În vara anului 2023, Meta a introdus Llama 2, o versiune îmbunătățită a modelului său lingvistic. Această iterație nouă vine cu 40% mai multe unități de informație comparativ cu Llama original și o capacitate de procesare a contextului dublată, surclasând semnificativ alte modele open-source. Pentru o utilizare rapidă și facilă, Llama 2 poate fi accesat printr-un API oferit de diverse platforme online. Cu toate acestea, instalarea și rularea directă pe computer oferă o experiență superioară pentru cei care caută control și performanță maximă.
În acest context, am creat un ghid detaliat pentru a vă ajuta să utilizați Text-Generation-WebUI pentru a încărca un model lingvistic Llama 2 direct pe computerul dumneavoastră.
De ce să instalăm Llama 2 local?
Există o serie de motive pentru care utilizatorii preferă să ruleze Llama 2 direct pe propriile computere. Printre acestea se numără preocupările legate de confidențialitate, dorința de personalizare avansată și necesitatea accesului offline. Dacă sunteți un cercetător, un dezvoltator sau un pasionat de inteligență artificială, rularea locală vă oferă controlul necesar pentru a adapta și integra Llama 2 în proiectele dumneavoastră, depășind limitările accesului prin API. În plus, elimină dependența de instrumente AI terțe și protejează datele sensibile de scurgeri către companii sau alte organizații.
Acestea fiind spuse, haideți să trecem la ghidul pas cu pas pentru instalarea locală a Llama 2.
Pentru a simplifica procesul, vom utiliza un program de instalare cu un singur clic pentru Text-Generation-WebUI, instrumentul care ne permite să încărcăm Llama 2 cu o interfață grafică intuitivă. Pentru ca programul să funcționeze corect, trebuie să descărcați Visual Studio 2019 și să instalați componentele necesare.
Descărcați: Visual Studio 2019 (Gratuit)
- Descărcați ediția Community a software-ului.
- Instalați Visual Studio 2019, apoi deschideți aplicația. Aici, bifați caseta „Dezvoltare desktop cu C++” și apăsați „Instalare”.
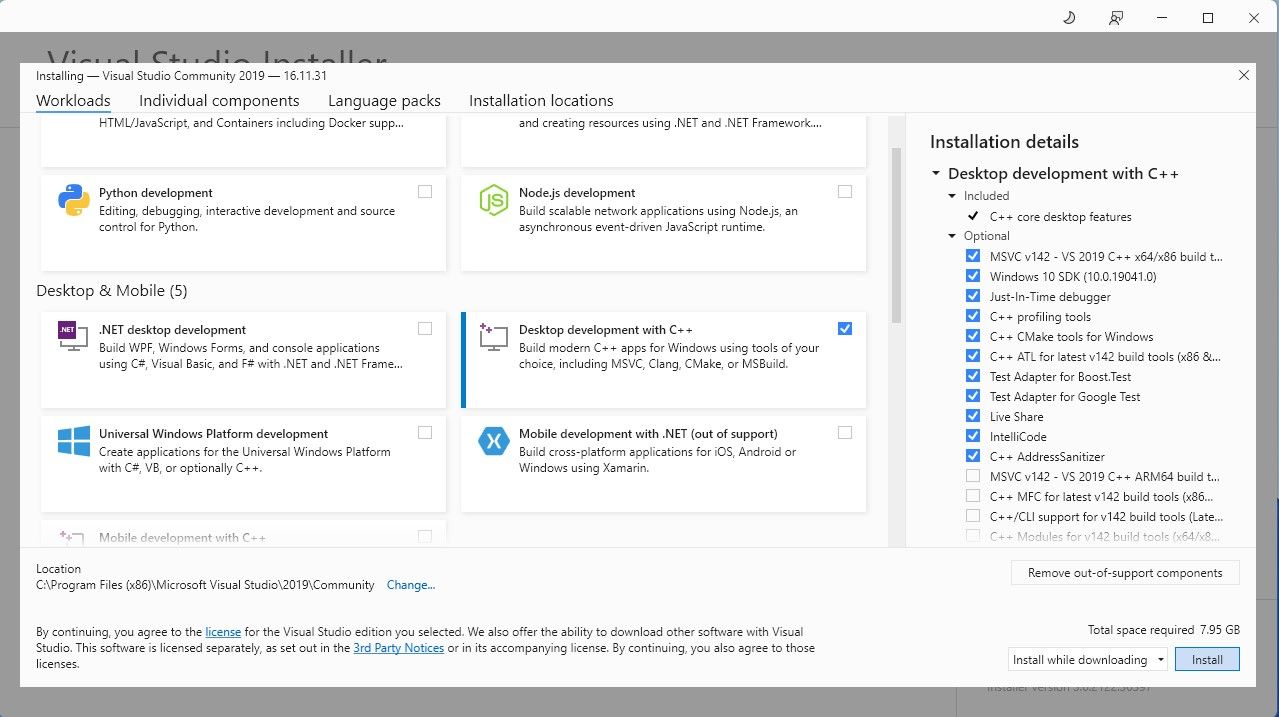
Acum, că aveți instalată componenta de dezvoltare desktop cu C++, este timpul să descărcați programul de instalare Text-Generation-WebUI cu un singur clic.
Pasul 2: Instalați Text-Generation-WebUI
Programul de instalare cu un singur clic pentru Text-Generation-WebUI este un script care creează automat toate directoarele necesare și configurează mediul Conda, împreună cu toate cerințele pentru a rula un model AI.
Pentru a instala scriptul, descărcați programul de instalare cu un singur clic dând clic pe „Cod” > „Descărcați ZIP”.
Descărcați: Text-Generation-WebUI Installer (Gratuit)
- Odată descărcat, dezarhivați fișierul ZIP în locația preferată, apoi deschideți folderul extras.
- În interiorul folderului, derulați în jos și căutați programul de lansare potrivit pentru sistemul dvs. de operare. Rulați programul făcând dublu clic pe scriptul corespunzător.
- Pentru Windows, selectați fișierul batch „start_windows”.
- Pentru MacOS, alegeți scriptul shell „start_macos”.
- Pentru Linux, selectați scriptul shell „start_linux”.
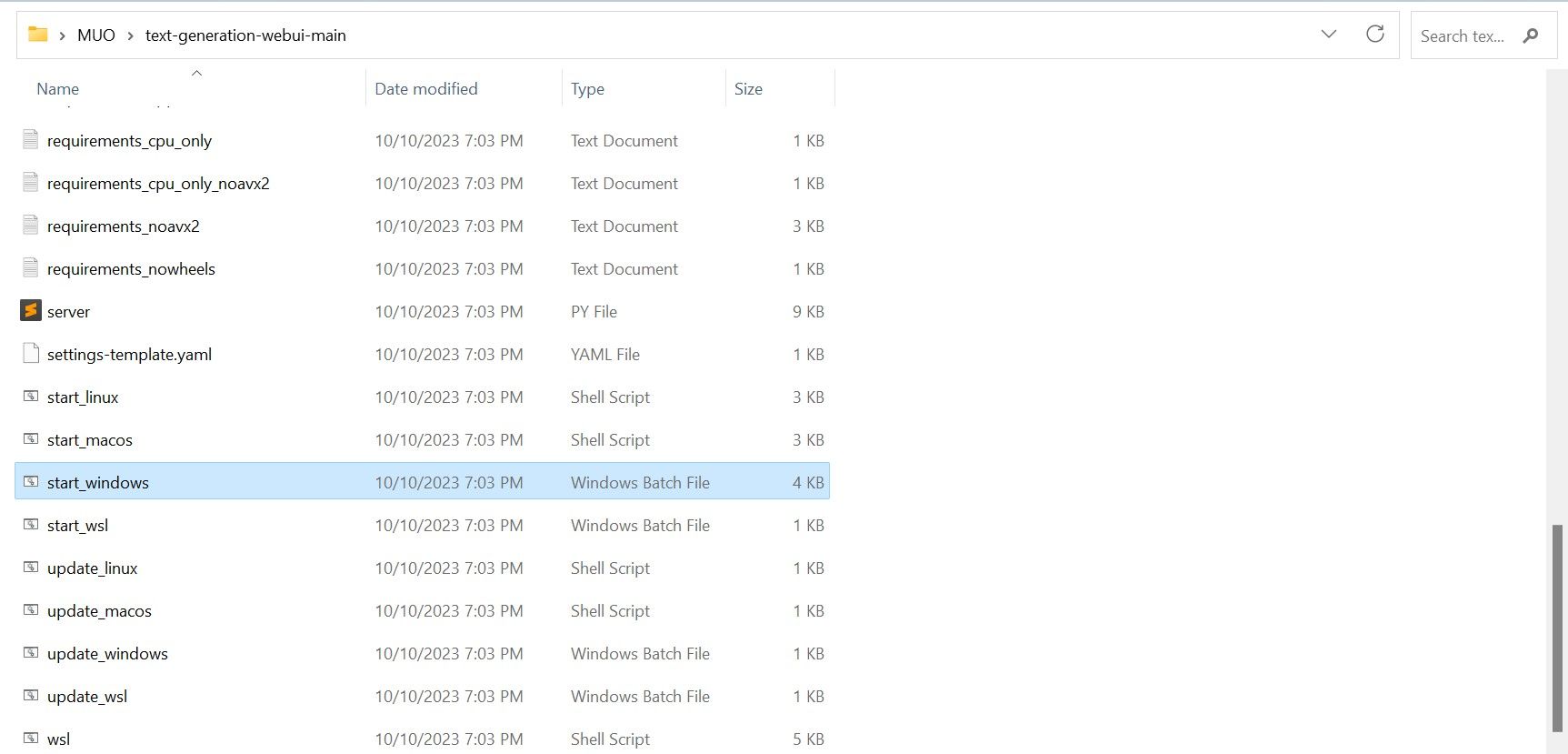
- Este posibil ca antivirusul să genereze o alertă. Acest lucru este normal și este un fals pozitiv. Faceți clic pe „Rulați oricum”.
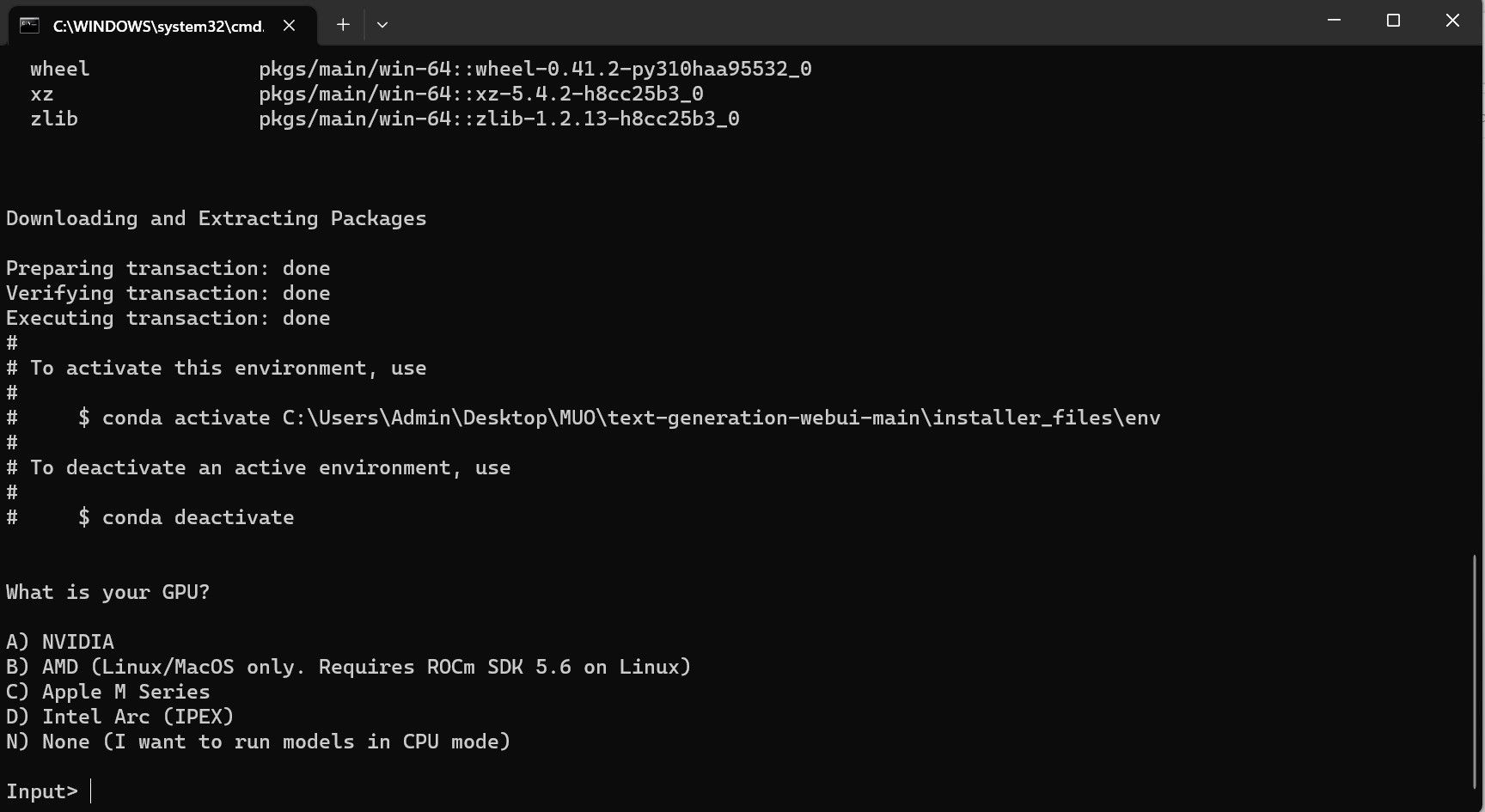
- Se va deschide un terminal și va începe configurarea. Veți fi întrebat ce tip de GPU aveți. Selectați opțiunea corespunzătoare și apăsați „Enter”. Dacă nu aveți placă grafică dedicată, selectați „None (Vreau să rulez modele în modul CPU)”. Rularea în modul CPU este mult mai lentă comparativ cu folosirea unui GPU dedicat.
- Odată configurarea finalizată, puteți lansa Text-Generation-WebUI local. Pentru aceasta, deschideți browserul web preferat și introduceți adresa IP afișată în terminal.
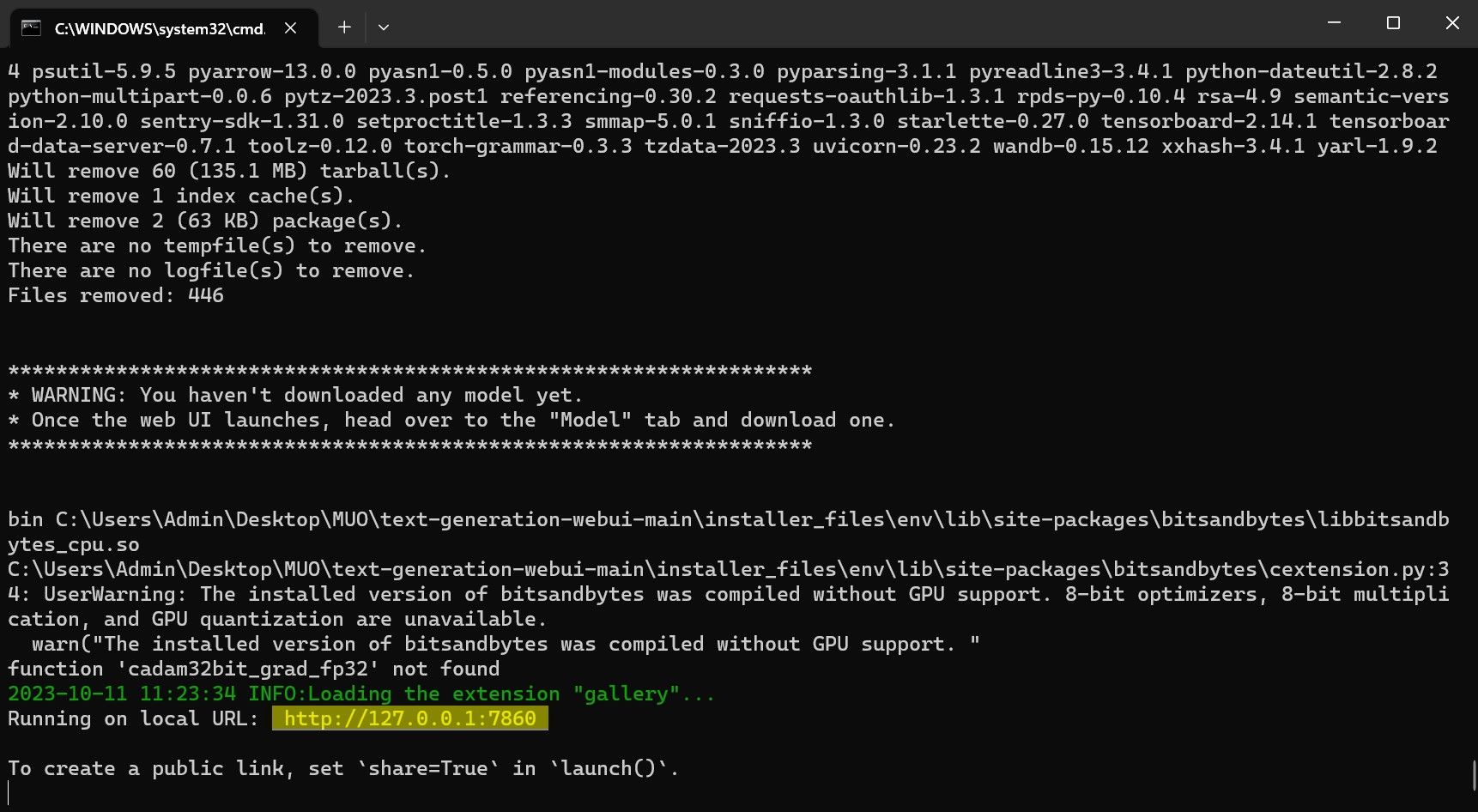
- Interfața WebUI este acum gata de utilizare.
Cu toate acestea, programul este doar un încărcător de modele. În continuare, vom descărca modelul Llama 2 pentru a-l utiliza în încărcătorul nostru de modele.
Pasul 3: Descărcați modelul Llama 2
Alegerea versiunii potrivite a modelului Llama 2 necesită atenție la mai mulți factori, cum ar fi: parametrii, cuantificarea, optimizarea hardware, dimensiunea și modul de utilizare. Toate aceste informații se regăsesc, de obicei, în denumirea modelului.
- Parametri: numărul de parametri utilizați pentru antrenarea modelului. Modelele cu mai mulți parametri oferă performanțe superioare, dar consumă mai multe resurse.
- Utilizare: poate fi standard sau pentru conversații (chat). Modelele de tip chat sunt optimizate pentru a funcționa ca chatbot-uri, în timp ce modelele standard sunt cele generale.
- Optimizare hardware: indică pe ce tip de hardware rulează cel mai bine modelul. GPTQ înseamnă optimizat pentru GPU-uri dedicate, iar GGML este optimizat pentru procesoare (CPU).
- Cuantificare: se referă la precizia datelor modelului. Pentru inferență, o precizie q4 este optimă.
- Dimensiune: se referă la mărimea fișierului modelului.
Rețineți că unele modele pot avea denumiri diferite și nu toate informațiile menționate mai sus pot fi disponibile. Cu toate acestea, convenția de denumire de mai sus este destul de uzuală în biblioteca de modele HuggingFace, deci este util să o înțelegeți.

În exemplul de mai sus, modelul este un model Llama 2 de dimensiune medie, antrenat cu 13 miliarde de parametri, optimizat pentru inferență prin chat, și destinat utilizării pe procesoare (CPU).
Pentru utilizatorii cu GPU dedicat, alegeți un model GPTQ. Pentru cei cu CPU, alegeți GGML. Dacă doriți să interacționați cu modelul ca un chatbot, alegeți un model „chat”. Dacă doriți să experimentați modelul la capacitatea sa maximă, alegeți un model standard. În ceea ce privește numărul de parametri, rețineți că modelele cu mai mulți parametri oferă rezultate mai bune, dar consumă mai multe resurse. Vă recomandăm să începeți cu un model 7B. În ceea ce privește cuantificarea, folosiți q4 deoarece este optimă pentru inferență.
Descărcați: GGML (Gratuit)
Descărcați: GPTQ (Gratuit)
Acum că știți ce tip de model Llama 2 aveți nevoie, descărcați-l.
În cazul meu, rulând pe un ultrabook, voi folosi un model GGML optimizat pentru chat, numit llama-2-7b-chat-ggmlv3.q4_K_S.bin.
După ce descărcarea s-a finalizat, mutați fișierul în directorul text-generation-webui-main > models.
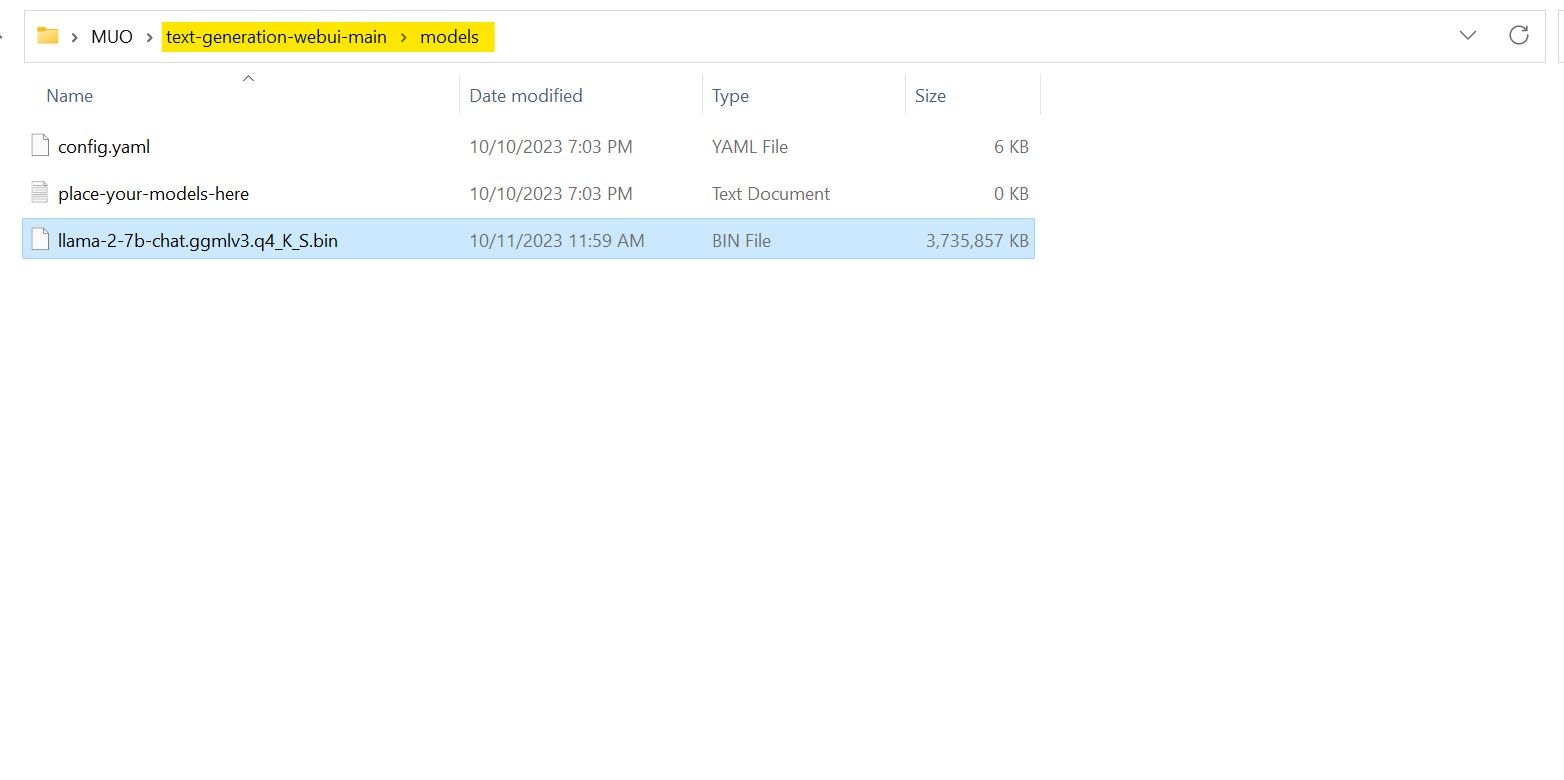
Acum că am descărcat și mutat modelul în directorul corect, este timpul să configurăm încărcătorul de modele.
Pasul 4: Configurați Text-Generation-WebUI
Să începem configurarea.
- Încă o dată, deschideți Text-Generation-WebUI rulând fișierul start_(OS) corespunzător (conform pașilor anteriori).
- În interfața grafică, dați clic pe fila „Model”. Aici, dați clic pe butonul de reîmprospătare din meniul derulant „Model” și selectați modelul descărcat.
- În meniul derulant „Încărcător de modele”, selectați „AutoGPTQ” pentru modelele GPTQ și „ctransformers” pentru modelele GGML. În final, dați clic pe „Încărcare” pentru a încărca modelul.
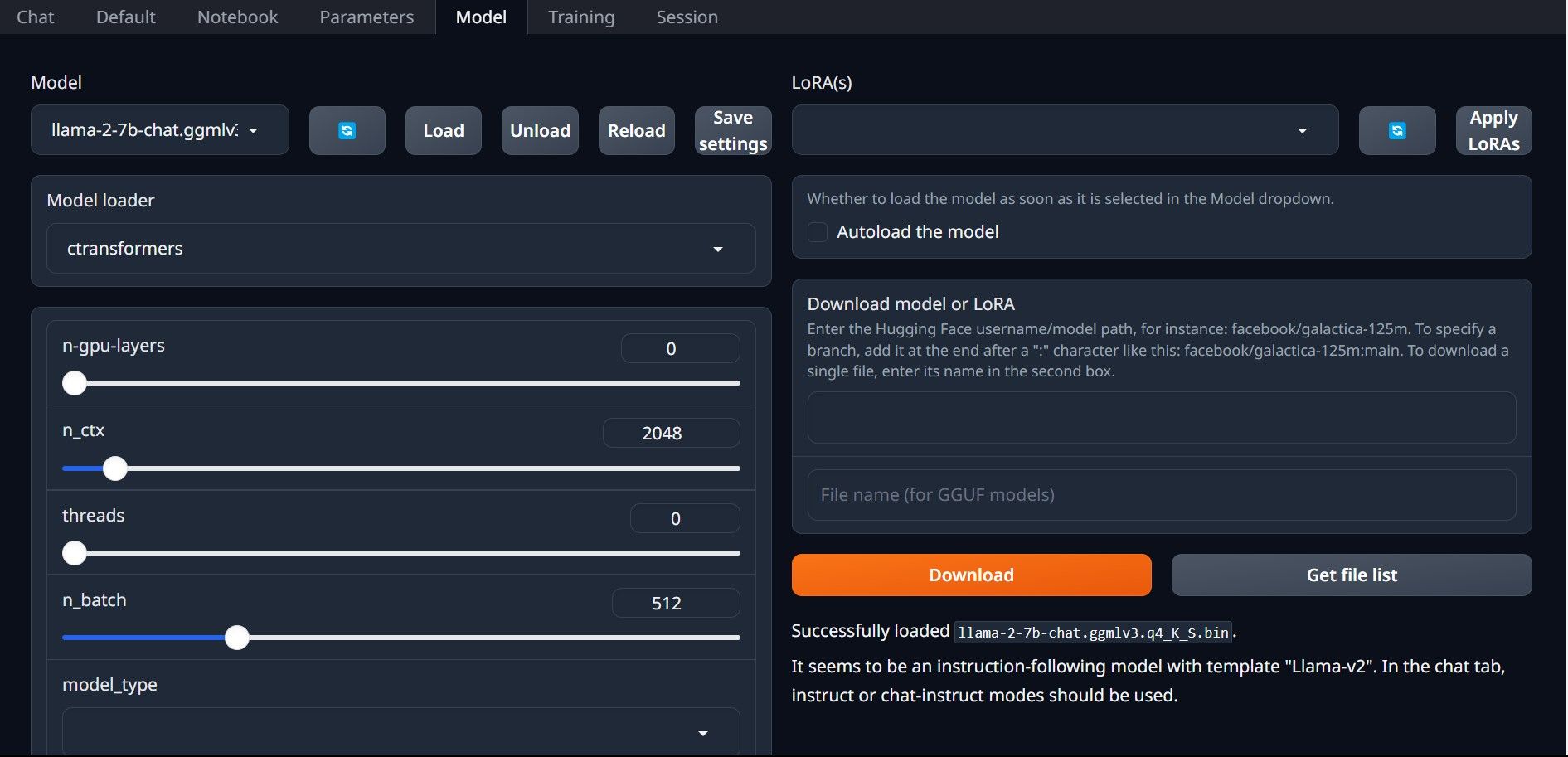
- Pentru a utiliza modelul, dați clic pe fila „Chat” și începeți să testați modelul.
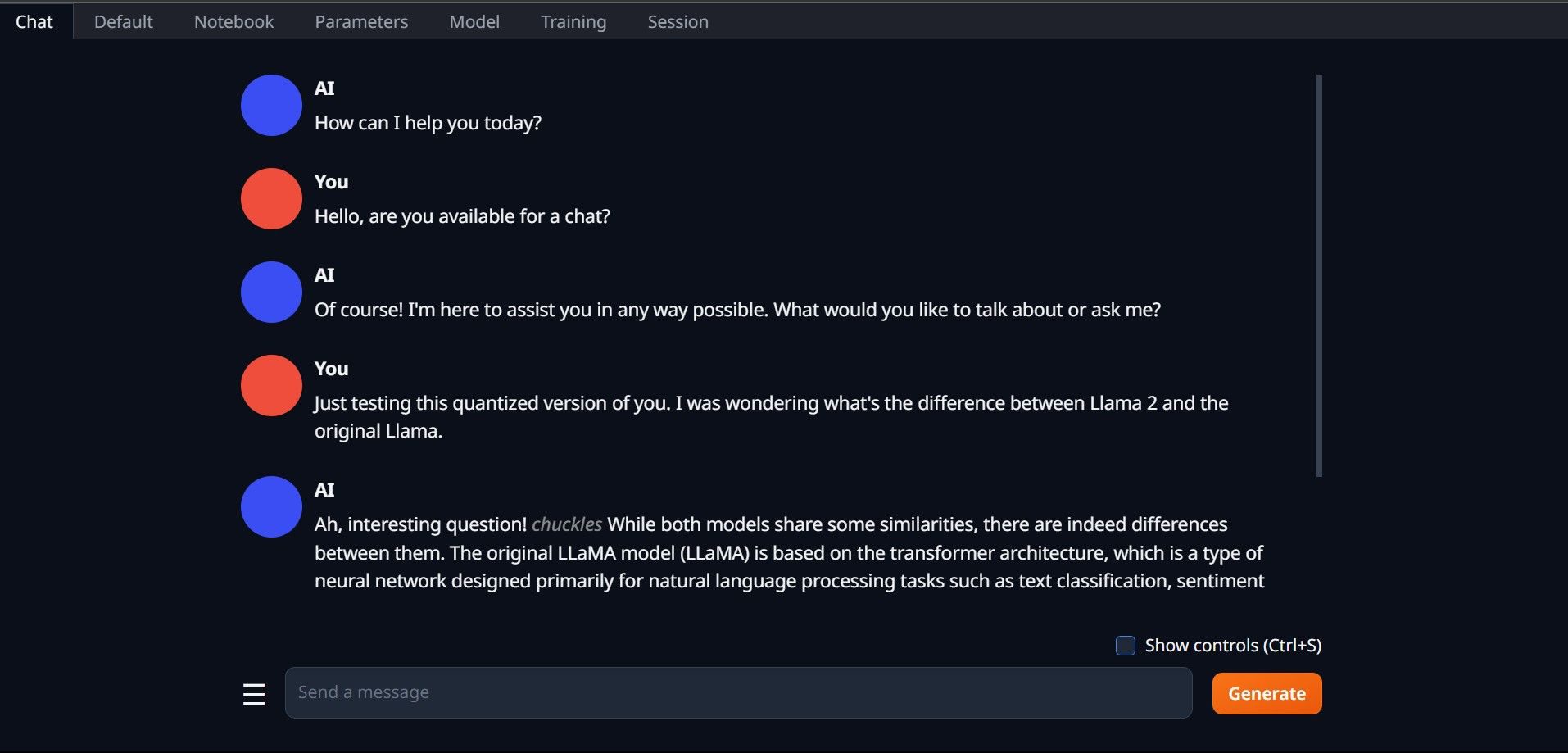
Felicitări, ați instalat cu succes Llama 2 pe computerul dumneavoastră!
Încercați și alte LLM-uri
Acum că știți cum să rulați Llama 2 direct pe computerul dumneavoastră folosind Text-Generation-WebUI, ar trebui să puteți rula și alte modele lingvistice (LLM-uri). Nu uitați de convențiile de denumire a modelelor și că doar versiunile cuantificate ale modelelor (de obicei cu precizia Q4) pot fi încărcate pe computere obișnuite. Multe modele LLM cuantificate sunt disponibile pe HuggingFace. Dacă doriți să explorați și alte modele, căutați „TheBloke” în biblioteca de modele HuggingFace, unde veți găsi multe opțiuni disponibile.