
Depozitul de date. Data Lake. Lakehouse. Dacă niciunul dintre aceste cuvinte nu rezonează cu tine măcar puțin, atunci meseria ta nu este în mod clar legată de date.
Cu toate acestea, aceasta ar fi o premisă destul de nerealistă, deoarece astăzi totul este legat de date, pare. Sau cum le place liderilor corporativi să o descrie:
- Afaceri centrate pe date și bazate pe date.
- Date oriunde, oricând, oricum.
Cuprins
Cel mai important activ
Se pare că datele au devenit cel mai valoros activ al din ce în ce mai multe companii. Îmi amintesc că marile corporații au generat întotdeauna o mulțime de date, gândiți-vă la terabytes de date noi în fiecare lună. Asta a fost încă acum 10-15 ani. Dar acum, puteți genera cu ușurință acea cantitate de date în câteva zile. S-ar întreba dacă este cu adevărat necesar, chiar dacă este un conținut pe care cineva îl va folosi. Și da, cu siguranță nu este 😃.
Nu tot conținutul va fi de folos, iar unele părți nici măcar o singură dată. Adesea am asistat în prima linie la modul în care companiile generau o cantitate enormă de date doar pentru a deveni inutile după o încărcare reușită.
Dar asta nu mai este relevant. Stocarea datelor – acum fiind în cloud – este ieftină, sursele de date cresc exponențial și astăzi nimeni nu poate prezice de ce va avea nevoie un an mai târziu, odată ce noile servicii vor fi integrate în sistem. În acel moment, chiar și datele vechi pot deveni valoroase.
Prin urmare, strategia este de a stoca cât mai multe date posibil. Dar și într-o formă cât mai eficientă. Astfel că datele pot fi salvate nu numai eficient, ci și interogate, reutilizate sau transformate și distribuite în continuare.
Să aruncăm o privire la trei moduri native de a realiza acest lucru în AWS:
- Baza de date Athena – modalitate ieftină și eficientă, deși simplă de a crea un lac de date în cloud.
- Redshift Database – o versiune serioasă în cloud a unui depozit de date care are potențialul de a înlocui majoritatea soluțiilor actuale on-premise, incapabil să ajungă din urmă cu creșterea exponențială a datelor.
- Databricks – o combinație de lac de date și depozit de date într-o singură soluție, cu un bonus pe deasupra.
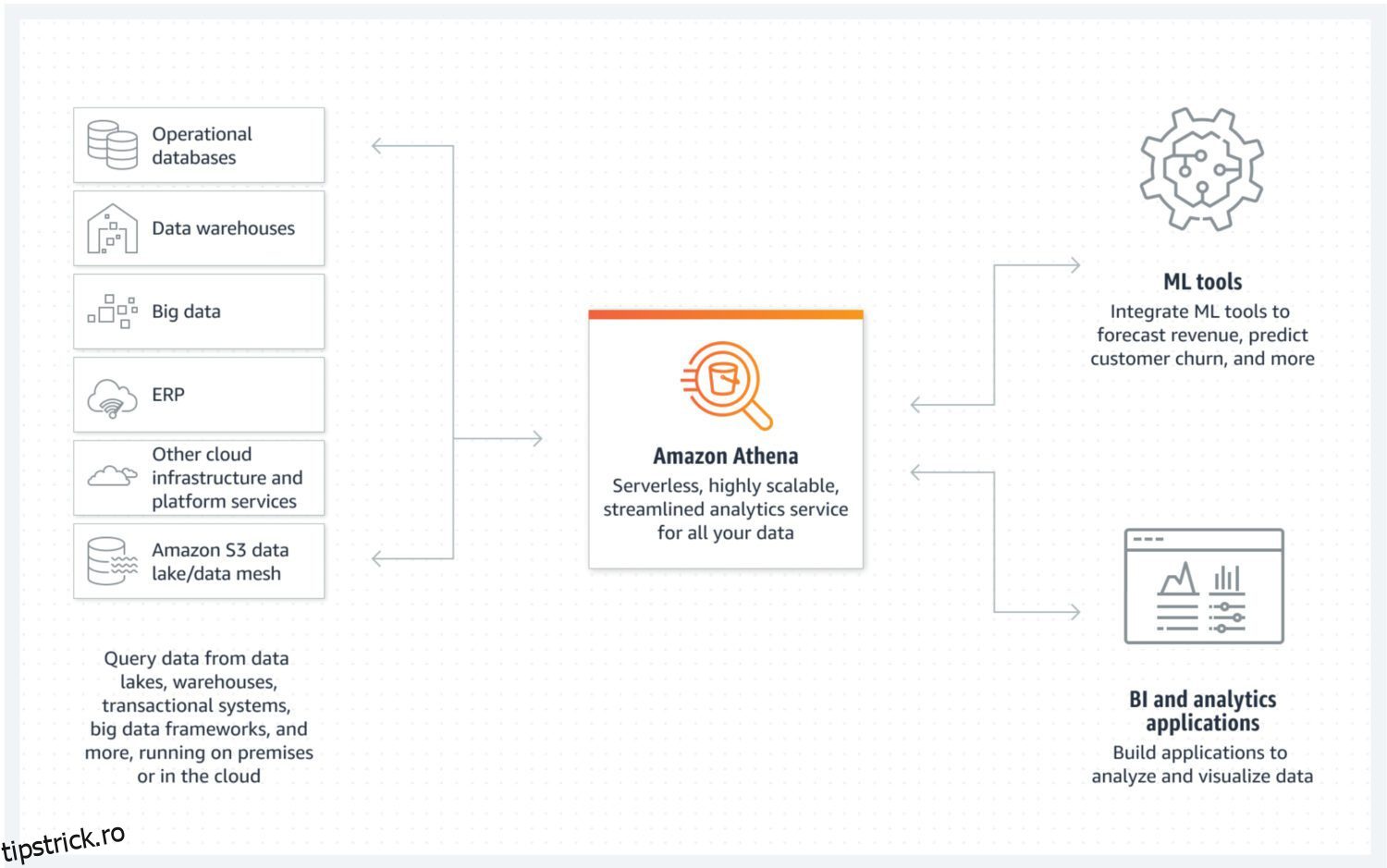
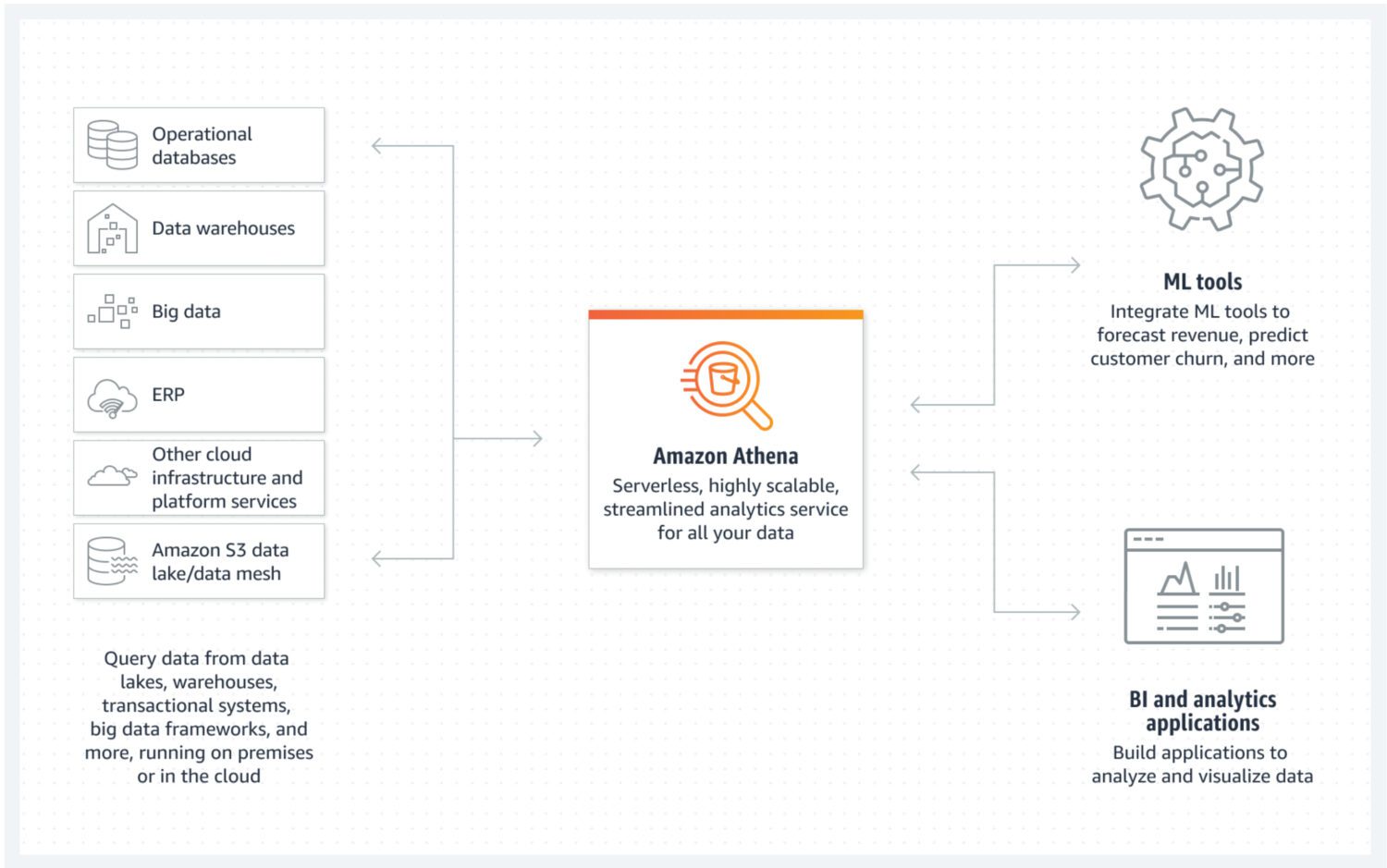
Data Lake de AWS Athena
 Sursa: aws.amazon.com
Sursa: aws.amazon.com
Lacul de date este un loc în care puteți stoca datele primite într-o formă nestructurată, semistructurată sau structurată într-un mod rapid. În același timp, nu vă așteptați ca aceste date să fie modificate odată ce sunt stocate. În schimb, vrei să fie cât mai atomice și imuabile posibil. Numai acest lucru va asigura cel mai mare potențial de reutilizare în etapele ulterioare. Dacă ați pierde această proprietate atomică a datelor imediat după prima încărcare într-un lac de date, nu există nicio modalitate de a obține din nou aceste informații pierdute.
AWS Athena este o bază de date cu stocare direct pe compartimente S3 și fără clustere de servere care rulează în fundal. Asta înseamnă că este un serviciu de data lake cu adevărat ieftin. Formatele de fișiere structurate, cum ar fi fișierele cu parchet sau cu valori separate prin virgulă (CSV), mențin organizarea datelor. Bucket-ul S3 deține fișierele, iar Athena se referă la ele ori de câte ori procesele selectează datele din baza de date.
Athena nu acceptă diverse funcționalități considerate standard, cum ar fi declarațiile de actualizare. Acesta este motivul pentru care trebuie să priviți Athena ca pe o opțiune foarte simplă. Pe de altă parte, vă ajută să preveniți modificarea lacului de date atomice pur și simplu pentru că nu puteți 😐.
Acceptă indexarea și partiționarea, ceea ce îl face utilizabil pentru executarea eficientă a instrucțiunilor select și pentru crearea de bucăți de date separate logic (de exemplu, separate prin dată sau coloane cheie). De asemenea, se poate scala pe orizontală foarte ușor, deoarece acest lucru este la fel de complex ca și adăugarea de noi găleți la infrastructură.

Argumente pro şi contra
Beneficiile de luat în considerare:
- Faptul că Athena este ieftină (constând doar din găleți S3 și costuri de utilizare SQL pe utilizare) reprezintă cel mai semnificativ avantaj. Dacă doriți să construiți un lac de date accesibil în AWS, acesta este.
- Ca serviciu nativ, Athena se poate integra cu ușurință cu alte servicii AWS utile, cum ar fi Amazon QuickSight pentru vizualizarea datelor sau AWS Glue Data Catalog pentru a crea metadate structurate persistente.
- Cel mai bun pentru a rula interogări ad-hoc pe o cantitate mare de date structurate sau nestructurate fără a menține o întreagă infrastructură în jurul acesteia.
Dezavantajele de luat în considerare:
- Athena nu este deosebit de eficient în returnarea rapidă a interogărilor complexe de selecție, mai ales dacă interogările nu urmează ipotezele modelului de date privind modul în care ați proiectat să solicitați datele de la lacul de date.
- Acest lucru îl face, de asemenea, mai puțin flexibil în ceea ce privește potențialele schimbări viitoare ale modelului de date.
- Athena nu acceptă funcționalități avansate suplimentare din cutie și, dacă doriți ca ceva specific să facă parte din serviciu, trebuie să îl implementați pe deasupra.
- Dacă vă așteptați la utilizarea datelor lacului de date într-un strat de prezentare mai avansat, de multe ori singura alegere este să îl combinați cu un alt serviciu de bază de date mai potrivit pentru acest scop, cum ar fi AWS Aurora sau AWS Dynamo DB.
Scop și caz de utilizare în lumea reală
Alegeți Athena dacă ținta este crearea unui lac de date simplu fără funcționalități avansate de tip depozit de date. Deci, de exemplu, dacă nu vă așteptați la interogări de analiză serioase, de înaltă performanță, care rulează în mod regulat peste lacul de date. În schimb, prioritatea este a avea un grup de date imuabile cu extensie ușoară de stocare a datelor.
Nu mai trebuie să vă faceți griji prea mult din cauza lipsei de spațiu. Chiar și costul stocării compartimentului S3 poate fi redus și mai mult prin implementarea unei politici privind ciclul de viață al datelor. Acest lucru înseamnă, practic, mutarea datelor în diferite tipuri de compartimente S3, direcționate mai mult spre scopuri de arhivare, cu timpi de returnare mai lenți, dar costuri mai mici.
O caracteristică excelentă a Athena este că creează automat un fișier format din date care fac parte dintr-un rezultat al interogării dvs. SQL. Apoi puteți lua acest fișier și îl puteți utiliza în orice scop. Deci, este o opțiune bună dacă aveți multe servicii lambda care procesează în continuare datele în mai mulți pași. Fiecare rezultat lambda va fi automat rezultatul într-un format de fișier structurat ca intrare pregătită pentru procesarea ulterioară.
Athena este o opțiune bună în situațiile în care o cantitate mare de date brute vine în infrastructura dvs. de cloud și nu trebuie să procesați acestea în momentul încărcării. Asta înseamnă că tot ce ai nevoie este stocarea rapidă în cloud într-o structură ușor de înțeles.
Un alt caz de utilizare ar fi crearea unui spațiu dedicat pentru arhivarea datelor pentru un alt serviciu. Într-un astfel de caz, Athena DB ar deveni un loc de rezervă ieftin pentru toate datele de care nu aveți nevoie în acest moment, dar s-ar putea schimba în viitor. În acest moment, veți ingera doar datele și le veți trimite mai departe.
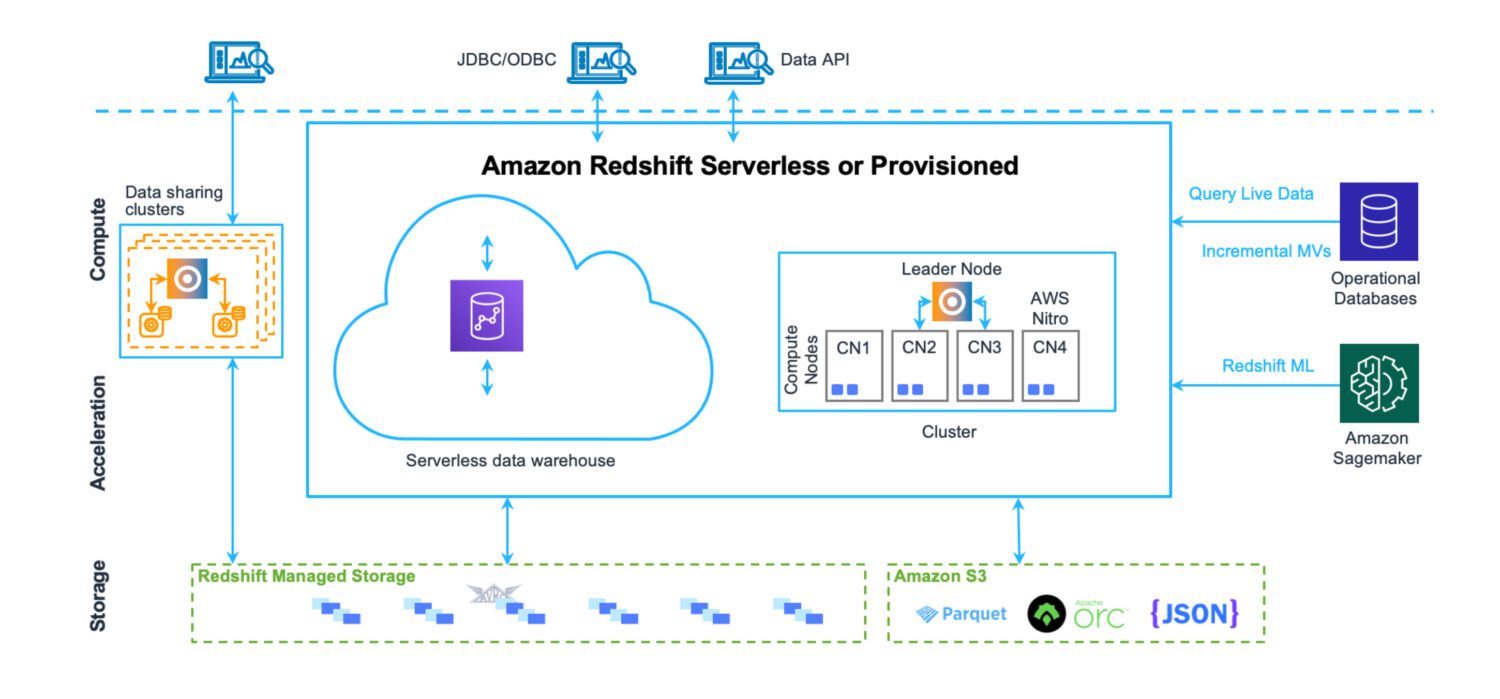
Data Warehouse de la AWS Redshift
 Sursa: aws.amazon.com
Sursa: aws.amazon.com
Un depozit de date este un loc în care datele sunt stocate într-un mod foarte structurat. Ușor de încărcat și extras. Intenția este de a rula un număr mare de interogări foarte complexe, unind multe tabele prin îmbinări complexe. Există diferite funcții analitice pentru a calcula diverse statistici asupra datelor existente. Scopul final este de a extrage previziuni și fapte viitoare care să fie valorificate în afaceri în viitor, folosind datele existente.
Redshift este un sistem de depozit de date cu drepturi depline. Cu servere de cluster de reglat și scalat – orizontal și vertical și un sistem de stocare a bazei de date optimizat pentru returnări rapide de interogări complexe. Deși astăzi puteți rula Redshift și în modul serverless. Nu există fișiere pe S3 sau ceva similar. Acesta este un server de cluster de baze de date standard cu propriul format de stocare.
Are instrumente de monitorizare a performanței disponibile imediate, alături de valori personalizabile ale tabloului de bord pe care le puteți utiliza și urmări pentru a ajusta performanța pentru cazul dvs. de utilizare. Administrația este accesibilă și prin tablouri de bord separate. Este nevoie de ceva efort pentru a înțelege toate caracteristicile și setările posibile și modul în care acestea influențează clusterul. Dar totuși, nu este nicăieri la fel de complex precum administrarea serverelor Oracle în cazul soluțiilor on-premise.
Chiar dacă există diverse limite AWS în Redshift care stabilesc anumite limite ale modului de utilizare zilnică (de exemplu, limite stricte privind numărul de utilizatori sau sesiuni active simultane dintr-un cluster de baze de date), faptul că operațiunile sunt executat foarte rapid ajută la rezolvarea acestor limite într-o anumită măsură.

Argumente pro şi contra
Beneficiile de luat în considerare:
- Serviciu nativ de depozit de date în cloud AWS care este ușor de integrat cu alte servicii.
- Un loc central pentru stocarea, monitorizarea și ingerarea diferitelor tipuri de surse de date din sisteme de surse foarte diferite.
- Dacă ați dorit vreodată să aveți un depozit de date fără server, fără infrastructura pentru a-l întreține, acum puteți.
- Optimizat pentru analiză și raportare de înaltă performanță. Spre deosebire de o soluție de lac de date, există un model de date relațional puternic pentru stocarea tuturor datelor primite.
- Motorul de baze de date Redshift își are originea în PostgreSQL, care asigură o compatibilitate ridicată cu alte sisteme de baze de date.
- Instrucțiuni COPY și UNLOAD foarte utile pentru încărcarea și descărcarea datelor din și către găleți S3.
Dezavantajele de luat în considerare:
- Redshift nu acceptă o cantitate mare de sesiuni active simultane. Sesiunile vor fi suspendate și procesate secvenţial. Deși s-ar putea să nu fie o problemă în majoritatea cazurilor, deoarece operațiunile sunt foarte rapide, este un factor limitativ în sistemele cu mulți utilizatori activi.
- Chiar dacă Redshift acceptă o mulțime de funcționalități cunoscute anterior din sistemele Oracle mature, încă nu este la același nivel. Este posibil ca unele dintre caracteristicile așteptate să nu fie acolo (cum ar fi declanșatoarele DB). Sau Redshift le suportă într-o formă destul de limitată (cum ar fi vederile materializate).
- Ori de câte ori aveți nevoie de o lucrare de procesare a datelor personalizată mai avansată, trebuie să o creați de la zero. De cele mai multe ori, utilizați limbajul de cod Python sau Javascript. Nu este la fel de firesc ca PL/SQL în cazul sistemului Oracle, unde chiar și funcția și procedurile folosesc un limbaj foarte asemănător interogărilor SQL.
Scop și caz de utilizare în lumea reală
Redshift poate fi magazinul dvs. central pentru toate sursele de date diferite care trăiau anterior în afara cloudului. Este un înlocuitor valid pentru soluțiile anterioare de depozit de date Oracle. Deoarece este și o bază de date relațională, migrarea de la Oracle este chiar o operațiune destul de simplă.
Dacă aveți soluții de depozit de date existente în multe locuri care nu sunt cu adevărat unificate în ceea ce privește abordarea, structura sau un set predefinit de procese comune pentru a rula deasupra datelor, Redshift este o alegere excelentă.
Vă va oferi doar o oportunitate de a îmbina toate diferitele sisteme de depozit de date din diferite locuri și țări sub un singur acoperiș. Le puteți separa în continuare pe țară, astfel încât datele să rămână în siguranță și accesibile numai celor care au nevoie de ele. Dar, în același timp, vă va permite să construiți o soluție de depozit unificată care să acopere toate datele corporative.
Un alt caz ar putea fi dacă ținta este construirea unei platforme de depozit de date cu suport extins de autoservicii. Îl puteți înțelege ca un set de procesare pe care utilizatorii individuali de sistem le pot construi. Dar, în același timp, nu fac niciodată parte din soluția comună a platformei. Aceasta înseamnă că astfel de servicii vor rămâne accesibile numai creatorului sau grupului de persoane definit de creat. Ele nu vor afecta în niciun fel restul utilizatorilor.
Verificați comparația noastră dintre Datalake și Datawarehouse.
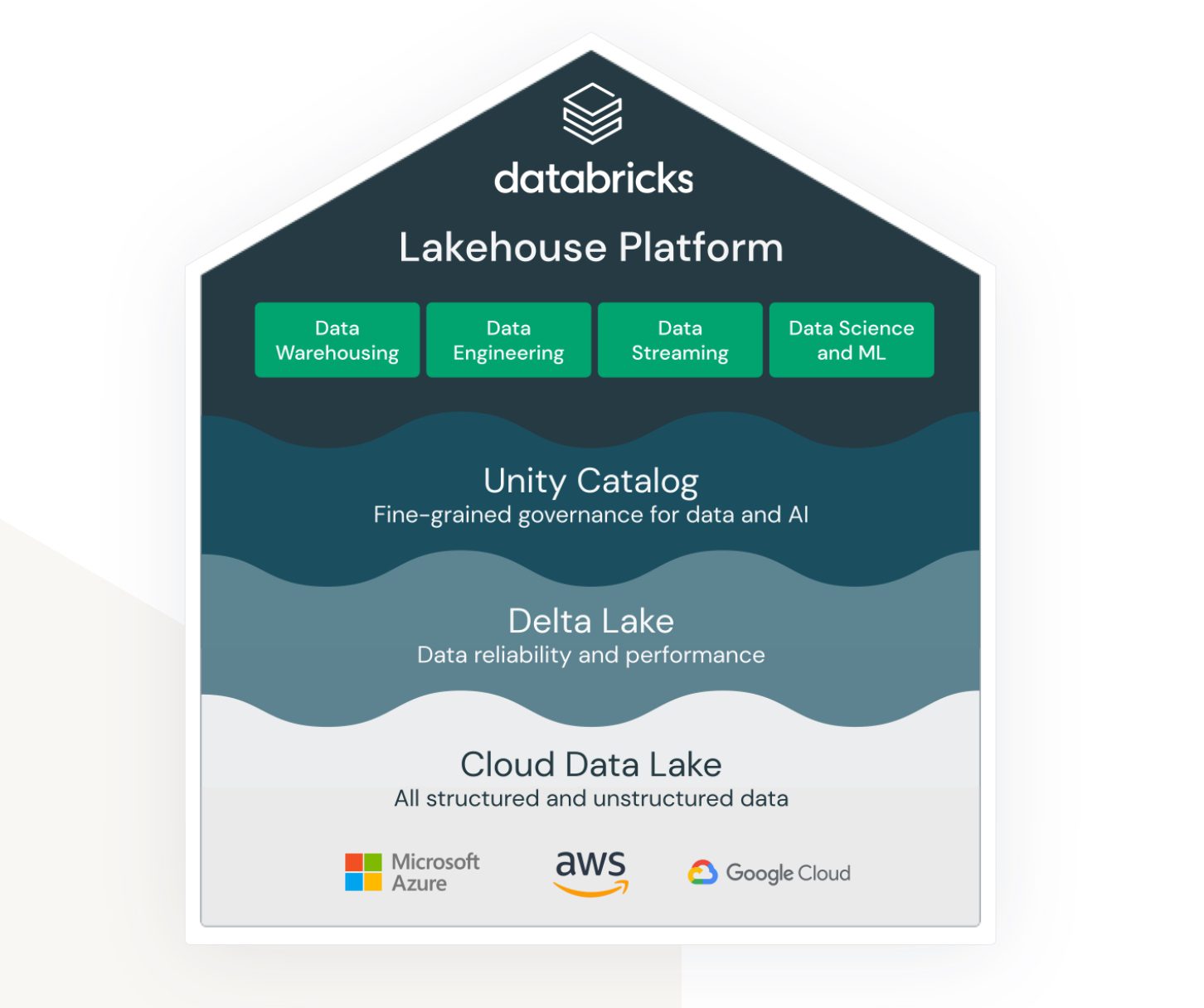
Lakehouse de la Databricks pe AWS
 Sursa: databricks.com
Sursa: databricks.com
Lakehouse este un termen care este într-adevăr legat de serviciul Databricks. Chiar dacă nu este un serviciu AWS nativ, trăiește și funcționează în cadrul ecosistemului AWS foarte frumos și oferă diverse opțiuni de conectare și integrare cu alte servicii AWS.
Databricks își propune să conecteze împreună (anterior) zone foarte distincte:
- O soluție pentru stocarea lacului de date a datelor nestructurate, semistructurate și structurate.
- O soluție pentru date de interogare structurate și accesibile rapid în depozit de date (numită și Delta Lake).
- O soluție care susține analiza și calculul de învățare automată pe lacul de date.
- Guvernanța datelor pentru toate domeniile de mai sus, cu administrare centralizată și instrumente ieșite din cutie pentru a susține productivitatea pentru diferite tipuri de dezvoltatori și utilizatori.
Este o platformă comună pe care inginerii de date, dezvoltatorii SQL și oamenii de știință ai datelor de învățare automată o pot folosi simultan. Fiecare dintre grupuri are, de asemenea, un set de instrumente pe care le poate folosi pentru a-și îndeplini sarcinile.
Deci, Databricks vizează o soluție universală, încercând să combine beneficiile lacului de date și ale depozitului de date într-o singură soluție. În plus, oferă instrumentele pentru a testa și rula modele de învățare automată direct peste depozitele de date deja construite.

Argumente pro şi contra
Beneficiile de luat în considerare:
- Databricks este o platformă de date extrem de scalabilă. Se scalează în funcție de dimensiunea sarcinii de lucru și o face chiar și automat.
- Este un mediu de colaborare pentru oamenii de știință de date, inginerii de date și analiștii de afaceri. A avea posibilitatea de a face toate acestea în același spațiu și împreună este un mare beneficiu. Nu numai dintr-o perspectivă organizațională, dar ajută și la economisirea unui alt cost, altfel necesar pentru medii separate.
- AWS Databricks se integrează perfect cu alte servicii AWS, cum ar fi Amazon S3, Amazon Redshift și Amazon EMR. Acest lucru permite utilizatorilor să transfere cu ușurință date între servicii și să profite de gama completă de servicii cloud AWS.
Dezavantajele de luat în considerare:
- Databricks poate fi complex de configurat și gestionat, în special pentru utilizatorii care sunt începători în procesarea datelor mari. Este nevoie de un nivel semnificativ de expertiză tehnică pentru a profita la maximum de platformă.
- În timp ce Databricks este eficient din punct de vedere al costurilor în ceea ce privește modelul său de prețuri cu plata pe măsură, poate fi în continuare costisitor pentru proiectele de prelucrare a datelor la scară largă. Costul utilizării platformei poate crește rapid, mai ales dacă utilizatorii trebuie să-și extindă resursele.
- Databricks oferă o gamă largă de instrumente și șabloane pre-construite, dar aceasta poate fi și o limitare pentru utilizatorii care au nevoie de mai multe opțiuni de personalizare. Este posibil ca platforma să nu fie potrivită pentru utilizatorii care au nevoie de mai multă flexibilitate și control asupra fluxurilor de lucru de procesare a datelor mari.
Scop și caz de utilizare în lumea reală
AWS Databricks este cel mai potrivit pentru corporațiile mari cu o cantitate foarte mare de date. Aici poate acoperi cerința de a încărca și contextualiza diverse surse de date din diferite sisteme externe.
Adesea, cerința este de a furniza date în timp real. Aceasta înseamnă că, din momentul în care datele apar în sistemul sursă, procesele vor prelua imediat și vor procesa și stoca datele în Databricks instantaneu sau cu o întârziere minimă. Dacă întârzierea este peste un minut, este considerată procesare aproape în timp real. În orice caz, ambele scenarii sunt adesea realizabile cu platforma Databricks. Acest lucru se datorează în principal cantității mari de adaptoare și interfețe în timp real care se conectează la diverse alte servicii native AWS.
De asemenea, Databricks se integrează cu ușurință cu sistemele ETL Informatica. Ori de câte ori sistemul de organizare utilizează deja ecosistemul Informatica pe scară largă, Databricks arată ca un bun plus compatibil pentru platformă.
Cuvinte finale
Pe măsură ce volumul de date continuă să crească exponențial, este bine de știut că există soluții care pot face față eficient. Ceea ce cândva a fost un coșmar de administrat și întreținut acum necesită foarte puțină muncă de administrare. Echipa se poate concentra pe crearea de valoare din date.
În funcție de nevoile dvs., alegeți doar serviciul care se poate ocupa. În timp ce AWS Databricks este ceva de care probabil va trebui să te ții după luarea deciziei, celelalte alternative sunt destul de mai flexibile, chiar dacă mai puțin capabile, în special modurile lor fără server. Este destul de ușor să migrați la o altă soluție mai târziu.