MapReduce oferă o metodă eficace, rapidă și economică pentru dezvoltarea aplicațiilor.
Acest model folosește concepte avansate, cum ar fi prelucrarea paralelă și localitatea datelor, aducând numeroase avantaje programatorilor și organizațiilor.
Totuși, având în vedere multitudinea de modele și cadre de programare disponibile, alegerea devine dificilă.
Mai ales când vine vorba de Big Data, selectarea tehnologiei potrivite pentru a gestiona volume mari de date este esențială.
MapReduce reprezintă o soluție excelentă pentru aceste provocări.
Acest articol explorează în profunzime conceptul MapReduce și avantajele sale.
Să începem!
Ce este MapReduce?
MapReduce este un model de programare, un cadru software integrat în Apache Hadoop, utilizat pentru crearea de aplicații care procesează cantități mari de date în paralel pe mii de noduri (numite clustere sau grile), cu toleranță la erori și fiabilitate sporită.
Această prelucrare a datelor are loc pe o bază de date sau un sistem de fișiere unde sunt stocate informațiile. MapReduce este compatibil cu sistemul de fișiere Hadoop (HDFS) pentru a accesa și gestiona cantități imense de date.
Introdus de Google în 2004 și popularizat de Apache Hadoop, MapReduce este un strat sau un motor de procesare în Hadoop, care rulează programe dezvoltate în diverse limbaje, inclusiv Java, C++, Python și Ruby.
Programele MapReduce în cloud computing se execută în paralel, fiind ideale pentru analiza datelor la scară largă.
Scopul MapReduce este de a diviza o sarcină complexă în sarcini mai mici prin intermediul funcțiilor „map” și „reduce”. Aceasta permite distribuirea sarcinii inițiale și reducerea ei la sarcini echivalente, rezultând o putere de procesare mai eficientă și o suprasarcină redusă în rețeaua de cluster.
De exemplu, imaginați-vă că pregătiți o masă pentru mulți oaspeți. Dacă încercați să faceți singur toate felurile de mâncare, procesul va deveni complicat și va dura mult timp.
Dar, dacă apelați la ajutorul prietenilor sau colegilor, distribuind diferite sarcini fiecăruia, masa va fi pregătită mai rapid și mai ușor. Aceasta este esența procesării paralele.
MapReduce funcționează similar, folosind distribuirea sarcinilor și procesarea paralelă pentru a eficientiza și accelera finalizarea unei sarcini complexe.
Apache Hadoop permite programatorilor să utilizeze MapReduce pentru a executa modele pe seturi masive de date distribuite, utilizând tehnici avansate de învățare automată și statistică pentru a identifica modele, a face predicții și a stabili corelații.
Caracteristicile MapReduce
Câteva dintre caracteristicile cheie ale MapReduce includ:
- Interfață cu utilizatorul: o interfață intuitivă oferă detalii clare despre fiecare aspect al cadrului, facilitând configurarea, implementarea și ajustarea sarcinilor.
- Sarcina utilă: Aplicațiile utilizează interfețele Mapper și Reducer pentru a activa funcțiile de mapare și reducere. Mapper mapează perechile cheie-valoare de intrare la perechi cheie-valoare intermediare. Reducer reduce perechile cheie-valoare intermediare care partajează o cheie cu valori mai mici. Aceasta îndeplinește trei funcții: sortare, amestecare și reducere.
- Partitioner: controlează împărțirea cheilor intermediare de ieșire ale hărții.
- Reporter: permite raportarea progresului, actualizarea contoarelor și setarea mesajelor de stare.
- Contoare: reprezintă contoare globale definite de o aplicație MapReduce.
- OutputCollector: colectează datele de ieșire de la Mapper sau Reducer în loc de ieșiri intermediare.
- RecordWriter: scrie datele de ieșire sau perechile cheie-valoare în fișierul de ieșire.
- DistributedCache: distribuie eficient fișiere mari, doar pentru citire, specifice aplicației.
- Comprimarea datelor: permite comprimarea ieșirilor jobului și a ieșirilor intermediare ale hărților.
- Omiterea înregistrărilor defectuoase: permite omiterea înregistrărilor defectuoase în timpul prelucrării intrărilor hărții. Această caracteristică este controlată prin clasa SkipBadRecords.
- Depanare: oferă opțiunea de a rula scripturi definite de utilizator și de a activa depanarea. În cazul în care o sarcină MapReduce eșuează, se poate rula scriptul de depanare pentru a identifica problemele.
Arhitectura MapReduce
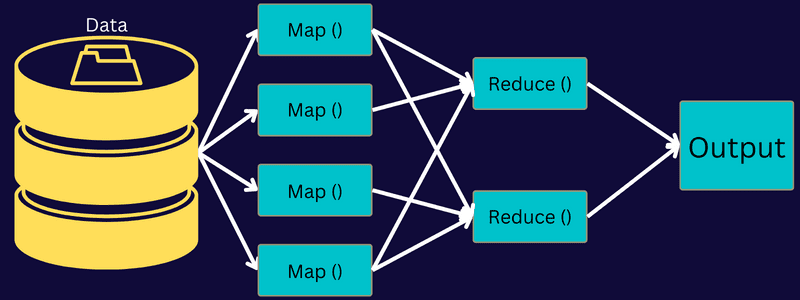
Pentru a înțelege arhitectura MapReduce, este necesar să analizăm componentele sale:
- Job: În MapReduce, un job este sarcina reală pe care clientul dorește să o execute. Acesta constă în mai multe sarcini mai mici care se combină pentru a forma sarcina finală.
- Job History Server: Un proces care stochează și salvează datele istorice despre o aplicație sau sarcină, inclusiv jurnalele generate înainte sau după executarea unui job.
- Client: Un program sau API care transmite un job la MapReduce pentru execuție. În MapReduce, unul sau mai mulți clienți pot trimite continuu joburi către MapReduce Manager pentru procesare.
- MapReduce Master: un element care împarte un job în părți mai mici, asigurându-se că sarcinile progresează simultan.
- Părți de lucru: Sarcini secundare obținute prin divizarea jobului principal. Acestea sunt lucrate și combinate pentru a crea sarcina finală.
- Date de intrare: Setul de date trimis la MapReduce pentru prelucrarea sarcinilor.
- Date de ieșire: Rezultatul final obținut după finalizarea procesării sarcinilor.
În arhitectura MapReduce, clientul trimite un job către MapReduce Master, care îl divide în părți egale. Astfel, jobul este procesat mai rapid, deoarece sarcinile mai mici necesită mai puțin timp decât cele mai mari.
Totuși, este important să se evite divizarea sarcinilor în prea multe părți mici, deoarece acest lucru poate crește cheltuielile de gestionare și poate duce la pierderi de timp.
Ulterior, părțile de lucru sunt puse la dispoziție pentru a continua cu sarcinile Map și Reduce. Programatorul dezvoltă codul bazat pe logică pentru a îndeplini cerințele specifice.
Datele de intrare sunt transmise sarcinii Map, care generează rapid rezultatul sub forma unei perechi cheie-valoare. În loc de stocarea pe HDFS, un disc local este utilizat pentru a evita replicarea inutilă a datelor.
După finalizarea sarcinii, rezultatul este eliberat. Ieșirea fiecărei sarcini de hartă este transmisă sarcinii de reducere, iar rezultatul hărții este furnizat mașinii care execută sarcina de reducere.
Apoi, rezultatul este fuzionat și transmis funcției de reducere definită de utilizator. În final, ieșirea redusă este stocată pe HDFS.
În funcție de scopul final, procesul poate include mai multe sarcini Map și Reduce pentru prelucrarea datelor. Algoritmii Map și Reduce sunt optimizați pentru a minimiza complexitatea temporală sau spațială.
Întrucât MapReduce implică în principal sarcinile Map și Reduce, este esențial să le înțelegem mai bine. Vom analiza fazele MapReduce pentru a oferi o imagine clară a acestor concepte.
Fazele MapReduce
Hartă
În această fază, datele de intrare sunt mapate în perechi de ieșire cheie-valoare. Cheia poate reprezenta ID-ul unei adrese, iar valoarea, conținutul real al acelei adrese.
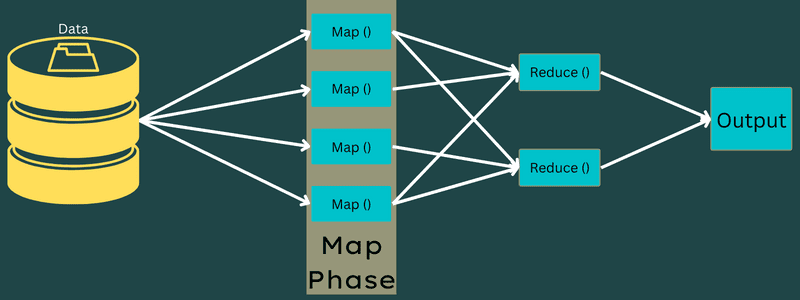
Această fază include două sarcini: divizarea și cartografierea. Divizarea se referă la sub-părțile jobului principal, numite și divizări de intrare, fiecare divizare fiind o porțiune din intrare procesată de o hartă.
Urmează sarcina de cartografiere, prima fază în timpul execuției unui program de reducere a hărții. Datele din fiecare divizare sunt transmise unei funcții de hartă pentru a genera rezultatul.
Funcția Map() se execută pe perechile cheie-valoare de intrare, generând o pereche cheie-valoare intermediară, care va servi ca intrare pentru funcția Reduce() sau Reducer.
Reduce
Perechile cheie-valoare intermediare obținute în faza de mapare servesc drept intrare pentru funcția Reduce sau Reducer. Similar cu cartografierea, sunt implicate două sarcini: amestecarea și reducerea.
Perechile cheie-valoare sunt sortate și amestecate pentru a fi transmise către Reducer. Reducer-ul grupează sau agregează datele în funcție de perechea cheie-valoare, folosind algoritmul de reducere scris de dezvoltator.
Valorile din faza de amestecare sunt combinate pentru a returna o valoare de ieșire, oferind un rezumat al întregului set de date.
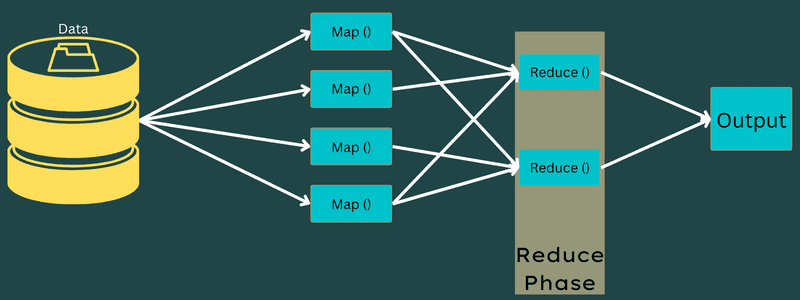
Întregul proces de executare a sarcinilor Map și Reduce este controlat de următoarele entități:
- Job Tracker: Funcționează ca un maestru, responsabil pentru executarea completă a unui job. Gestionează joburile și resursele dintr-un cluster, programând fiecare hartă adăugată în Task Tracker, care rulează pe un anumit nod de date.
- Task Tracker: Acționează ca un sclav, executând sarcinile conform instrucțiunilor Job Tracker. Este implementat pe fiecare nod din cluster și rulează sarcinile Map și Reduce.
Un job este împărțit în mai multe sarcini care rulează pe diferite noduri de date. Job Tracker coordonează sarcinile prin programarea și rularea lor pe mai multe noduri, în timp ce Task Tracker de pe fiecare nod execută porțiuni din sarcină.
Task Tracker trimite rapoarte de progres către Job Tracker și semnale de „bătăi ale inimii” pentru a-l informa despre starea sistemului. În caz de eșec, Task Tracker poate reprograma jobul pe un alt Task Tracker.
Faza de ieșire: în această fază se obțin perechile cheie-valoare finale generate de Reducer. Un formatator de ieșire poate fi utilizat pentru a traduce aceste perechi și a le scrie într-un fișier cu ajutorul unui scriitor de înregistrări.
De ce să folosiți MapReduce?
Iată câteva avantaje ale utilizării MapReduce în aplicațiile de Big Data:
Procesare paralelă
MapReduce permite împărțirea unui job pe diferite noduri, unde fiecare nod procesează simultan o parte a sarcinii. Acest lucru reduce complexitatea și accelerează procesarea datelor prin rularea sarcinilor în paralel pe mai multe mașini.
Localitatea datelor
În MapReduce, unitatea de procesare este mutată la date, nu invers.
În mod tradițional, datele erau aduse la unitatea de procesare, dar, odată cu creșterea volumului de date, acest proces a devenit ineficient. MapReduce inversează abordarea, aducând unitatea de procesare la date, distribuindu-le între noduri, fiecare nod procesând o parte din datele stocate.
Această metodă oferă eficiență economică și reduce timpul de procesare, eliminând supraîncărcarea unui singur nod.
Securitate

MapReduce oferă securitate sporită, protejând aplicațiile de date neautorizate și sporind securitatea clusterului.
Scalabilitate și flexibilitate
MapReduce este extrem de scalabil, permițând rularea aplicațiilor pe mai multe mașini, folosind date de mii de terabytes. De asemenea, oferă flexibilitatea procesării datelor structurate, semi-structurate sau nestructurate, de orice format sau dimensiune.
Simplitate
Programele MapReduce pot fi scrise în diverse limbaje de programare, precum Java, R, Perl, Python, ceea ce îl face ușor de învățat și utilizat pentru îndeplinirea cerințelor de procesare a datelor.
Cazuri de utilizare a MapReduce
- Indexarea textului integral: MapReduce este utilizat pentru a indexa textul integral. Mapper-ul mapează fiecare cuvânt sau frază dintr-un document, iar Reducer-ul scrie toate elementele mapate într-un index.
- Calcularea Pagerank: Google folosește MapReduce pentru a calcula Pagerank.
- Analiză jurnal: MapReduce poate analiza fișiere jurnal. Mapper-ul caută pagini web accesate, iar perechea cheie-valoare (pagina web, 1) este transmisă Reducer-ului. Rezultatul este numărul total de accesări pentru fiecare pagină web.

- Reverse Web-Link Graph: MapReduce este utilizat pentru a genera graficele de legături web inverse. Map() oferă URL-ul țintă și sursa, iar Reduce() adună lista fiecărei surse asociate cu URL-ul țintă.
Rezultatul final conține sursele și ținta.
- Numărarea cuvintelor: MapReduce poate fi folosit pentru a număra de câte ori apare un cuvânt într-un document.
- Încălzirea globală: Organizațiile pot utiliza MapReduce pentru a analiza problemele legate de încălzirea globală. De exemplu, date despre temperatura oceanelor (temperatură ridicată, temperatură scăzută, latitudine, longitudine, dată, oră) sunt colectate și prelucrate cu ajutorul sarcinilor Map și Reduce.
- Teste de medicamente: MapReduce poate fi folosit pentru a inspecta eficacitatea unui medicament pe un grup de pacienți.
- Alte aplicații: MapReduce poate procesa date la scară mare, care nu se pot încadra într-o bază de date relațională, și permite rularea instrumentelor de știința datelor pe seturi de date distribuite.
Datorită robustei și simplității sale, MapReduce este utilizat în diverse domenii, inclusiv militar, afaceri și știință.
Concluzie
MapReduce este o tehnologie inovatoare, care oferă procesare rapidă, simplă, economică și eficientă. Având în vedere avantajele sale și popularitatea în creștere, este de așteptat să devină și mai utilizat în diverse industrii și organizații.
De asemenea, puteți explora cele mai bune resurse pentru a învăța Big Data și Hadoop.