
Amazon Glue câștigă popularitate deoarece multe companii au început să folosească servicii de integrare a datelor gestionate.
ETL este un proces care transferă date dintr-o bază de date sursă într-un depozit de date. ETL este complex și dificil de implementat pentru toate datele întreprinderii datorită complexității sale. Amazon a introdus AWS Glue pentru a rezolva această problemă.
Dezvoltatorii ETL și inginerii de date folosesc Glue pentru a construi, monitoriza și rula fluxuri de lucru ETL.
Cuprins
Ce este AWS Glue?
AWS Glue, un serviciu de integrare a datelor fără server, facilitează găsirea, pregătirea, mutarea și integrarea datelor din mai multe surse. Acest lucru este util pentru învățarea automată (ML) și analiză.
Reduce dramatic timpul necesar pregătirii datelor pentru analiză. Găsește și listează automat datele, generează cod Scala sau Python pentru a transmite datele de la sursă și încarcă și transformă jobul în funcție de evenimentele cronometrate.
Acest lucru permite o programare flexibilă și creează un mediu Apache Spark care poate fi scalat pentru încărcarea țintită a datelor. În plus, AWS Glue asigură monitorizarea și modificarea fluxului de date complexe. AWS Glue este un serviciu fără server care simplifică operațiunile complicate ale dezvoltării aplicațiilor.
Permite integrarea rapidă a mai multor date valide. De asemenea, se defectează și autorizează datele rapid.
Pentru ce se folosește AWS Glue?
Este important să cunoașteți cele mai bune locuri pentru a utiliza Amazon Glue. Acestea sunt doar câteva exemple de utilizări AWS Glue pe care ar trebui să le luați în considerare.
- Glue este un instrument care vă permite să rulați interogări fără server pe lacurile de date Amazon S3. Amazon Glue este un instrument excelent pentru a începe. Vă face toate datele accesibile la o singură interfață, permițându-vă să le analizați fără a fi nevoie să le mutați.
- Amazon Glue poate fi folosit pentru a înțelege datele dvs. Amazon Glue vă ajută să căutați diferite seturi de date AWS folosind Catalogul de date. De asemenea, puteți salva date în mai multe servicii AWS utilizând Catalogul de date, având în același timp o vizualizare consecventă.
- Lipiciul poate fi util atunci când construiești fluxuri de lucru ETL bazate pe evenimente. Vă puteți executa operațiunile ETL de pe Amazon S3 apelând sarcinile ETL Glue printr-un serviciu AWS Lambda.
- AWS Glue poate fi folosit și pentru a curăța, verifica, formata și organiza datele pentru stocare într-un lac de date sau într-un depozit.
Care sunt componentele AWS Glue?
Mai jos sunt principalele componente ale AWS Glue:
- Catalog de date: acest catalog de date conține metadate și structura datelor.
- Baza de date: Aceasta este cheia pentru accesarea și crearea bazei de date pentru surse și ținte.
- Tabel: Creați unul sau mai multe tabele în baza de date care sunt utilizabile atât de către țintă, cât și de către sursă.
- Crawler și clasificator: crawler-ul preia date de la sursă utilizând fie clasificări încorporate, fie personalizate. Acesta creează/folosește tabele de metadate predefinite în catalogul de date.
- Job: Aceasta este sarcina logicii de afaceri pentru a efectua o sarcină ETL. Această logică de afaceri este scrisă intern de Apache Spark folosind limbaje python și scala.
- Trigger: un declanșator ETL este un dispozitiv care inițiază execuția unui job ETL la cerere sau la un anumit moment.
- Punct final pentru dezvoltare: se creează un mediu în care scriptul de job ETL este testat, dezvoltat și depanat.
Beneficiile AWS Glue
Acestea sunt beneficiile utilizării la locul de muncă sau în cadrul unei organizații.
- AWS Glue scanează toate datele disponibile cu un crawler.
- Datele finale procesate pot fi stocate în multe locuri (Amazon RDS și Amazon Redshift, Amazon S3 etc.
- Este un serviciu bazat pe cloud. Nu este nevoie să cheltuiți bani pe infrastructuri la sediu.
- Deoarece este un ETL fără server, este o alegere rentabilă.
- E rapid. Vă oferă imediat codul ETL Python/Scala.
Principalele caracteristici ale AWS Glue?
Amazon Glue are toate funcțiile de care aveți nevoie pentru a integra datele, astfel încât să puteți obține informații mai bune și să vă folosiți cunoștințele pentru a face noi progrese în câteva minute în loc de luni. Iată câteva dintre caracteristicile pe care ar trebui să le cunoașteți.
- Interfață de glisare și plasare: un editor de job-glisare și plasare vă permite să creați un proces ETL. AWS Glue va construi imediat codul necesar pentru a extrage, converti și încărca datele.
- Descoperire automată a schemelor: pentru a crea crawler-uri care se conectează la diferite surse de date, puteți utiliza serviciul Glue. Acesta organizează datele și extrage informații relevante. Aceste date pot fi apoi utilizate pentru a monitoriza procesele ETL prin sarcini ETL.
- Programarea lucrărilor: Glue poate fi folosit fie la cerere, fie conform unui program programat. Planificatorul poate fi folosit pentru a construi conducte ETL complexe, stabilind dependențe între sarcini.
- Generarea codului: Glue Elastic Views vă permite să creați cu ușurință vederi materializate care combină și replic date din diferite surse de date fără a fi nevoie să scrieți niciun cod proprietar.
- Învățare automată încorporată: Glue vine cu o funcție de învățare automată încorporată numită „Găsiți potriviri”. Deduplica înregistrările care nu sunt copii perfecte unele ale altora.
- Puncte finale pentru dezvoltatori: dacă doriți să dezvoltați în mod activ codul dvs. ETL, Glue oferă puncte finale pentru dezvoltatori care vă permit să modificați, să depanați și să testați codul pe care îl creează.
- Glue DataBrew: este un instrument de pregătire a datelor care poate fi folosit de analiștii de date și de oamenii de știință de date pentru a-i ajuta să curețe și să normalizeze datele. Utilizează interfața activă și vizuală a Glue DataBrew.
Cum funcționează prețurile AWS Glue?
AWS Glue percepe o taxă orară, care este facturată pe secundă pentru crawler-uri (descoperirea datelor) și joburi ETL (procesarea și încărcarea datelor). Se percepe o taxă lunară simplă pentru accesarea și stocarea metadatelor în AWS Glue Data Catalog.
Amazon Glue începe de la 0,44 USD. Puteți alege dintre patru planuri:
- Sarcinile ETL, punctele finale de dezvoltare și alte sarcini ETL sunt disponibile la 0,44 USD
- Sesiunile interactive Crawler sunt disponibile la 0,44 USD
- Joburile DataBrew încep de la 0,48 USD
- Stocarea lunară și solicitările către Catalogul de date costă 1,00 USD
AWS nu oferă un plan Glue gratuit. Fiecare oră va costa 0,44 USD per DPU. În medie, te-ar costa 21 USD pe zi. Prețurile pot varia în funcție de locul în care locuiți.
Pași pentru a configura AWS Glue
Catalogul de date poate fi utilizat pentru a găsi și căuta rapid mai multe seturi de date AWS fără a fi nevoie să mutați datele. După ce datele au fost catalogate, acestea sunt imediat disponibile pentru interogare și căutare folosind Amazon Athena și Amazon EMR.
Ref: https://aws.amazon.com/glue/
- Amazon Redshift, Amazon S3, Amazon RDS și baze de date pe Amazon EC2 – Descoperiți-vă datele, stocați metadatele și utilizați Catalogul de date AWS Glue pentru a le descoperi
- Catalogul de date AWS Glue – Gestionați datele cu catalogul de date acționând ca un depozit central pentru metadate
- AWS Glue ETL – Citiți și scrieți metadate în catalogul dvs. de date
- Amazon Athena și Amazon Redshift, Amazon EMR, Amazon ETL – Obțineți catalogul de date pentru ETL, analize și multe altele.
Cum se configurează AWS Glue?
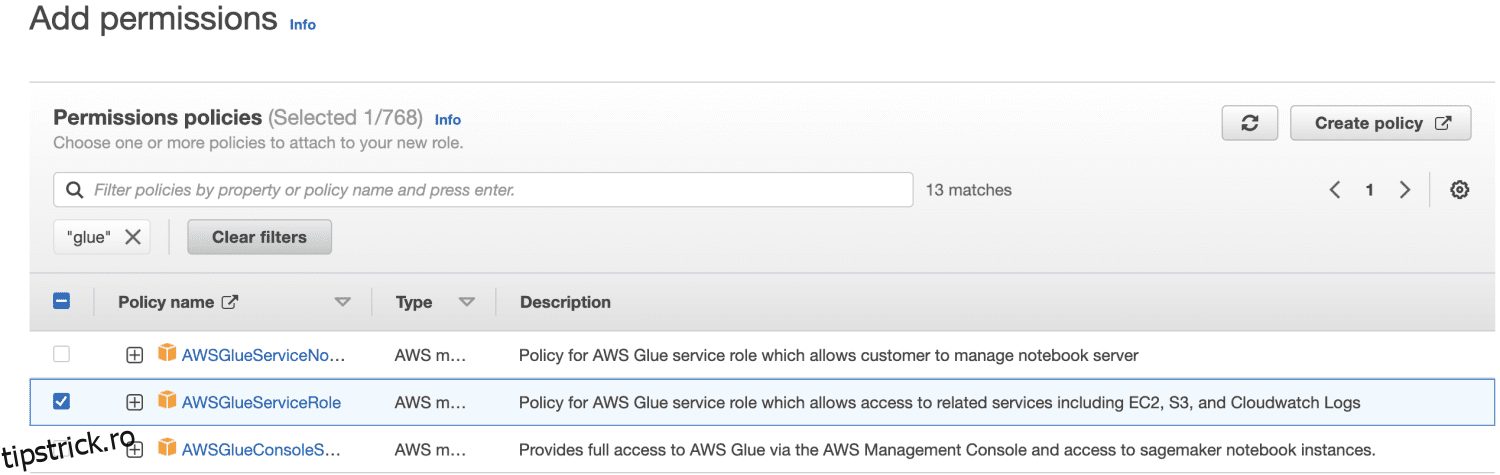
În primul rând, conectați-vă la AWS Management Console și deschideți consola IAM. Faceți clic pe Creare rol. Apoi, pentru tipul de rol, găsiți Glue și selectați Permisiuni.
Aleg AWSGlueServiceRole pentru permisiunile generale AWS Glue Studio și AWS Glue și politica gestionată de AWS AmazonS3FullAccess pentru acces la resursele Amazon S3.
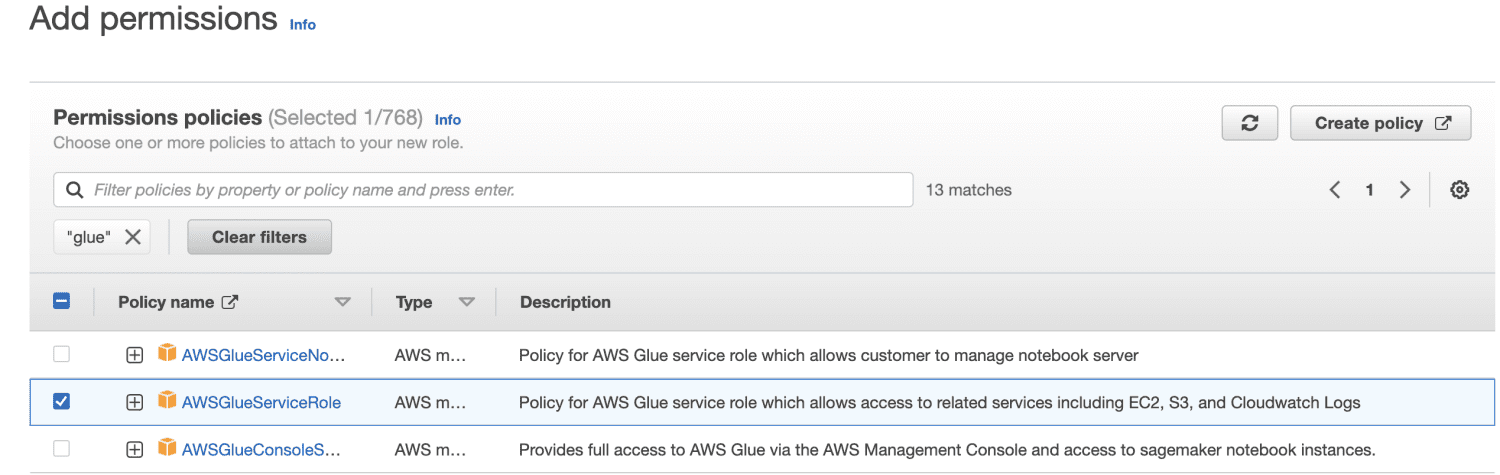
Introduceți un nume de rol.
Faceți clic pe Creare rol.
Creați o găleată Amazon S3.
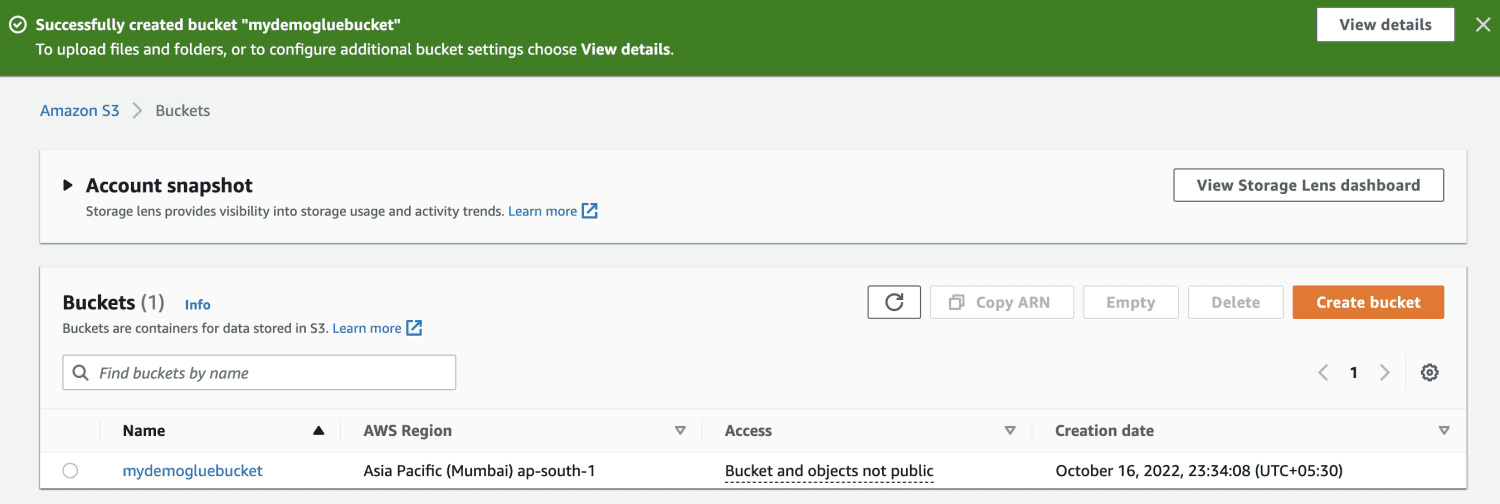
Creați un folder în interiorul găleții S3.
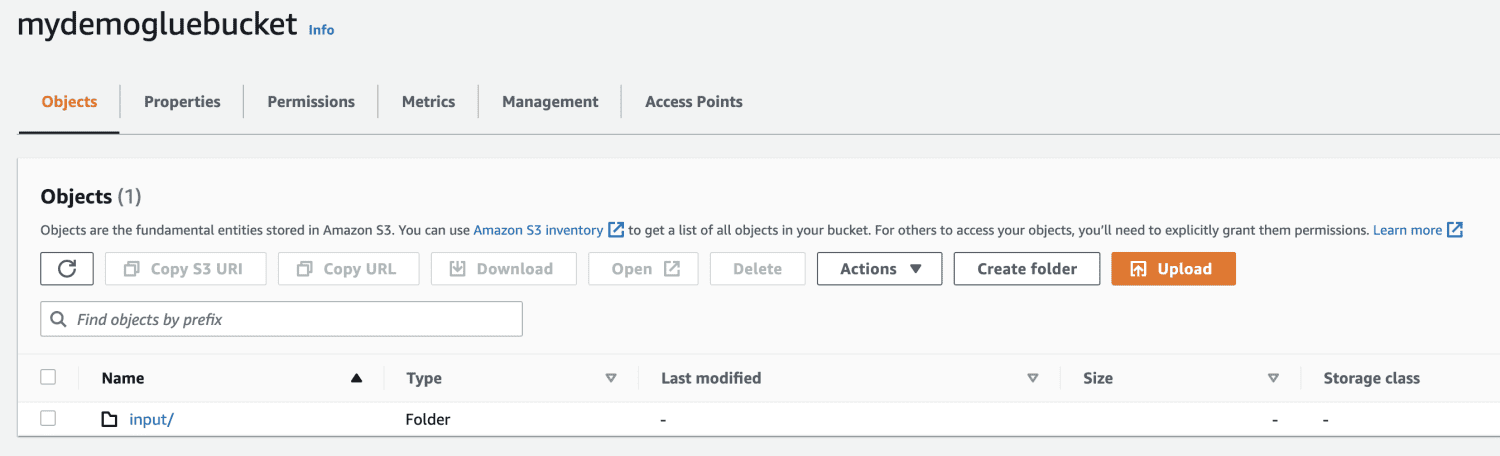
Alegeți fișierul de încărcat.
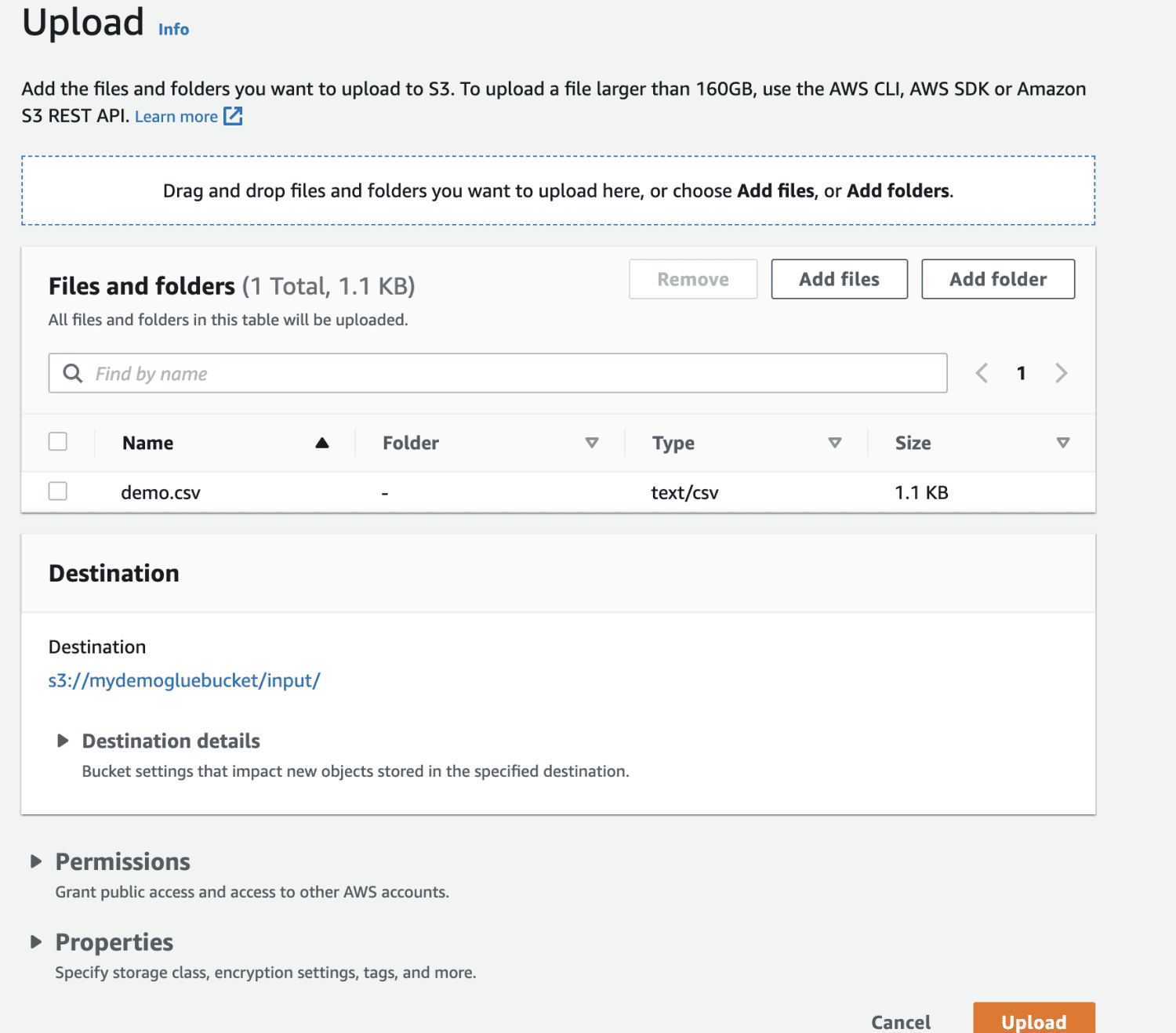
În cele din urmă, încărcați fișierul în găleată.
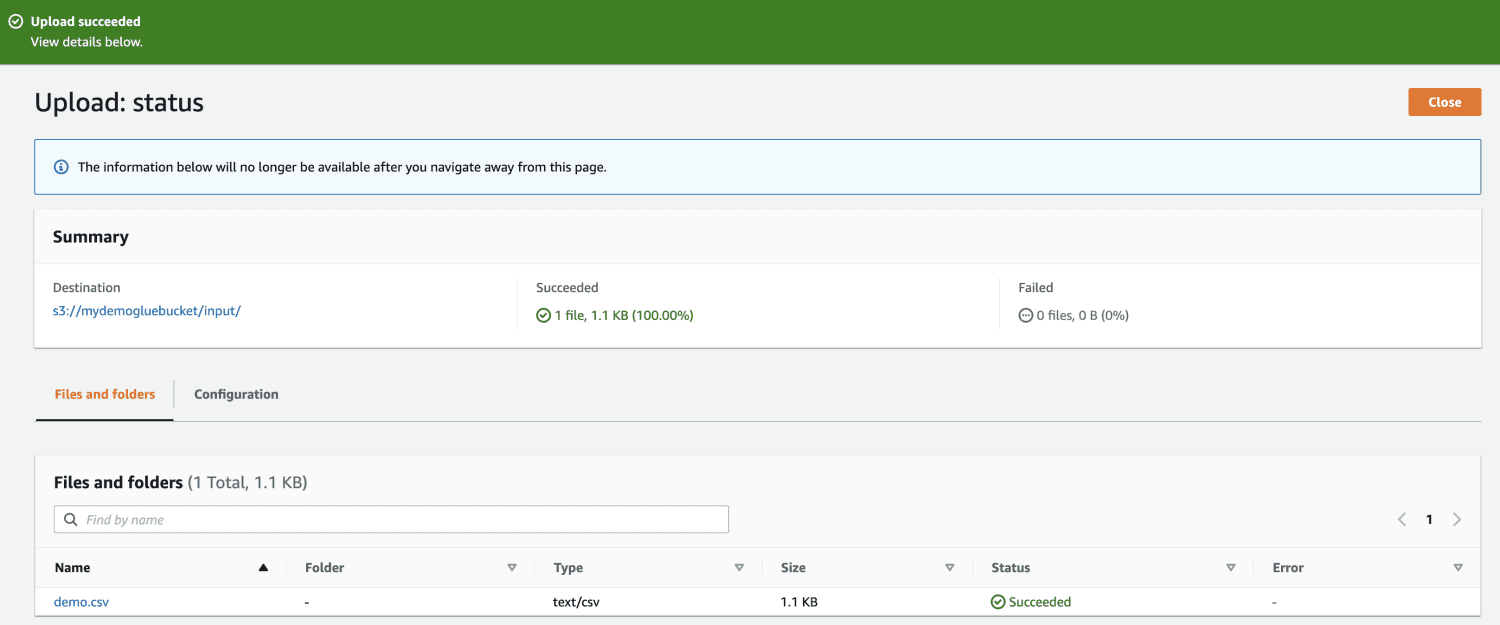
Apoi, deschideți AWS Glue din consola de management AWS și creați o bază de date.
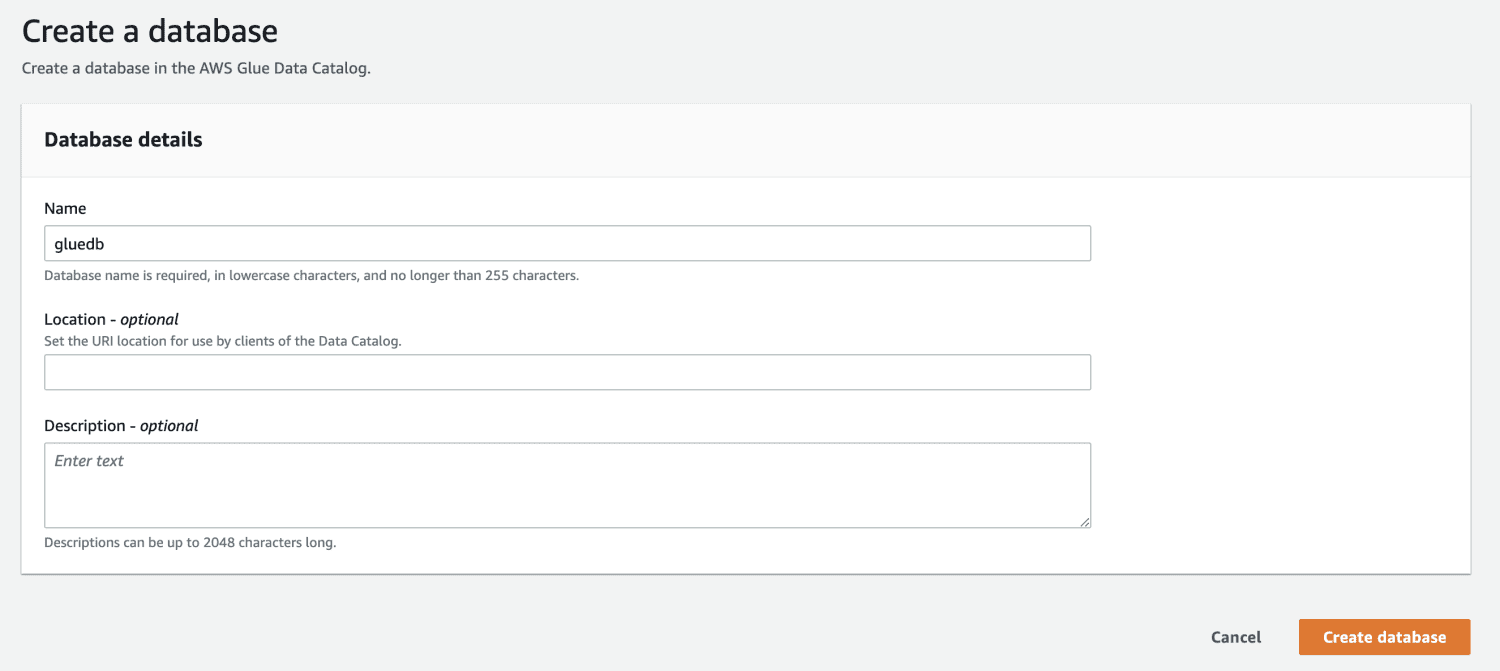
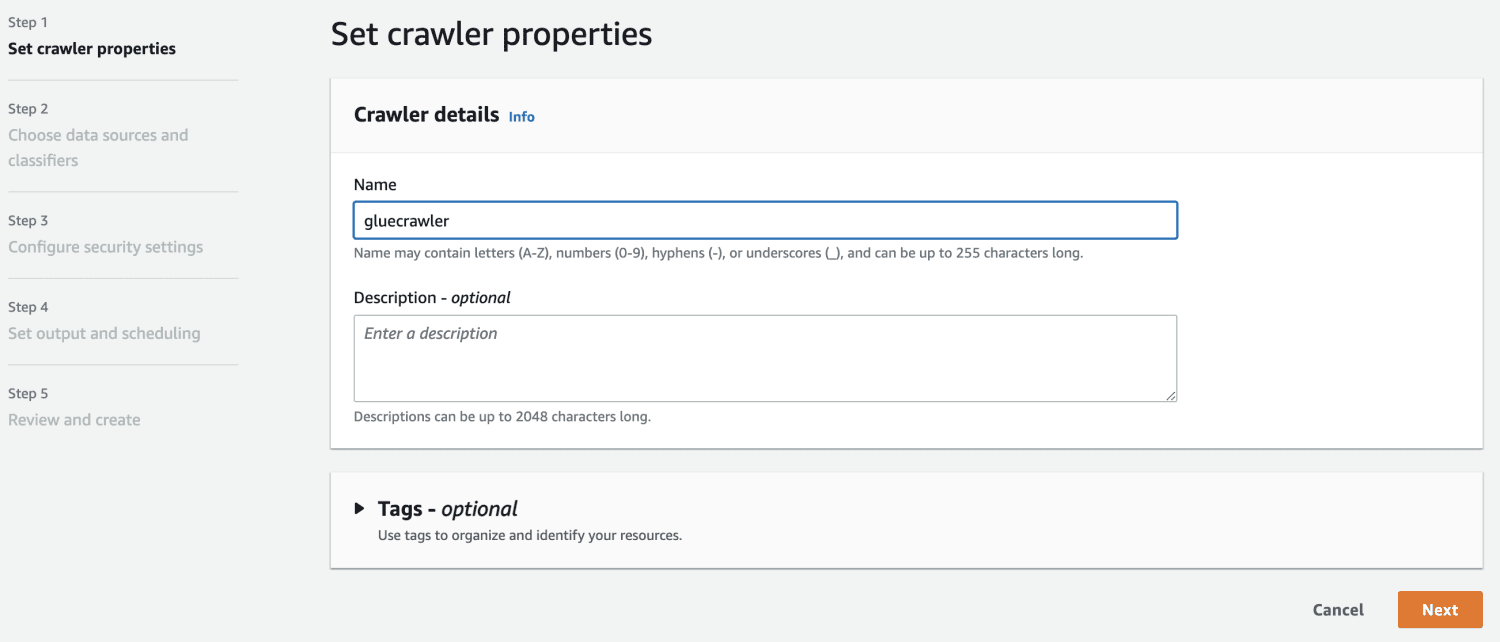
Acum că aveți o bază de date în AWS Glue, creați un crawler.
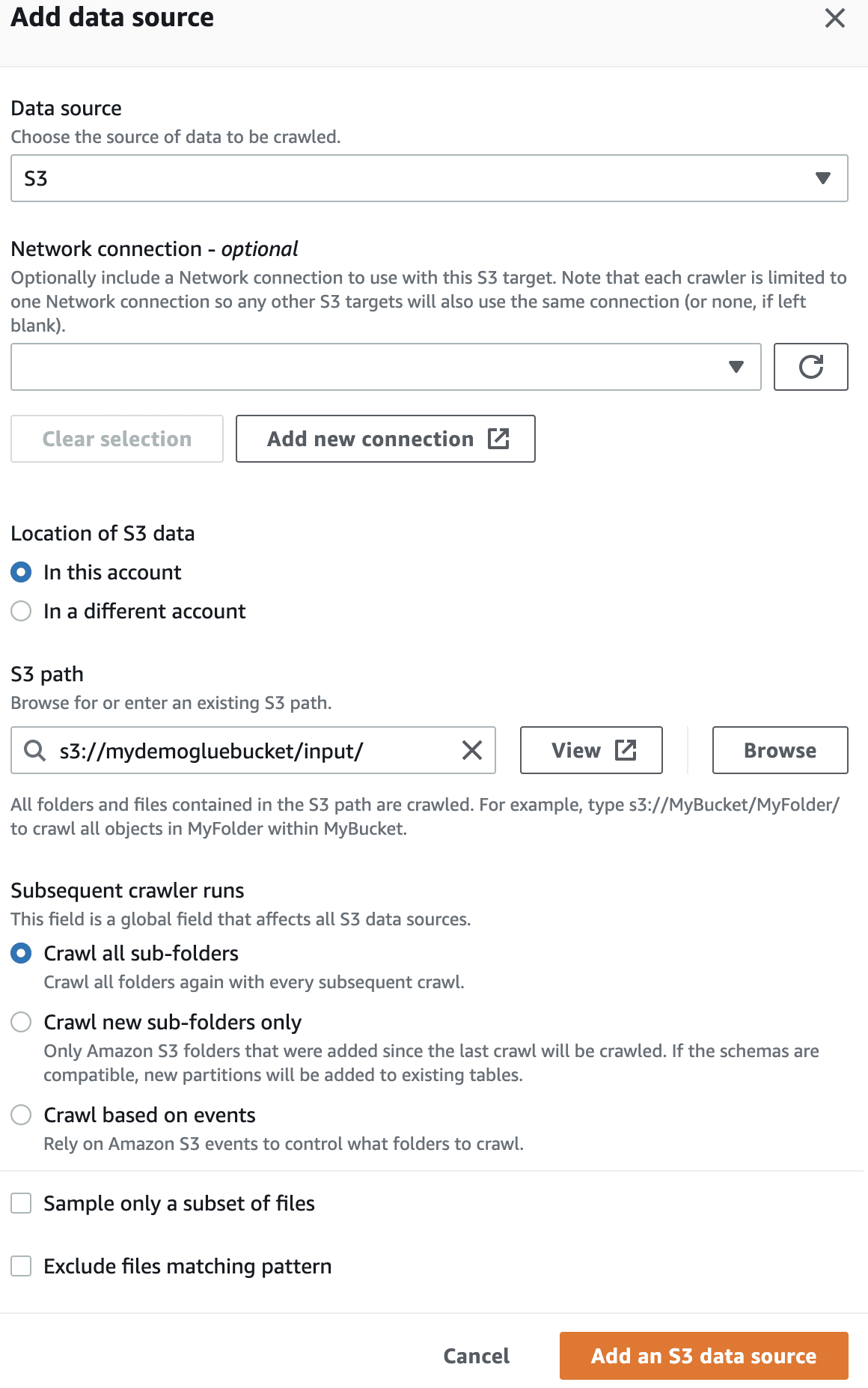
În sursa de date, selectați compartimentul S3 pe care l-ați creat.
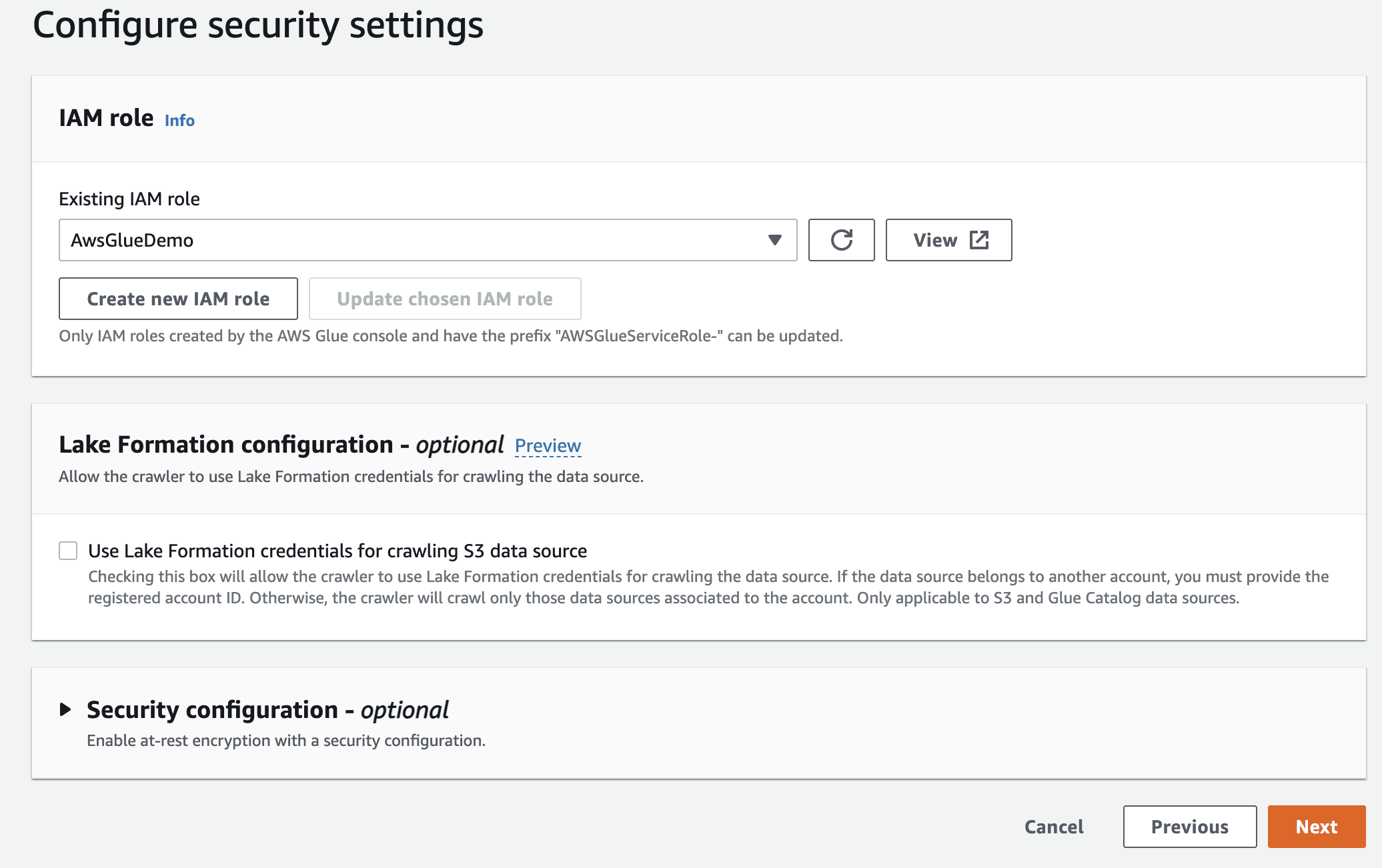
Apoi, selectați rolul IaM pentru AWS Glue pe care l-ați creat la început.
În cele din urmă, în rezultat, selectați gluedb pe care l-ați creat.
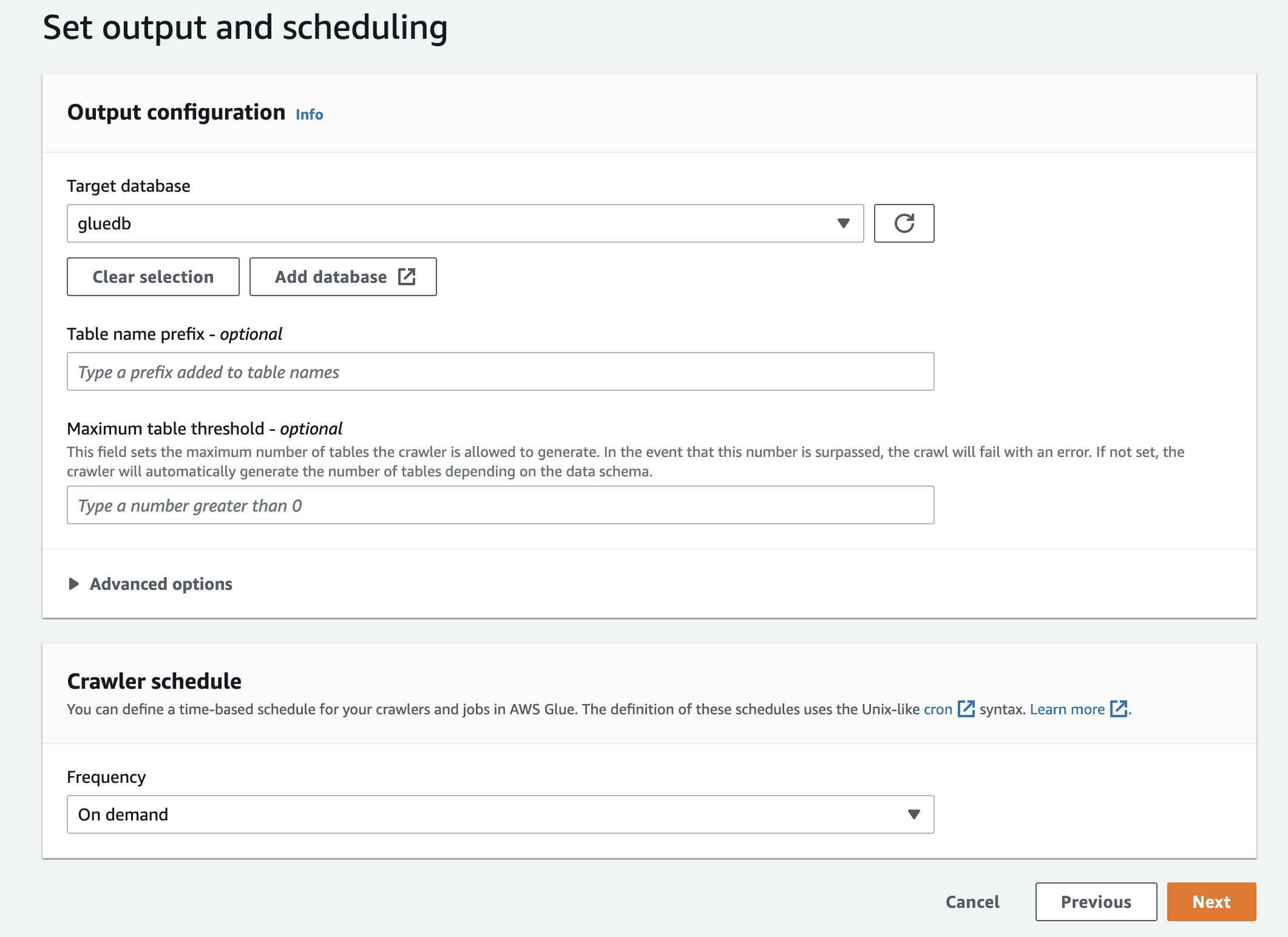
Examinați toate setările și creați crawlerul.
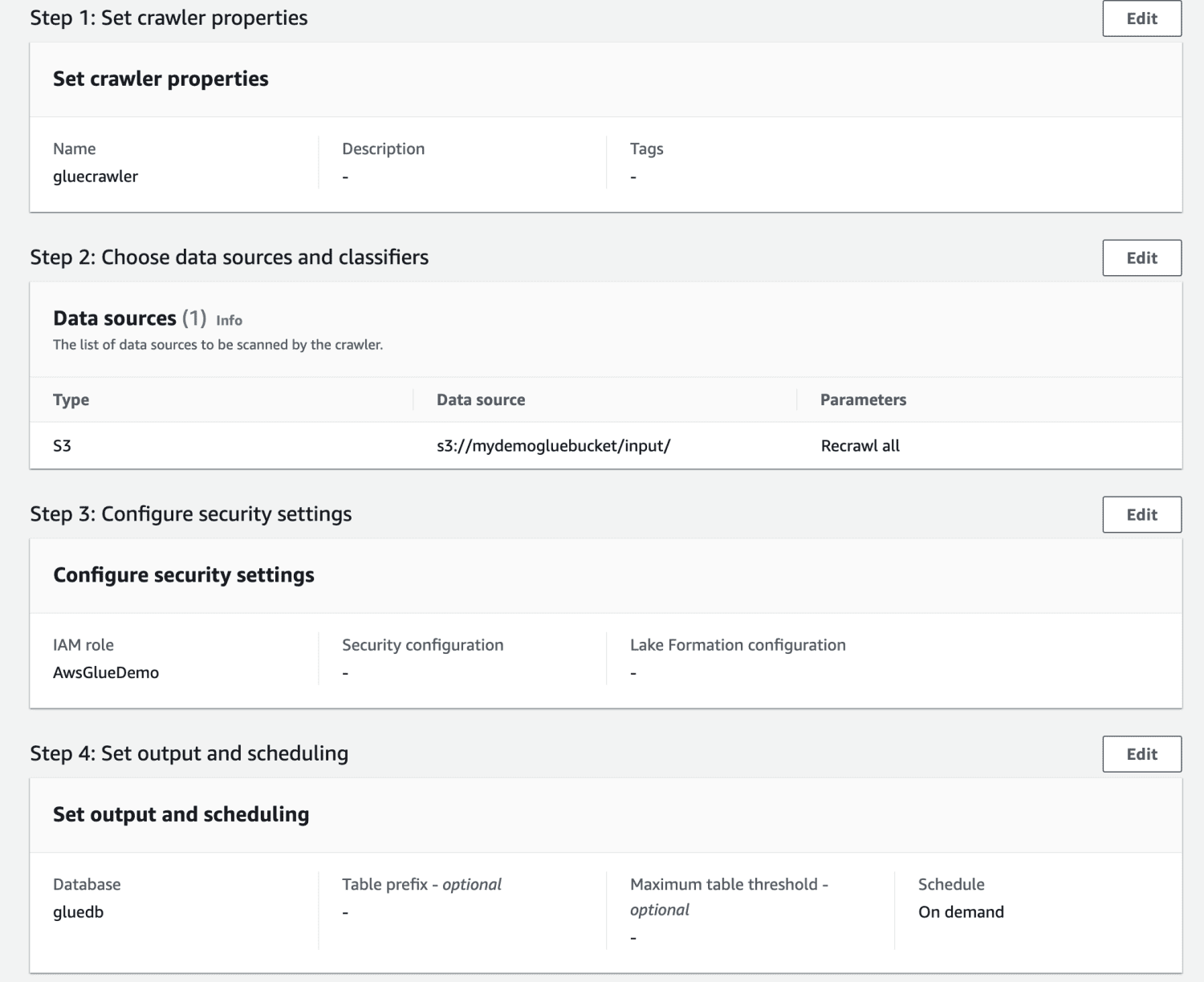
Odată ce crawler-ul este creat, selectați-l și faceți clic pe Run. După ceva timp, veți obține starea gata.
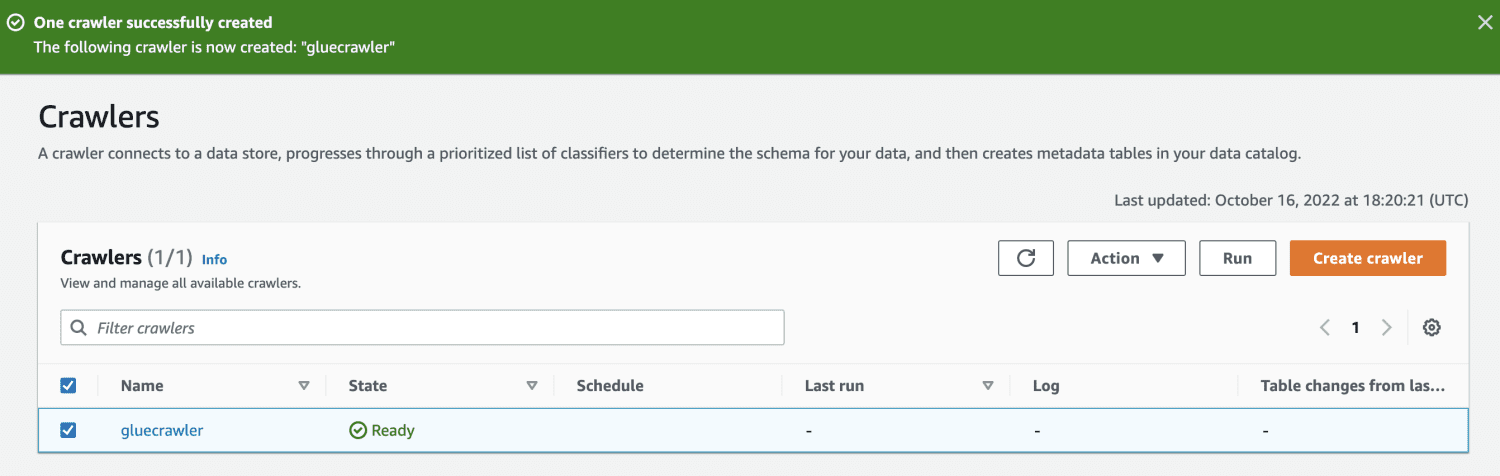
Prin rularea crawler-ului, baza de date va obține un tabel cu toate datele din fișierul CSV.
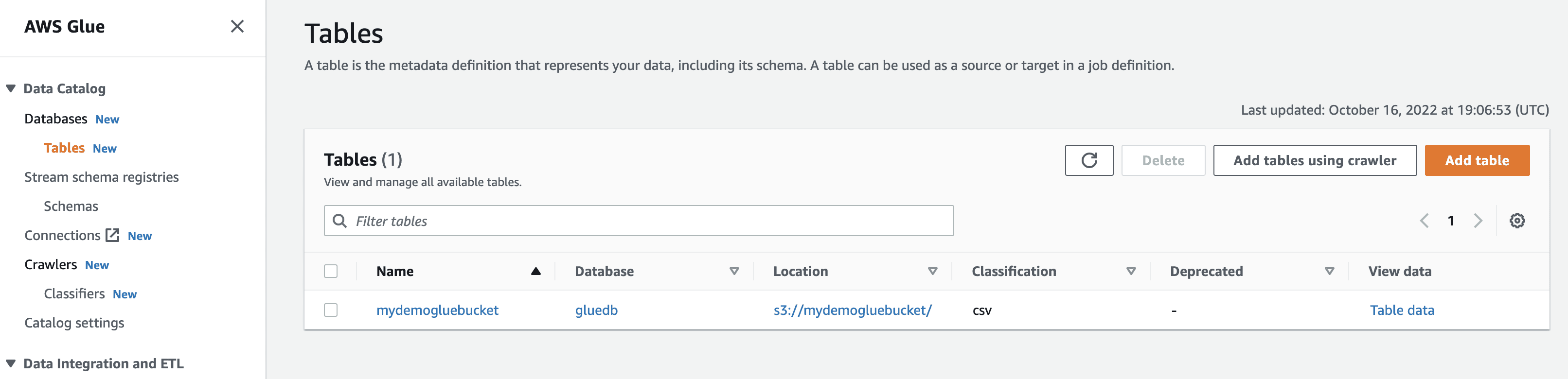
Când faceți clic pe vizualizarea datelor, veți fi dus la Amazon Athena (editor de interogări). Când executați interogarea, puteți vedea datele din tabel.
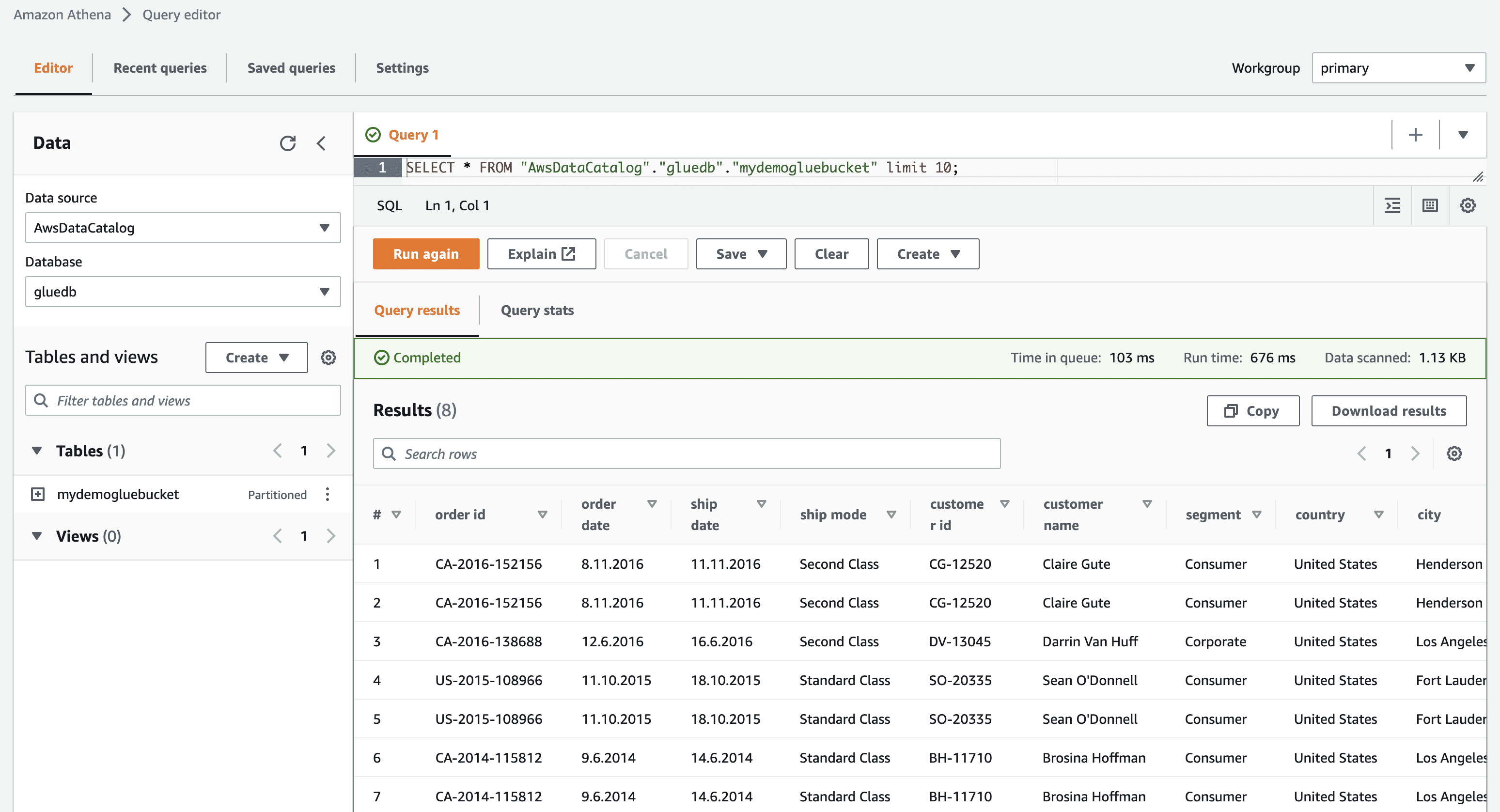
Acum puteți utiliza cu succes acest crawler AWS Glue în orice lucrare ETL.
Ce este AWS Glue Databrew?
AWS Glue DataBrew permite utilizatorilor să normalizeze și să curețe datele fără a scrie niciun cod. DataBrew poate reduce timpul necesar pregătirii datelor pentru învățarea automată și analiză cu până la 80% în comparație cu pregătirea datelor dezvoltate la comandă.
Există peste 250 de transformări de date prestabilite care pot fi folosite pentru a automatiza sarcinile de pregătire a datelor, cum ar fi filtrarea anomaliilor, corectarea valorilor nevalide și conversia datelor în formate standard.
DataBrew facilitează colaborarea oamenilor de știință de date, analiștilor de afaceri și inginerilor la extragerea de informații din datele brute. DataBrew este fără server, așa că nu trebuie să gestionați infrastructura sau să creați clustere pentru a explora și transforma date brute în valoare de terabytes.
Caracteristici DataBrew pentru întreprinderi
Pregătirea datelor vizualizate
DataBrew este o modalitate diferită de a vizualiza datele care sunt de obicei vizualizate în bazele de date coloane ca numere alfanumerice. DataBrew vizualizează toate sursele de date încărcate pentru a vă ajuta să înțelegeți relațiile și ierarhia datelor.
Peste 250 de automatizări de pregătire a datelor
Se așteaptă ca oamenii de știință de date să urmărească o varietate de fluxuri de lucru repetabile și izolate ca parte a muncii lor. Aceste fluxuri de lucru și procese au fost modelate de AWS ca module de module independente de limbaj și date. Această bibliotecă include acțiuni care pot fi utilizate de utilizatorii finali.
Linia de date
Similar cu jurnalele de audit care sunt utilizate pentru a urmări activitatea clienților în rețeaua IT a unei rețele IT, descendența datelor vă permite să urmăriți activitățile de transformare a datelor din AWS DataBrew. Aceste informații includ sursa de date, transformările aplicate și ieșirea datelor, inclusiv locația țintă.
Maparea datelor
Databrew vă permite să găsiți câmpuri potrivite în două surse de date. Odată ce câmpurile care se potrivesc au fost identificate, acestea pot fi încărcate într-o schemă.
AWS Glue DataBrew: Beneficii
Mai jos sunt caracteristicile AWS Glue DataBrew:
- Bariera inferioară la intrare pentru pregătirea datelor
- Generare automată a profilului de date
- Automatizați peste 250 de procese de pregătire a datelor
- Sugestii prescriptive inteligente
Alternative la AWS Glue
Flux de aer
Airflow aparține secțiunii Workflow Manager a unei stive de tehnologie. Este un instrument open-source care acceptă stelele GitHub, furcile GitHub și alte funcții. Airflow vă permite să creați fluxuri de lucru folosind diagrame aciclice direcționate (DAG). Planificatorul de flux de aer vă execută sarcinile utilizând o serie de lucrători și urmând dependențele specificate.
Matillion

Matillion ETL, un instrument ETL/ELT, a fost conceput în mod explicit pentru platformele de baze de date cloud, cum ar fi Amazon Redshift și Google BigQuery. Este o interfață de utilizare modernă bazată pe browser, cu capabilități ETL/ELT puternice push-down. Puteți fi activ și funcțional în câteva minute cu o configurare rapidă.
coase
Stitch este un serviciu ETL open-source care conectează mai multe surse de date și reproduce datele către destinațiile preferate. Este foarte ușor de utilizat, deoarece nu aveți nevoie de cunoștințe de codare pentru a muta datele între surse și destinații în Stitch. Este ușor de utilizat, are o interfață grafică prietenoasă și este rapid.
Stitch nu vă permite să alegeți un tablou de bord prefabricat, spre deosebire de alte instrumente ETL. În schimb, trebuie să vă integrați datele în depozitele de date deschise pe care le selectați ca destinație. Poate fi dificil să navighezi în inventare.
Alteryx

Alteryx este o platformă de automatizare a analizei care ajută la pregătirea și combinarea culegerii datelor. Aceste date pot fi folosite pentru a accelera procesele și pentru a oferi informații despre afaceri. Deoarece este un instrument drag-and-drop, nu aveți nevoie de cunoștințe de programare. Alteryx este un loc grozav pentru a primi sfaturi și răspunsuri de la profesioniștii din industrie.
Concluzie
Deci, asta a fost totul despre AWS Glue, care este o soluție bazată pe cloud care vă permite să lucrați cu conducte ETL. Pentru a rezuma, procesul de interacțiune cu utilizatorul AWS Glue este compus din trei faze. Pentru a crea un catalog de date, mai întâi utilizați crawlerele de date. Apoi, creați codul ETL cerut de conducta de date AWS. În cele din urmă, programul ETL este apoi creat. Sper că acest blog v-a oferit o imagine de ansamblu bună asupra Amazon Glue.
De asemenea, puteți explora cele mai bune sfaturi pentru a securiza stocarea AWS S3.