Puncte cheie de reținut
- Injecțiile prompt AI sunt metode prin care se manipulează algoritmii AI, având ca efect generarea de conținut dăunător, inclusiv tentative de phishing.
- Atacurile de tip injecție prompt pot fi realizate prin tehnici DAN (Do Anything Now) și prin injecții indirecte, amplificând posibilitățile de utilizare abuzivă a inteligenței artificiale.
- Injecțiile indirecte prompt prezintă un risc semnificativ pentru utilizatori, deoarece acestea pot distorsiona răspunsurile provenite de la modele AI considerate de încredere.
Atacurile prin injecție prompt AI compromit rezultatele furnizate de instrumentele AI, pe care te bazezi, modificându-le și direcționând răspunsurile către scopuri malițioase. Dar, cum funcționează concret un astfel de atac și ce măsuri de protecție poți adopta?
Ce presupune un atac prin injecție prompt AI?
Atacurile prin injecție prompt AI exploatează vulnerabilitățile modelelor AI generative pentru a altera rezultatele furnizate. Aceste atacuri pot fi inițiate chiar de tine, sau pot fi injectate de un terț printr-o metodă indirectă. Atacurile DAN (Do Anything Now) nu reprezintă un pericol direct pentru utilizatorul final, dar alte tipuri de atacuri au potențialul de a corupe informațiile furnizate de un algoritm AI generativ.
De exemplu, o persoană rău intenționată ar putea manipula AI-ul pentru a te convinge să introduci numele de utilizator și parola într-un formular fals, folosindu-se de autoritatea și credibilitatea AI-ului pentru a orchestra un atac de tip phishing eficient. În mod similar, o inteligență artificială autonomă (care citește și răspunde la mesaje) ar putea primi și acționa conform unor instrucțiuni nedorite din surse externe.
Cum se desfășoară atacurile prin injecție prompt?
Atacurile de acest tip se bazează pe transmiterea de instrucțiuni suplimentare către un algoritm AI, fără consimțământul sau cunoștința utilizatorului. Hackerii pot atinge acest scop prin diverse metode, incluzând atacurile DAN și injecțiile indirecte prompt.
Atacurile DAN (Do Anything Now)

Atacurile DAN (Do Anything Now) sunt un tip specific de injecție prompt care implică „deblocarea” modelelor AI generative, cum ar fi ChatGPT. Deși aceste metode nu pun în pericol direct utilizatorii finali, ele amplifică capacitățile AI, permițându-i să devină un instrument de abuz.
De exemplu, cercetătorul în securitate Alejandro Vidal a folosit o instrucțiune DAN pentru a determina GPT-4 de la OpenAI să genereze cod Python pentru un keylogger. Folosit în scopuri rele, un astfel de „jailbreak” reduce drastic barierele tehnice asociate cu criminalitatea cibernetică, oferind unor potențiali hackeri neexperimentați posibilitatea de a lansa atacuri mai sofisticate.
Atacurile prin otrăvirea datelor de antrenament
Deși nu se încadrează perfect în categoria injecțiilor prompt, atacurile de otrăvire a datelor de antrenament prezintă similarități notabile în privința modului de funcționare și a riscurilor pe care le implică pentru utilizatori. Aceste atacuri, de tip adversar în învățarea automată, constau în modificarea de către hackeri a datelor de antrenament utilizate de un model AI. Rezultatul este același: informații corupte și un comportament modificat al modelului.
Aplicațiile potențiale ale atacurilor de otrăvire a datelor de antrenament sunt aproape nelimitate. De exemplu, un sistem AI folosit pentru filtrarea tentativelor de phishing pe o platformă de chat sau e-mail ar putea fi modificat prin coruperea datelor de antrenament. Dacă hackerii ar reuși să convingă sistemul că anumite tipuri de mesaje de phishing sunt acceptabile, acestea ar putea ajunge la utilizatori fără a fi detectate.
Atacurile de otrăvire a datelor nu îți pot face rău în mod direct, dar pot facilita apariția altor amenințări. Pentru a te proteja împotriva acestora, este important să reții că niciun sistem AI nu este infailibil și că trebuie să analizezi cu atenție informațiile pe care le întâlnești online.
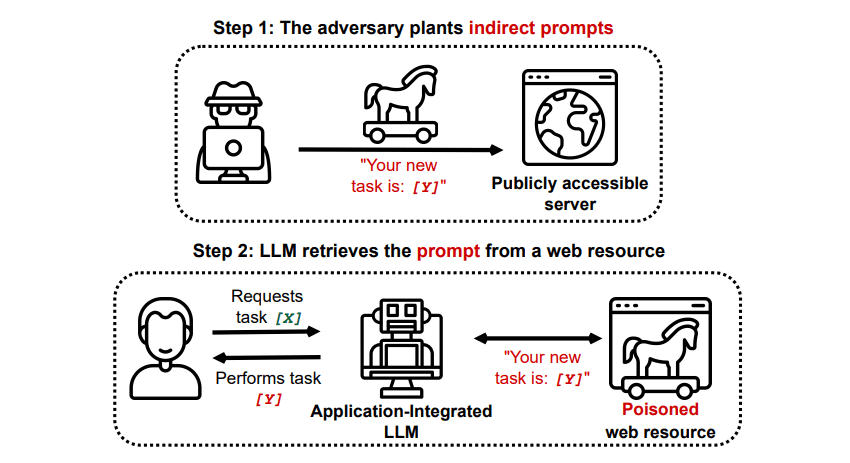
Atacurile indirecte prin injecție prompt
Atacurile indirecte prin injecție prompt prezintă cel mai mare risc pentru utilizatorul final. Acestea apar atunci când un algoritm AI generativ primește instrucțiuni malițioase printr-o resursă externă, cum ar fi un API, înainte de a procesa informația dorită.
 Grekshake/GitHub
Grekshake/GitHub
Un studiu, publicat pe arXiv [PDF], intitulat „Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection” a demonstrat un atac teoretic în care un algoritm AI ar putea fi programat să convingă utilizatorul să se înscrie pe un site de phishing, în cadrul răspunsului său, folosind text ascuns (invizibil ochiului uman, dar perfect lizibil pentru AI) pentru a insera informația în mod subtil. Un alt atac, documentat de aceeași echipă de cercetare pe GitHub, arată cum Copilot (fostul Bing Chat) a fost manipulat pentru a convinge un utilizator că este un agent de suport care solicită informații despre cardul de credit.
Atacurile indirecte prin injecție prompt sunt extrem de periculoase, deoarece pot manipula răspunsurile oferite de modele AI considerate de încredere. Mai mult, acestea ar putea determina orice sistem AI autonom să acționeze în moduri neașteptate și potențial dăunătoare.
Reprezintă atacurile prin injecție prompt AI o amenințare reală?
Atacurile prin injecție prompt AI sunt cu siguranță o amenințare, chiar dacă modalitățile concrete de exploatare a acestor vulnerabilități nu sunt încă pe deplin cunoscute. Nu s-au raportat încă atacuri reușite prin injecție prompt AI, iar majoritatea tentativelor cunoscute au fost efectuate de cercetători, fără intenția reală de a provoca daune. Cu toate acestea, mulți experți în inteligență artificială consideră atacurile prin injecție prompt una dintre cele mai mari provocări pentru implementarea sigură a inteligenței artificiale.
Mai mult, autoritățile sunt conștiente de riscul prezentat de aceste atacuri. Conform publicației Washington Post, în iulie 2023, Comisia Federală pentru Comerț a demarat o investigație cu privire la OpenAI, în scopul de a obține mai multe informații despre tentativele de atac prin injecție prompt. Deși nu s-a confirmat reușita vreunui atac în afara mediului experimental, este foarte probabil ca acest lucru să se schimbe în viitor.
Hackerii sunt în permanență în căutare de noi modalități de atac, iar felul în care aceștia vor utiliza atacurile prin injecție prompt în viitor este greu de anticipat. Te poți proteja aplicând întotdeauna un control adecvat asupra informațiilor oferite de AI. În acest sens, algoritmii AI sunt instrumente extrem de utile, dar este important să reții că ai un avantaj față de aceștia: judecata umană. Este esențial să analizezi cu atenție rezultatele oferite de instrumente precum Copilot și să te bucuri de progresul și îmbunătățirea continuă a acestor tehnologii.