

Named Entity Recognition (NER) oferă o modalitate excelentă de a înțelege o anumită informație textuală și de a identifica anumite entități sau etichete din ea pentru diverse aplicații.
De la categorizarea numelor persoanelor până la indicarea datelor, organizațiilor, locațiilor și multe altele, NER își face drumul pentru o mai bună înțelegere a limbii.
Multe organizații se ocupă cu un volum mare de date sub formă de conținut, informații personale, feedback-ul clienților, detalii despre produse și multe altele.
Când aveți nevoie de informații instantaneu, va trebui să efectuați operațiuni de căutare pentru a obține rezultatul, ceea ce poate consuma mult timp, energie și resurse, mai ales atunci când aveți de-a face cu volume mari de date.
Pentru a oferi organizațiilor o soluție eficientă pentru operațiunile de căutare și găsirea datelor potrivite, NER este o opțiune excelentă.
În acest articol, voi discuta în detaliu NER, conceptul său matematic, diferitele sale utilizări și alte puncte importante.
Să începem!
Cuprins
Ce este recunoașterea entității numite?
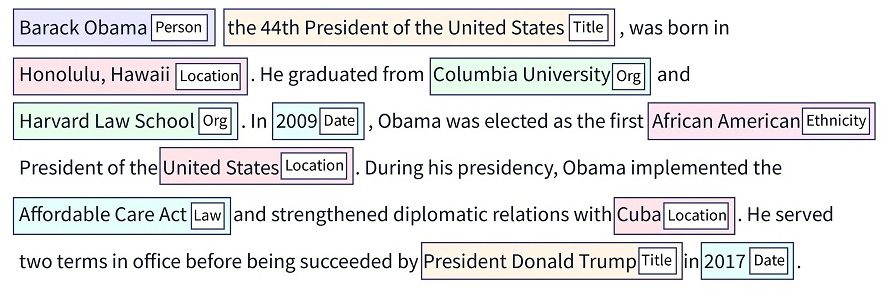
Recunoașterea entităților numite (NER) este o metodă de procesare a limbajului natural (NLP) care poate identifica și clasifica entități în date textuale, nestructurate.
Aceste entități conțin o gamă largă de informații, cum ar fi organizații, locații, nume de persoane, valori numerice, date și multe altele. Dă putere mașinilor să extragă entitățile de mai sus, făcându-l un instrument util pentru aplicații precum traducerea, răspunsul la întrebări etc., în mai multe industrii.
 Sursă: Scaler
Sursă: Scaler
Deci, NER caută să localizeze și să clasifice diferitele entități dintr-un text nestructurat în grupuri predefinite, cum ar fi organizații, coduri medicale, cantități, nume de persoane, procente, valori monetare, expresii de timp și multe altele.
Să înțelegem asta cu un exemplu:
[William] a cumparat o proprietate de la [Z1 Corp.] în [2023]. Aici blocurile sunt entitățile identificate de NER. Ele sunt clasificate ca:
- William – Numele unei persoane
- Z1 Corp. – Organizare
- 2003 – Timp
NER este utilizat în mai multe domenii ale AI, inclusiv învățarea profundă, învățarea automată (ML) și rețelele neuronale. Este o componentă critică a sistemelor NLP, cum ar fi instrumentele de analiză a sentimentelor, motoarele de căutare și chatboții. În plus, poate fi folosit în finanțe, asistență pentru clienți, învățământ superior, asistență medicală, resurse umane și analiza rețelelor sociale.
Mai simplu spus, NER identifică, clasifică și extrage informațiile esențiale din textul nestructurat fără nicio analiză umană. Poate extrage rapid informații cheie din setul disponibil de date mari.
În plus, NER oferă organizației dumneavoastră informații esențiale despre produse, tendințele pieței, clienții și concurența. De exemplu, instituțiile medicale folosesc NER pentru a extrage date medicale esențiale din dosarele pacienților. Multe companii îl folosesc pentru a identifica dacă sunt menționate în vreo publicație.
Concepte cheie: NER

Este important să cunoaștem conceptele de bază implicate în NER. Să discutăm câțiva termeni cheie legați de NER pentru a fi familiarizați.
- Entitate numită: orice cuvânt care se referă la un loc, organizație, persoană sau altă entitate.
- Corpus: O colecție de texte diferite utilizate pentru analiza limbilor și formarea modelelor NER.
- Etichetarea POS: un proces în care textul este etichetat în funcție de vorbirea corespunzătoare, cum ar fi adjective, verbe și substantive.
- Chunking: este un proces folosit pentru a grupa cuvintele în diferite fraze semnificative, bazate pe structura sintactică și o parte a vorbirii.
- Date de instruire și testare: Acesta este procesul utilizat pentru a antrena un model cu date etichetate și pentru a evalua performanța primului set pe un alt set de date.
Utilizarea NER în NLP

NER are multiple aplicații în NLP, cum ar fi analiza sentimentelor, sisteme de recomandare, răspunsuri la întrebări, extragerea de informații și multe altele.
- Analiza sentimentelor: NER este utilizat pentru a detecta sentimentul exprimat într-o propoziție sau paragraf față de o anumită entitate numită, cum ar fi un produs sau serviciu. Aceste date sunt folosite pentru a îmbunătăți experiența clienților și pentru a identifica zonele de îmbunătățire.
- Sisteme de recomandare: NER este utilizat pentru a identifica preferințele și interesele utilizatorilor pe baza entităților numite menționate în interacțiunile online sau în interogările de căutare. Aceste date sunt folosite pentru a îmbunătăți îmbunătățirea utilizatorilor prin furnizarea de recomandări personalizate.
- Răspuns la întrebare: NER este folosit pentru a detecta anumite entități dintr-un text, care este folosit în continuare pentru a răspunde la o întrebare sau la o anumită întrebare. Acesta este în general folosit pentru asistenți virtuali și chatbot.
- Extragerea informațiilor: NER este utilizat pentru a extrage informații esențiale dintr-un set mai mare de text nestructurat. Acestea includ postări pe rețelele sociale, recenzii online, articole de știri și multe altele. Aceste date sunt folosite pentru a genera informații valoroase și pentru a lua decizii bazate pe date.
Concepte matematice: NER
Procesul NER include diferite concepte matematice, cum ar fi învățarea automată, învățarea profundă, teoria probabilității și multe altele. Iată câteva tehnici matematice:
- Modele Markov ascunse: Modelele Markov ascunse sau HMM-uri reprezintă o abordare statistică pentru secvențierea sarcinilor de clasificare, cum ar fi NER. Aceasta implică reprezentarea unei secvențe de cuvinte din text ca stări diferite, în care fiecare stat reprezintă o entitate specifică numită. Analizând probabilitățile, puteți identifica entitățile numite din text.
- Învățare profundă: tehnicile de învățare profundă, cum ar fi rețelele neuronale, sunt utilizate în sarcinile NER. Acest lucru vă permite să identificați și să clasificați în mod eficient și precis entitățile numite.
- Câmpuri aleatoare condiționale: acestea intră sub un model grafic care este utilizat în sarcinile de etichetare a secvenței. Ele oferă modelarea probabilității condiționate a fiecărei etichete care conține secvența de cuvinte. Acest lucru vă permite să identificați entitățile numite într-un text.
Cum funcționează NER?
 Sursă: Publicaţii ACS
Sursă: Publicaţii ACS
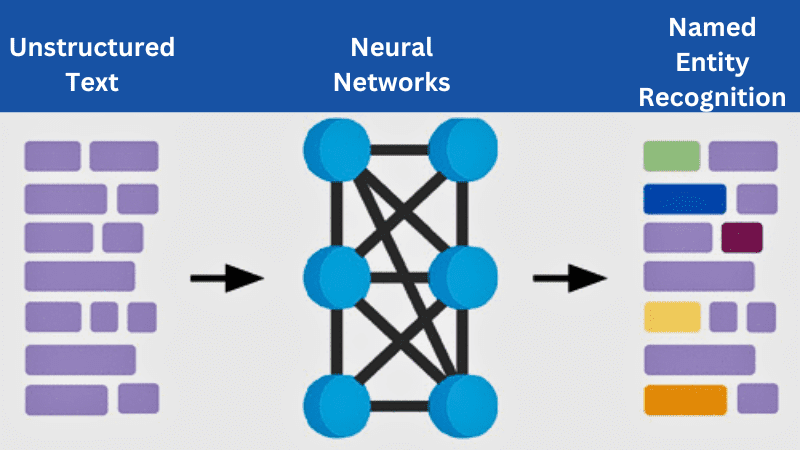
Named Entity Recognition (NER) funcționează ca o extragere de informații. Funcționarea sa este împărțită în diferite etape cheie:
#1. Preprocesează textul
În primul pas, NER presupune pregătirea informațiilor textuale pentru analiză. În general, implică sarcini precum tokenizarea. Aici, textul s-a împărțit la început în token-uri înainte ca NER să înceapă să identifice entitățile.
De exemplu, „Bill Gates a fondat Microsoft” poate fi împărțit în diferite simboluri precum „Bill”, „Gates”, „fondat” și „Microsoft”.
#2. Identificați Entitățile
Potențialele entități numite pot fi detectate folosind metode statistice sau reguli lingvistice. Acest pas implică recunoașterea modelelor, cum ar fi anumite formate (date) sau scrierea cu majuscule în nume („Bill Gates”). Odată ce funcția de preprocesare este finalizată, algoritmii NER scanează textul pentru a identifica cuvintele din secvențele care corespund entităților.
#3. Clasificarea entităților
După ce NER identifică entitățile, clasifică aceste entități recunoscute în tipuri, clase sau grupuri. Categoriile comune sunt organizația, data, locația, persoana și multe altele. Acest lucru se realizează prin modele de învățare automată care sunt antrenate pe date etichetate.
De exemplu, „Bill Gates” ar fi recunoscut ca „persoană” și „Microsoft” ca „organizație”.
#4. Analiza contextuală
NER nu se oprește niciodată la recunoașterea și clasificarea entităților. Adesea, ia în considerare contextul pentru a spori acuratețea. Acest pas ia în considerare contextul în care apar entitățile, oferind o clasificare precisă.
De exemplu, „Bill Gates a fondat Microsoft”. Aici, contextul permite sistemelor să identifice „Bill” ca numele unei persoane și nu factura unei plăți.
#5. Post procesare
După identificarea și clasificarea inițială, este necesară post-procesarea pentru a rafina rezultatele finale. Aceasta implică rezolvarea ambiguităților, utilizarea bazelor de cunoștințe, fuzionarea entităților multi-token și multe altele pentru a îmbunătăți datele entităților.
Partea uimitoare a NER este că are capacitatea de a interpreta și înțelege textul nestructurat, care conține datele necesare pentru afacerea dvs. Primește o parte esențială a datelor din articole de știri, pagini web, lucrări de cercetare, postări pe rețelele sociale și multe altele.
Prin recunoașterea și clasificarea entităților numite, NER adaugă un strat suplimentar de semnificație și structură peisajului textual.
Metode de NER

Cele mai frecvent utilizate metode sunt următoarele:
#1. Metodă bazată pe învățarea automată supravegheată
Această metodă utilizează modele de învățare automată care sunt antrenate pe texte care sunt pre-etichetate de oameni cu categorii de entități numite.
Această abordare utilizează algoritmi, inclusiv entropia maximă și câmpuri aleatoare condiționate, pentru a obține modele complexe de limbaj statistic. Este eficient pentru rezolvarea semnificațiilor lingvistice împreună cu alte complexități, dar are nevoie de un volum mare de date de antrenament pentru a efectua operația.
#2. Sisteme bazate pe reguli
Această metodă utilizează diferite reguli pentru a colecta informații. Include titluri sau majuscule, cum ar fi „Er”. În această metodă, este necesară multă intervenție umană pentru a da input, a monitoriza și a răsuci regulile. Această metodă poate pierde variațiile textuale care nu sunt incluse în adnotările de instruire. De aceea, sistemele bazate pe reguli nu pot face față complexității și modelelor de învățare automată.
#3. Dicţionar-Based Systems
În această metodă, un dicționar care conține o cantitate mare de sinonime și colecție de vocabular este utilizat pentru a identifica și verifica identitățile cu nume. Această metodă se confruntă cu dificultăți în clasificarea entităților numite care au diferite variații de ortografie.
De asemenea, există multe alte metode NER emergente. Să le discutăm și pe ele:
#4. Sisteme de învățare automată nesupravegheate
Aceste sisteme ML folosesc modele de învățare automată care nu sunt pre-antrenate pe datele text. Modelele de învățare nesupravegheată sunt mai capabile să execute sarcini complexe decât modelele supravegheate.
#5. Sisteme de bootstrapping
Sistemele de bootstrapping sunt cunoscute și ca sisteme auto-supravegheate care clasifică entitățile numite în funcție de caracteristicile gramaticale, inclusiv părți de etichete de vorbire, majuscule și alte categorii pre-antrenate.
Apoi, un om modifică sistemul bootstrap etichetând predicțiile sistemului ca fiind incorecte sau corecte și adăugându-le pe cele potrivite la noul set de antrenament.
#6. Sisteme de rețele neuronale
Construiește modelul de recunoaștere a entităților cu nume folosind modele de învățare a arhitecturii bidirecționale (reprezentări bidirecționale de codificare din transformatoare), rețele neuronale și tehnici de codare. Această metodă minimizează interacțiunea umană.
#7. Sisteme Statistice
Această metodă utilizează modele probabilistice care sunt antrenate pe relații și modele textuale. Ajută la prezicerea cu ușurință a entităților numite din noi date bazate pe text.
#8. Sisteme de etichetare semantică a rolurilor
Acest sistem preprocesează un model de recunoaștere a entității numite folosind tehnicile de învățare semantică care predau relația dintre categorii și context.
#9. Sisteme hibride
Această metodă este una interesantă care utilizează aspecte ale mai multor abordări într-o manieră combinată.
Beneficiile NER
Modelele NER oferă numeroase beneficii.
- NER automatizează procesul de extragere a datelor pentru un volum mare de date.
- Este folosit în fiecare industrie pentru a extrage informații cheie dintr-un text nestructurat.
- Acest lucru vă poate economisi timp pe dvs. și angajaților dvs. în efectuarea sarcinilor de extragere a datelor.
- Poate îmbunătăți acuratețea proceselor și sarcinilor NLP.
- Acesta asigură securitatea datelor prin găzduirea modelelor NER personalizate, eliminând necesitatea de a partaja informații sensibile cu furnizori terți.
- Se adaptează la noi tipuri de entități și terminologii pe măsură ce domeniul evoluează.
Provocările NER
- Ambiguitate: multe cuvinte folosite în text pot fi înșelătoare. De exemplu, cuvântul „Amazon” se referă la o companie, un râu și o pădure. Poate fi diferențiat de un context specific. Astfel, acest lucru face recunoașterea entităților puțin mai dificilă.
- Dependența de context: Cuvintele derivate din contextul înconjurător au semnificații diferite; de exemplu, „Apple” într-un text bazat pe tehnologie se referă la corporație, în timp ce în împrejurimi, se referă la fructe. Nu este greu să recunoști o entitate exactă.
- Raritatea datelor: pentru metodele NER bazate pe ML, disponibilitatea datelor etichetate este esențială. Cu toate acestea, extragerea unor astfel de date, în special pentru domenii specializate sau limbi mai puțin obișnuite, poate fi o provocare.
- Variații de limbă: limbile umane au forme diferite în funcție de dialectele lor, de diferențele regionale și de argou. Prin urmare, este dificil să extragi textul în limbă străină.
- Generalizarea modelului: modelele NER ar putea excela în clasificarea entităților într-un singur domeniu, dar pot confunda generalizarea într-un alt domeniu. Deci, modelele NER se pot comporta diferit în diferite domenii.
Aceste provocări pot fi abordate dacă combinați algoritmi avansați, expertiză lingvistică și date de calitate. Deoarece NER evoluează, echipele de cercetare și dezvoltare trebuie să perfecționeze diferite tehnici pentru a face față acestor provocări.
Cazuri de utilizare ale NER
#1. Clasificarea conținutului

Editurile și casele de știri generează un volum mare de conținut online. Deci, gestionarea lor eficientă este crucială pentru a profita la maximum de un articol sau știre.
Named Entity Recognition scanează automat întregul conținut și extrage date precum organizații, locuri și nume de persoane utilizate în conținut. Cunoașterea etichetelor necesare pentru fiecare articol vă ajută să clasificați articolele în ierarhia definită, îmbunătățind livrarea conținutului.
#2. Algoritmi de căutare
Să presupunem că aveți un algoritm intern de căutare pentru editorul dvs. online, care conține milioane de articole. Pentru fiecare interogare de căutare, algoritmul tău intern de căutare ajunge să adune toate cuvintele din acele articole. Acesta este un proces care consumă timp.
Acum, dacă utilizați NER pentru editorul dvs. online, acesta va obține cu ușurință entitățile esențiale din toate articolele și le va stoca separat. Acest lucru vă va accelera procesul de căutare.
#3. Recomandări de conținut
Automatizarea procesului de recomandare este un caz de utilizare major al NER. Sistemele de recomandare ghidează în descoperirea de noi idei și conținut.
Netflix este cel mai bun exemplu în acest sens. Este dovada că construirea unui sistem eficient de recomandare te ajută să devii mai captivant și mai captivant de evenimente.
Pentru editorii de știri, NER lucrează eficient în recomandarea unor articole similare. Acest lucru se poate face prin colectarea etichetelor dintr-un anumit articol și recomandarea altor conținuturi care au entități similare.
#4. Relații Clienți

Pentru fiecare organizație, asistența pentru clienți este un lucru important. De aceea, există mai multe moduri de a face funcția de gestionare a feedback-ului clienților fără probleme. NER este unul dintre ele. Să înțelegem asta cu un exemplu.
Să presupunem că un client oferă feedback „Personalul din magazinul Adidas din San Diego nu are detalii mai fine despre pantofii sport.” Aici, NER scoate etichetele „San Diego” (locație) și „pantofi sport” (produs).
Astfel, NER este folosit pentru a clasifica fiecare reclamație și a o trimite departamentului respectiv din cadrul organizației pentru a se ocupa de problema. Puteți dezvolta o bază de date constând din feedback care este clasificat în diferite departamente și puteți analiza fiecare feedback.
#5. Lucrări de cercetare
O publicație online sau un site web de jurnal deține o mulțime de articole academice și lucrări de cercetare. Puteți găsi sute de lucrări care seamănă cu subiecte similare, cu ușoare modificări. Deci, organizarea tuturor acestor date într-o manieră structurată poate fi o sarcină complicată.
Pentru a sări peste procesul lung, puteți separa aceste documente pe baza etichetelor relevante.
De exemplu, există mii de lucrări despre învățarea automată. Pentru a-l găsi pe cel care a menționat utilizarea rețelelor neuronale convoluționale (CNN), trebuie să puneți entități pe ele. Acest lucru vă va ajuta să găsiți rapid articolul conform cerințelor dvs.
Concluzie
Tehnica NLP, Named Entity Recognition (NER), ajută la identificarea entităților numite într-un text nestructurat și la clasificarea acestor entități în grupuri predefinite, cum ar fi locații, nume de persoane, produse și multe altele.
Scopul principal al NER este de a aduna informații structurate dintr-un text nestructurat și de a le reprezenta într-un format care poate fi citit. Implica diverse modele si procese si aduce multe beneficii profesionistilor si afacerilor. Este, de asemenea, folosit pentru diverse aplicații în afară de NLP.
Sper că înțelegeți explicația de mai sus despre această tehnică pentru a putea implementa acest lucru în afacerea dvs. și pentru a obține informații relevante și valoroase în timp.
De asemenea, puteți explora unele cele mai bune cursuri NLP pentru a învăța procesarea limbajului natural