Amazon Glue: Un instrument esențial pentru integrarea datelor
Popularitatea Amazon Glue este în creștere, deoarece tot mai multe companii adoptă soluții gestionate pentru integrarea datelor.
Procesul ETL (Extragere, Transformare, Încărcare) este vital pentru transferul datelor dintr-o bază sursă într-un depozit de date. Cu toate acestea, implementarea ETL la scară largă poate fi complexă. Pentru a simplifica această provocare, Amazon a introdus AWS Glue.
Dezvoltatorii ETL și inginerii de date folosesc Glue pentru a proiecta, monitoriza și executa fluxuri de lucru ETL.
Ce este AWS Glue?
AWS Glue este un serviciu de integrare a datelor fără server, care simplifică descoperirea, pregătirea, mutarea și integrarea datelor din diverse surse. Această flexibilitate îl face ideal pentru aplicații de învățare automată (ML) și analiză.
Glue reduce considerabil timpul alocat pregătirii datelor pentru analiză. Acesta identifică și cataloghează automat datele, generează cod Scala sau Python pentru transferul datelor din surse și execută transformările în funcție de un program stabilit.
Acest serviciu oferă o programare flexibilă și creează un mediu Apache Spark scalabil pentru încărcarea eficientă a datelor. În plus, AWS Glue facilitează monitorizarea și modificarea fluxurilor de date complexe. Fiind un serviciu fără server, acesta simplifică semnificativ operațiunile de dezvoltare a aplicațiilor.
Glue permite integrarea rapidă a unei game variate de date valide și oferă mecanisme de detectare și corectare a datelor cu probleme.
Pentru ce este utilizat AWS Glue?
Este crucial să cunoaștem scenariile optime de utilizare ale Amazon Glue. Iată câteva exemple relevante:
- Glue permite interogarea fără server a datelor stocate în lacurile de date Amazon S3. Acesta consolidează accesul la date într-o singură interfață, facilitând analiza fără a fi nevoie de migrarea lor.
- Amazon Glue poate fi folosit pentru a obține o înțelegere a datelor. Prin intermediul Catalogului de date, Glue permite explorarea diverselor seturi de date AWS, oferind o vedere unitară și consecventă.
- Glue este util în construirea fluxurilor de lucru ETL bazate pe evenimente. Operațiunile ETL pot fi declanșate de evenimente Amazon S3 prin intermediul sarcinilor ETL Glue, apelate prin serviciul AWS Lambda.
- AWS Glue este excelent pentru curățarea, validarea, formatarea și organizarea datelor înainte de stocarea într-un lac de date sau depozit de date.
Componentele principale ale AWS Glue
AWS Glue este alcătuit din următoarele componente cheie:
- Catalog de date: Un depozit de metadate care descrie structura datelor.
- Baza de date: Permite accesarea și crearea bazelor de date pentru surse și ținte.
- Tabel: Structuri organizate în baza de date, utilizabile atât pentru sursă, cât și pentru țintă.
- Crawler și clasificator: Extrage datele sursă folosind clasificări predefinite sau personalizate și creează/utilizează tabele de metadate în catalogul de date.
- Job: Logica de afaceri pentru a realiza o sarcină ETL, implementată intern folosind Apache Spark și limbajele Python/Scala.
- Trigger: Mecanism care inițiază execuția unui job ETL la cerere sau conform unui program.
- Punct final pentru dezvoltare: Mediu de testare, dezvoltare și depanare a scripturilor joburilor ETL.
Beneficiile utilizării AWS Glue
Iată câteva dintre avantajele oferite de AWS Glue:
- AWS Glue scanează automat toate datele disponibile cu ajutorul unui crawler.
- Datele procesate pot fi stocate într-o varietate de locații, inclusiv Amazon RDS, Amazon Redshift și Amazon S3.
- Serviciul este bazat pe cloud, eliminând necesitatea investițiilor în infrastructuri locale.
- Fiind un serviciu ETL fără server, oferă un raport cost-eficiență superior.
- Viteza de generare a codului ETL în Python/Scala este remarcabilă.
Caracteristicile cheie ale AWS Glue
Amazon Glue oferă toate instrumentele necesare pentru integrarea eficientă a datelor, permițându-vă să obțineți informații valoroase în câteva minute, nu luni. Iată câteva dintre principalele caracteristici:
- Interfață drag-and-drop: Editorul vizual simplifică crearea proceselor ETL, iar AWS Glue generează automat codul necesar pentru extragere, transformare și încărcare.
- Descoperirea automată a schemelor: Glue creează crawlere care se conectează la diverse surse de date, organizează datele, extrage informații relevante și monitorizează procesele ETL.
- Programarea sarcinilor: Glue permite executarea sarcinilor la cerere sau conform unui program prestabilit. Planificatorul facilitează construirea de conducte ETL complexe prin definirea dependențelor dintre sarcini.
- Generarea codului: Glue Elastic Views permite crearea rapidă a vizualizărilor materializate care combină și reproduc date din diverse surse, fără a scrie cod personalizat.
- Învățare automată încorporată: Funcția „Găsește potriviri” permite deduplicarea înregistrărilor care nu sunt identice.
- Puncte finale pentru dezvoltatori: Permite modificarea, depanarea și testarea codului ETL generat.
- Glue DataBrew: Un instrument pentru pregătirea datelor, ideal pentru analiștii și oamenii de știință de date, facilitând curățarea și normalizarea datelor printr-o interfață vizuală.
Cum funcționează prețurile AWS Glue?
AWS Glue percepe o taxă orară, facturată pe secundă pentru crawlere și joburi ETL. Pentru accesul la metadate în AWS Glue Data Catalog se percepe o taxă lunară fixă.
Prețul de pornire pentru Amazon Glue este de 0,44 USD. Sunt disponibile patru planuri:
- Sarcini ETL, puncte finale de dezvoltare și alte sarcini: 0,44 USD
- Sesiuni interactive Crawler: 0,44 USD
- Joburi DataBrew: încep de la 0,48 USD
- Stocare lunară și solicitări la Catalogul de date: 1,00 USD
AWS nu oferă un plan gratuit pentru Glue. Fiecare oră costă 0,44 USD per DPU (Unitate de Procesare a Datelor), iar costul mediu zilnic este de aproximativ 21 USD. Prețurile pot varia în funcție de regiune.
Pașii de configurare AWS Glue
Catalogul de date permite găsirea și căutarea rapidă a seturilor de date AWS fără a fi necesară mutarea acestora. După catalogare, datele devin imediat disponibile pentru interogare și căutare prin Amazon Athena și Amazon EMR.
Ref: https://aws.amazon.com/glue/
- Descoperiți datele din Amazon Redshift, Amazon S3, Amazon RDS și bazele de date din Amazon EC2. Stocați metadatele și utilizați Catalogul de date AWS Glue.
- Gestionați datele cu Catalogul de date AWS Glue, un depozit central pentru metadate.
- Citiți și scrieți metadate în catalogul de date prin AWS Glue ETL.
- Utilizați catalogul de date pentru ETL, analize și multe altele cu Amazon Athena, Amazon Redshift și Amazon EMR.
Cum se configurează AWS Glue?
Începeți prin a vă conecta la Consola de management AWS și accesați consola IAM. Faceți clic pe „Creare rol” și alegeți „Glue” ca tip de rol, apoi selectați permisiunile necesare.
Recomandăm rolul `AWSGlueServiceRole` pentru permisiunile generale AWS Glue Studio și AWS Glue, precum și politica `AmazonS3FullAccess` pentru acces la resursele Amazon S3.
Introduceți un nume de rol, de exemplu: `my-glue-role`.
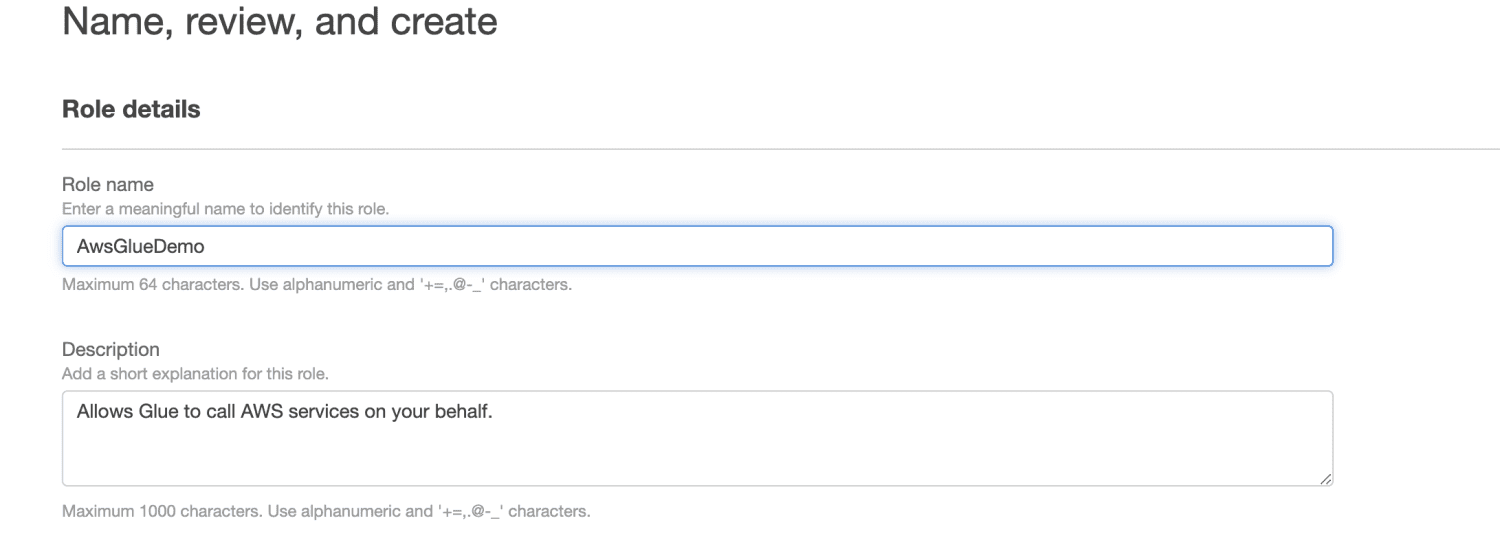
Faceți clic pe „Creare rol”.
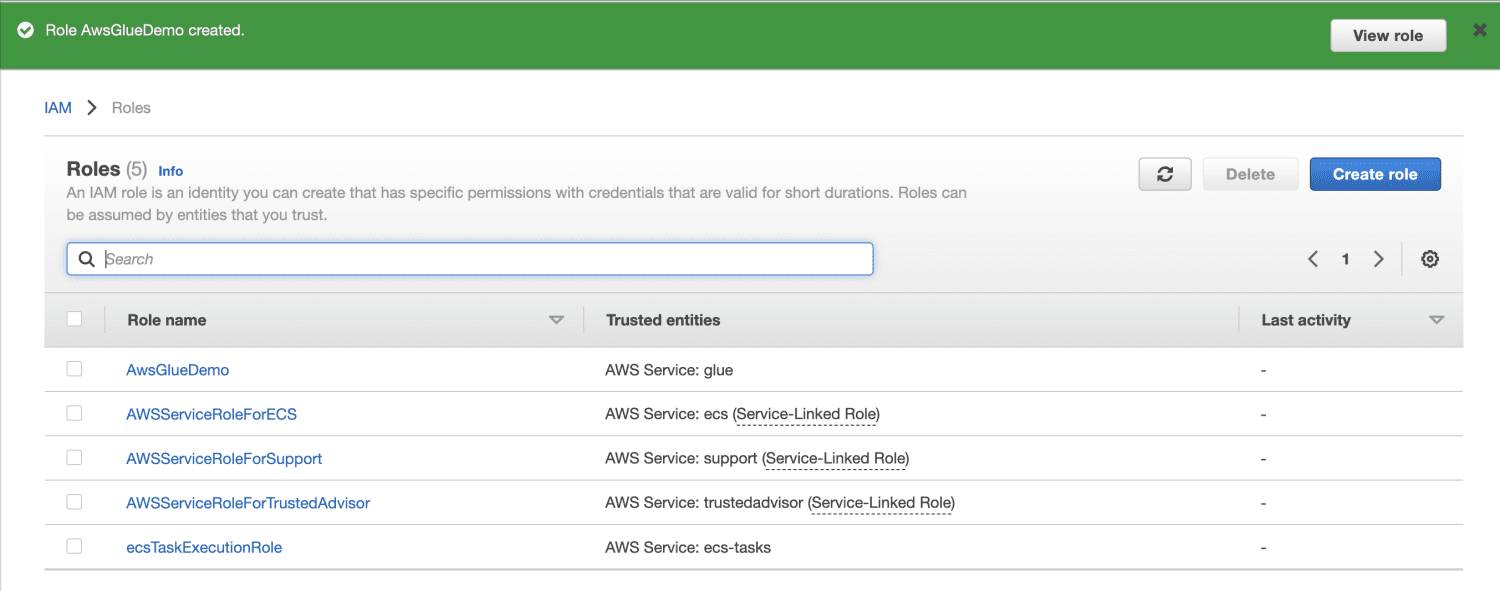
Creați un bucket Amazon S3.
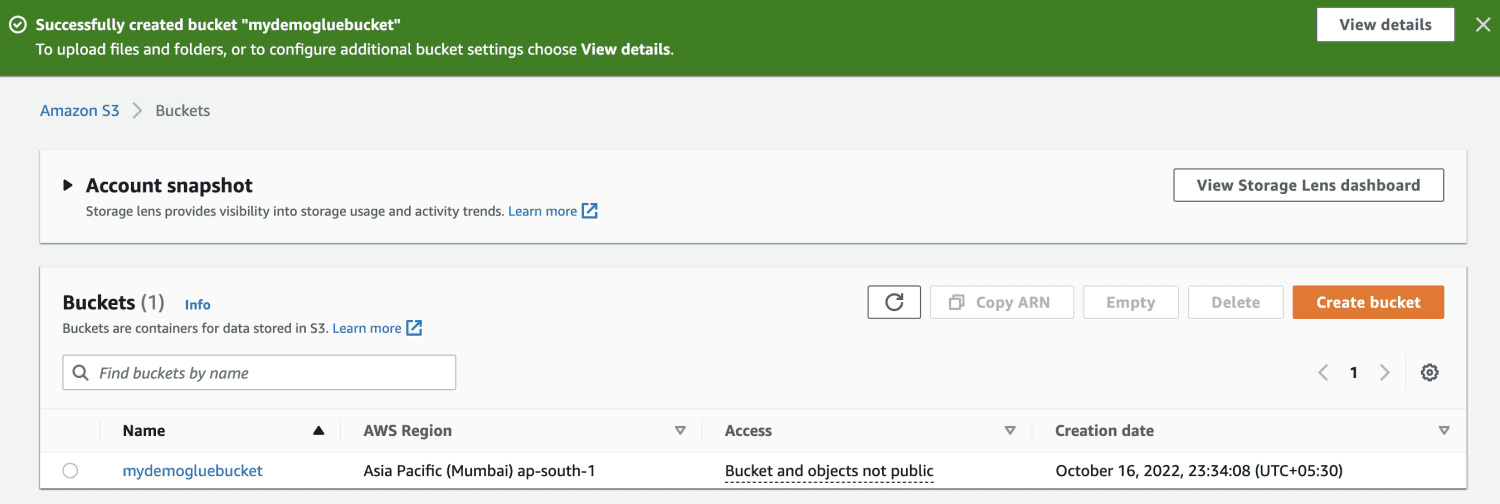
Creați un folder în interiorul bucketului S3, de exemplu: `input`.
Selectați fișierul pe care doriți să îl încărcați.
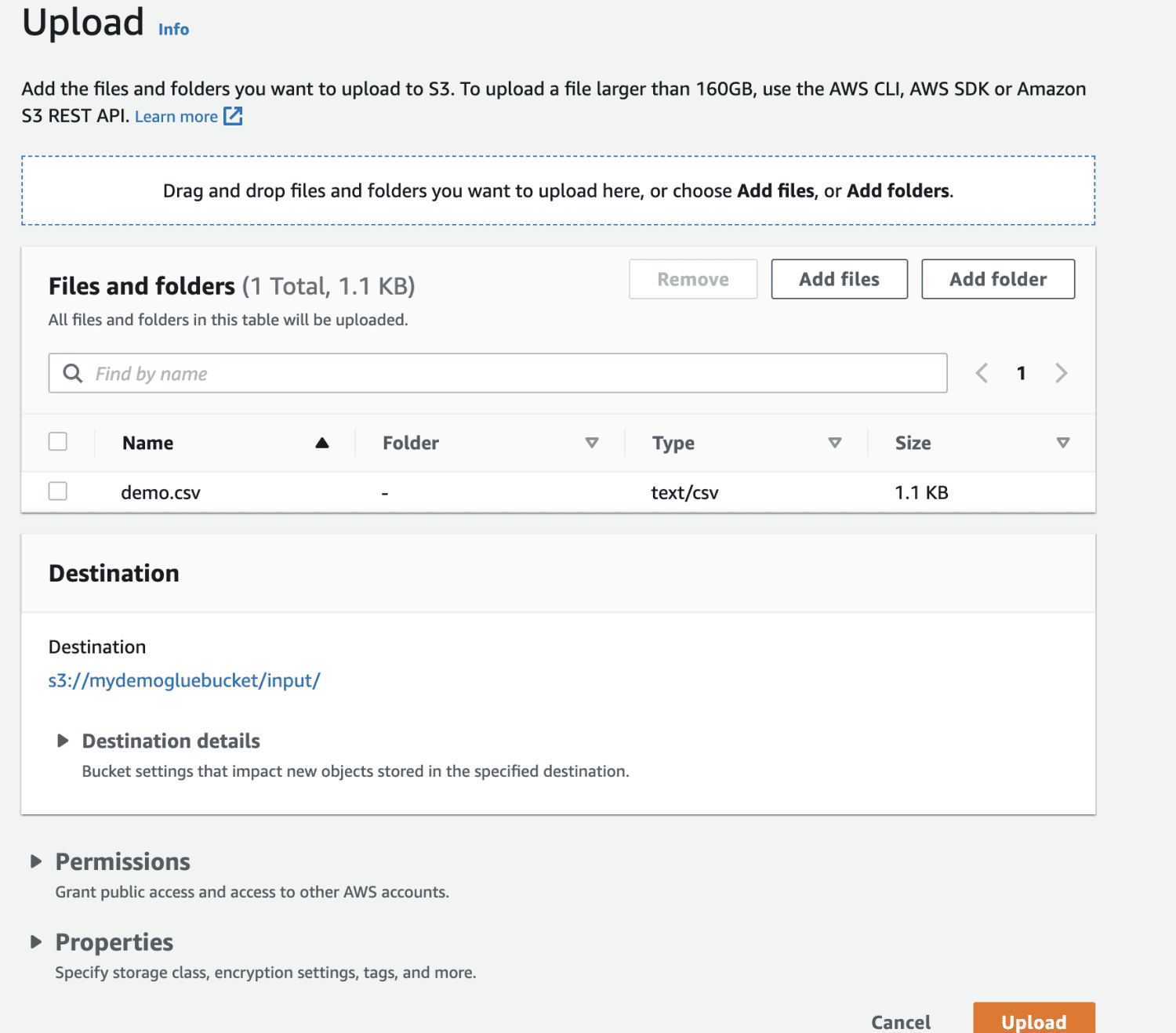
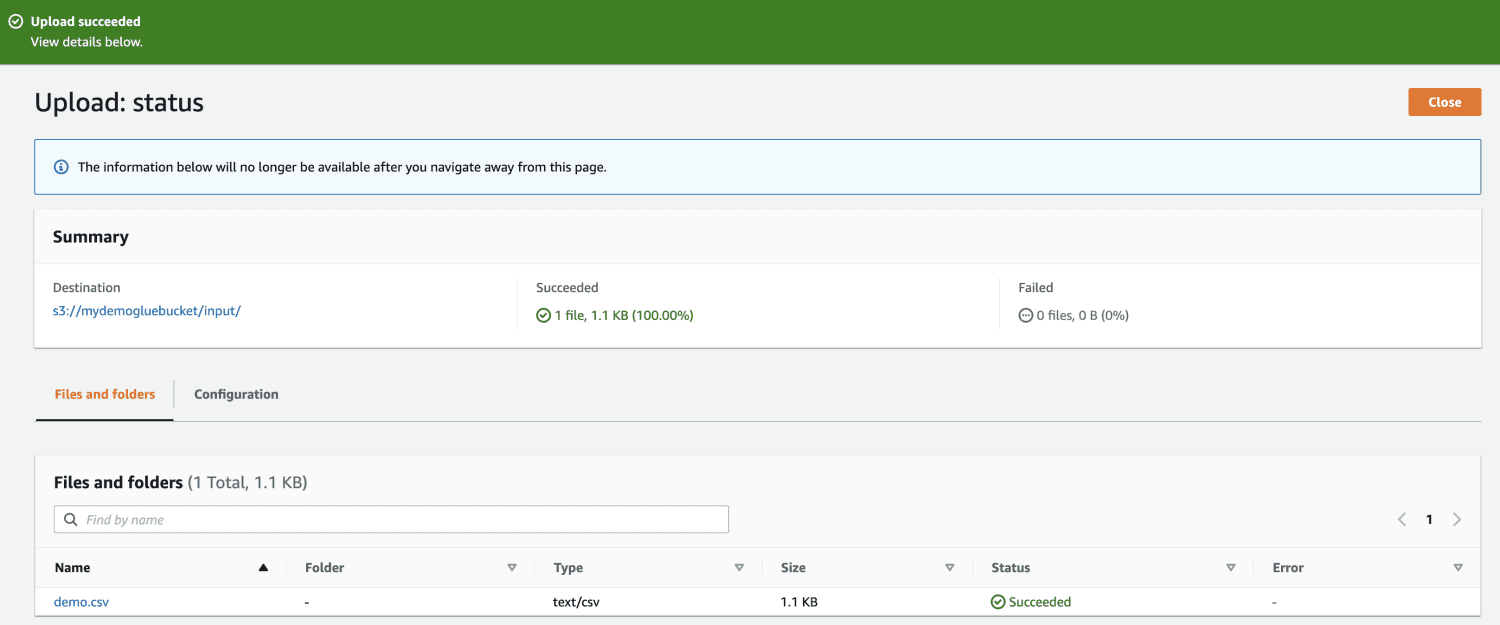
Încărcați fișierul în bucket.
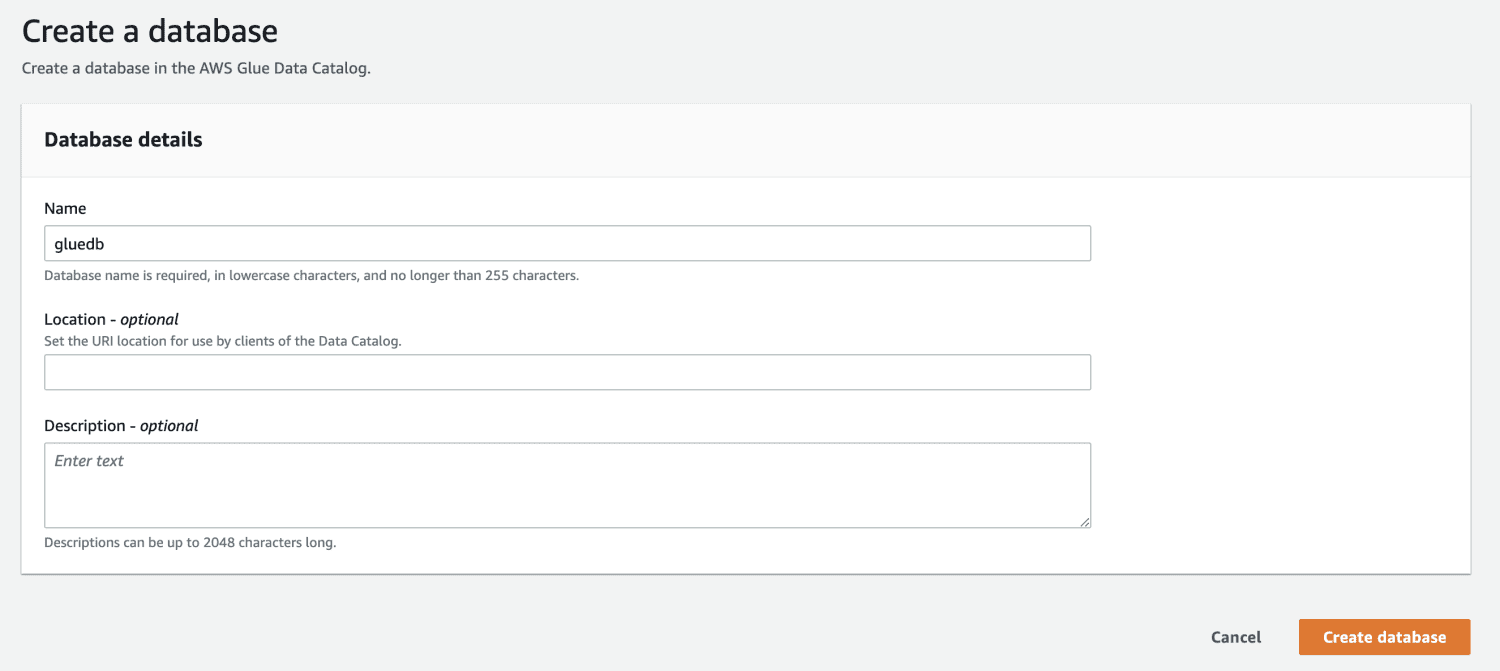
Apoi, deschideți AWS Glue din consola de management AWS și creați o bază de date.
Creați un crawler după ce ați creat o bază de date.
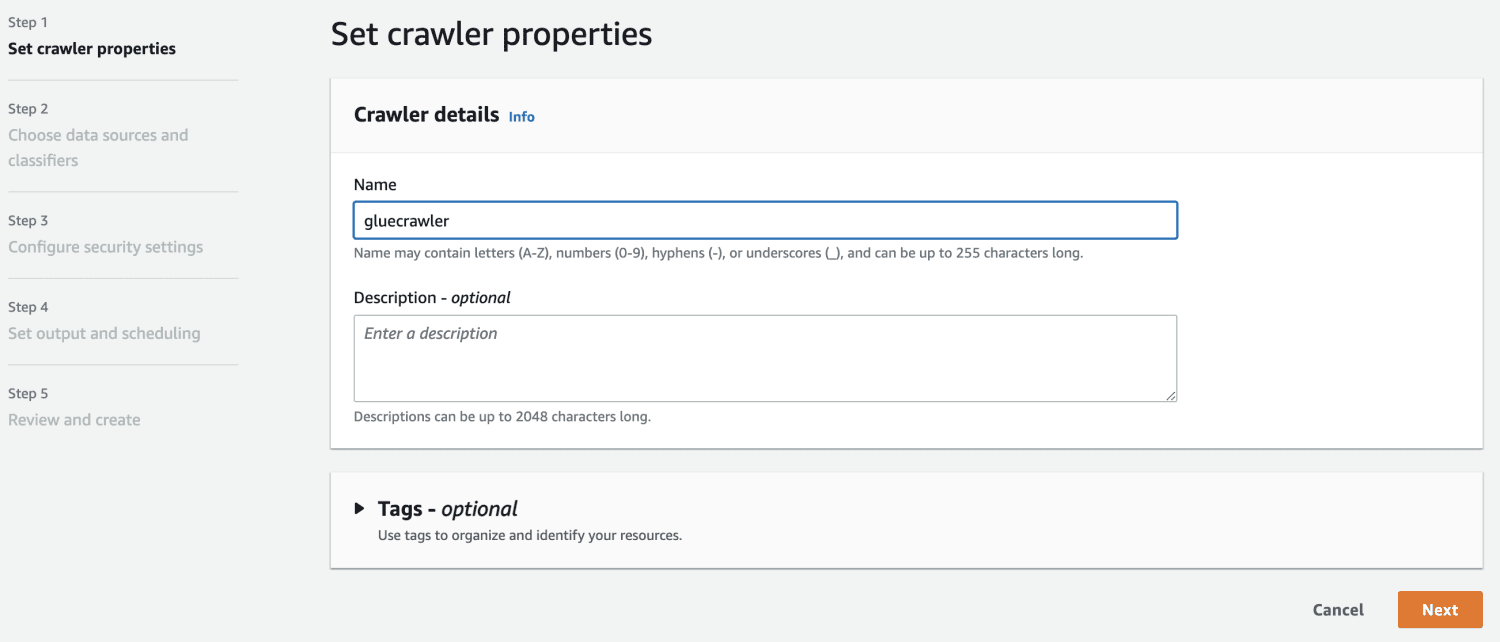
La sursa de date, selectați bucket-ul S3 pe care l-ați creat anterior.
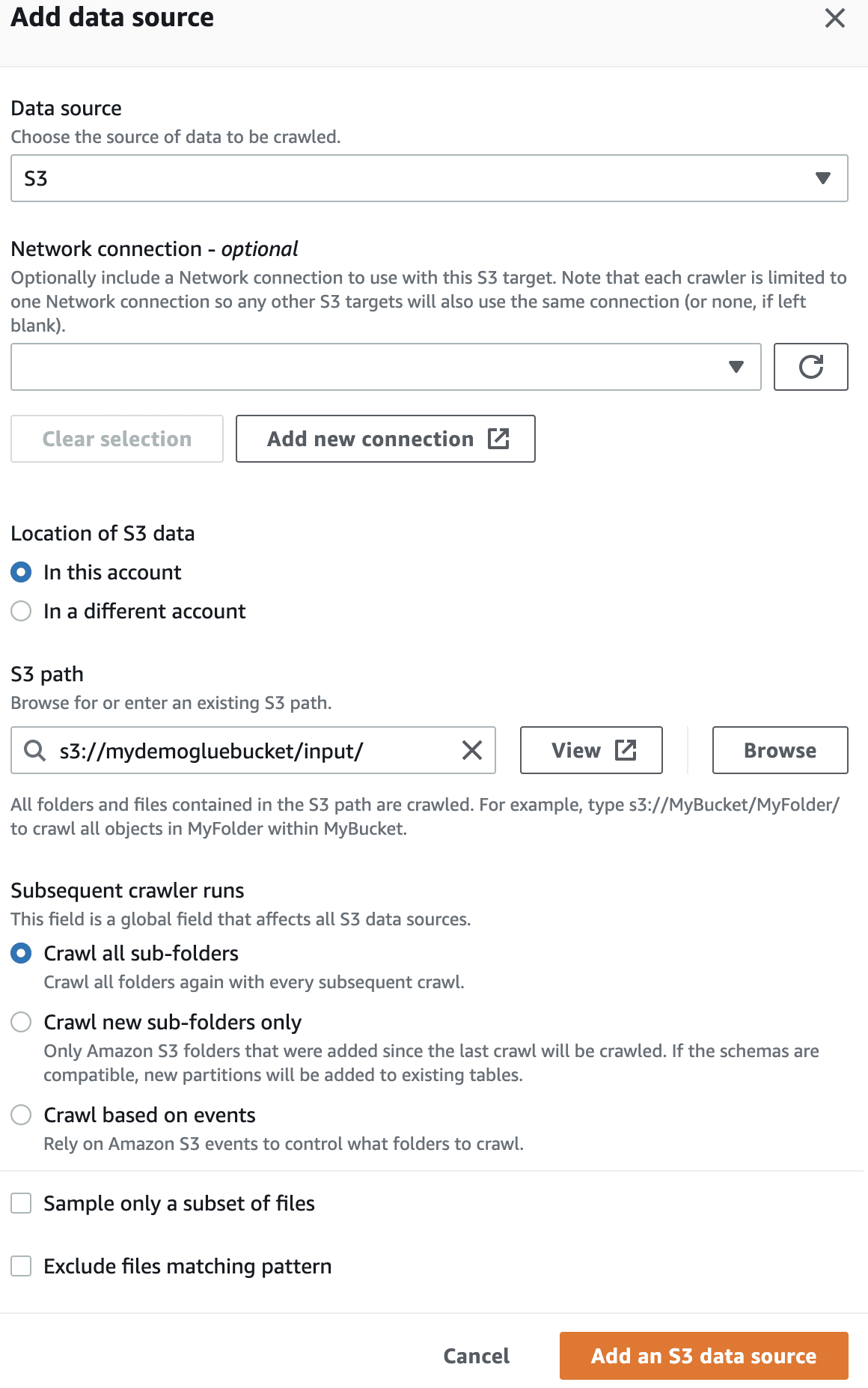
Selectați rolul IAM pentru AWS Glue pe care l-ați creat la început.
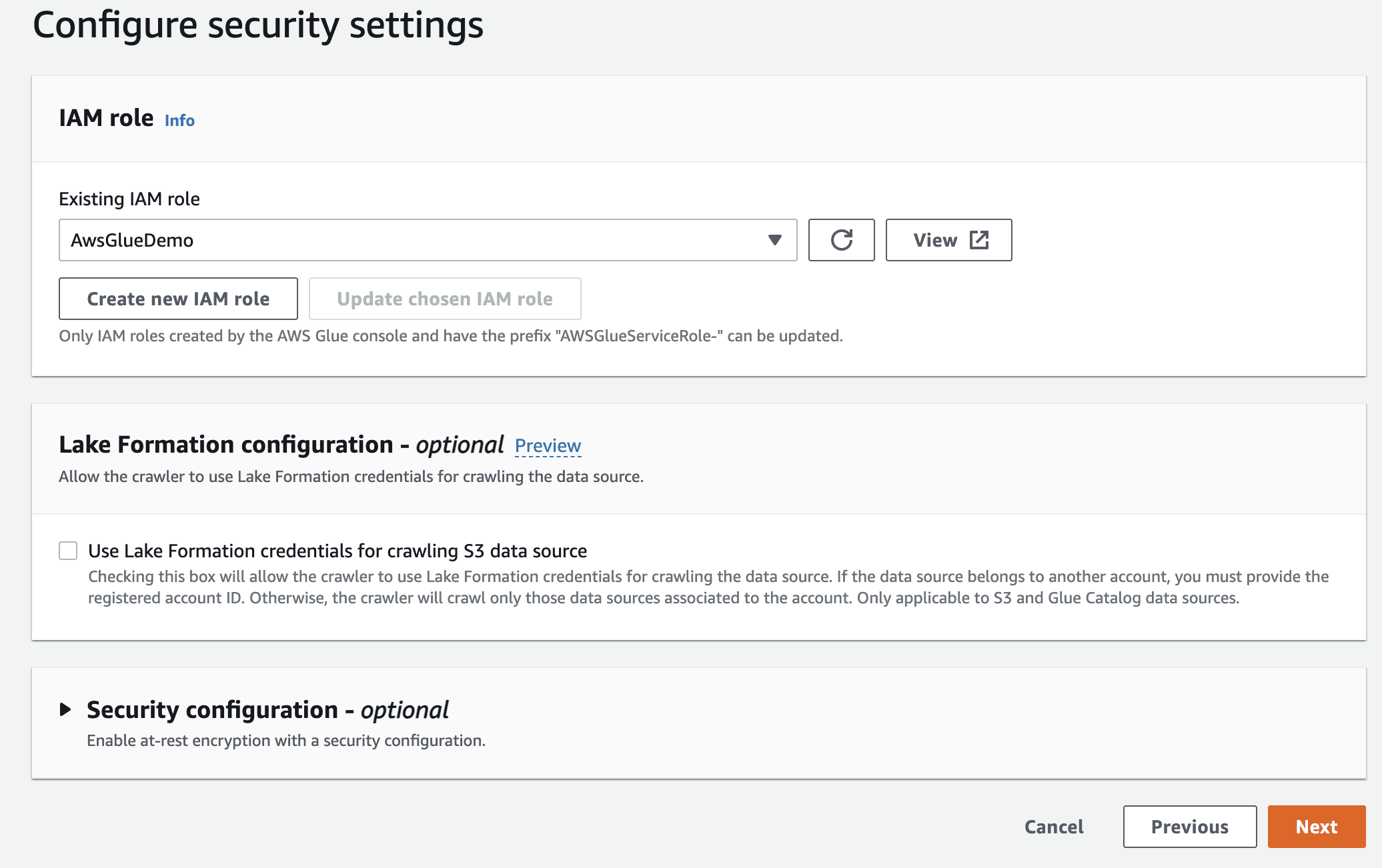
În final, la destinație, selectați baza de date creată, de exemplu `gluedb`.
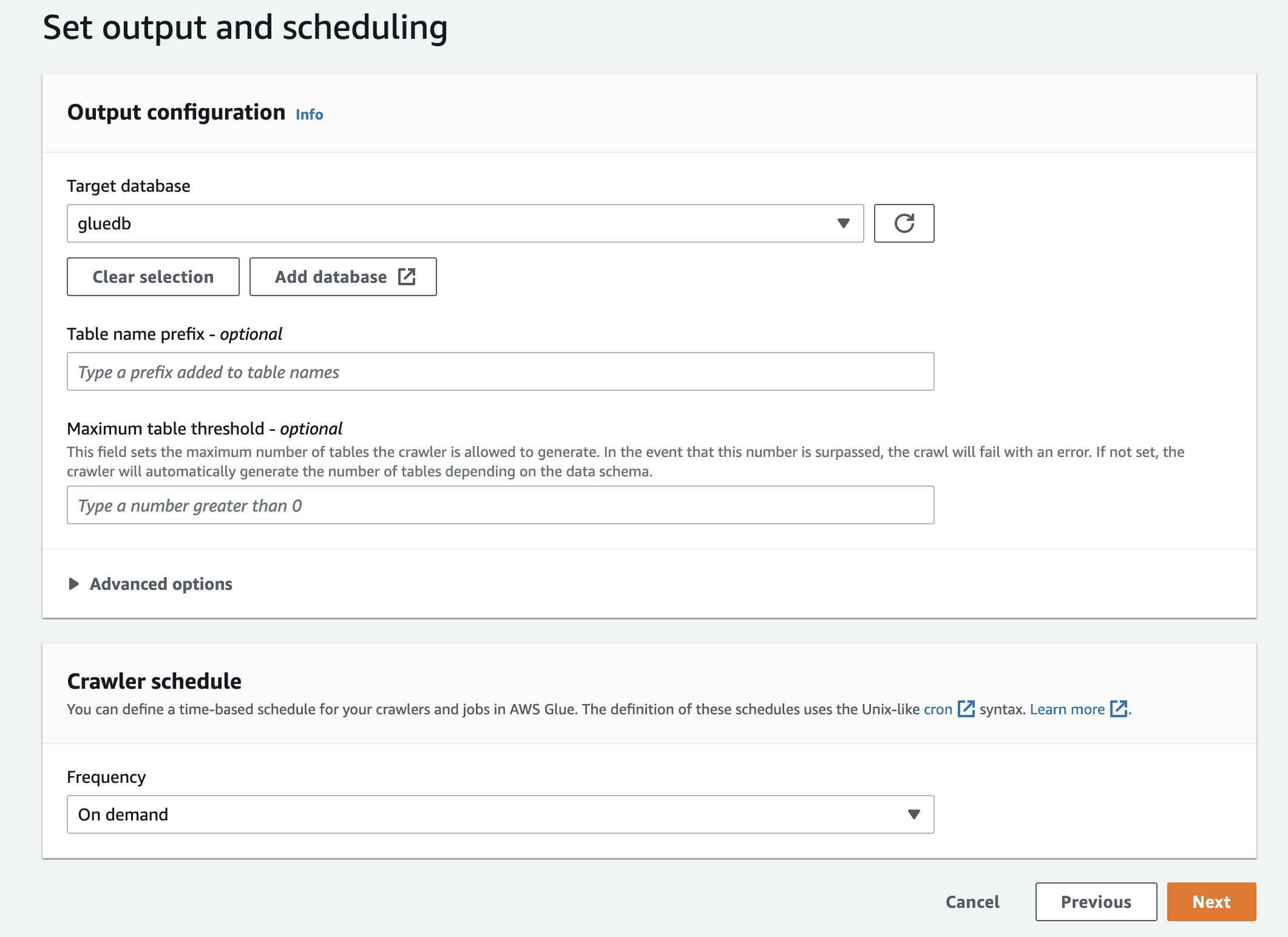
Examinați setările și creați crawlerul.
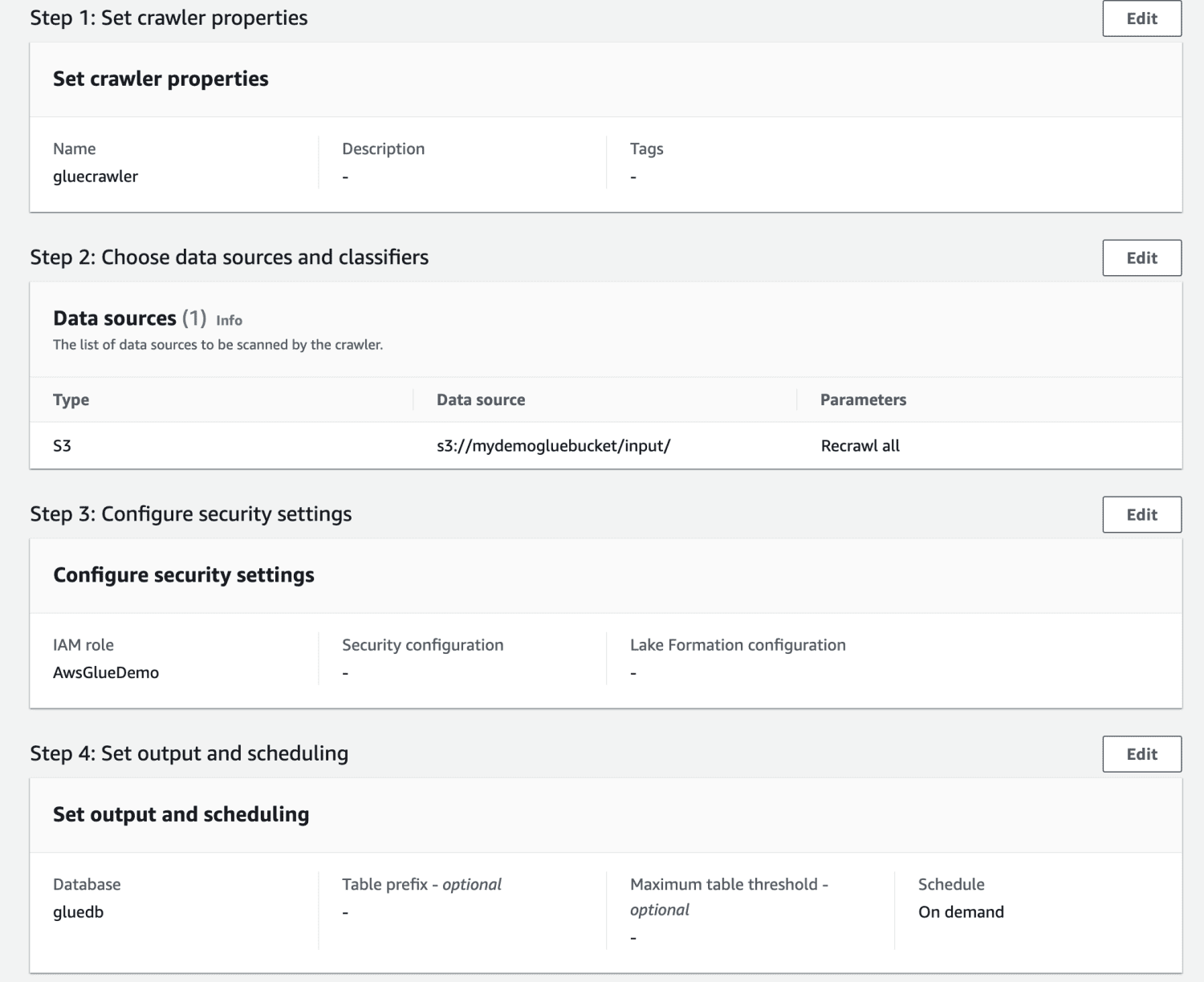
După ce a fost creat, selectați crawlerul și faceți clic pe „Run”. După un timp, acesta va avea starea „Gata”.
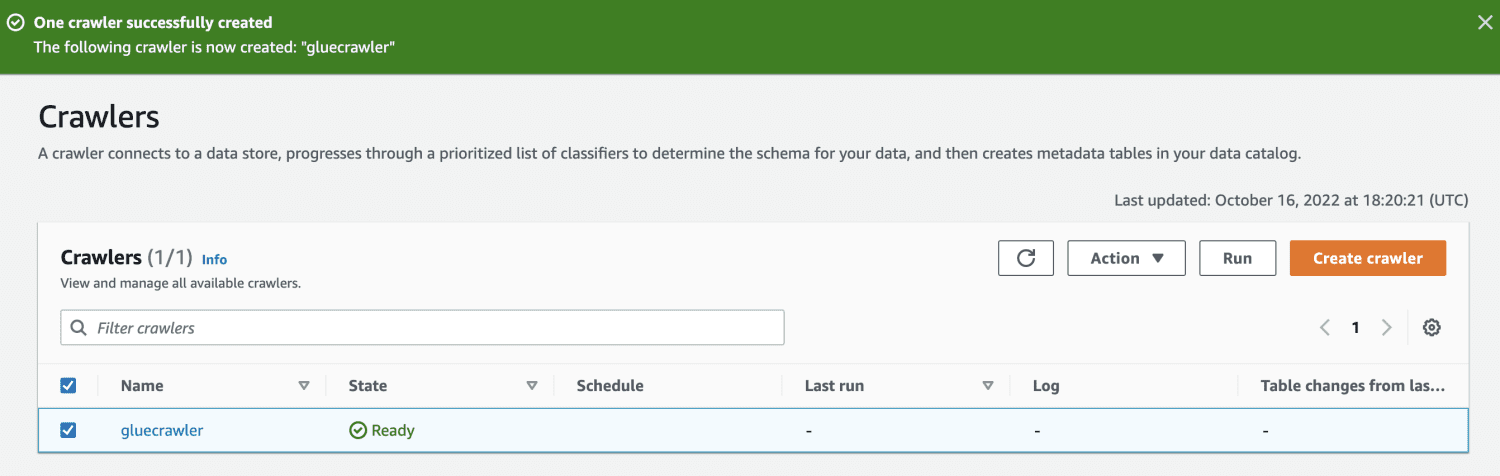
După rularea crawlerului, baza de date va include un tabel cu toate datele din fișierul CSV.
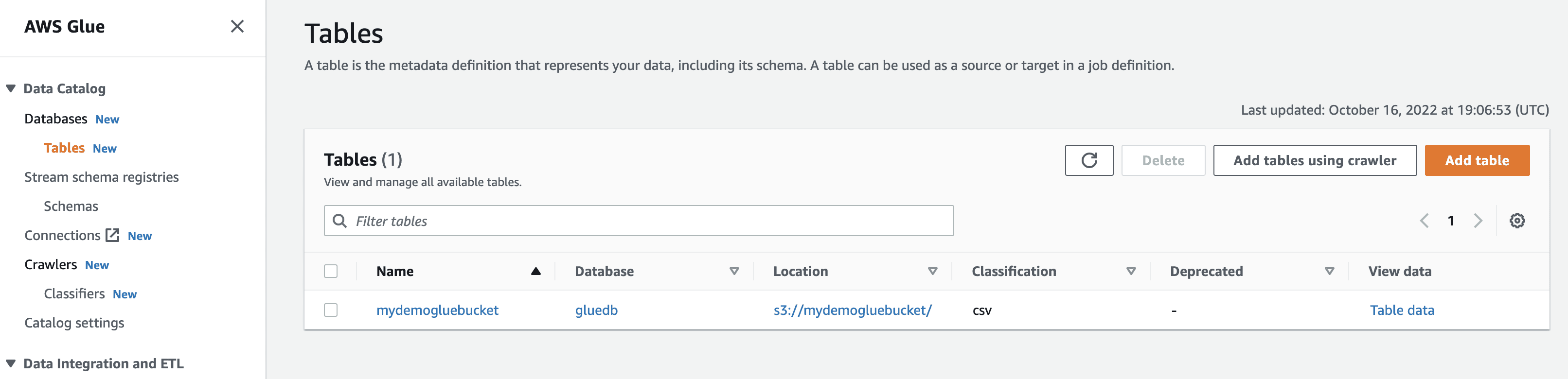
Când faceți clic pe vizualizarea datelor, veți fi redirecționat către Amazon Athena, un editor de interogări. Rulați interogarea pentru a vedea datele din tabel.
Acum puteți folosi acest crawler AWS Glue în orice lucrare ETL.
Ce este AWS Glue DataBrew?
AWS Glue DataBrew facilitează normalizarea și curățarea datelor fără a scrie cod. Comparativ cu dezvoltarea personalizată, DataBrew poate reduce cu până la 80% timpul necesar pregătirii datelor pentru învățarea automată și analiză.
Acesta oferă peste 250 de transformări de date predefinite, automatizând sarcini precum filtrarea anomaliilor, corectarea valorilor invalide și conversia datelor în formate standard.
DataBrew simplifică colaborarea dintre oamenii de știință de date, analiștii de afaceri și inginerii pentru extragerea de informații din date brute. Serviciul este fără server, eliminând necesitatea gestionării infrastructurii sau crearea de clustere.
Caracteristicile DataBrew pentru întreprinderi
Pregătirea datelor vizualizată
DataBrew oferă o modalitate unică de a vizualiza datele, care sunt adesea prezentate în tabele cu numere alfanumerice. Acesta afișează vizual toate sursele de date încărcate, facilitând înțelegerea relațiilor și ierarhiei acestora.
Peste 250 de automatizări pentru pregătirea datelor
Oamenii de știință de date se confruntă adesea cu fluxuri de lucru repetitive și izolate. AWS a modelat aceste fluxuri de lucru ca module independente de limbaj și date, oferind o bibliotecă de acțiuni ușor de utilizat.
Linia de date
Similar cu jurnalele de audit din rețelele IT, linia de date permite urmărirea activităților de transformare a datelor din AWS DataBrew, inclusiv sursa datelor, transformările aplicate și ieșirea acestora, precum și locația de destinație.
Maparea datelor
Databrew identifică câmpurile corespunzătoare din două surse de date, care pot fi ulterior încărcate într-o schemă comună.
AWS Glue DataBrew: Beneficii
Iată principalele beneficii ale AWS Glue DataBrew:
- Bariera scăzută pentru utilizarea pregătirii datelor
- Generarea automată a profilului de date
- Automatizarea a peste 250 de procese de pregătire a datelor
- Sugestii prescriptive inteligente
Alternative la AWS Glue
Airflow
Airflow este un instrument open-source de gestionare a fluxurilor de lucru, care vă permite să creați fluxuri utilizând grafice aciclice direcționate (DAG). Sarcinile sunt executate de planificatorul Airflow, ținând cont de dependențele definite.
Matillion

Matillion ETL este un instrument special conceput pentru platformele de baze de date cloud, cum ar fi Amazon Redshift și Google BigQuery. Interfața sa modernă, bazată pe browser, oferă capabilități ETL/ELT puternice. Configurarea sa rapidă vă permite să deveniți operațional în câteva minute.
Stitch
Stitch este un serviciu ETL open-source, care conectează multiple surse de date și replică datele către destinații prestabilite. Ușurința de utilizare, datorită absenței cerințelor de codare, simplifică transferul datelor între surse și destinații. Totuși, Stitch nu oferă un panou de bord prefabricat, necesitând integrarea datelor în depozite de date deschise.
Alteryx

Alteryx este o platformă de automatizare a analizelor care ajută la pregătirea și combinarea datelor. Instrumentul drag-and-drop elimină necesitatea cunoștințelor de programare, oferind informații valoroase pentru afaceri. Alteryx este, de asemenea, o resursă utilă pentru a obține sfaturi și răspunsuri de la profesioniștii din domeniu.
Concluzie
AWS Glue este o soluție excelentă pentru lucrul cu conducte ETL în cloud. Procesul de interacțiune cu utilizatorul AWS Glue se desfășoară în trei etape principale: crearea catalogului de date folosind crawlere, generarea codului ETL necesar și, în final, crearea unui program ETL. Acest articol a oferit o imagine de ansamblu cuprinzătoare asupra Amazon Glue.
Puteți explora și cele mai bune practici pentru securizarea stocării AWS S3.