În prezent, datele joacă un rol crucial în dezvoltarea modelelor de învățare automată, testarea aplicațiilor și extragerea informațiilor valoroase pentru afaceri.
Cu toate acestea, respectarea reglementărilor stricte privind datele impune adesea o securizare și protecție sporită a acestora. Obținerea accesului la astfel de date poate necesita luni de așteptare pentru aprobările necesare. Ca alternativă eficientă, companiile pot opta pentru utilizarea datelor sintetice.
Ce sunt datele sintetice?
Imagine: Twinify
Datele sintetice reprezintă date create artificial, care prezintă similarități statistice cu seturile de date reale. Acestea pot fi utilizate împreună cu datele reale pentru a consolida și perfecționa modelele de inteligență artificială (IA), sau pot servi ca un substitut complet.
Deoarece nu sunt asociate cu nicio persoană identificabilă și nu includ informații personale sau sensibile, cum ar fi numerele de identificare personală, datele sintetice reprezintă o alternativă care protejează confidențialitatea în comparație cu datele reale de producție.
Diferențele dintre datele reale și cele sintetice
- Cea mai importantă distincție constă în modul de generare a celor două tipuri de date. Datele reale sunt obținute de la subiecți reali, ale căror informații au fost colectate prin sondaje sau în timpul utilizării aplicației. În contrast, datele sintetice sunt generate artificial, menținând totuși similarități cu setul de date inițial.
- O altă diferență esențială se referă la reglementările privind protecția datelor. În cazul datelor reale, subiecții trebuie să fie informați cu privire la datele colectate și scopul colectării, existând restricții privind modul în care acestea pot fi utilizate. În schimb, reglementările respective nu se aplică datelor sintetice, deoarece acestea nu pot fi atribuite unei persoane și nu conțin informații personale.
- A treia diferență se referă la cantitatea de date disponibilă. În cazul datelor reale, cantitatea este limitată la ceea ce oferă utilizatorii, în timp ce datele sintetice pot fi generate în cantități nelimitate.
De ce să luați în considerare utilizarea datelor sintetice
- Producția este relativ mai puțin costisitoare, deoarece se pot crea seturi de date extinse, similare cu cele existente, dar mai mici. Acest aspect îmbunătățește cantitatea de date disponibile pentru instruirea modelelor de învățare automată.
- Datele generate sunt automat etichetate și curățate, eliminând necesitatea alocării timpului pentru pregătirea lor în vederea învățării automate sau analizei.
- Nu există probleme de confidențialitate, deoarece datele nu sunt identificabile personal și nu aparțin unei persoane reale, permițând utilizarea și partajarea lor liberă.
- Se poate depăși părtinirea inteligenței artificiale, asigurând o reprezentare adecvată a claselor minoritare, ceea ce contribuie la crearea unei inteligențe artificiale corecte și responsabile.
Cum se generează date sintetice
Deși procesul variază în funcție de instrumentul utilizat, în general, se începe prin conectarea unui generator la un set de date existent. Apoi, se identifică câmpurile care conțin informații personale și se etichetează pentru excludere sau anonimizare.
Generatorul începe să identifice tipurile de date ale coloanelor rămase și modelele statistice. Apoi, se pot genera date sintetice în funcție de necesități.
Ulterior, se pot compara datele generate cu setul original pentru a evalua cât de bine se potrivesc datele sintetice cu cele reale.
În continuare, vom explora instrumentele disponibile pentru generarea de date sintetice destinate instruirii modelelor de învățare automată.
Mostly AI
Mostly AI oferă un generator de date sintetice bazat pe inteligență artificială, care învață modelele statistice ale setului de date original. Ulterior, generatorul creează personaje fictive, care respectă modelele învățate.
Cu Mostly AI, se pot genera baze de date complete cu integritate referențială, sintetizând diverse tipuri de date pentru a sprijini crearea unor modele de inteligență artificială mai performante.
Synthesized.io

Synthesized.io este utilizat de companii de top în cadrul inițiativelor lor de inteligență artificială. Pentru a utiliza această platformă, este necesară specificarea cerințelor de date într-un fișier de configurare YAML.
Ulterior, se creează un task, care este executat ca parte a unui pipeline de date. Synthesized.io oferă și o versiune gratuită generoasă, care permite experimentarea și evaluarea adecvării platformei pentru nevoile individuale.
YData

Cu YData, se pot genera date tabulare, serii temporale, tranzacționale, multi-tabel și relaționale, evitând dificultățile asociate cu colectarea, partajarea și calitatea datelor.
Platforma include o inteligență artificială și un SDK care permite interacțiunea cu serviciile sale. YData oferă și un nivel gratuit generos, disponibil pentru demonstrarea produsului.
Gretel AI

Gretel AI furnizează API-uri pentru generarea unei cantități nelimitate de date sintetice. Platforma dispune de un generator de date open-source, care poate fi instalat și utilizat.
Alternativ, se poate utiliza API-ul sau CLI-ul REST, care implică costuri. Prețurile sunt rezonabile și se adaptează la dimensiunea afacerii.
Copule
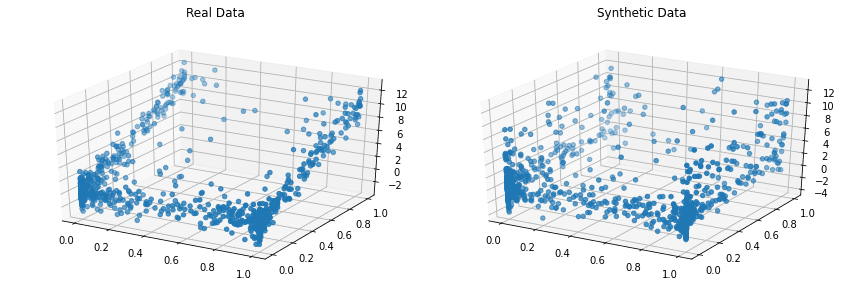
Copulas este o bibliotecă Python open-source pentru modelarea distribuțiilor multivariate prin utilizarea funcțiilor copula și generarea de date sintetice care respectă aceleași proprietăți statistice.
Proiectul a fost inițiat în 2018 la MIT, ca parte a proiectului Synthetic Data Vault.
CTGAN
CTGAN este format din generatoare care pot învăța modele din date reale dintr-un singur tabel și genera date sintetice conform modelelor identificate.
Acesta este implementat ca o bibliotecă Python open-source. CTGAN, împreună cu Copulas, face parte din Proiectul Synthetic Data Vault.
Doppelganger
DoppelGANger este o implementare open-source a rețelelor generative adversariale (GAN) pentru generarea de date sintetice.
DoppelGANger este util pentru generarea de date de tip serie temporală și este utilizat de companii precum Gretel AI. Biblioteca Python este disponibilă gratuit și este open-source.
Synth

Synth este un generator de date open-source care ajută la crearea de date realiste conform specificațiilor, la anonimizarea informațiilor personale și la dezvoltarea de date de testare pentru aplicații.
Synth poate fi utilizat pentru a genera serii în timp real și date relaționale, conform necesităților de învățare automată. Synth este, de asemenea, agnostic față de bazele de date, putând fi folosit cu baze de date SQL și NoSQL.
SDV.dev
SDV este acronimul pentru Synthetic Data Vault. SDV.dev este un proiect software inițiat la MIT în 2016, care a creat diferite instrumente pentru generarea de date sintetice.
Aceste instrumente includ Copulas, CTGAN, DeepEcho și RDT, fiind implementate ca biblioteci Python open-source, ușor de utilizat.
Tofu
Tofu este o bibliotecă Python open-source pentru generarea de date sintetice bazate pe datele biobancii din Regatul Unit. Spre deosebire de instrumentele menționate anterior, care ajută la generarea oricărui tip de date pe baza setului de date existent, Tofu generează date similare doar cu cele ale biobancii.
UK Biobank este un studiu privind caracteristicile fenotipice și genotipice ale a 500.000 de adulți de vârstă mijlocie din Marea Britanie.
Twinify
Twinify este un pachet software utilizat ca bibliotecă sau instrument de linie de comandă pentru a dubla date sensibile prin crearea de date sintetice cu distribuții statistice identice.

Pentru a utiliza Twinify, se furnizează datele reale sub forma unui fișier CSV, iar software-ul învață din date pentru a crea un model care poate fi folosit pentru generarea de date sintetice. Este complet gratuit.
Datanamic
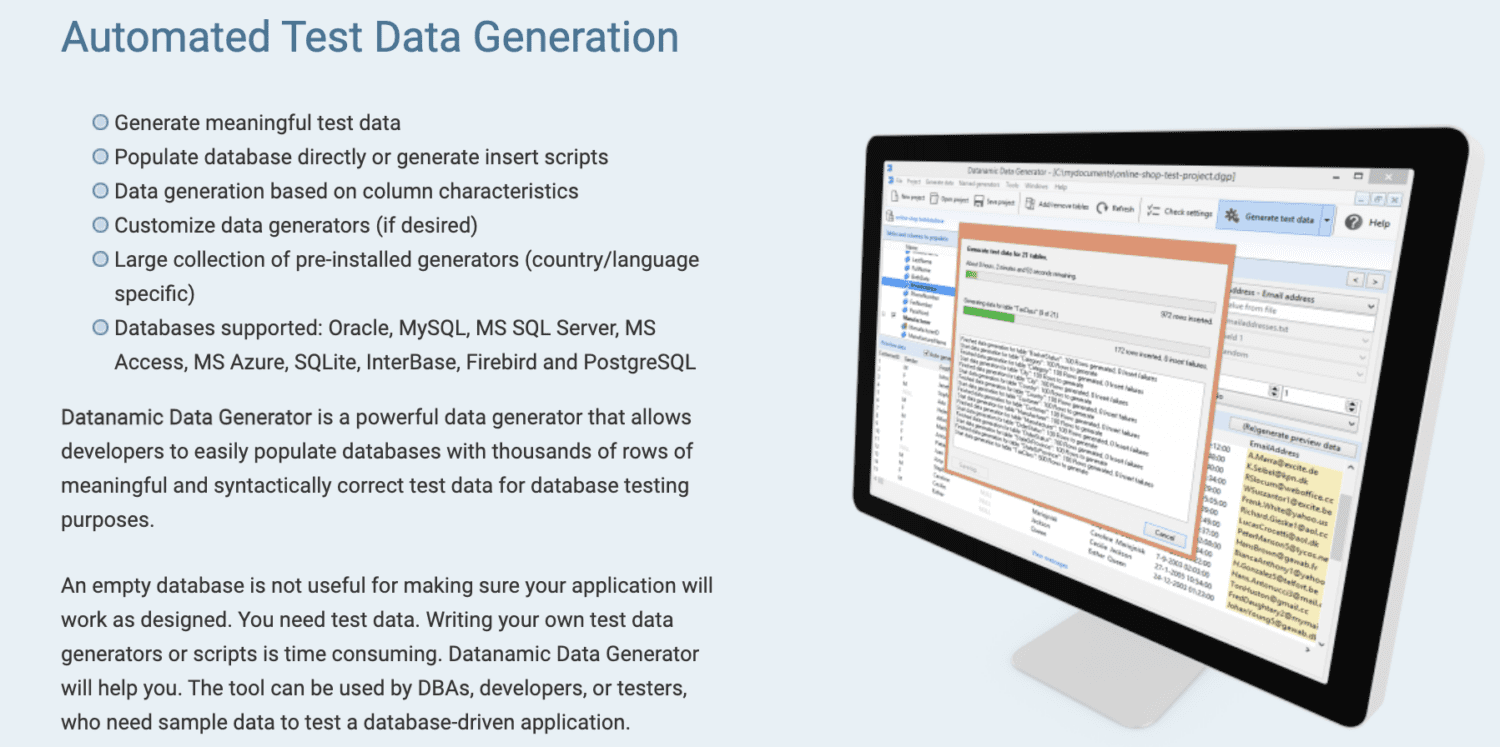
Datanamic ajută la crearea de date de testare pentru aplicații bazate pe date și de învățare automată. Instrumentul generează date conform caracteristicilor coloanei, cum ar fi adresele de e-mail, numele și numerele de telefon.
Generatoarele de date Datanamic sunt personalizabile și acceptă majoritatea bazelor de date, precum Oracle, MySQL, MySQL Server, MS Access și Postgres. Instrumentul susține și asigură integritatea referențială în datele generate.
Benerator
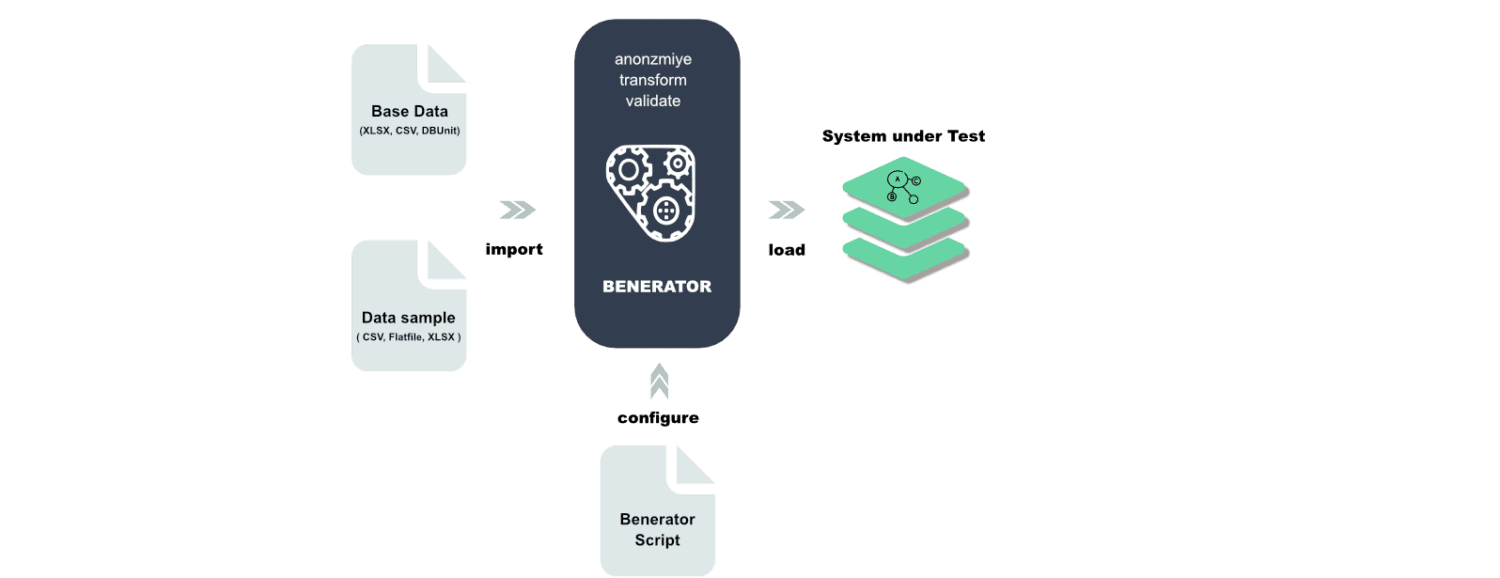
Benerator este un software pentru anonimizarea, generarea și migrarea datelor în scopuri de testare și instruire. Cu ajutorul Benerator, se descriu datele utilizând XML (Extensible Markup Language) și se generează folosind un instrument de linie de comandă.
Software-ul este conceput pentru a fi utilizabil și de către persoane fără cunoștințe de programare, putând genera miliarde de rânduri de date. Benerator este gratuit și open-source.
Concluzii
Gartner estimează că, până în 2030, datele sintetice vor fi folosite mai mult decât datele reale pentru învățarea automată.
Acest lucru nu este surprinzător, având în vedere costurile și problemele legate de confidențialitate care apar la utilizarea datelor reale. Prin urmare, este esențial ca întreprinderile să se informeze despre datele sintetice și diferitele instrumente disponibile pentru generarea lor.
Vă recomandăm să examinați instrumentele de monitorizare sintetică pentru afacerea dvs. online.