Analiza Detaliată a Agregărilor în MongoDB
Pentru operațiunile de interogare complexe în MongoDB, mecanismul recomandat este conducta de agregare. Dacă în trecut ați folosit MapReduce, ar fi benefic să migrați la conducta de agregare, deoarece aceasta oferă performanțe superioare la calcule.
Ce Reprezintă Agregarea în MongoDB și Cum Funcționează?
Conducta de agregare reprezintă un proces structurat în mai multe faze, proiectat pentru a realiza interogări sofisticate în MongoDB. Aceasta procesează datele printr-o serie de etape, numite în mod colectiv „conductă”. Rezultatele obținute dintr-o etapă pot fi folosite ca bază pentru operațiile dintr-o altă etapă, facilitând un flux continuu de procesare.
De exemplu, rezultatele unei operațiuni de filtrare pot fi utilizate într-o etapă ulterioară pentru a sorta datele, conducând la obținerea rezultatului final dorit.
Fiecare etapă a conductei de agregare utilizează un operator specific MongoDB și generează unul sau mai multe documente transformate. În funcție de cerințele interogării, anumite etape pot fi repetate de mai multe ori în cadrul conductei. De pildă, operatorii $count sau $sort pot fi necesari în multiple etape.
Etapele Principale ale Conductei de Agregare
Conducta de agregare gestionează datele prin diverse etape în cadrul unei singure interogări. Există numeroase etape posibile, detaliile acestora fiind disponibile în Documentația Oficială MongoDB.
Vom analiza în detaliu câteva dintre cele mai frecvent utilizate etape:
Etapa $match
Această etapă permite specificarea unor condiții de filtrare precise, care sunt aplicate înainte de începerea altor etape de agregare. Astfel, se pot selecta datele relevante care vor fi procesate în continuare în cadrul conductei.
Etapa $group
Etapa de grupare organizează datele în grupuri distincte, bazate pe criterii definite, utilizând perechi cheie-valoare. Fiecare grup este reprezentat de o cheie în documentul de ieșire.
Considerăm exemplul unor date despre vânzări:
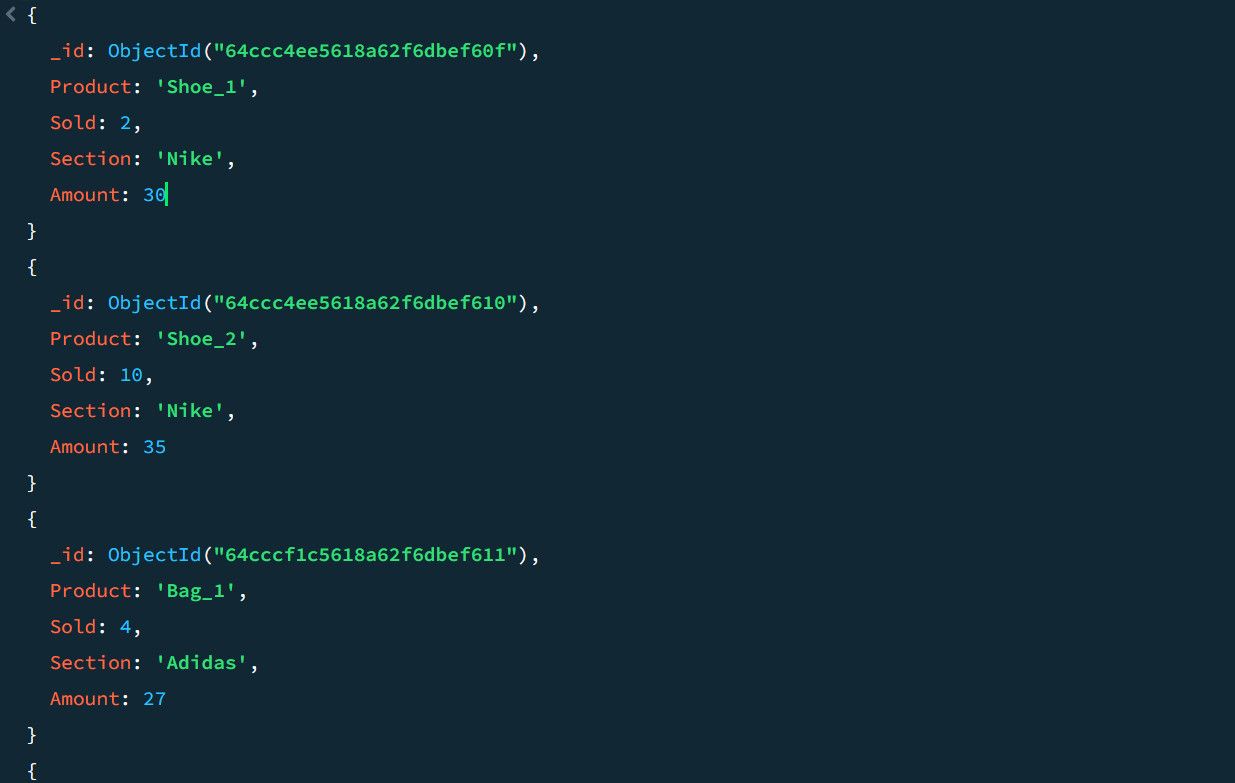
Prin intermediul conductei de agregare, putem calcula numărul total de vânzări și valoarea maximă a vânzărilor pentru fiecare categorie de produs:
{
$group: {
_id: $Section,
total_sales_count: {$sum : $Sold},
top_sales: {$max: $Amount},
}
}
Asocierea _id: $Section grupează documentele de ieșire pe baza secțiunilor. Prin specificarea câmpurilor total_sales_count și top_sales, MongoDB generează noi chei conform operațiunii de agregare definite, care poate fi $sum, $min, $max sau $avg.
Etapa $skip
Etapa $skip este folosită pentru a omite un număr specificat de documente în cadrul rezultatului. Este adesea utilizată după etapa de grupare. De exemplu, dacă rezultatul este preconizat să conțină două documente, iar etapa $skip este setată să omită unul, agregarea va produce doar al doilea document.
Pentru a utiliza etapa de omitere, se inserează operatorul $skip în conductă:
...,
{
$skip: 1
},
Etapa $sort
Etapa de sortare permite ordonarea datelor în ordine crescătoare sau descrescătoare. De exemplu, datele rezultate din interogarea anterioară pot fi sortate descrescător, pentru a identifica secțiunea cu cele mai mari vânzări.
Se adaugă operatorul $sort la interogarea precedentă:
...,
{
$sort: {top_sales: -1}
},
Etapa $limit
Operațiunea $limit reduce numărul de documente returnate de conductă. De exemplu, se poate utiliza $limit pentru a obține secțiunea cu cele mai mari vânzări, așa cum a fost identificată în etapa anterioară:
...,
{
$sort: {top_sales: -1}
},
{"$limit": 1}
Acest exemplu va returna doar primul document, reprezentând secțiunea cu cele mai mari vânzări, conform rezultatelor sortate.
Etapa $project
Etapa $project permite modelarea documentului de ieșire conform specificațiilor dorite. Utilizând operatorul $project, se pot selecta câmpurile incluse în rezultat și se pot personaliza denumirile cheilor.
Un exemplu de rezultat fără etapa $project arată astfel:
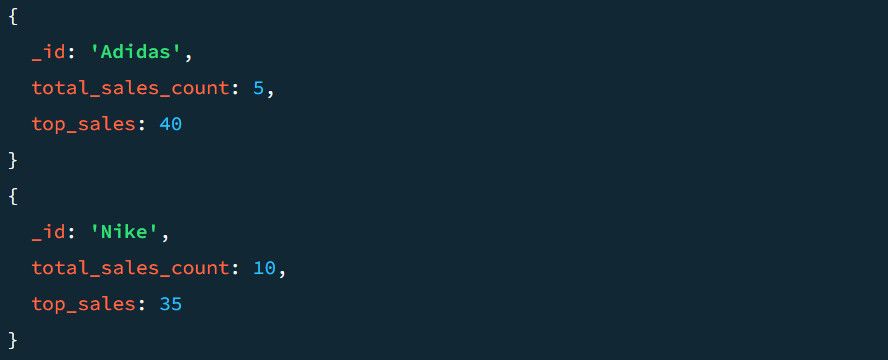
Să analizăm cum arată rezultatul cu etapa $project. Pentru a include $project în conductă:
...,
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",
}
}
Deoarece datele au fost grupate anterior pe baza secțiunilor de produse, exemplul de mai sus include fiecare secțiune în documentul de ieșire. De asemenea, se asigură că numărul total de vânzări și valoarea maximă a vânzărilor apar în rezultat sub denumirile TotalSold și TopSale.
Rezultatul final este mai structurat și mai ușor de înțeles:

Etapa $unwind
Etapa $unwind descompune un array dintr-un document în documente individuale. Considerăm următorul exemplu de date despre comenzi:
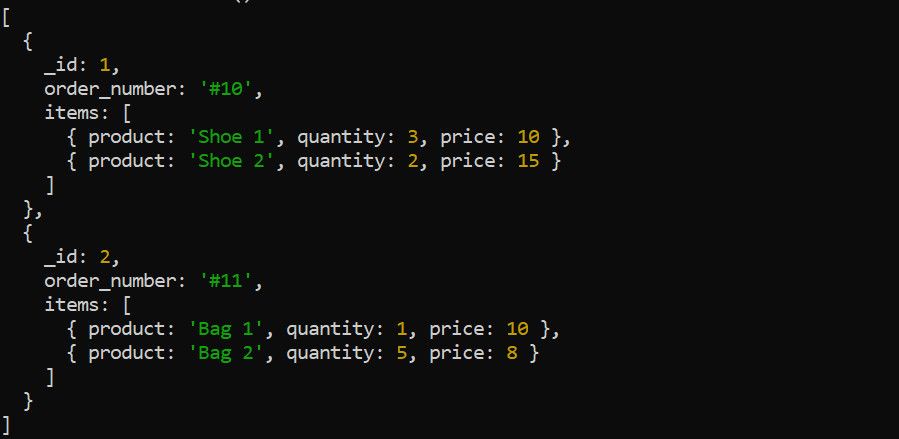
Se folosește etapa $unwind pentru a descompune array-ul de articole înainte de aplicarea altor etape de agregare. De exemplu, descompunerea array-ului de articole este utilă dacă se dorește calculul venitului total pentru fiecare produs:
db.Orders.aggregate(
[
{
"$unwind": "$items"
},
{
"$group": {
"_id": "$items.product",
"total_revenue": { "$sum": { "$multiply": ["$items.quantity", "$items.price"] } }
}
},
{
"$sort": { "total_revenue": -1 }
},
{
"$project": {
"_id": 0,
"Product": "$_id",
"TotalRevenue": "$total_revenue",
}
}
])
Rezultatul interogării de agregare de mai sus este:

Crearea unei Conducte de Agregare în MongoDB
Deși o conductă de agregare implică multiple operații, etapele prezentate anterior oferă o înțelegere a modului de aplicare a acestora, incluzând interogările de bază pentru fiecare etapă.
Folosind datele de vânzări prezentate anterior, vom combina câteva dintre etapele discutate, pentru a obține o imagine de ansamblu a conductei de agregare:
db.sales.aggregate([
{
"$match": {
"Sold": { "$gte": 5 }
}
},
{
"$group": {
"_id": "$Section",
"total_sales_count": { "$sum": "$Sold" },
"top_sales": { "$max": "$Amount" },
}
},
{
"$sort": { "top_sales": -1 }
},
{"$skip": 0},
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",
}
}
])
Rezultatul final este similar cu cel observat anterior:
Comparație între Conducta de Agregare și MapReduce
Înainte de deprecierea sa, începând cu MongoDB 5.0, metoda principală de agregare a datelor în MongoDB era MapReduce. Deși MapReduce are aplicații mai largi în afara MongoDB, este mai puțin eficientă decât conducta de agregare. În plus, necesită scripturi suplimentare pentru a implementa funcțiile de mapare și reducere separat.
Conducta de agregare este specifică MongoDB, dar oferă o modalitate mai elegantă și mai performantă de a realiza interogări complexe. Pe lângă simplificarea și scalabilitatea interogărilor, etapele oferă rezultate mai personalizabile.
Există multe alte diferențe între conducta de agregare și MapReduce, care vor fi observate pe măsură ce se face tranziția de la MapReduce la conducta de agregare.
Optimizarea Interogărilor pentru Date Mari în MongoDB
Pentru a efectua calcule detaliate pe seturi complexe de date în MongoDB, interogările trebuie să fie cât mai eficiente. Conducta de agregare este ideală pentru interogări avansate. În loc de a manipula datele în operațiuni separate, ceea ce reduce adesea performanța, agregarea permite gruparea tuturor operațiunilor într-o singură conductă performantă, executată o singură dată.
Deși conducta de agregare este mai eficientă decât MapReduce, performanța agregării poate fi îmbunătățită prin indexarea datelor. Aceasta reduce cantitatea de date pe care MongoDB trebuie să o analizeze în timpul fiecărei etape de agregare.