negativ). FN este denumită și eroare de tip II.
Pentru o mai bună înțelegere, vom analiza un scenariu real.
Să presupunem că avem un set de date cu 400 de persoane care au fost testate pentru COVID. Acum avem rezultatele diferiților algoritmi care au estimat numărul de persoane pozitive și negative la COVID.
Iată două matrice de confuzie pentru comparație:
La prima vedere, se poate crede că primul algoritm este mai precis. Însă, pentru o evaluare concretă, avem nevoie de valori care măsoară acuratețea, precizia și alte metrici pentru a determina care algoritm este mai performant.
Metrici derivate din matricea de confuzie și importanța lor
Metricile cheie care ne ajută să evaluăm performanța clasificatorului sunt:
#1. Rechemare/Sensibilitate
Rechemarea, sensibilitatea, rata de pozitivitate reală (TPR) sau probabilitatea de detectare este raportul dintre predicțiile pozitive corecte (TP) și totalul rezultatelor pozitive (TP + FN).
R = TP/(TP + FN)
Rechemarea măsoară proporția rezultatelor pozitive corecte identificate din numărul total de rezultate pozitive posibile. O valoare mare a rechemării indică un număr redus de falsuri negative, ceea ce este de dorit. Rechemarea este utilă atunci când este critic să se reducă erorile de fals negativ. De exemplu, dacă modelul indică un pacient cu multiple blocaje cardiace ca fiind sănătos, consecințele ar putea fi grave.
#2. Precizie
Precizia măsoară proporția rezultatelor pozitive corecte din totalul rezultatelor pozitive prezise, incluzând atât pozitivele reale, cât și cele false.
Pr = TP/(TP + FP)
Precizia este crucială atunci când erorile de fals pozitiv sunt inacceptabile. De exemplu, dacă un model indică eronat că o persoană are diabet, iar medicul prescrie tratament, pot apărea efecte secundare nedorite.
#3. Specificitate
Specificitatea, sau rata negativă adevărată (TNR), reprezintă proporția rezultatelor negative corecte din totalul rezultatelor negative posibile.
S = TN/(TN + FP)
Aceasta măsoară eficiența clasificatorului în identificarea corectă a valorilor negative.
#4. Acuratețe
Acuratețea indică numărul de predicții corecte din totalul predicțiilor efectuate. De exemplu, dacă dintr-un eșantion de 50 de observații, 20 sunt clasificate corect ca pozitive și 10 ca negative, acuratețea este de 30/50.
Acuratețe A = (TP + TN)/(TP + TN + FP + FN)
#5. Prevalența
Prevalența măsoară proporția rezultatelor pozitive din totalul observațiilor.
P = (TP + FN)/(TP + TN + FP + FN)
#6. Scor F
Compararea clasificatorilor folosind doar precizia și rechemarea, care sunt medii aritmetice, poate fi dificilă. În aceste situații, se folosește Scorul F sau F1, care este media armonică, mai precisă în gestionarea valorilor extreme. Un scor F mai mare (maxim 1) indică un model superior.
Scor F = 2 * Precizie * Rechemare / (Rechemare + Precizie)
Scorul F1 este important atunci când se dorește echilibrarea falselor pozitive și a falselor negative. De exemplu, persoanele care nu au Covid (dar modelul le indică) nu trebuie izolate, în timp ce persoanele pozitive (dar modelul le indică negativ) trebuie izolate.
#7. Curbele ROC
Acuratețea și precizia sunt utile dacă datele sunt echilibrate. Într-un set de date dezechilibrat, o precizie ridicată nu înseamnă neapărat un clasificator eficient. De exemplu, dacă 90 din 100 de elevi cunosc spaniola, chiar dacă algoritmul indică eronat că toți 100 cunosc limba, acuratețea va fi de 90%, oferind o imagine distorsionată. În aceste situații, curbele ROC sunt mai relevante.
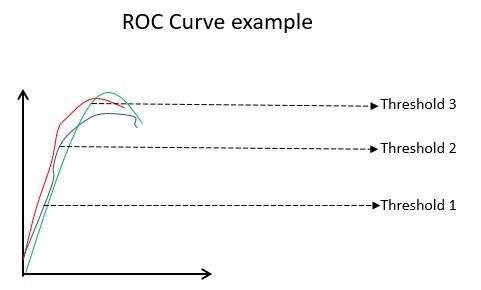 Exemplu de curbă ROC
Exemplu de curbă ROC
Curba ROC (Receiver Operating Characteristic) vizualizează performanța unui model de clasificare binară la praguri diferite. Reprezintă o diagramă a TPR (Rata de Pozitivitate Reală) în funcție de FPR (Rata de Fals Pozitiv), calculată ca (1 – Specificitate) la diferite praguri. Valoarea cea mai apropiată de 45 de grade (în stânga sus) este cea mai precisă. Dacă pragul este prea ridicat, vom avea puține falsuri pozitive, dar multe falsuri negative, și invers.
În general, atunci când se compară curbele ROC pentru diferite modele, modelul cu cea mai mare arie sub curba (AUC) este considerat superior.
Să calculăm valorile metrice pentru matricele de confuzie ale clasificatorilor I și II:
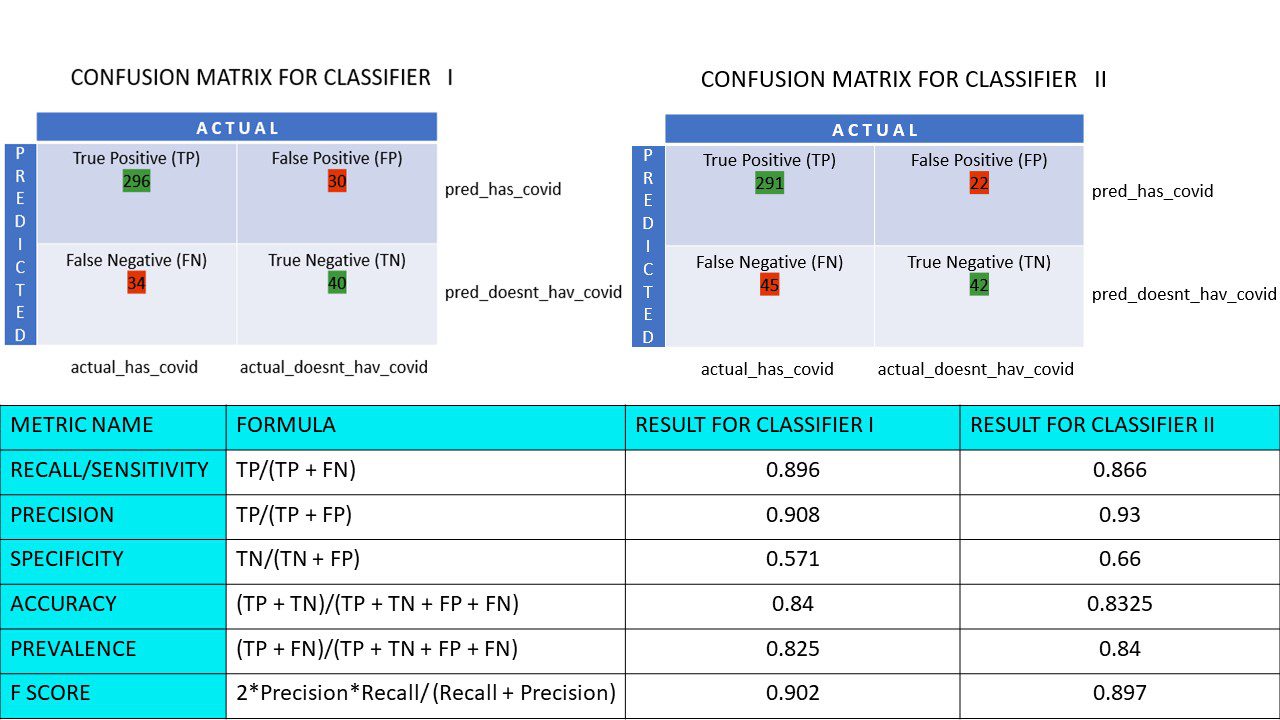 Comparație metrică pentru clasificatorii 1 și 2 din sondajul pizza
Comparație metrică pentru clasificatorii 1 și 2 din sondajul pizza
Observăm că precizia este mai mare la clasificatorul II, în timp ce acuratețea este ușor mai mare la clasificatorul I. Decizia între cei doi clasificatori depinde de problema specifică.
Matrice de confuzie N x N
Am analizat matricea de confuzie pentru clasificatori binari. Dacă am avea mai mult de două categorii, de exemplu, clasificarea imaginilor în culori roșu, verde și albastru? Acest tip de clasificare se numește multiclasă. Dimensiunea matricei de confuzie este determinată de numărul de variabile de ieșire, în acest caz, 3×3.
 Matrice de confuzie pentru un clasificator multiclasă
Matrice de confuzie pentru un clasificator multiclasă
Rezumat
Matricea de confuzie este un instrument excelent de evaluare, furnizând informații detaliate despre performanța algoritmilor de clasificare. Este utilă atât pentru clasificatoarele binare, cât și pentru cele multiclasă. Matricea de confuzie este ușor de vizualizat și permite calcularea altor metrici precum scorul F, precizia, ROC și acuratețea.
De asemenea, puteți explora metode de selectare a algoritmilor ML pentru probleme de regresie.