

Ești gata să înveți ingineria caracteristicilor pentru învățarea automată și știința datelor? Ești în locul potrivit!
Ingineria caracteristicilor este o abilitate esențială pentru extragerea de informații valoroase din date și, în acest ghid rapid, o voi împărți în bucăți simple și digerabile. Așadar, haideți să ne scufundăm și să începem călătoria dvs. către stăpânirea extragerii caracteristicilor!
Cuprins
Ce este ingineria caracteristicilor?

Când creați un model de învățare automată legat de o problemă de afaceri sau experimentală, furnizați date de învățare în coloane și rânduri. În domeniul științei datelor și dezvoltării ML, coloanele sunt cunoscute ca atribute sau variabile.
Datele granulare sau rândurile de sub aceste coloane sunt cunoscute sub denumirea de observații sau instanțe. Coloanele sau atributele sunt caracteristicile dintr-un set de date brute.
Aceste caracteristici brute nu sunt suficiente sau optime pentru a antrena un model ML. Pentru a reduce zgomotul metadatelor colectate și a maximiza semnalele unice de la caracteristici, trebuie să transformați sau să convertiți coloanele de metadate în caracteristici funcționale prin inginerie de caracteristici.
Exemplul 1: Modelare financiară
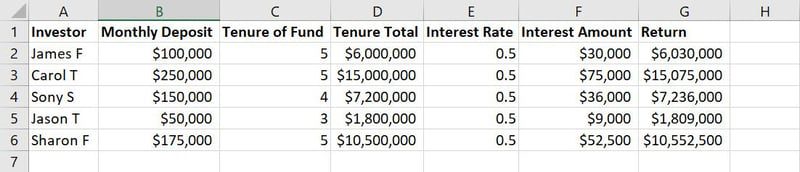 Date brute pentru antrenamentul modelului ML
Date brute pentru antrenamentul modelului ML
De exemplu, în imaginea de mai sus a unui exemplu de set de date, coloanele de la A la G sunt caracteristici. Valorile sau șirurile de text din fiecare coloană de-a lungul rândurilor, cum ar fi numele, suma depozitului, anii de depozit, ratele dobânzii etc., sunt observații.
În modelarea ML, trebuie să ștergeți, să adăugați, să combinați sau să transformați datele pentru a crea caracteristici semnificative și pentru a reduce dimensiunea bazei de date de formare a modelului general. Aceasta este ingineria caracteristicilor.
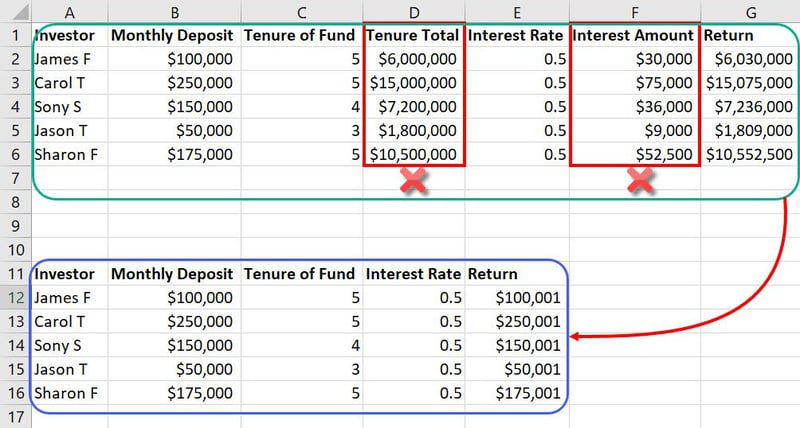 Exemplu de inginerie a caracteristicilor
Exemplu de inginerie a caracteristicilor
În același set de date menționat mai devreme, caracteristici precum Tenure Total și Interest Amount sunt intrări inutile. Acestea pur și simplu vor ocupa mai mult spațiu și vor încurca modelul ML. Deci, puteți reduce două caracteristici dintr-un total de șapte caracteristici.
Deoarece bazele de date din modelele ML conțin mii de coloane și milioane de rânduri, reducerea a două caracteristici afectează foarte mult proiectul.
Exemplul 2: AI Music Playlist Maker
Uneori, puteți crea o funcție complet nouă din mai multe funcții existente. Să presupunem că creați un model AI care va crea automat o listă de redare cu muzică și melodii în funcție de eveniment, gust, mod etc.
Acum, ați colectat date despre melodii și muzică din diverse surse și ați creat următoarea bază de date:
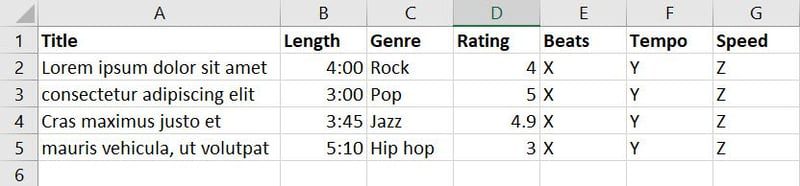
Există șapte caracteristici în baza de date de mai sus. Cu toate acestea, deoarece ținta dvs. este să antrenați modelul ML pentru a decide ce melodie sau muzică este potrivită pentru ce eveniment, puteți asocia funcții precum Gen, Rating, Beats, Tempo și Speed într-o nouă funcție numită Aplicabilitate.
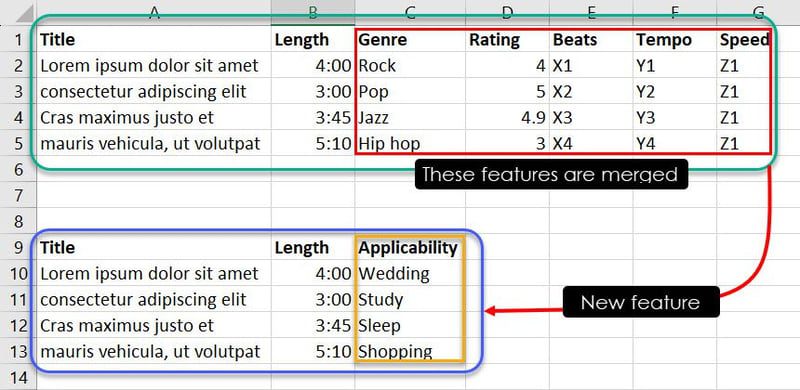
Acum, fie prin expertiză, fie prin identificarea modelelor, puteți combina anumite exemple de caracteristici pentru a determina ce melodie este potrivită pentru ce eveniment. De exemplu, observații precum Jazz, 4.9, X3, Y3 și Z1 spun modelului ML că melodia Cras maximus justo et ar trebui să fie în lista de redare a utilizatorului dacă caută o melodie pentru timpul somnului.
Tipuri de caracteristici în Machine Learning
Caracteristici categoriale
Acestea sunt atribute de date care reprezintă categorii sau etichete distincte. Trebuie să utilizați acest tip pentru a eticheta seturile de date calitative.
#1. Caracteristici categoriale ordinale
Caracteristicile ordinale au categorii cu o ordine semnificativă. De exemplu, nivelurile de educație precum Liceul, Licența, Masteratul etc., au o distincție clară în standarde, dar nu există diferențe cantitative.
#2. Caracteristici nominale categoriale
Caracteristicile nominale sunt categorii fără nicio ordine inerentă. Exemplele ar putea fi culorile, țările sau tipurile de animale. De asemenea, există doar diferențe calitative.
Caracteristici ale matricei
Acest tip de caracteristică reprezintă date organizate în matrice sau liste. Oamenii de știință de date și dezvoltatorii ML folosesc adesea funcțiile Array pentru a gestiona secvențe sau pentru a încorpora date categorice.
#1. Încorporarea caracteristicilor matricei
Încorporarea tablourilor convertește datele categorice în vectori denși. Este folosit în mod obișnuit în procesarea limbajului natural și sistemele de recomandare.
#2. Listează caracteristicile matricei
Matricele de liste stochează secvențe de date, cum ar fi liste de articole dintr-o ordine sau istoricul acțiunilor.
Caracteristici numerice
Aceste caracteristici de antrenament ML sunt folosite pentru a efectua operații matematice, deoarece aceste caracteristici reprezintă date cantitative.
#1. Caracteristici numerice de interval
Caracteristicile de interval au intervale consecvente între valori, dar nu există un adevărat punct zero, de exemplu, datele de monitorizare a temperaturii. Aici, zero înseamnă temperatură de îngheț, dar atributul este încă acolo.
#2. Caracteristici numerice ale raportului
Caracteristicile raportului au intervale consistente între valori și un adevărat punct zero. Exemplele includ vârsta, înălțimea și venitul.
Importanța ingineriei caracteristicilor în ML și știința datelor
În continuare, vom explora procesul pas cu pas al ingineriei caracteristicilor.
Caracteristică Procesul de inginerie pas cu pas

În continuare, vom discuta despre metodele de inginerie a caracteristicilor.
Metode de inginerie caracteristică
#1. Analiza componentelor principale (PCA)
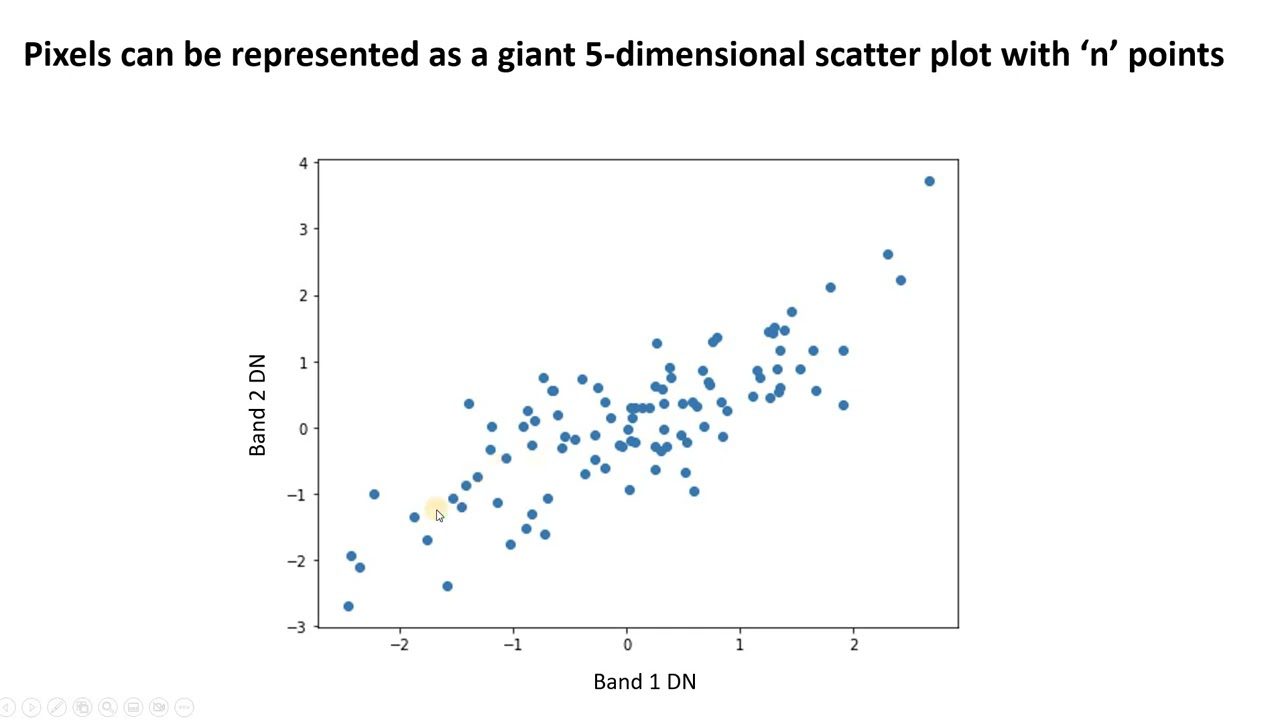
PCA simplifică datele complexe prin găsirea de noi caracteristici necorelate. Acestea se numesc componente principale. Îl puteți folosi pentru a reduce dimensionalitatea și a îmbunătăți performanța modelului.
#2. Caracteristici polinomiale
Crearea de caracteristici polinomiale înseamnă adăugarea puterilor caracteristicilor existente pentru a captura relații complexe în datele dvs. Vă ajută modelul să înțeleagă modelele neliniare.
#3. Manipularea Outliers
Valorile abere sunt puncte de date neobișnuite care pot afecta performanța modelelor dvs. Trebuie să identificați și să gestionați valorile aberante pentru a preveni rezultatele distorsionate.
#4. Transformare jurnal
Transformarea logaritmică vă poate ajuta să normalizați datele cu o distribuție anormală. Reduce impactul valorilor extreme pentru a face datele mai potrivite pentru modelare.
#5. t-Incorporare stocastică de vecinătate distribuită (t-SNE)
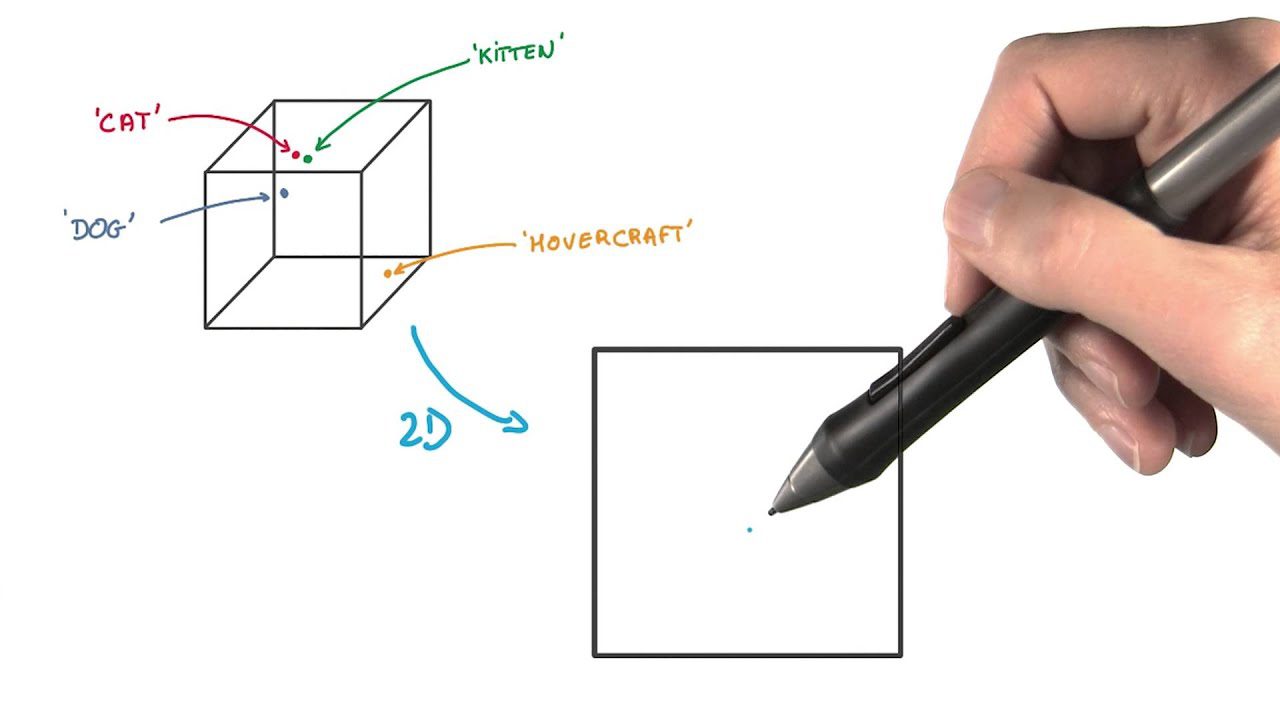
t-SNE este util pentru vizualizarea datelor cu dimensiuni mari. Reduce dimensionalitatea și face clusterele mai evidente, păstrând în același timp structura datelor.
În această metodă de extragere a caracteristicilor, reprezentați punctele de date ca puncte într-un spațiu de dimensiuni inferioare. Apoi, plasați punctele de date similare în spațiul original de dimensiuni înalte și sunt modelate pentru a fi aproape unul de celălalt în reprezentarea de dimensiuni inferioare.
Diferă de alte metode de reducere a dimensionalității prin păstrarea structurii și a distanțelor dintre punctele de date.
#6. Codificare One-Hot
Codificarea one-hot transformă variabilele categoriale în format binar (0 sau 1). Deci, obțineți noi coloane binare pentru fiecare categorie. Codificarea one-hot face ca datele categorice să fie potrivite pentru algoritmii ML.
#7. Codificarea numărului
Codificarea numărului înlocuiește valorile categorice cu numărul de ori când apar în setul de date. Poate capta informații valoroase din variabile categorice.
În această metodă de inginerie a caracteristicilor, utilizați frecvența sau numărarea fiecărei categorii ca o caracteristică numerică nouă, în loc să utilizați etichetele de categorie originale.
#8. Standardizare caracteristică

Caracteristicile valorilor mai mari domină adesea caracteristicile valorilor mici. Astfel, modelul ML poate fi ușor părtinitor. Standardizarea previne astfel de cauze de părtinire într-un model de învățare automată.
Procesul de standardizare implică de obicei următoarele două tehnici comune:
- Standardizare Z-Score: Această metodă transformă fiecare caracteristică astfel încât să aibă o medie (medie) de 0 și o abatere standard de 1. Aici, scădeți media caracteristicii din fiecare punct de date și împărțiți rezultatul la abaterea standard.
- Scalare min-max: scalarea min-max transformă datele într-un interval specific, de obicei între 0 și 1. Puteți realiza acest lucru scăzând valoarea minimă a caracteristicii din fiecare punct de date și împărțind la interval.
#9. Normalizare
Prin normalizare, caracteristicile numerice sunt scalate la un interval comun, de obicei între 0 și 1. Menține diferențele relative dintre valori și asigură că toate caracteristicile sunt pe condiții de concurență echitabile.

#1. Instrumente de caracteristici
Instrumente de caracteristici este un cadru Python open-source care creează automat caracteristici din seturi de date temporale și relaționale. Poate fi folosit cu instrumentele pe care le utilizați deja pentru a dezvolta conducte ML.
Soluția folosește Deep Feature Synthesis pentru a automatiza ingineria caracteristicilor. Are o bibliotecă de funcții de nivel scăzut pentru crearea de funcții. Featuretools are, de asemenea, un API, care este, de asemenea, ideal pentru gestionarea precisă a timpului.
#2. CatBoost
Dacă sunteți în căutarea unei biblioteci open-source care combină mai mulți arbori de decizie pentru a crea un model predictiv puternic, alegeți CatBoost. Această soluție oferă rezultate precise cu parametrii impliciti, astfel încât nu trebuie să petreceți ore întregi regland parametrii.
CatBoost vă permite, de asemenea, să utilizați factori non-numerici pentru a vă îmbunătăți rezultatele antrenamentului. Cu el, vă puteți aștepta, de asemenea, să obțineți rezultate mai precise și predicții rapide.
#3. Caracteristică-motor
Caracteristică-motor este o bibliotecă Python cu mai multe transformatoare și caracteristici selectate pe care le puteți utiliza pentru modelele ML. Transformatoarele pe care le include pot fi utilizate pentru transformarea variabilelor, crearea de variabile, caracteristici date și oră, preprocesare, codificare categorială, limitarea sau eliminarea valorii aberante și imputarea datelor lipsă. Este capabil să recunoască automat variabile numerice, categoriale și datetime.
Caracteristici Resurse de învățare pentru inginerie
Cursuri online și cursuri virtuale

#1. Inginerie de funcții pentru învățarea automată în Python: Datacamp
Acest Datacamp curs despre Ingineria caracteristicilor pentru învățarea automată în Python vă permite să creați noi funcții care vă îmbunătățesc performanța modelului de învățare automată. Vă va învăța să efectuați inginerie de caracteristici și colectare de date pentru a dezvolta aplicații ML sofisticate.
#2. Inginerie de funcții pentru învățarea automată: Udemy
De la Curs de Inginerie a caracteristicilor pentru învățare automatăveți învăța subiecte, inclusiv imputarea, codificarea variabilelor, extragerea de caracteristici, discretizarea, funcționalitatea dată și oră, valori aberante etc. Participanții vor învăța, de asemenea, să lucreze cu variabile distorsionate și să se ocupe de categorii rare, nevăzute și rare.
#3. Inginerie caracteristică: Pluralsight
Acest Vedere plurală calea de învățare are un total de șase cursuri. Aceste cursuri vă vor ajuta să învățați importanța ingineriei caracteristicilor în fluxul de lucru ML, modalități de a aplica tehnicile sale și extragerea caracteristicilor din text și imagini.
#4. Selectarea caracteristicilor pentru Machine Learning: Udemy
Cu ajutorul acestuia Udemy Desigur, participanții pot învăța metode de amestecare a funcțiilor, filtrare, wrapper și încorporate, eliminarea recursivă a caracteristicilor și căutarea exhaustivă. Se discută, de asemenea, tehnici de selecție a caracteristicilor, inclusiv cele cu Python, Lasso și arbori de decizie. Acest curs conține 5,5 ore de videoclipuri la cerere și 22 de articole.
#5. Inginerie de caracteristici pentru învățarea automată: învățare excelentă
Acest curs de la Învățare grozavă vă va prezenta ingineria caracteristicilor în timp ce vă va învăța despre supraeșantionare și subeșantionare. În plus, vă va permite să efectuați exerciții practice privind reglarea modelului.
#6. Inginerie caracteristică: Coursera
Alatura-te Coursera curs pentru a utiliza BigQuery ML, Keras și TensorFlow pentru a efectua ingineria caracteristicilor. Acest curs de nivel mediu acoperă, de asemenea, practici avansate de inginerie a caracteristicilor.
Cărți digitale sau cartonate

#1. Inginerie de caracteristici pentru învățarea automată
Această carte vă învață cum să transformați caracteristicile în formate pentru modele de învățare automată.
De asemenea, vă învață principiile ingineriei caracteristice și aplicarea practică prin exerciții.
#2. Inginerie și selecție a caracteristicilor
Citind această carte, veți învăța metodele de dezvoltare a modelelor predictive în diferite etape.
Din acesta, puteți învăța tehnici pentru a găsi cele mai bune reprezentări de predictori pentru modelare.
#3. Caracteristică Inginerie simplificată
Cartea este un ghid pentru îmbunătățirea puterii de predicție a algoritmilor ML.
Vă învață să proiectați și să creați funcții eficiente pentru aplicațiile bazate pe ML, oferind informații detaliate despre date.
#4. Feature Engineering Bookcamp
Această carte tratează studii de caz practice pentru a vă învăța tehnici de inginerie a caracteristicilor pentru rezultate ML mai bune și dispute de date îmbunătățite.
Citirea acestui lucru vă va asigura că puteți oferi rezultate îmbunătățite fără a pierde mult timp pentru reglarea fină a parametrilor ML.
#5. Arta ingineriei caracteristicilor
Resursa funcționează ca un element esențial pentru orice om de știință de date sau inginer de învățare automată.
Cartea folosește o abordare inter-domeniu pentru a discuta grafice, texte, serii cronologice, imagini și studii de caz.
Concluzie
Deci, acesta este modul în care puteți efectua ingineria caracteristicilor. Acum că cunoașteți definiția, procesul treptat, metodele și resursele de învățare, le puteți implementa în proiectele dvs. de ML și puteți vedea succesul!
În continuare, consultați articolul despre învățarea prin întărire.