Comparativ cu metodele tradiționale de stocare a datelor, cum ar fi CSV, formatul Apache Parquet oferă avantaje considerabile în ceea ce privește eficiența stocării și viteza de acces la date.
Parquet este special conceput pentru a accelera procesarea seturilor de date complexe. În acest articol, vom analiza modul în care formatul Parquet răspunde necesităților actuale de gestionare a volumelor mari de date.
Înainte de a detalia caracteristicile formatului Parquet, este important să înțelegem ce presupune stocarea datelor în format CSV și care sunt limitările acestui format.
Ce este stocarea CSV?
Formatul CSV (Comma Separated Values) este un mod comun de structurare și formatare a datelor. Datele CSV sunt stocate în fișiere cu extensia .csv, organizate pe rânduri. Aceste fișiere pot fi vizualizate și editate folosind aplicații precum Excel, Google Sheets sau orice editor de text, oferind o prezentare ușor de înțeles a datelor.
Cu toate acestea, formatul CSV nu este ideal pentru gestionarea bazelor de date, în special a celor de mari dimensiuni.
Pe măsură ce cantitatea de date crește, devine dificil să interogăm, gestionăm și recuperăm informațiile stocate în format CSV.
Iată un exemplu de date stocate într-un fișier .CSV:
EmpId,First name,Last name, Division 2012011,Sam,Butcher,IT 2013031,Mike,Johnson,Human Resource 2010052,Bill,Matthew,Architect 2010079,Jose,Brian,IT 2012120,Adam,James,Solutions
În Excel, structura rând-coloană a acestor date ar fi vizualizată astfel:
Limitările stocării CSV
Formatele de stocare bazate pe rânduri, precum CSV, sunt eficiente pentru operațiunile de creare, actualizare și ștergere (CRUD).
Dar cum se comportă la operațiunile de citire (R din CRUD)?
Să ne imaginăm un fișier .csv care conține un milion de rânduri. Deschiderea și căutarea informațiilor relevante într-un astfel de fișier ar dura considerabil. Mai mult, majoritatea furnizorilor de servicii cloud, cum ar fi AWS, tarifează utilizatorii în funcție de cantitatea de date scanate sau stocate, iar fișierele CSV ocupă un spațiu semnificativ.
Stocarea CSV nu include o metodă directă pentru stocarea metadatelor, ceea ce face ca procesul de scanare a datelor să fie complex și îndelungat.
Care este așadar, soluția optimă și eficientă pentru operațiunile CRUD? Haideți să explorăm.
Ce este stocarea datelor Parquet?
Parquet este un format de stocare open-source destinat stocării datelor, frecvent utilizat în ecosistemele Hadoop și Spark. Fișierele Parquet au extensia .parquet.
Parquet este un format structurat care poate optimiza datele brute complexe stocate în lacurile de date, reducând semnificativ timpul necesar pentru interogări.
Formatul Parquet combină stocarea pe rânduri și pe coloane (hibrid), ceea ce permite o stocare eficientă și o recuperare mai rapidă a datelor. Datele sunt împărțite atât orizontal, cât și vertical, iar costul analizei este diminuat considerabil.
Parquet limitează numărul total de operații I/O, reducând costurile asociate.
De asemenea, Parquet stochează metadate care includ informații despre schema datelor, numărul de valori, locația coloanelor, valorile minime și maxime, tipul de codificare etc. Metadatele sunt stocate la diferite niveluri în fișier, facilitând un acces rapid la date.
În formatul CSV, citirea datelor necesită timp, deoarece interogarea trebuie să parcurgă fiecare rând. În schimb, în formatul Parquet, toate coloanele necesare pot fi accesate simultan.
Pe scurt:
- Parquet utilizează o structură pe coloane pentru stocarea datelor
- Este optimizat pentru stocarea datelor complexe în sistemele de stocare
- Formatul Parquet oferă diverse metode de comprimare și codificare a datelor
- Reduce semnificativ timpul de scanare și interogare și ocupă mai puțin spațiu pe disc comparativ cu alte formate precum CSV
- Minimizează operațiile I/O, scăzând costul de stocare și de execuție a interogărilor
- Include metadate care facilitează localizarea datelor
- Este un format open-source
Structura formatului Parquet
Pentru a înțelege modul în care sunt stocate datele în format Parquet, putem examina un exemplu:
Un fișier poate conține mai multe partiții orizontale, numite grupuri de rânduri. Fiecare grup de rânduri este împărțit vertical în coloane, iar datele sunt stocate în pagini în interiorul acestor coloane. Fiecare pagină conține valori și metadate codificate. Metadatele pentru întregul fișier sunt, de asemenea, stocate la nivel de grup de rânduri, în subsolul fișierului.
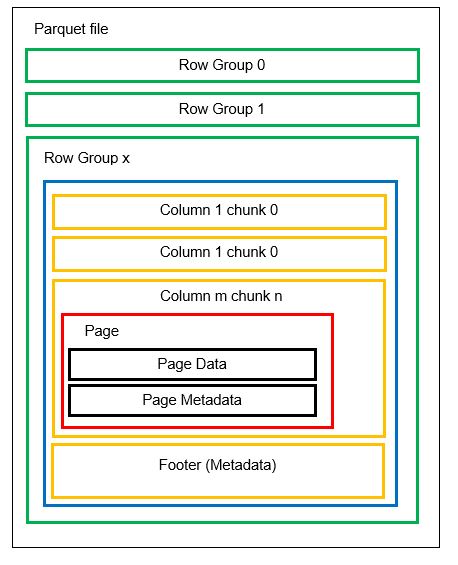
Datorită structurii pe coloane, adăugarea de noi date este facilă: noile valori sunt codificate într-un nou segment, iar metadatele sunt actualizate. Astfel, Parquet este un format flexibil.
Parquet suportă nativ comprimarea datelor prin tehnici de compresie a paginilor și codificare a dicționarului. Un exemplu de compresie prin dicționar este:
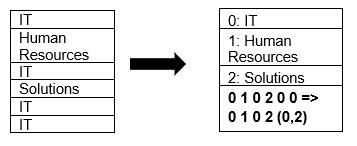
În acest exemplu, divizia IT apare de 4 ori. Prin urmare, în timpul stocării, formatul codifică valoarea IT cu o altă valoare (0,1,2…) și stochează numărul de repetiții. De exemplu, IT, IT este transformat în 0,2, economisind spațiu. Interogarea datelor comprimate este mai rapidă.
Comparație directă
Acum că am înțeles cum funcționează formatele CSV și Parquet, iată o comparație a statisticilor lor:
| CSV | Parquet |
| Format de stocare pe rând. | Format de stocare hibrid, bazat pe rânduri și coloane. |
| Consumă mult spațiu deoarece nu are compresie implicită. Un fișier de 1 TB va ocupa același spațiu pe Amazon S3 sau alt serviciu cloud. | Comprimă datele în timpul stocării, consumând mai puțin spațiu. Un fișier de 1 TB stocat în format Parquet va ocupa doar 130 GB. |
| Timpul de rulare a interogării este lent datorită căutării pe rând. Pentru fiecare coloană, fiecare rând trebuie parcurs. | Timpul de interogare este de aproximativ 34 de ori mai rapid datorită stocării pe coloană și prezenței metadatelor. |
| Mai multe date trebuie scanate pentru fiecare interogare. | Aproximativ 99% mai puține date sunt scanate pentru interogare, optimizând performanța. |
| Majoritatea dispozitivelor de stocare tarifează în funcție de spațiul ocupat, deci formatul CSV implică costuri mari. | Costuri mai mici de stocare deoarece datele sunt stocate comprimat și codificat. |
| Schema de fișiere trebuie dedusă (cu posibile erori) sau furnizată manual (ceea ce este obositor). | Schema de fișiere este stocată în metadate. |
| Formatul este potrivit pentru tipuri simple de date. | Formatul este potrivit inclusiv pentru tipuri complexe, cum ar fi scheme imbricate, matrice, dicționare. |
Concluzie 👩💻
Am observat, prin exemple, că Parquet este mai eficient decât CSV în ceea ce privește costul, flexibilitatea și performanța. Este un mecanism eficient pentru stocarea și recuperarea datelor, mai ales în contextul migrării spre stocarea în cloud și al optimizării spațiului. Toate platformele majore precum Azure, AWS și BigQuery suportă formatul Parquet.