
Python este un limbaj foarte versatil, iar dezvoltatorii Python trebuie adesea să lucreze cu o varietate de fișiere și să obțină informații stocate în ele pentru procesare. Un format de fișier popular pe care trebuie să-l întâlniți în calitate de dezvoltator Python este formatul de document portabil, cunoscut sub numele de PDF.
Fișierele PDF pot conține text, imagini și link-uri. Când procesați date într-un program Python, este posibil să aveți nevoie să extrageți datele stocate într-un document PDF. Spre deosebire de structurile de date precum tupluri, liste și dicționare, obținerea de informații stocate într-un document PDF poate părea un lucru dificil de făcut.
Din fericire, există o serie de biblioteci care facilitează lucrul cu PDF-uri și extrage datele stocate în fișiere PDF. Pentru a afla mai multe despre aceste biblioteci diferite, haideți să vedem cum puteți extrage texte, link-uri și imagini din fișiere PDF. Pentru a urma, descărcați următorul fișier PDF și salvați-l în același director cu fișierul programului Python.
Pentru a extrage text din fișierele PDF folosind Python, vom folosi PyPDF2 bibliotecă. PyPDF2 este o bibliotecă Python gratuită și open-source care poate fi folosită pentru a îmbina, decupa și transforma paginile fișierelor PDF. Poate adăuga date personalizate, opțiuni de vizualizare și parole la fișierele PDF. Important, totuși, PyPDF2 poate prelua text din fișiere PDF.
Pentru a utiliza PyPDF2 pentru a extrage text din fișierele PDF, instalați-l folosind pip, care este un program de instalare a pachetelor pentru Python. pip vă permite să instalați diferite pachete Python pe mașina dvs.:
1. Verificați dacă aveți deja instalat pip rulând:
pip --version
Dacă nu primiți înapoi un număr de versiune, înseamnă că pip nu este instalat.
2. Pentru a instala pip, faceți clic pe ia pip pentru a-și descărca scriptul de instalare.
Linkul deschide o pagină cu scriptul de instalare a pip, așa cum se arată mai jos:
Faceți clic dreapta pe pagină și faceți clic pe Salvare ca pentru a salva fișierul. În mod implicit, numele fișierului este get-pip.py
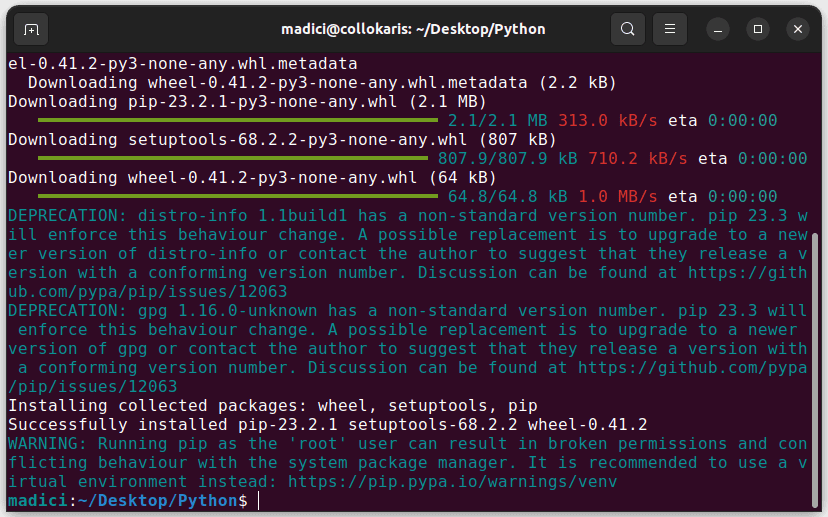
Deschideți terminalul și navigați la directorul cu fișierul get-pip.py pe care tocmai l-ați descărcat, apoi rulați comanda:
sudo python3 get-pip.py
Aceasta ar trebui să instaleze pip așa cum se arată mai jos:
3. Verificați dacă pip a fost instalat cu succes rulând:
pip --version
Dacă aveți succes, ar trebui să obțineți un număr de versiune:

Cu pip instalat, acum putem începe să lucrăm cu PyPDF2.
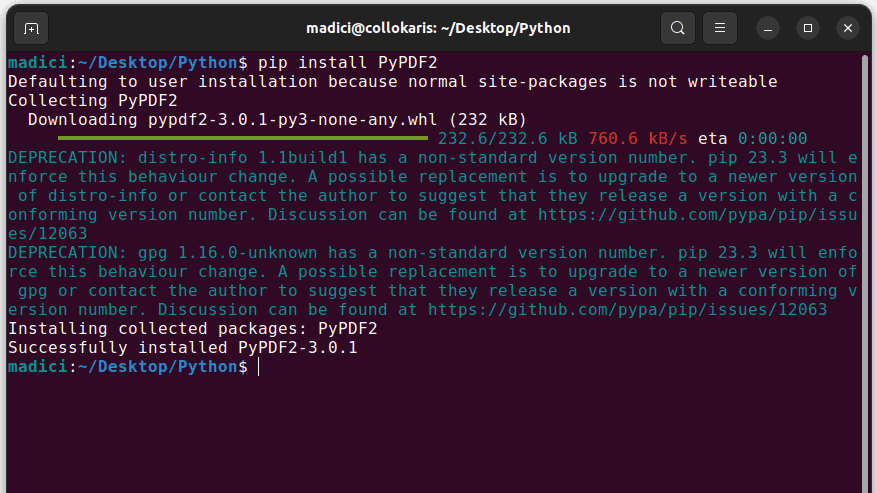
1. Instalați PyPDF2 executând următoarea comandă în terminal:
pip install PyPDF2
2. Creați un fișier Python și importați PdfReader din PyPDF2 utilizând următoarea linie:
from PyPDF2 import PdfReader
Biblioteca PyPDF2 oferă o varietate de clase pentru lucrul cu fișiere PDF. O astfel de clasă este PdfReader, care poate fi folosită pentru a deschide fișiere PDF, a citi conținutul și a extrage text din fișiere PDF, printre altele.
3. Pentru a începe să lucrați cu un fișier PDF mai întâi trebuie să deschideți fișierul. Pentru a face acest lucru, creați o instanță a clasei PdfReader și transmiteți fișierul PDF cu care doriți să lucrați:
reader = PdfReader('games.pdf')
Linia de mai sus instanțează PdfReader și îl pregătește pentru a accesa conținutul fișierului PDF pe care îl specificați. Instanța este stocată într-o variabilă numită reader, care va trebui să acceseze o varietate de metode și proprietăți disponibile în clasa PdfReader.
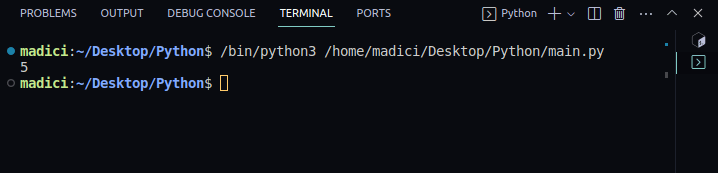
4. Pentru a vedea dacă totul funcționează bine, tipăriți numărul de pagini din PDF-ul pe care l-ați trimis folosind următorul cod:
print(len(reader.pages))
Ieșire:
5
5. Deoarece fișierul nostru PDF are 5 pagini, putem accesa fiecare pagină disponibilă în PDF. Cu toate acestea, numărarea începe de la 0, la fel ca convenția de indexare a lui Python. Prin urmare, prima pagină din fișierul pdf va fi pagina cu numărul 0. Pentru a prelua prima pagină a PDF-ului, adăugați următoarea linie la codul dvs.:
page1 = reader.pages[0]
Linia de mai sus preia prima pagină din fișierul PDF și o stochează într-o variabilă numită page1.
6. Pentru a extrage textul de pe prima pagină a fișierului PDF, adăugați următoarea linie:
textPage1 = page1.extract_text()
Aceasta extrage textul de pe prima pagină a PDF-ului și stochează conținutul într-o variabilă numită textPage1. Aveți astfel acces la textul de pe prima pagină a fișierului PDF prin variabila textPage1.
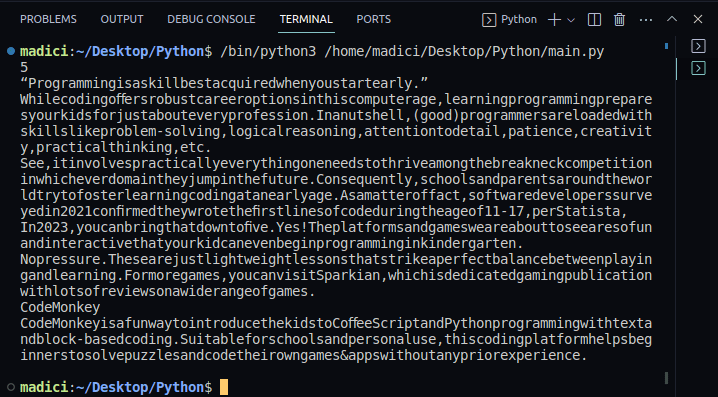
7. Pentru a confirma că textul a fost extras cu succes, puteți imprima conținutul variabilei textPage1. Întregul nostru cod, care tipărește și textul pe prima pagină a fișierului PDF, este afișat mai jos:
# import the PdfReader class from PyPDF2
from PyPDF2 import PdfReader
# create an instance of the PdfReader class
reader = PdfReader('games.pdf')
# get the number of pages available in the pdf file
print(len(reader.pages))
# access the first page in the pdf
page1 = reader.pages[0]
# extract the text in page 1 of the pdf file
textPage1 = page1.extract_text()
# print out the extracted text
print(textPage1)
Ieșire:
Pentru a extrage legături din fișierele PDF, mergem la PyMuPDF, care este o bibliotecă Python pentru extragerea, analizarea, convertirea și manipularea datelor stocate în documente, cum ar fi PDF-urile. Pentru a utiliza PyMuPDF, ar trebui să aveți Python 3.8 sau o versiune ulterioară. Pentru a incepe:
1. Instalați PyMuPDF executând următoarea linie în terminal:
pip install PyMuPDF
2. Importați PyMuPDF în fișierul dvs. Python utilizând următoarea declarație:
import fitz
3. Pentru a accesa PDF-ul din care doriți să extrageți linkuri, mai întâi trebuie să îl deschideți. Pentru a-l deschide, introduceți următorul rând:
doc = fitz.open("games.pdf")
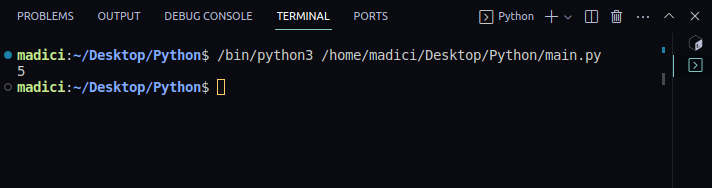
4. După ce ați deschis fișierul PDF, imprimați numărul de pagini din PDF folosind următoarea linie:
print(doc.page_count)
Ieșire:
5
4. Pentru a extrage linkuri dintr-o pagină din fișierul PDF, trebuie să încărcăm pagina din care dorim să extragem linkuri. Pentru a încărca o pagină, introduceți următoarea linie, unde treceți numărul paginii pe care doriți să o încărcați într-o funcție numită load_page()
page = doc.load_page(0)
Pentru a extrage link-uri din prima pagină, trecem 0(zero). Numărarea paginilor începe de la zero la fel ca în structurile de date, cum ar fi matrice și dicționare.
5. Extrageți linkurile din pagină folosind următoarea linie:
links = page.get_links()
Toate link-urile din pagina pe care ați specificat-o, în cazul nostru, pagina 1, vor fi extrase și stocate în variabila numită link-uri
6. Pentru a vedea conținutul variabilei linkuri, imprimați-o astfel:
print(links)
Ieșire:
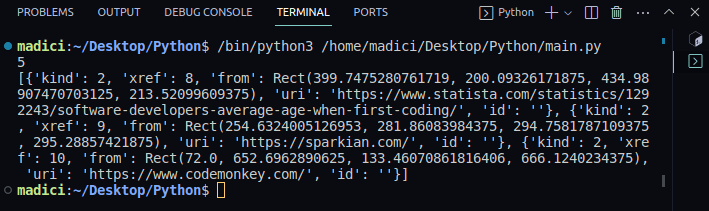
Din rezultatul tipărit, observați că legăturile variabile conțin o listă de dicționare cu perechi cheie-valoare. Fiecare link de pe pagină este reprezentat de un dicționar, cu linkul real stocat sub cheia „uri“
7. Pentru a obține legăturile din lista de obiecte stocate sub legăturile cu numele variabilei, parcurgeți lista folosind o instrucțiune for in și tipăriți legăturile specifice stocate sub cheia uri. Întregul cod care face acest lucru este prezentat mai jos:
import fitz
# Open the PDF file
doc = fitz.open("games.pdf")
# Print out the number of pages
print(doc.page_count)
# load the first page from the PDF
page = doc.load_page(0)
# extract all links from the page and store it under - links
links = page.get_links()
# print the links object
#print(links)
# print the actual links stored under the key "uri"
for obj in links:
print(obj["uri"])
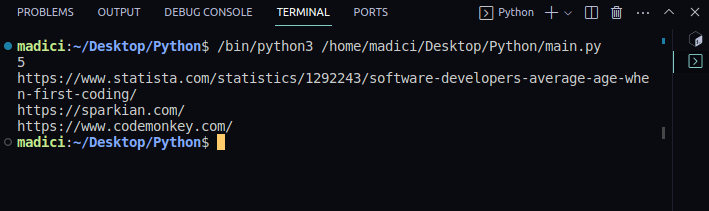
Ieșire:
5 https://www.statista.com/statistics/1292243/software-developers-average-age-when-first-coding/ https://sparkian.com/ https://www.codemonkey.com/
8. Pentru a face codul nostru mai reutilizabil, îl putem refactoriza definind o funcție pentru a extrage toate linkurile dintr-un PDF și o funcție pentru a tipări toate linkurile găsite într-un PDF. În acest fel, puteți apela funcțiile cu orice PDF și veți primi înapoi toate linkurile din PDF. Codul care face acest lucru este prezentat mai jos:
import fitz
# Extract all the links in a PDF document
def extract_link(path_to_pdf):
links = []
doc = fitz.open(path_to_pdf)
for page_num in range(doc.page_count):
page = doc.load_page(page_num)
page_links = page.get_links()
links.extend(page_links)
return links
# print out all the links returned from the PDF document
def print_all_links(links):
for link in links:
print(link["uri"])
# Call the function to extract all the links in a pdf
# all the return links are stored under all_links
all_links = extract_link("games.pdf")
# call the function to print all links in the PDF
print_all_links(all_links)
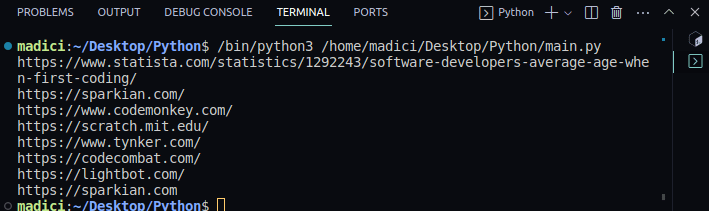
Ieșire:
https://www.statista.com/statistics/1292243/software-developers-average-age-when-first-coding/ https://sparkian.com/ https://www.codemonkey.com/ https://scratch.mit.edu/ https://www.tynker.com/ https://codecombat.com/ https://lightbot.com/ https://sparkian.com
Din codul de mai sus, funcția extract_link() primește un fișier PDF, iterează prin toate paginile din PDF, extrage toate linkurile și le returnează. Rezultatul acestei funcții este stocat într-o variabilă numită all_links
Funcția print_all_links() preia rezultatul extract_link(), iterează prin listă și tipărește toate linkurile reale găsite în PDF-ul pe care l-ați transmis în funcția extract_link().
Pentru a extrage imagini dintr-un PDF, vom folosi în continuare PyMuPDF. Pentru a extrage imagini dintr-un fișier PDF:
1. Importați PyMuPDF, io și PIL. Python Imaging Library (PIL) oferă instrumente care facilitează crearea și salvarea imaginilor, printre alte funcții. io oferă clase pentru manipularea ușoară și eficientă a datelor binare.
import fitz from io import BytesIO from PIL import Image
2. Deschideți fișierul PDF din care doriți să extrageți imagini:
doc = fitz.open("games.pdf")
3. Încărcați pagina din care doriți să extrageți imagini:
page = doc.load_page(0)
4. PyMuPdf identifică imaginile dintr-un fișier PDF folosind un număr de referință încrucișată (xref), care este de obicei un număr întreg. Fiecare imagine dintr-un fișier PDF are un xref unic. Prin urmare, pentru a extrage o imagine dintr-un PDF, trebuie mai întâi să obținem numărul xref care o identifică. Pentru a obține numărul xref al imaginilor dintr-o pagină, folosim funcția get_images() astfel:
image_xref = page.get_images() print(image_xref)
Ieșire:
[(7, 0, 699, 407, 8, 'DeviceRGB', '', 'X7', 'FlateDecode')]
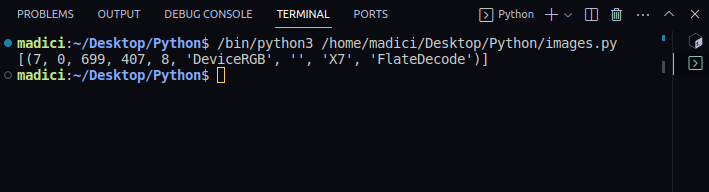
get_images() returnează o listă de tupluri cu informații despre imagine. Deoarece avem o singură imagine pe prima pagină, există un singur tuplu. Primul element din tuplu reprezintă xref-ul imaginii de pe pagină. Prin urmare, xref-ul imaginii de pe prima pagină este 7.
5. Pentru a extrage valoarea xref pentru imagine din lista de tupluri, folosim codul de mai jos:
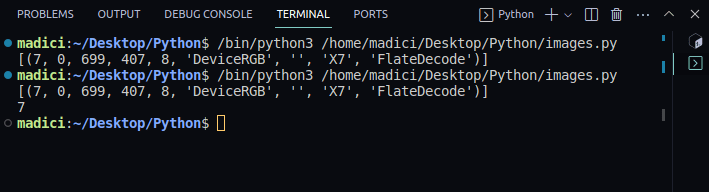
# get xref value of the image xref_value = image_xref[0][0] print(xref_value)
Ieșire:
[(7, 0, 699, 407, 8, 'DeviceRGB', '', 'X7', 'FlateDecode')] 7
6. Deoarece acum aveți xref care identifică o imagine în PDF, puteți extrage imaginea folosind funcția extract_image() astfel:
img_dictionary = doc.extract_image(xref_value)
Această funcție, totuși, nu returnează imaginea reală. În schimb, returnează un dicționar care conține, printre altele, datele de imagine binare ale imaginii și metadatele despre imagine.
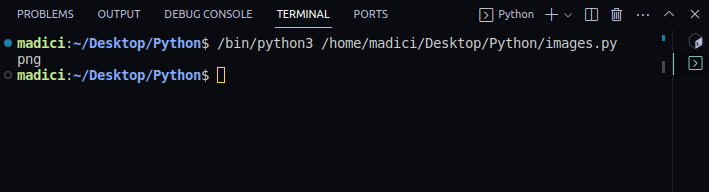
7. Din dicționarul returnat de funcția extract_image(), verificați extensia de fișier a imaginii extrase. Extensia fișierului este stocată sub cheia „ext“:
# get file extenstion img_extension = img_dictionary["ext"] print(img_extension)
Ieșire:
png
8. Extrageți imaginile binare din dicționarul stocat în img_dictionary. Binarele imaginilor sunt stocate sub cheia „imagine”
# get the actual image binary data img_binary = img_dictionary["image"]
9. Creați un obiect BytesIO și inițializați-l cu datele de imagine binare care reprezintă imaginea. Acest lucru creează un obiect asemănător unui fișier care poate fi procesat de bibliotecile Python, cum ar fi PIL, astfel încât să puteți salva imaginea.
# create a BytesIO object to work with the image bytes image_io = BytesIO(img_binary)
10. Deschideți și analizați datele de imagine stocate în obiectul BytesIO numit image_io folosind biblioteca PIL. Acest lucru este important deoarece permite bibliotecii PIL să determine formatul de imagine al imaginii cu care încercați să lucrați, în acest caz, un PNG. După detectarea formatului imaginii, PIL creează un obiect imagine care poate fi manipulat cu funcții și metode PIL, cum ar fi metoda save(), pentru a salva imaginea în stocarea locală.
# open the image using Pillow image = Image.open(image_io)
11. Specificați calea în care doriți să salvați imaginea.
output_path = "image_1.png"
Deoarece calea de mai sus conține doar numele fișierului cu extensia sa, imaginea extrasă va fi salvată în același director cu fișierul Python care conține acest program. Imaginea va fi salvată ca imagine_1.png. Extensia PNG este importantă pentru a se potrivi cu extensia originală a imaginii.
12. Salvați imaginea și închideți obiectul ByteIO.
# save the image image.save(output_path) # Close the BytesIO object image_io.close()
Întregul cod pentru extragerea unei imagini dintr-un fișier PDF este afișat mai jos:
import fitz
from io import BytesIO
from PIL import Image
doc = fitz.open("games.pdf")
page = doc.load_page(0)
# get a cross reference(xref) to the image
image_xref = page.get_images()
# get the actual xref value of the image
xref_value = image_xref[0][0]
# extract the image
img_dictionary = doc.extract_image(xref_value)
# get file extenstion
img_extension = img_dictionary["ext"]
# get the actual image binary data
img_binary = img_dictionary["image"]
# create a BytesIO object to work with the image bytes
image_io = BytesIO(img_binary)
# open the image using PIL library
image = Image.open(image_io)
#specify the path where you want to save the image
output_path = "image_1.png"
# save the image
image.save(output_path)
# Close the BytesIO object
image_io.close()
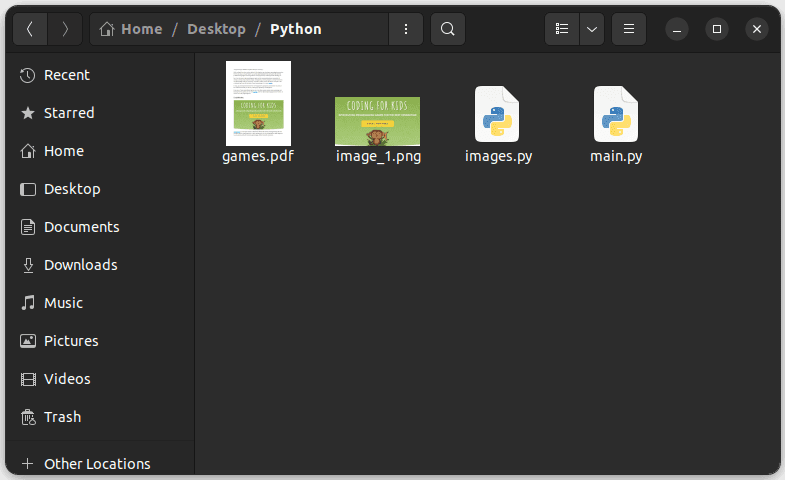
Rulați codul și mergeți la folderul care conține fișierul dvs. Python; ar trebui să vedeți imaginea extrasă numită image_1.png, așa cum se arată mai jos:
Concluzie
Pentru a obține mai multă practică cu extragerea de link-uri, imagini și texte din PDF-uri, încercați să refactorizați codul din exemple pentru a le face mai reutilizabile, așa cum se arată în exemplul de link-uri. În acest fel, va trebui să treceți doar un fișier PDF, iar programul dvs. Python va extrage toate linkurile, imaginile sau textul din întregul PDF. Codare fericită!
De asemenea, puteți explora unele dintre cele mai bune API-uri PDF pentru fiecare nevoie de afaceri.