
Datele au devenit din ce în ce mai importante pentru construirea de modele de învățare automată, testarea aplicațiilor și elaborarea de informații despre afaceri.
Cu toate acestea, pentru a se conforma cu numeroasele reglementări privind datele, acesta este adesea boltit și protejat strict. Accesarea unor astfel de date ar putea dura luni pentru a obține aprobările necesare. Alternativ, companiile pot folosi date sintetice.
Cuprins
Ce sunt datele sintetice?
Credit foto: Twinify
Datele sintetice sunt date generate artificial care seamănă statistic cu vechiul set de date. Poate fi folosit cu date reale pentru a susține și îmbunătăți modelele AI sau poate fi folosit ca înlocuitor cu totul.
Deoarece nu aparține niciunei persoane vizate și nu conține informații de identificare personală sau date sensibile, cum ar fi numerele de securitate socială, poate fi folosit ca o alternativă de protecție a confidențialității la datele reale de producție.
Diferențele dintre datele reale și cele sintetice
- Cea mai importantă diferență este modul în care sunt generate cele două tipuri de date. Datele reale provin de la subiecți reali ale căror date au fost colectate în timpul sondajelor sau când au folosit aplicația dvs. Pe de altă parte, datele sintetice sunt generate artificial, dar seamănă totuși cu setul de date original.
- A doua diferență este în reglementările privind protecția datelor care afectează datele reale și sintetice. Cu date reale, subiecții ar trebui să poată ști ce date despre ei sunt colectate și de ce sunt colectate și există limite în ceea ce privește modul în care pot fi utilizate. Cu toate acestea, reglementările respective nu se mai aplică datelor sintetice, deoarece datele nu pot fi atribuite unui subiect și nu conțin informații personale.
- A treia diferență este în cantitățile de date disponibile. Cu date reale, puteți avea doar atât cât vă oferă utilizatorii. Pe de altă parte, puteți genera oricâte date sintetice doriți.
De ce ar trebui să luați în considerare utilizarea datelor sintetice
- Este relativ mai ieftin de produs, deoarece puteți genera seturi de date mult mai mari, asemănătoare cu setul de date mai mic pe care îl aveți deja. Aceasta înseamnă că modelele dvs. de învățare automată vor avea mai multe date cu care să se antreneze.
- Datele generate sunt etichetate și curățate automat pentru dvs. Aceasta înseamnă că nu trebuie să petreceți timp făcând munca consumatoare de timp de pregătire a datelor pentru învățarea automată sau analiză.
- Nu există probleme de confidențialitate, deoarece datele nu sunt de identificare personală și nu aparțin unei persoane vizate. Aceasta înseamnă că îl poți folosi și partaja liber.
- Puteți depăși părtinirea AI asigurându-vă că clasele minoritare sunt bine reprezentate. Acest lucru vă ajută să construiți o IA corectă și responsabilă.
Cum se generează date sintetice
În timp ce procesul de generare variază în funcție de instrumentul pe care îl utilizați, în general, procesul începe cu conectarea unui generator la un set de date existent. După care, apoi identificați câmpurile de identificare personală din setul dvs. de date și le etichetați pentru excludere sau înfundare.
Generatorul începe apoi să identifice tipurile de date ale coloanelor rămase și modelele statistice din acele coloane. De atunci, puteți genera oricâte date sintetice aveți nevoie.
De obicei, puteți compara datele generate cu setul de date original pentru a vedea cât de bine seamănă datele sintetice cu datele reale.
Acum, vom explora instrumentele pentru generarea de date sintetice pentru a antrena modele de învățare automată.
Mai ales AI
În cea mai mare parte, AI are un generator de date sintetice alimentat de AI care învață din modelele statistice ale setului de date original. AI generează apoi personaje fictive care se conformează tiparelor învățate.
Cu Mostly AI, puteți genera baze de date întregi cu integritate referențială. Puteți sintetiza tot felul de date pentru a vă ajuta să construiți modele AI mai bune.
Sintetizat.io

Synthesized.io este folosit de companiile de top pentru inițiativele lor AI. Pentru a utiliza synthesize.io, specificați cerințele de date într-un fișier de configurare YAML.
Apoi creați un job și îl rulați ca parte a unei conducte de date. De asemenea, are un nivel gratuit foarte generos care vă permite să experimentați și să vedeți dacă se potrivește nevoilor dvs. de date.
YData

Cu YData, puteți genera date tabulare, serii temporale, tranzacționale, multi-tabele și relaționale. Acest lucru vă permite să evitați problemele asociate cu colectarea, partajarea și calitatea datelor.
Vine cu un AI și un SDK de utilizat pentru a interacționa cu platforma lor. În plus, au un nivel generos gratuit pe care îl puteți folosi pentru a demonstra produsul.
Gretel AI

Gretel AI oferă API-uri pentru a genera cantități nelimitate de date sintetice. Gretel are un generator de date open-source pe care îl puteți instala și utiliza.
Alternativ, puteți folosi API-ul sau CLI-ul REST, care va avea un cost. Prețul lor este, totuși, rezonabil și se adaptează la dimensiunea afacerii.
Copule
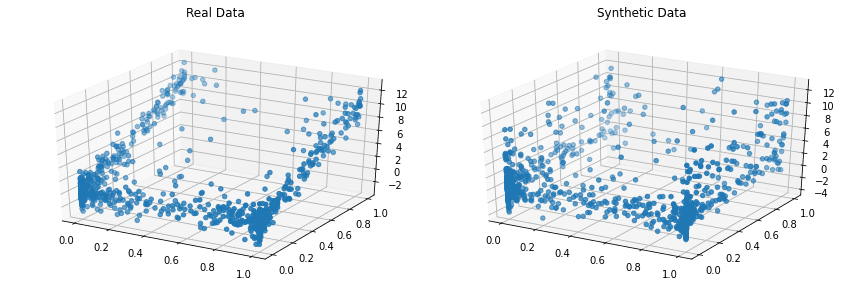
Copulas este o bibliotecă Python open-source pentru modelarea distribuțiilor multivariate folosind funcții copula și generarea de date sintetice care urmează aceleași proprietăți statistice.
Proiectul a început în 2018 la MIT, ca parte a proiectului Synthetic Data Vault.
CTGAN
CTGAN este format din generatoare care sunt capabile să învețe din date reale dintr-un singur tabel și să genereze date sintetice din tiparele identificate.
Este implementat ca o bibliotecă Python open-source. CTGAN, împreună cu Copulas, face parte din Proiectul Sintetic Data Vault.
Dublura
DoppelGANger este o implementare open-source a Generative Adversarial Networks pentru a genera date sintetice.
DoppelGANger este util pentru generarea de date în serie de timp și este utilizat de companii precum Gretel AI. Biblioteca Python este disponibilă gratuit și este open-source.
Sintetizator

Synth este un generator de date open-source care vă ajută să creați date realiste conform specificațiilor dvs., să ascundeți informații de identificare personală și să dezvoltați date de testare pentru aplicațiile dvs.
Puteți utiliza Synth pentru a genera serii în timp real și date relaționale pentru nevoile dvs. de învățare automată. Synth este, de asemenea, agnostic baza de date, astfel încât să îl puteți utiliza cu bazele de date SQL și NoSQL.
SDV.dev
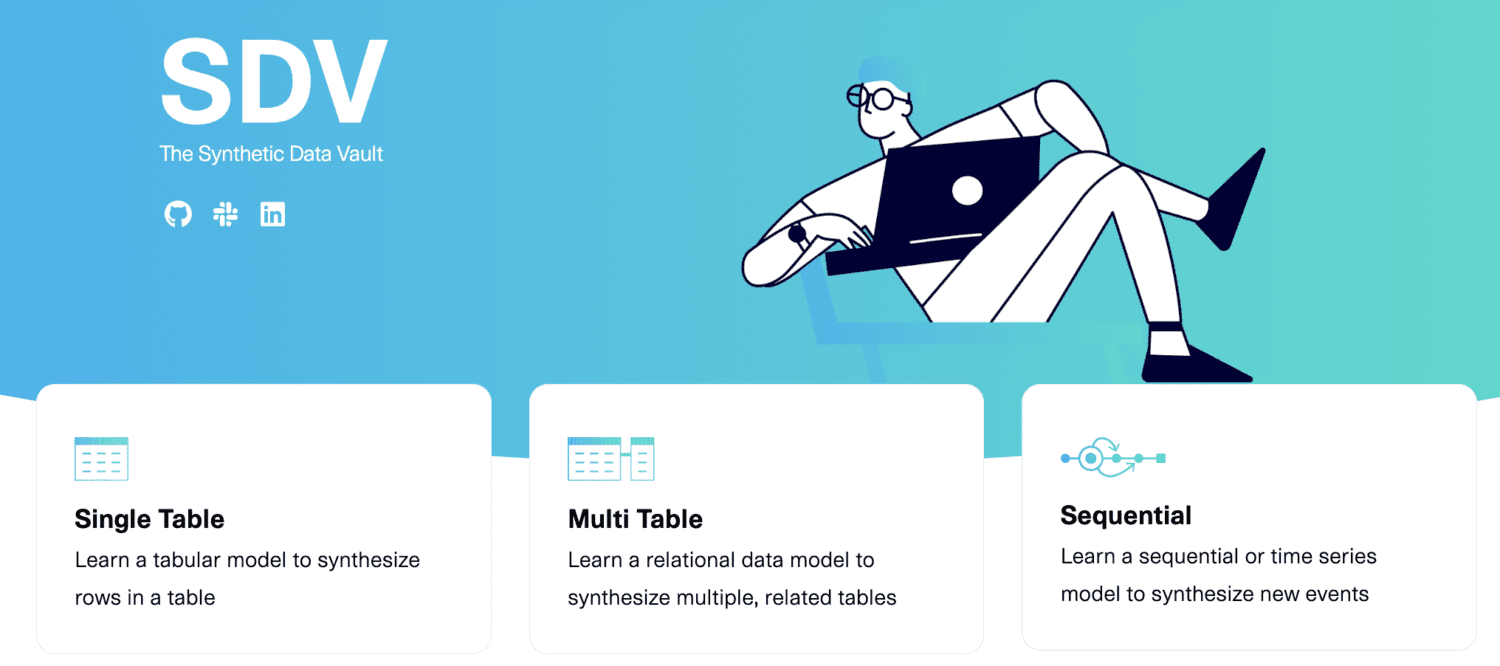
SDV înseamnă Sintetic Data Vault. SDV.dev este un proiect software care a început la MIT în 2016 și a creat diferite instrumente pentru generarea de date sintetice.
Aceste instrumente includ Copulas, CTGAN, DeepEcho și RDT. Aceste instrumente sunt implementate ca biblioteci Python open-source pe care le puteți utiliza cu ușurință.
Tofu
Tofu este o bibliotecă Python open-source pentru generarea de date sintetice bazate pe datele biobancii din Regatul Unit. Spre deosebire de instrumentele menționate anterior, care vă vor ajuta să generați orice tip de date pe baza setului de date existent, Tofu generează date care seamănă doar cu cele ale biobancii.
UK Biobank este un studiu privind caracteristicile fenotipice și genotipice ale a 500 000 de adulți de vârstă mijlocie din Marea Britanie.
Twinify
Twinify este un pachet software utilizat ca bibliotecă sau instrument de linie de comandă pentru a dubla date sensibile prin producerea de date sintetice cu distribuții statistice identice.

Pentru a utiliza Twinify, furnizați datele reale ca fișier CSV și acesta învață din date pentru a produce un model care poate fi folosit pentru a genera date sintetice. Este complet gratuit de utilizat.
Datanamic
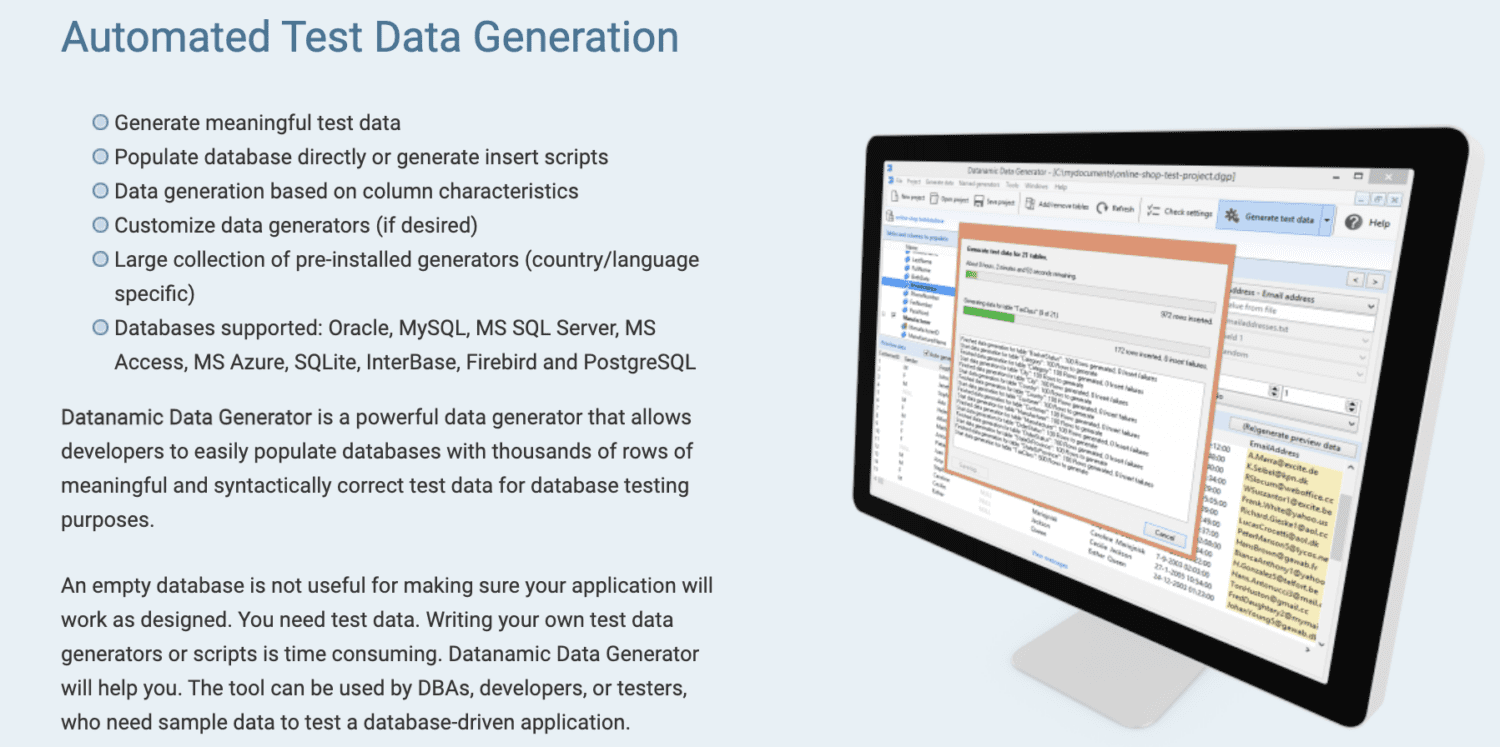
Datanamic vă ajută să creați date de testare pentru aplicații bazate pe date și de învățare automată. Acesta generează date pe baza caracteristicilor coloanei, cum ar fi e-mailul, numele și numărul de telefon.
Generatoarele de date Datanamic sunt personalizabile și acceptă majoritatea bazelor de date precum Oracle, MySQL, MySQL Server, MS Access și Postgres. Susține și asigură integritatea referențială în datele generate.
Benerator
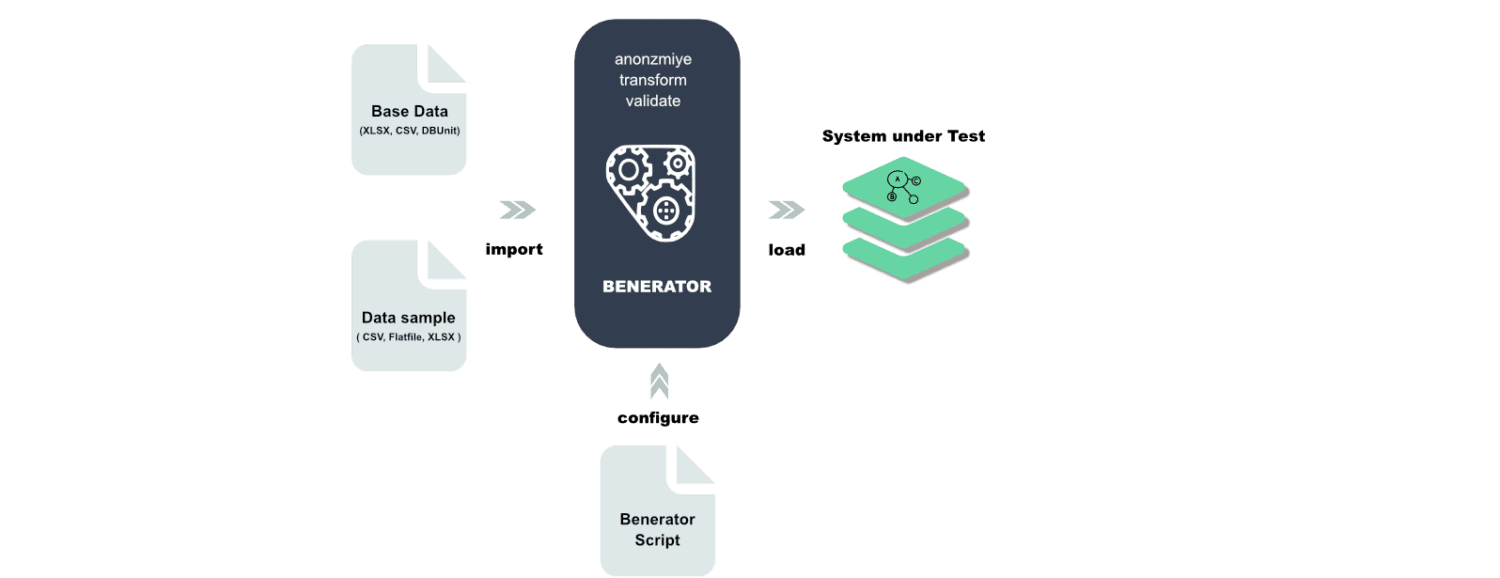
Benerator este un software pentru ofuscarea, generarea și migrarea datelor în scopuri de testare și instruire. Folosind Benerator, descrieți datele folosind XML (Extensible Markup Language) și generați folosind instrumentul de linie de comandă.
Este făcut pentru a fi utilizabil de către non-dezvoltatori și, odată cu el, puteți genera miliarde de rânduri de date. Benerator este gratuit și open-source.
Cuvinte finale
Gartner estimează că până în 2030 vor exista mai multe date sintetice utilizate pentru învățarea automată decât date reale.
Nu este greu de înțeles de ce, având în vedere costurile și preocupările privind confidențialitatea utilizării datelor reale. Prin urmare, este necesar ca întreprinderile să învețe despre datele sintetice și despre diferitele instrumente care să le ajute să le genereze.
Apoi, verificați instrumentele de monitorizare sintetice pentru afacerea dvs. online.