Dacă ai studiat diverse limbaje de programare, cu siguranță ai auzit de analiza textului, cunoscută și ca „parsing”. Acest proces este esențial pentru a gestiona și simplifica date complexe din fișiere. Acest articol își propune să te ghideze prin metodele de analiză a textului, folosind limbaje de programare, și să ofere soluții pentru eventualele erori întâmpinate.
Tehnici de analiză a textului
În acest ghid detaliat, vom explora diverse abordări pentru analiza textului, începând cu o scurtă introducere în acest domeniu.
Ce înseamnă analiza textului?
Înainte de a începe să scriem cod pentru analiza textului, este important să înțelegem conceptele de bază ale limbajelor de programare și codificare.
Procesarea limbajului natural (NLP)
Analiza textului se bazează pe procesarea limbajului natural (NLP), un subdomeniu al inteligenței artificiale. Limbajul Python este adesea folosit în acest context, datorită instrumentelor sale puternice.
Codurile NLP permit computerelor să interpreteze și să prelucreze limbajul uman. Pentru a aplica tehnici de învățare automată (Machine Learning) limbajului, datele textuale nestructurate trebuie transformate în date tabelare structurate. Python este folosit pentru a manipula codul necesar în finalizarea procesului de analiză.
Definiția analizei textului
Analiza textului presupune conversia datelor dintr-un format în altul. Practic, formatul inițial al unui fișier este transformat într-un format diferit, permițând utilizarea acestuia în diverse aplicații.
- Cu alte cuvinte, procesul implică examinarea unui șir sau a unui text și descompunerea acestuia în componente logice prin modificarea formatului fișierului.
- Limbajul Python oferă reguli specifice pentru a finaliza această sarcină de programare. În timpul analizei, secvența de text este divizată în unități mai mici.
De ce este necesară analiza textului?
În continuare, vom examina motivele pentru care este esențial să analizăm textul, o etapă premergătoare învățării tehnicilor de analiză.
- Datele computerizate sunt stocate în diverse formate, variind în funcție de aplicații.
- Formatele de date diferă între aplicații, iar un cod necompatibil poate genera erori.
- Nu există un program universal care să poată procesa date din orice format.
Metoda 1: Utilizarea clasei DataFrame
Clasa DataFrame din Python include funcționalități esențiale pentru analiza textului. Această bibliotecă încorporată oferă coduri necesare pentru a converti date din orice format în altul.
Scurtă descriere a clasei DataFrame
DataFrame este o structură de date complexă, folosită ca instrument de analiză a datelor. Permite analiza cu efort minim.
- Codul este încărcat în Pandas DataFrame pentru a fi analizat în Python.
- Clasa include numeroase pachete oferite de Pandas, utilizate de analiștii de date Python.
- O caracteristică importantă este abstractizarea, unde detaliile interne ale funcțiilor sunt ascunse utilizatorilor. Aceasta se bazează pe NumPy, o bibliotecă Python ce conține funcții și comenzi pentru lucrul cu matrici.
- Clasa DataFrame poate genera o matrice bidimensională cu indici de rând și coloană multipli (MultiIndex). Acești indici facilitează stocarea datelor multidimensionale.
Biblioteca Pandas din Python permite efectuarea operațiunilor SQL sau de tip bază de date, minimizând erorile în analiza textului. Conține instrumente IO pentru analiza fișierelor CSV, MS Excel, JSON, HDF5 și alte formate.
Cum analizăm textul cu clasa DataFrame?
Pentru a analiza textul, urmează acest proces standard utilizând clasa DataFrame:
- Identifică formatul datelor de intrare.
- Alege formatul datelor de ieșire (ex. CSV).
- Scrie tipul de date primitiv (listă sau dict).
Notă: Scrie cod direct într-un DataFrame gol poate fi complex. Pandas facilitează crearea datelor din clasa DataFrame plecând de la aceste tipuri de date, permițând o analiză ușoară a datelor în formatul dorit.
- Analizează datele folosind Pandas DataFrame și afișează rezultatul.
Opțiunea I: Format Standard
Metoda standard de formatare a unui fișier cu un format specific (ex. CSV) este explicată aici.
- Salvează fișierul cu datele local (ex. data.txt).
- Importă fișierul în Pandas și stochează datele într-o variabilă (ex. pd pentru Pandas).
- Importul trebuie să includă detalii despre numele fișierului de intrare, funcția și formatul acestuia.
Notă: Variabila „res” citește datele din „data.txt” folosind Pandas (pd). Formatul este specificat ca CSV.
- Apelează tipul de fișier și afișează textul analizat. De exemplu, comanda „res” va printa rezultatul.
Un exemplu de cod este dat mai jos:
import pandas as pd
res = pd.read_csv('data.txt')
res
În acest caz, dacă „data.txt” conține [1,2,3], rezultatul analizat va fi 1 2 3.
Opțiunea II: Metoda Șirurilor
Dacă textul conține șiruri de caractere sau caractere alfanumerice, putem folosi caracterele speciale (virgule, spații) pentru a separa și analiza textul. Procesul este similar cu operațiile interne cu șiruri. Pentru a remedia erorile de analiză, urmează pașii de mai jos.
- Extrage datele din șir și identifică caracterele speciale care separă textul.
De exemplu, în codul de mai jos, caracterele speciale „,”, și „:” sunt identificate în șirul „my_string”. Fii atent la acest pas pentru a evita erorile.
- Împarte textul individual pe baza poziției caracterelor speciale.
De exemplu, șirul este divizat în valori de date text folosind comanda „split”, bazată pe caracterele speciale.
- Afișează valorile datelor individuale ca text analizat. Folosește funcția „print” pentru a afișa rezultatul.
Exemplu de cod:
my_string = 'Names: Tech, computer'
sfinal = [name.strip() for name in my_string.split(':')[1].split(',')]
print("Names: {}".format(sfinal))
Rezultatul analizat va fi:
Names: ['Tech', 'computer']
Pentru o înțelegere mai bună, folosim o buclă „for” și modificăm codul:
my_string = 'Names: Tech, computer'
s1 = my_string.split(':')
s2 = s1[1]
s3 = s2.split(',')
s4 = [name.strip() for name in s3]
for idx, item in enumerate([s1, s2, s3, s4]):
print("Step {}: {}".format(idx, item))
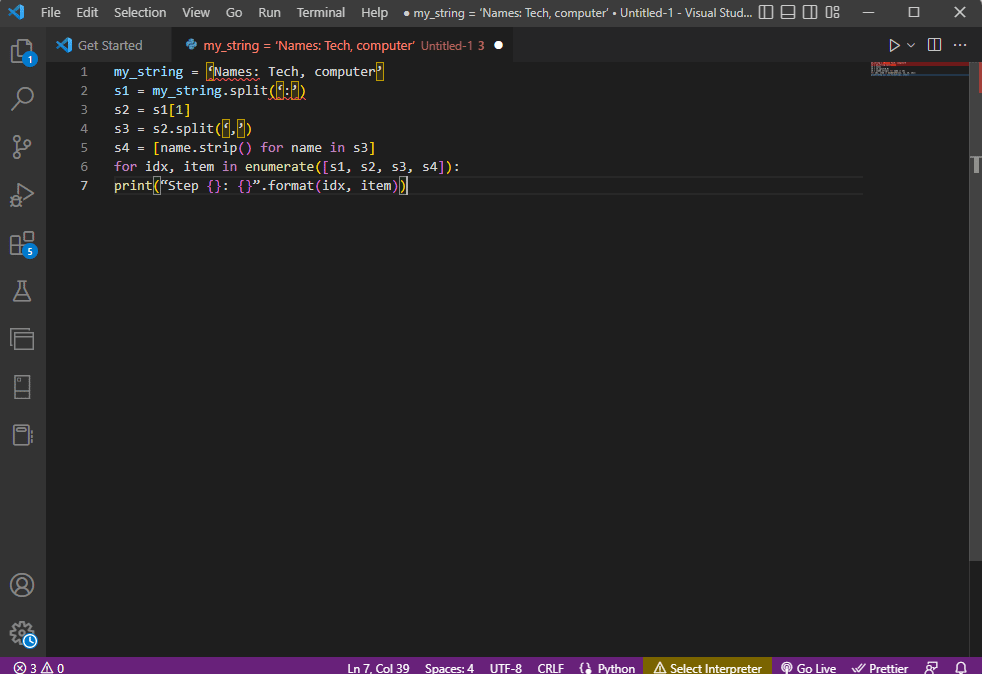
Rezultatul textului analizat pentru fiecare pas este afișat mai jos. Observați cum șirul este separat la pasul 0, iar valorile datelor sunt separate în pașii următori.
Step 0: ['Names', 'Tech, computer'] Step 1: Tech, computer Step 2: [' Tech', ' computer'] Step 3: ['Tech', 'computer']
Opțiunea III: Analiza Fișierelor Complexe
În multe cazuri, fișierele de analizat conțin diverse tipuri și valori de date. Analiza acestor fișiere poate fi dificilă cu metodele anterioare.
Analiza datelor complexe presupune afișarea valorilor într-un format tabelar.
- Titlul sau metadatele sunt afișate în partea de sus a fișierului.
- Variabilele și câmpurile sunt afișate tabelar.
- Valorile datelor formează o cheie compusă.
Înainte de a începe, trebuie să înțelegi câteva concepte de bază. Analiza valorilor de date se bazează pe expresii regulate (Regex).
Modele Regex
Pentru a evita erorile, asigură-te că modelele Regex sunt corecte. Codul de analiză a șirurilor include modele Regex, prezentate mai jos:
- „d”: Cifra zecimală
- „s”: Caracterul spațiu
- „w”: Caracterul alfanumeric
- „+” sau „*”: Potrivire lacomă (unul sau mai multe caractere)
- „a-z”: Litere mici
- „A-Z” sau „a-z”: Litere mari și mici
- „0-9”: Valori numerice
Expresii Regulate
Modulele de expresii regulate sunt parte a bibliotecii Pandas. O expresie greșită poate duce la erori. Regex este un limbaj mic pentru a găsi modele în șiruri. Expresiile regulate sunt șiruri cu sintaxă specială, ce permit potrivirea modelelor din alte șiruri.
Regex este creat în funcție de tipul datelor. Simbolurile folosite sunt listate mai jos:
- „.” : Orice caracter
- „*”: Zero sau mai multe date din expresia anterioară
- „(.*)”: Grupează o parte a expresiei regulate în paranteze
- „n”: Caracter nou la sfârșitul liniei
- „d”: Valoare întreagă între 0 și 9
- „+”: Unul sau mai multe date din expresia anterioară
- „|”: Declarație logică (sau)
RegexObjects
RegexObject este returnat de funcția „compile” și returnează un MatchObject dacă expresia se potrivește cu șirul.
1. MatchObject
Valoarea booleană a unui MatchObject este întotdeauna True. Putem folosi „if” pentru a identifica potrivirile pozitive. Folosind un index, identificăm grupul din obiect.
- „group()” returnează unul sau mai multe subgrupuri de potrivire
- „group(0)” returnează întreaga potrivire
- „group(1)” returnează primul subgrup între paranteze
- Pentru grupuri multiple, folosim o extensie specifică Python, unde definim numele grupului (ex. (?P<group1>regex1) ) și verificăm potrivirea în „regex1”.
2. Metodele MatchObject
MatchObject include două metode de bază: returnează instanța, dacă este găsită, altfel returnează Nimic.
- „match(string)” verifică potrivirea la începutul expresiei regulate
- „search(string)” scanează șirul pentru a găsi o potrivire în expresia regulată
Funcții de Expresii Regulate
Funcțiile Regex sunt linii de cod care execută o funcție specifică.
Notă: Pentru funcții, folosim șiruri brute pentru a evita erorile (adaugă „r” înainte de model).
Funcții comune:
1. re.findall()
Returnează toate modelele găsite într-un șir. Dacă nu se găsește nicio potrivire, returnează o listă goală (ex. șir = re.findall(‘[aeiou]’, regex_filename)).
2. re.split()
Împarte șirul, dacă găsește o potrivire cu un caracter specific. Returnează un șir gol dacă nu se găsește nicio potrivire.
3. re.sub()
Înlocuiește textul potrivit cu o variabilă. Dacă nu se găsește niciun model, returnează șirul original.
4. search()
Caută un model în șir și returnează un obiect match. Dacă nu găsește, nu returnează nicio valoare.
5. re.compile(model)
Compilă modele de expresii regulate într-un RegexObject.
Alte Cerințe
Funcții extra pentru programatori avansați:
- Vizualizarea expresiilor regulate: regexper
- Testarea expresiilor regulate: regex101
Procesul de Analiză a Textului
Pașii de analiză pentru opțiunea complexă:
- Înțelege formatul fișierului. Funcțiile „with open” și „read()” deschid și citesc conținutul fișierului (ex. sample.txt, cu conținutul din file.txt).
- Afișează conținutul fișierului pentru a analiza manual datele și metadatele.
- Importă pachetele necesare pentru analiză (regex și Pandas).
- Definește expresiile regulate folosind modelul regex și funcția regex.
- Urmează exemplul de cod. Funcția „compile()” compilează șirul din grupul „șirnume1”. Funcția „ief_parse_line(line)” verifică potrivirile.
- Scrie un analizor de linii (def_parse_file(filepath)), unde funcția verifică toate potrivirile regex. Metoda „regex search()” caută cheia „rx” în numele fișierului. Orice eroare poate duce la o problemă în analiza textului.
- Scrie un analizor de fișiere (def_parse_file(filepath)). Creează o listă goală (data = []). Verifică potrivirea la fiecare linie (match = _parse_line(line)) și returnează datele exacte.
- Extrage numărul și valoarea pentru tabel cu „line.strip().split(‘,’)”. Creează un dicționar cu „row{}”. Folosește „data.append(row)” pentru a înțelege și analiza datele.
Comanda „data = pd.DataFrame(data)” creează un Pandas DataFrame. Alternativ:
- „data.set_index([‘string’, ‘integer’], inplace=True)” setează indexul tabelului.
- „data = data.groupby(level=data.index.names).first()” consolidează și elimină „NaN”.
- „data = data.apply(pd.to_numeric, errors=’ignore’)” actualizează scorul.
Testează analizatorul utilizând o instrucțiune „if” și afișează datele cu „print(data)”.
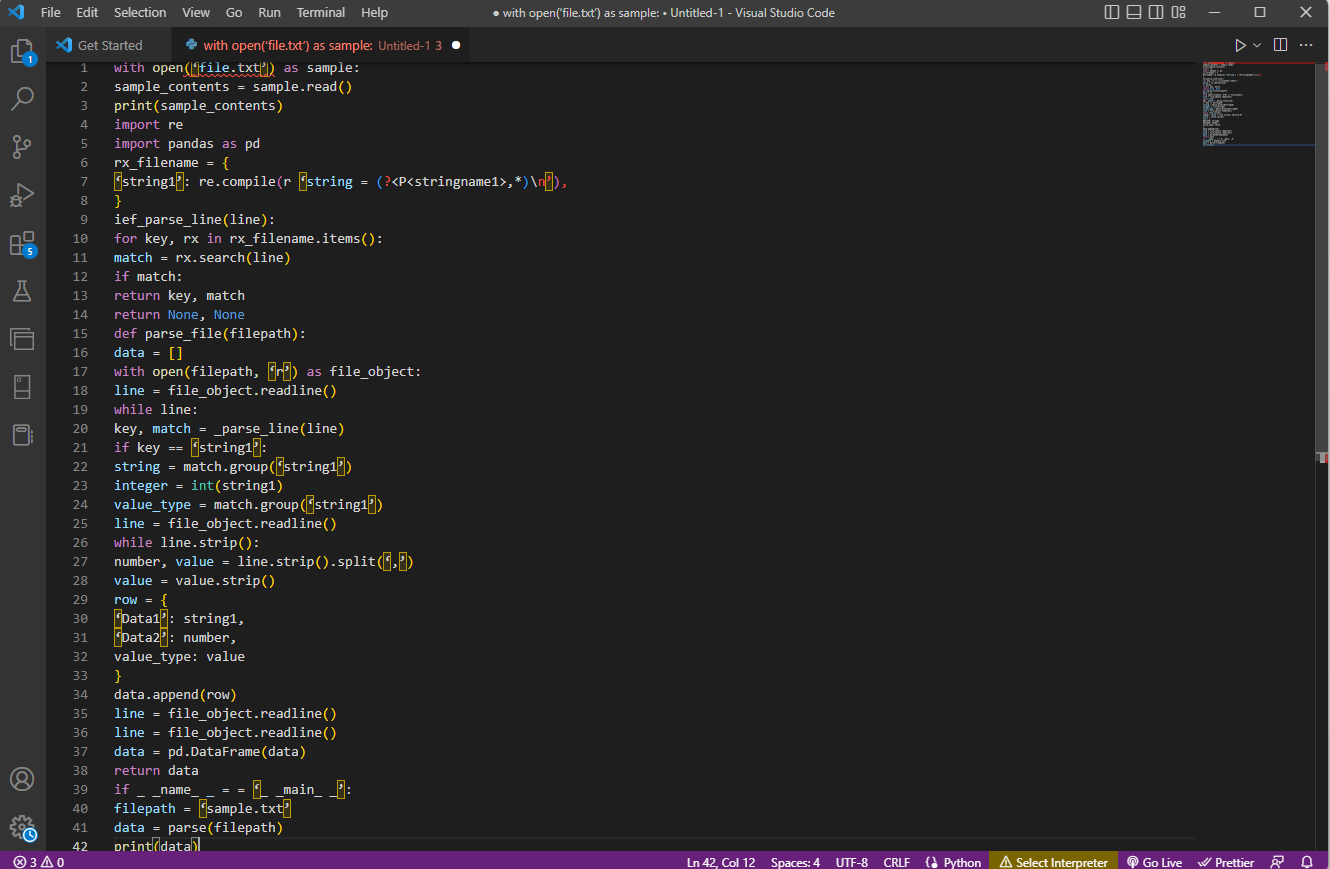
Exemplu de cod:
with open('file.txt') as sample:
sample_contents = sample.read()
print(sample_contents)
import re
import pandas as pd
rx_filename = {
'string1': re.compile(r'string = (?<P<stringname1>.*)n'),
}
ief_parse_line(line):
for key, rx in rx_filename.items():
match = rx.search(line)
if match:
return key, match
return None, None
def parse_file(filepath):
data = []
with open(filepath, 'r') as file_object:
line = file_object.readline()
while line:
key, match = _parse_line(line)
if key == 'string1':
string = match.group('string1')
integer = int(string1)
value_type = match.group('string1')
line = file_object.readline()
while line.strip():
number, value = line.strip().split(',')
value = value.strip()
row = {
'Data1': string1,
'Data2': number,
value_type: value
}
data.append(row)
line = file_object.readline()
line = file_object.readline()
data = pd.DataFrame(data)
return data
if __name__ == '__main__':
filepath = 'sample.txt'
data = parse(filepath)
print(data)
Metoda 2: Tokenizarea Cuvintelor
Tokenizarea împarte textul în unități mai mici (token-uri), bazată pe anumite reguli. Verifică comenzile de tokenizare a cuvintelor din cod. Se pot crea reguli proprii pentru preprocesarea textului (ex. maparea părților de vorbire), căutarea cuvintelor comune, curățarea textului și pregătirea datelor. O tokenizare necorespunzătoare poate cauza erori.
Biblioteca Ntlk
Utilizează biblioteca „nltk”, un set de instrumente puternice pentru joburi NLP. Se descarcă prin „Pip”. Poți folosi și pachetul Anaconda, ce o include implicit.
Forme de Tokenizare
Tokenizarea cuvintelor (la nivel de cuvânt) și a propozițiilor (la nivel de propoziție). Prima imprimă un cuvânt o singură dată, iar a doua, la nivel de propoziție.
Procesul de analiză a textului
- Importă toolkitul „nltk” și metodele de tokenizare.
- Definește un șir și comenzile de tokenizare.
- Afișând șirul, rezultatul va fi „computer este cuvântul.”.
- Cu „word_tokenize()”, fiecare cuvânt este imprimat individual („computer”, „este”, „the”, „cuvânt”, „.”).
- Cu „sent_tokenize()”, propozițiile individuale sunt plasate în ghilimele („calculatorul este cuvântul.”).
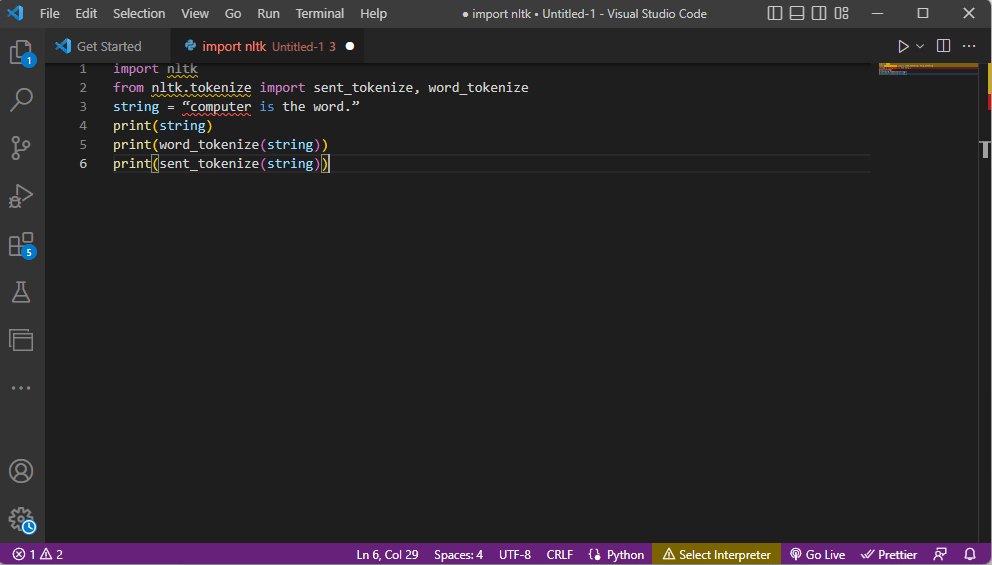
Exemplu de cod:
import nltk from nltk.tokenize import sent_tokenize, word_tokenize string = "computer is the word." print(string) print(word_tokenize(string)) print(sent_tokenize(string))
Metoda 3: Clasa DocParser
Similar clasei DataFrame, DocParser analizează textul folosind calea fișierului.
Procesul de analiză a textului
Instrucțiuni de utilizare:
- Funcția „get_format(nume fișier)” extrage extensia fișierului și o trimite la următoarea funcție (ex. p1 = get_format(filename)).
- Construiește o structură logică cu funcțiile „if-elif-else”.
- Dacă extensia este validă, funcția „get_parser” analizează datele din calea fișierului și returnează un obiect șir.
Notă: Implementează corect această funcție.
- Analiza valorilor de date se face pe baza extensiei. Clasa „parse_txt” sau „parse_docx” generează obiecte șir din tipul dat.
- Poți analiza și alte tipuri de fișiere (parse_pdf, parse_html, parse_pptx).
- Importă valorile datelor și interfața în aplicații. Instanțiază un obiect DocParser. Acest lucru trebuie făcut cu atenție pentru a evita erorile.
Metoda 4: Instrumentul Parse Text
Extrage date din variabile și le mapează cu altele. Funcționează independent de alte instrumente și folosește platforma BPA. Accesează Instrumentul de analiză a textului online.
Metoda 5: TextFieldParser (Visual Basic)
TextFieldParser analizează fișiere mari structurate și delimitate. Poate utiliza fișiere jurnal sau informații vechi de bază de date. Se aseamănă cu repetarea codului într-un fișier text și este folosit pentru a extrage câmpuri, similar manipulării șirurilor. Tokenizează șiruri și câmpuri delimitate, folosind un delimitator (virgulă, spațiu).
Funcții de Analiză a Textului
Funcții folosite în această metodă:
- „SetDelimiters”: Definește un delimitator (ex. testReader.SetDelimiters(vbTab) – tab).
- „SetFieldWidths”: Setează lățimea unui câmp la o valoare întreagă.
- „TextFieldType”: Setează tipul câmpului la „Microsoft.VisualBasic.FileIO.FieldType.FixedWidth”.
Metode pentru a găsi MatchObject
- „ReadFields”: Definește formatul și parcurge fișierul, procesând fiecare linie.
- „PeekChars”: Verifică fiecare câmp înainte de a-l citi și definește formate multiple.
Dacă un câmp nu se potrivește formatului, este returnată o excepție „MalformedLineException”.
Sfat Profesional: Analiza Textului în MS Excel
Poți utiliza MS Excel pentru a crea fișiere delimitate. Folosește pentru a verifica rezultatele analizate.
1. Selectează și copiază (Ctrl + C) valorile din fișier.
2. Deschide Excel.
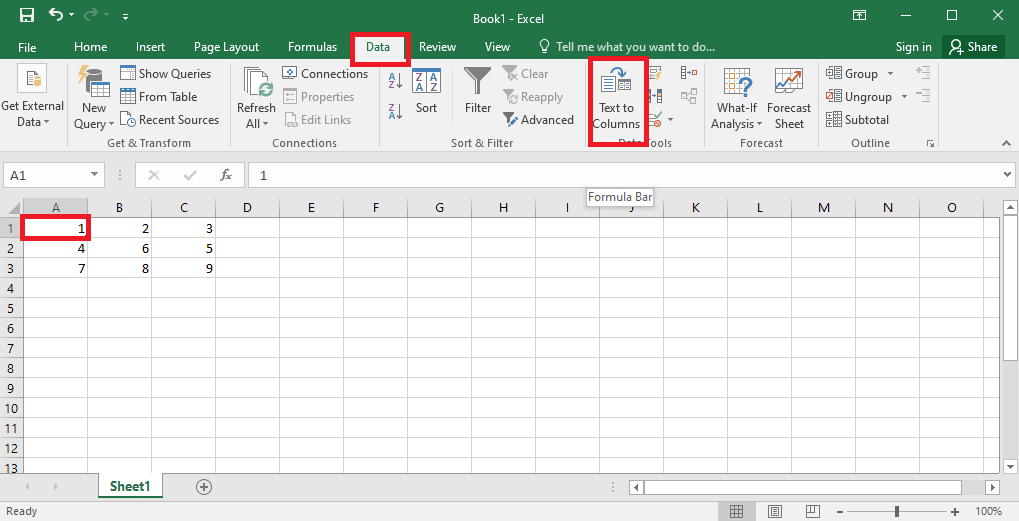
3. Dă click pe celula A1 și lipește (Ctrl + V) textul.
4. Selectează celula A1, mergi la „Date” și selectează „Text în coloane”.
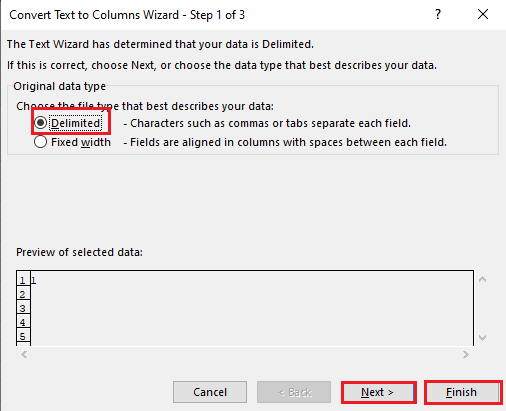
5A. Alege „Delimitat” dacă folosești o virgulă sau spațiu tab ca separator și dă click pe „Următorul” și „Terminare”.
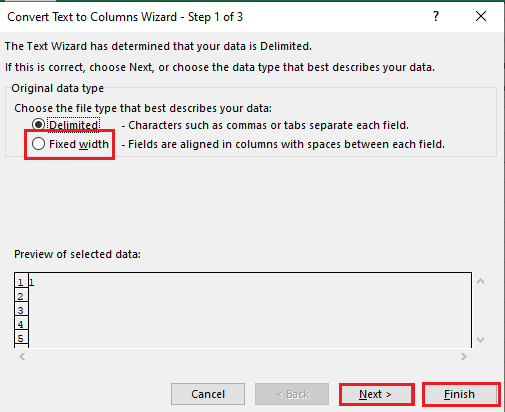
5B. Alege „Lățime fixă”, atribuie o valoare pentru separator și dă click pe „Următorul” și „Terminare”.
Cum Remediem Erorile de Analiză
Eroarea „Parse error: there was a problem parsing the package” apare pe dispozitivele Android când aplicația nu se instalează corect. Apare și la rularea unei aplicații terță parte.
Eroarea poate apărea dacă o listă de vectori de caractere formează un model liniar pentru calculul valorilor de date: Error in parse(text = x, keep.source = FALSE):<text>:2.0:unexpected end of input 1:OffenceAgainst ~ ^.
Pentru a afla mai multe despre cauze și remedii, poți citi articolul despre cum să remediezi erorile de analiză pe Android.
Alte soluții:
- Redescarcă fișierul .apk sau restaurează numele fișierului.
- Restabilește modificările din „AndroidManifest.xml”, dacă ai cunoștințe de programare.
***
Acest articol te ajută să înțelegi cum să analizezi textul și cum să remediezi erorile. Spune-ne ce metodă te-a ajutat și care este metoda ta preferată de analiză. Împărtășește-ne sugestiile și întrebările în secțiunea de comentarii.